近日部署跑通的若干多模态模型总结与论文概述
CLIP模型概述与落地测试
CLIP模型全称是Contrastive Language-Image Pretraining(对比语言图像预训练)。是OpenAI于2021年提出的多模态预训练模型,通过对比学习对齐图像和文本的表示,实现零样本(zero-shot)迁移到多种视觉任务。其核心思想是“用自然语言监督视觉模型”,即利用互联网规模的图像-文本对训练,使模型理解开放世界的视觉概念。
其特点总结如下:
1.采用多模态对齐,图像用视觉编码器VIT(vision transformer),或者resnet残差网络,文本用文本编码器如transformer编码。最终实现最大化匹配图像和文本的相似度。CLIP对于图像的编码实际上用的是resnet 50
2.零样本迁移,无需微调即可直接应用于新任务(如分类、检索),通过文本提示(prompt)生成分类器。
3.prompt工程,提示工程与集成提高了零样本性能。与使用无上下文类名的基线相比,提示工程与集成在 36 个数据集上平均将零样本分类性能提高了近 5 个百分点。这种提升与使用基线零样本方法时将计算量增加 4倍所获得的提升相似,但在进行多次预测时,这种提升是“免费的”。
resnet50是五十层的残差神经网络,通过全局池化和批量归一化来优化性能,可以用于对图像进行特征提取。
在论文中阐述clip的图例如下:
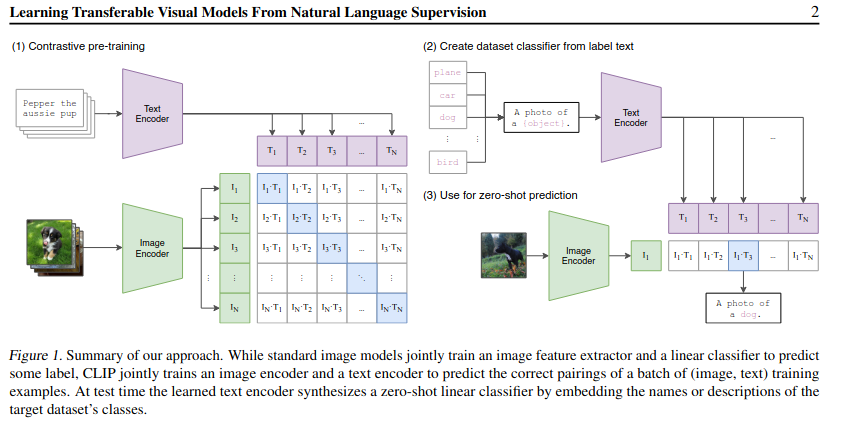
首先是预训练,然后是构建数据集分类器,最后是用于零损失预测。
CLIP模型被发布在hugging face官网以供下载。
但是由于国内下载hugging face速度太慢,而模型本身大小较大,因此在国内镜像网站上面下载,采用git lfs clone来下载。
测试办法参考项目工程,该工程应用CLIP来做图文等多模态信息检索并求解相似度。
GitHub - pydaxing/clip_blip_embedding_rag: 在RAG技术中,嵌入向量的生成和匹配是关键环节。本文介绍了一种基于CLIP/BLIP模型的嵌入服务,该服务支持文本和图像的嵌入生成与相似度计算,为多模态信息检索提供了基础能力。
比如:
git lfs clone https://www.modelscope.cn/<namespace>/<model-name>.git 然后将namespace/model-name.git替换成要下载的模型名称。openai/clip-vit-large-patch14,namespace是出品方,model-name是下载的模型的名字。主要的代码如下,运行时候
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
import requests
from io import BytesIO
import numpy as np
import time
import asyncio
from concurrent.futures import ThreadPoolExecutor
from typing import List # 导入 List 类型# Use a pipeline as a high-level helper# 加载模型和处理器
# Load model directly
processor = CLIPProcessor.from_pretrained("./dataroot/models/openai/clip-vit-large-patch14")
model = CLIPModel.from_pretrained("./dataroot/models/openai/clip-vit-large-patch14")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)# 函数:生成文本嵌入
def get_text_embedding(text):inputs = processor(text=[text], return_tensors="pt", padding=True).to(device)with torch.no_grad():embedding = model.get_text_features(**inputs)return embedding.cpu().numpy()def get_image_embedding(image_url):try:response = requests.get(image_url)image = Image.open(BytesIO(response.content)).convert("RGB")inputs = processor(images=image, return_tensors="pt").to(device)with torch.no_grad():embedding = model.get_image_features(**inputs)return embedding.cpu().numpy()except Exception as e:return Noneclass EmbeddingService:def __init__(self, max_concurrency=5):self.semaphore = asyncio.Semaphore(max_concurrency)async def get_embedding(self, index, param, result, candidate_type):async with self.semaphore:loop = asyncio.get_running_loop()with ThreadPoolExecutor() as pool:if candidate_type == "text":result[index] = await loop.run_in_executor(pool, get_text_embedding, param)elif candidate_type == "image":result[index] = await loop.run_in_executor(pool, get_image_embedding, param)app = FastAPI()class QueryRequest(BaseModel):query: strcandidates: List[str]query_type: str = "text" # 默认为文本candidate_type: str = "text" # 默认为文本def cosine_similarity(vec1, vec2):return np.dot(vec1, vec2.T) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))@app.post("/similarity")
async def similarity(request: QueryRequest):# 解析请求数据query = request.querycandidates = request.candidatesquery_type = request.query_typecandidate_type = request.candidate_type# 生成查询嵌入if query_type == "text":query_embedding = get_text_embedding(query).tolist() # 转换为可序列化格式elif query_type == "image":query_embedding = get_image_embedding(query)if query_embedding is None:raise HTTPException(status_code=400, detail="Failed to load query image from URL")query_embedding = query_embedding.tolist() # 转换为可序列化格式else:raise HTTPException(status_code=400, detail="Invalid query_type")# 使用并发生成候选嵌入result = [None] * len(candidates)embedding_service = EmbeddingService(max_concurrency=5)# 并发执行任务,限制同时运行的任务数await asyncio.gather(*[embedding_service.get_embedding(i, candidate, result, candidate_type)for i, candidate in enumerate(candidates)])# 计算相似度similarities = []for candidate, candidate_embedding in zip(candidates, result):if candidate_embedding is None:raise HTTPException(status_code=400, detail=f"Failed to load candidate image from URL: {candidate}")similarity_score = cosine_similarity(query_embedding, candidate_embedding)similarities.append((candidate, float(similarity_score))) # 确保 similarity_score 是 float 类型# 按相似度排序并返回最相似的候选结果similarities.sort(key=lambda x: x[1], reverse=True)return {"similarities": similarities}uvicorn是一个基于 Python 的 ASGI(Asynchronous Server Gateway Interface)服务器,专为高性能异步 Web 应用设计。通过uvicorn启动服务器的命令如下:
uvicorn embedding:app --host 0.0.0.0 --port 9502得到的测试结果如下:
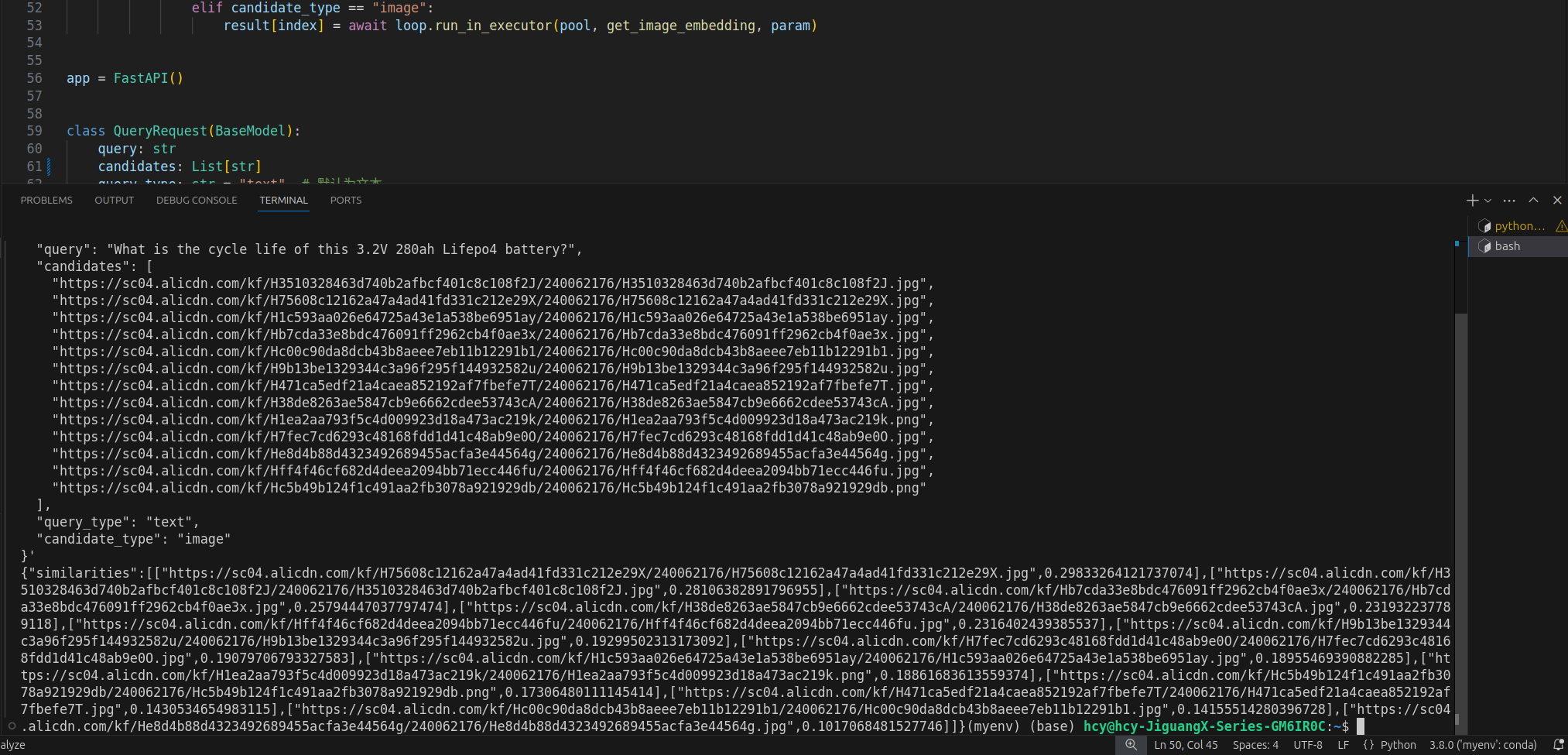
在上图中和锂电池查询What is the cycle life of this 3.2V 280ah Lifepo4 battery匹配最高的图像是,相似度为0.2983

videochat模型概述与部署测试
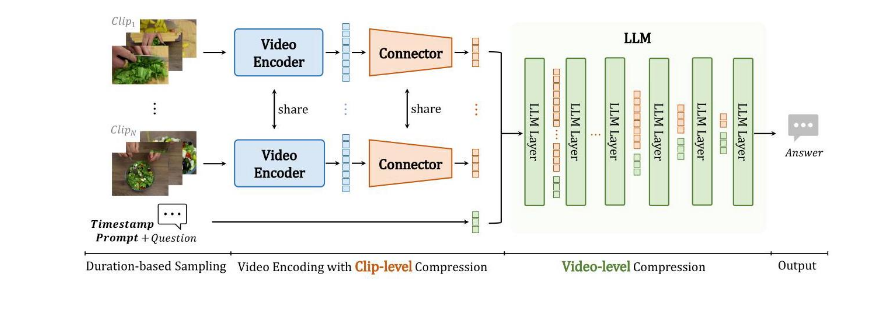
videochat-flash模型是由上海AI lab研究人员等开发的一款MLLM模型,以往模型的难点在于如何处理长时间的视频。该模型的创新点在于:
1.片段级压缩:将视频分割为片段,通过时空注意力(UMT-L编码器)和相似令牌合并(ToMe),将每帧压缩至16个令牌(压缩比1/50)。
2.视频级压缩:在LLM推理时渐进丢弃冗余令牌(浅层均匀丢弃,深层基于文本引导的注意力选择),减少计算量且提升性能。
训练的数据集为:
LongVid数据集:30万小时长视频+20亿文本注释,覆盖5类任务(字幕生成、时间定位等),整合Ego4D、HowTo100M等数据。
通过这些办法最终在处理长视频时候计算量大大降低。性能大大提高。图例如下:
在镜像网站上的开源模型为:
本地的测试代码如下,在实际测试中引起问题的主要来源在transformer的版本。
还有其他的下载的包应当保持对齐为:
pip install transformers==4.40.1
pip install timm
pip install av
pip install imageio
pip install decord
pip install opencv-python
# optional
pip install flash-attn --no-build-isolation
from modelscope import AutoModel, AutoTokenizer
import torch# model setting
model_path = './VideoChat-Flash-Qwen2_5-2B_res448'tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
image_processor = model.get_vision_tower().image_processormm_llm_compress = False # use the global compress or not
if mm_llm_compress:model.config.mm_llm_compress = Truemodel.config.llm_compress_type = "uniform0_attention"model.config.llm_compress_layer_list = [4, 18]model.config.llm_image_token_ratio_list = [1, 0.75, 0.25]
else:model.config.mm_llm_compress = False# evaluation setting
max_num_frames = 512
generation_config = dict(do_sample=False,temperature=0.0,max_new_tokens=1024,top_p=0.1,num_beams=1
)video_path = "./testvideo.mp4"# single-turn conversation
question1 = "Describe this video in detail."
output1, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question1, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)print(output1)# multi-turn conversation
question2 = "How many people appear in the video?"
output2, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question2, chat_history=chat_history, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)print(output2)#multi-turn
question3="who is the oldest in this video?"
output3, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question3, chat_history=chat_history, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)
print(output3)然后问题在于如何找到测试视频,这里采用的是python中的you-get模块:
pip install you-get后通过下面的命令就可以实现视频的爬取,这里下载了一段电视剧片段,2720帧,视频大意是一个老人去法国买羊角面包回去给他的老朋友带去吃。
you-get https://www.bilibili.com/video/爬取后进行模型测试,备注,此处还需要使用CUDA支持,需要电脑装有invidia显卡并下载CUDA相应工具包。得到结果如下,符合视频实际逻辑。

VICLIP模型概述与部署测试
viclip 是由上海ai lab的opengv-lab等团队联合实现的,这篇论文,arxiv链接如下:
https://arxiv.org/pdf/2307.06942
其中首先提出了一个intern vid数据集,其具备大范围多国源视频和高质量文本标注,用BLIP-2为视频中间帧生成描述。用Tag2Text逐帧标注,再通过大语言模型(如LLaMA)汇总为整体描述。
随后介绍了VICLIP模型,其基于CLIP的对比学习框架,视频编码器为ViT-L(加入时空注意力),文本编码器与CLIP相同。VICLIP的创新点在于使用了视频掩码学习来随机遮蔽视频块(类似MAE),降低计算成本。视频掩码学习(Video Masked Learning) 是一种受自然语言处理(NLP)和计算机视觉中掩码建模(如BERT、MAE)启发的自监督学习方法,旨在通过遮蔽部分视频数据并让模型预测被遮蔽的内容,从而学习视频的时空表征。
VCLIP采用两段训练,关注infoNCE损失度,最大化视频-文本对的相似度。
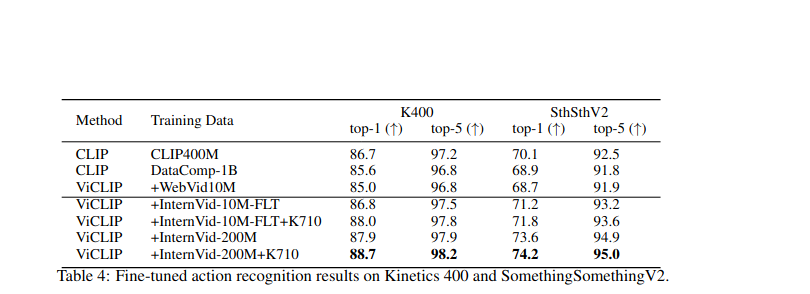
VICLIP在训练过程中使用了64张A100,训练了三天在五千万的视频-文本对上。结果较好
viclip在hugging face平台的模型如下:
在下载好后,使用其示例中的视频,一个男人和狗在雪地中玩的视频。

在jupyter笔记本的demo中跑得结果如下:
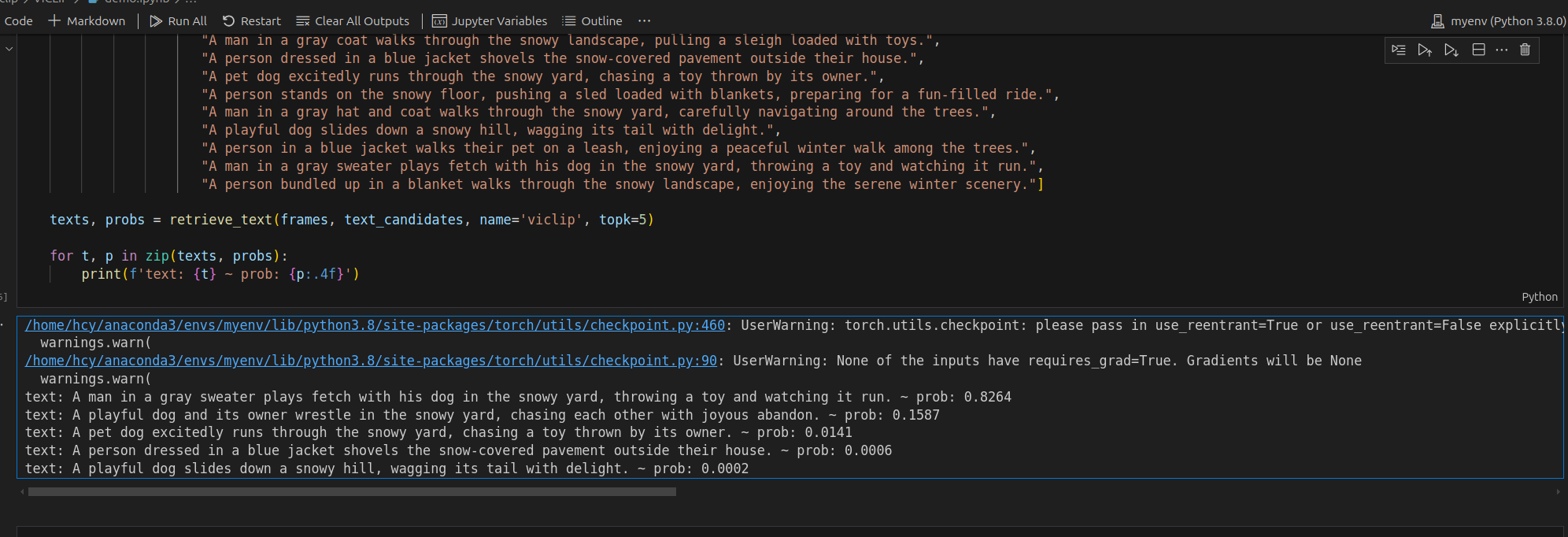
text: A man in a gray sweater plays fetch with his dog in the snowy yard, throwing a toy and watching it run. ~ prob: 0.8264 该文本最和视频相符。