【AlphaFold2】深入浅出,Feature Embedding|学习笔记

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【AlphaFold2】深入浅出,讲解Evoformer|学习笔记
- 每日一言🌼: 永远不要只看见前方路途遥远 而忘了从前的自己坚持了多久才走到这里。🌺
0、前言
在前两期博客中,我们讲解了特征提取(Feature Extraction)和Evoformer(【AlphaFold2】Feature extraction:提取特征,为模型输入做准备|Datapipeline讲解、【AlphaFold2】深入浅出,讲解Evoformer|学习笔记)。
这期我们要讲解的特征嵌入(Feature Embedding) 是连接特征提取(Feature Extraction)和Evoformer(核心结构)的桥梁。
特征嵌入一般指的是网络的前几层,将初始的特征(通常是one-hot独热编码)进行,嵌入到第一层可学习的嵌入向量中。此外,我们还会给模型构造位置编码,引入位置信息,弥补注意力机制对位置的感知;然后我们会使用迭代编码优化的机制(Recycling Embedder ),将模型预测的结果作为新一轮的输入,进行迭代优化,从而逐步提高预测的效果。
注明:此篇博客以Youtube视频博主Kilian Mandon的《从零实现AlphaFold》作为参考学习内容写成:AlphaFold Decoded: Feature Embedding (Lesson 6),仅供学习使用。
特征嵌入的介绍
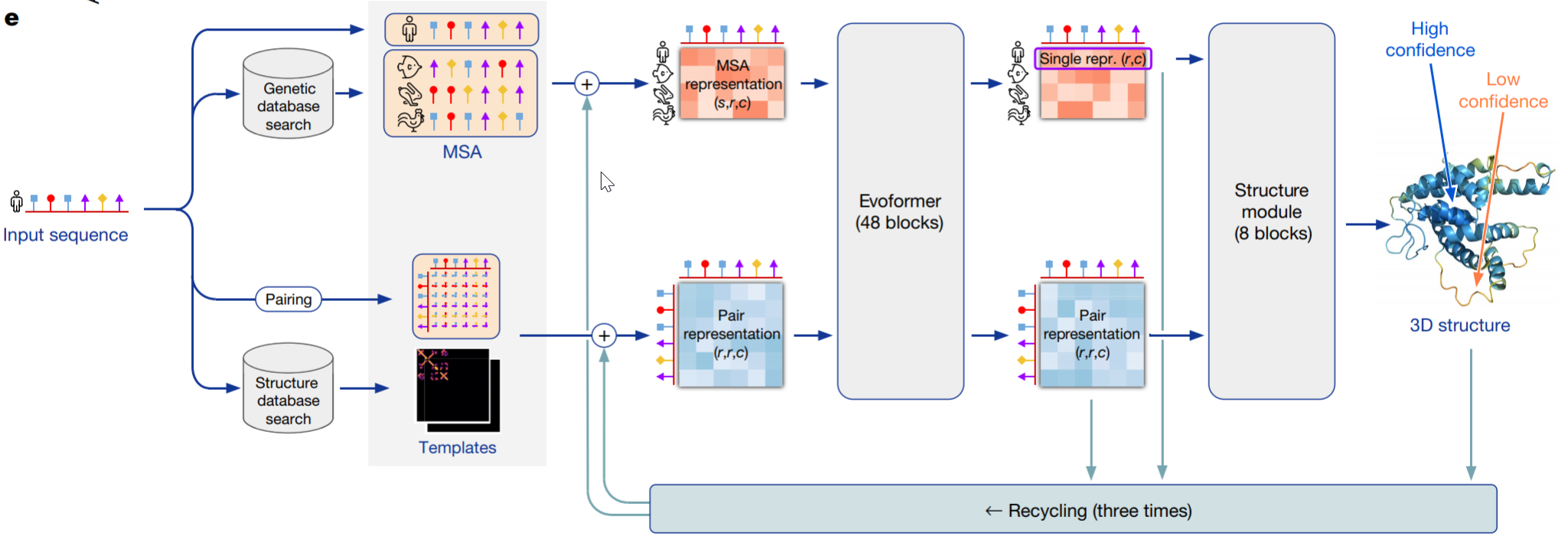
在Feature Extraction部分,我们成功构建了下图架构中的左侧四个初始输入张量:
extra_msa_featthe residue_indexthe target_featthe msa_feat
上期博客我们讲解了右侧的Main Evoformer Stack。在这两部分之间,也就是我们今天所要讲解的。
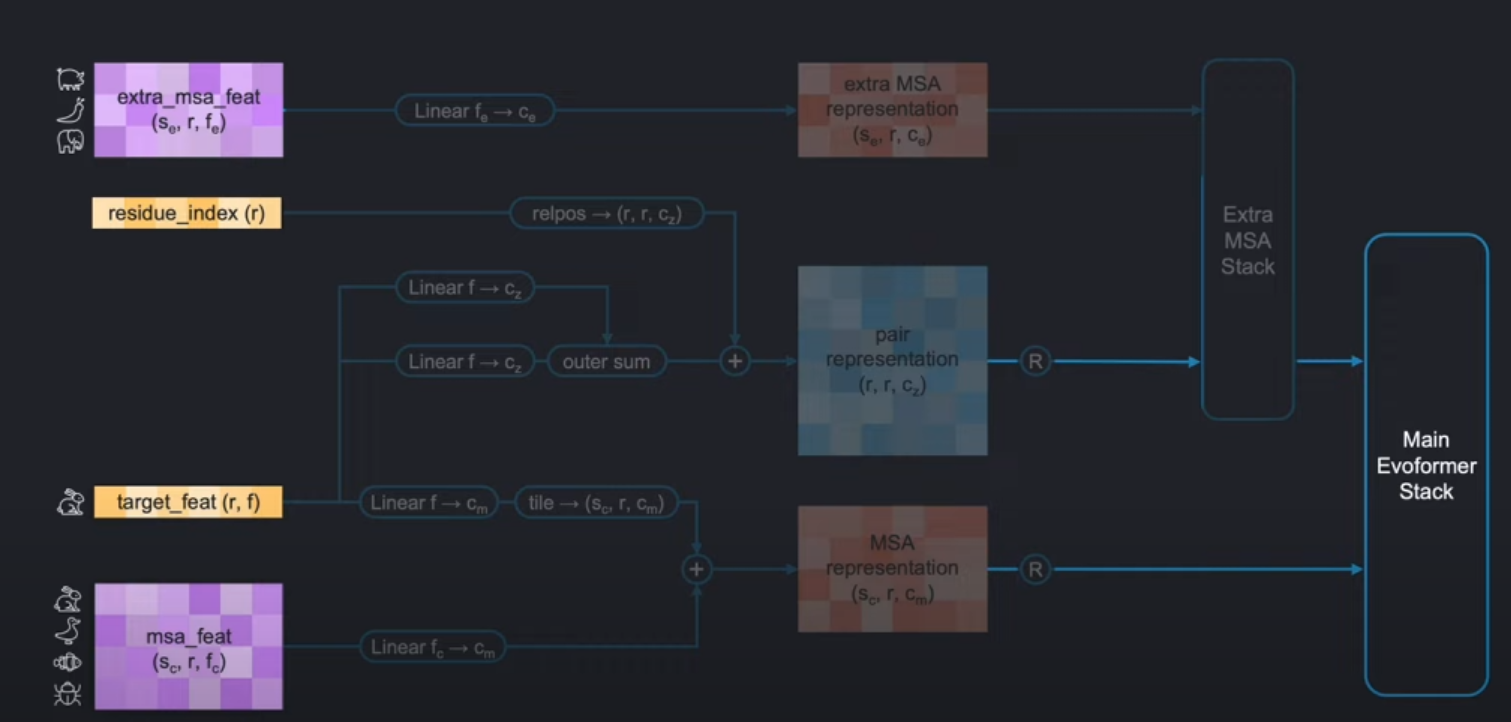
中间的特征编码主要由以下三部分组成
- Input Embedder:从初始特征输入构建
pair representation和MSA representation。
2. Extra MSA Stack:结合Extra MSA representation来更新pair representation。其中Extra MSA representation是由那些在特征提取阶段没有被选作聚类中心的序列。 - Recycling Embedder:整个AlphaFold对一个蛋白质的预测会进行迭代多次,其中Recycling Embedder的作用就是将前一轮Evoformer和Structure Module的输出作为此轮的输如,进行迭代更新pair 和MSA representation。
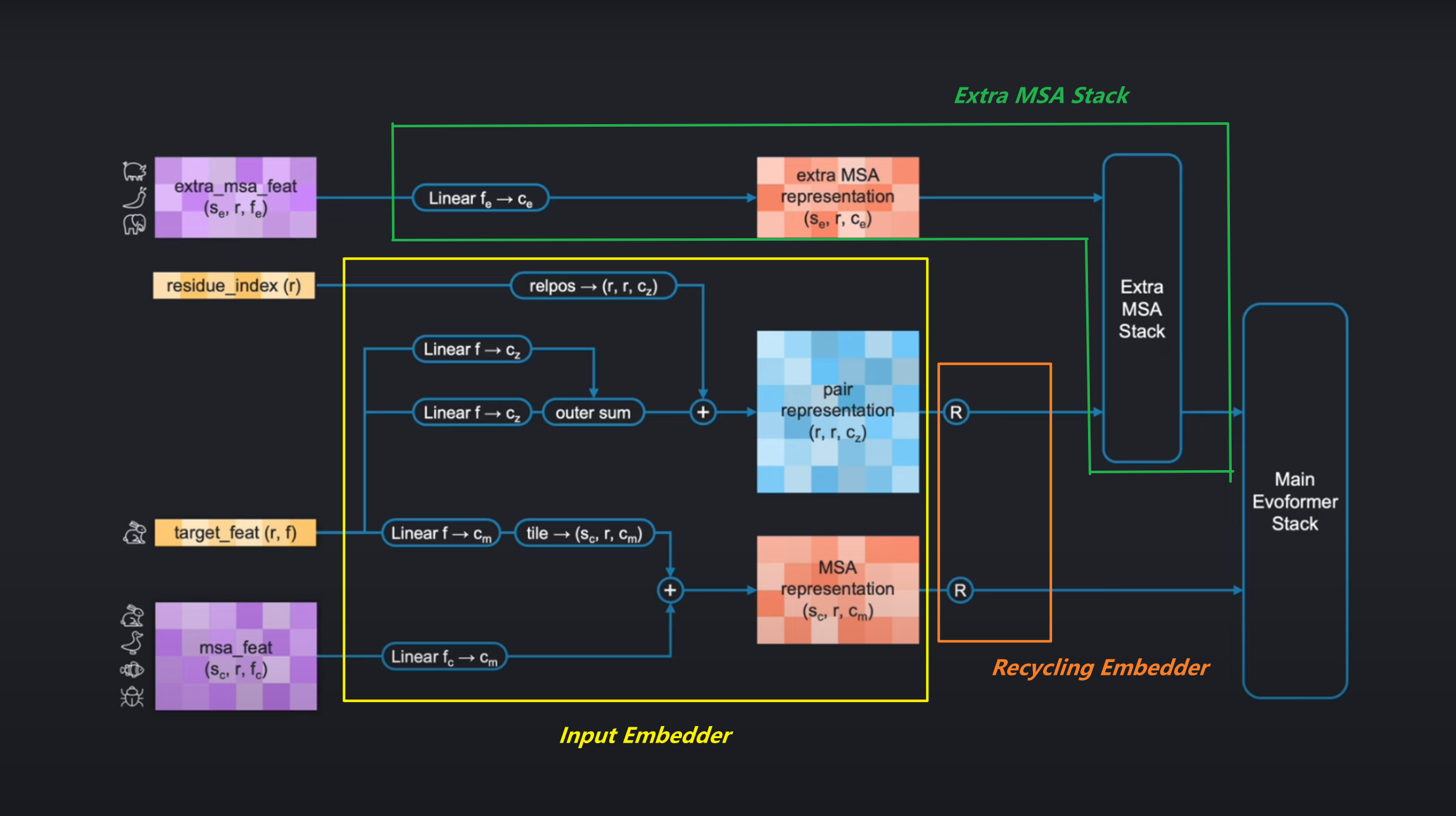
1. 输入嵌入器(Input Embedder)
1.1 初始特征的编码
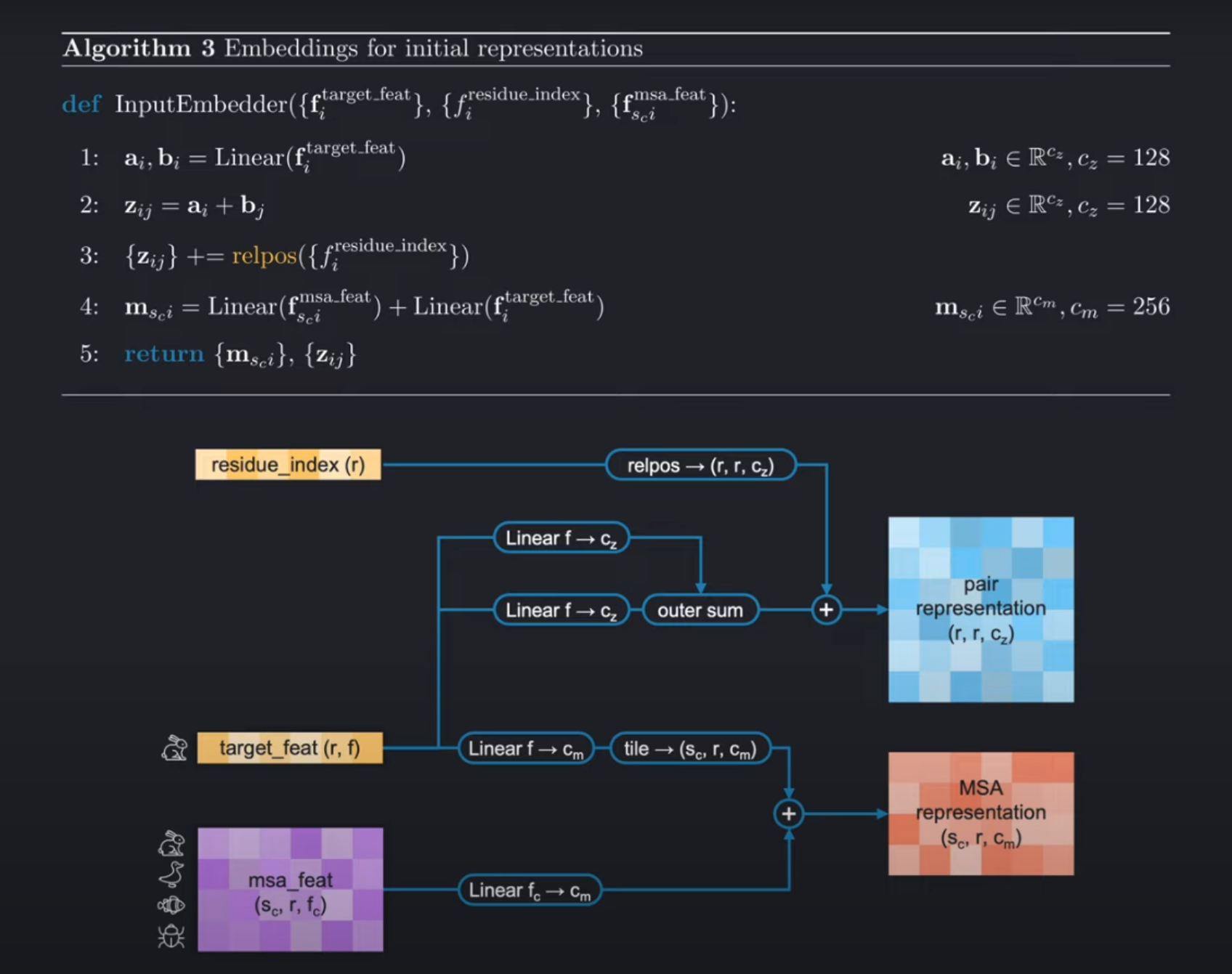
首先让我们看到输入编码器,它的架构相对比较简单,根据架构图几乎可以直接写成伪代码。接下来对下图的架构和实现进行讲解:
Pair representation的获取:
- 首先,
target_feat会直接进入两个独立的线性层,然后计算它们的 外积和(Outer Sum) 得到和pair-representation形状一致的张量。 relpos是一种位置编码的方式,编码后的结果直接和外outer-sum的结果相加。
MSA representation的获取:
MSA 的获取也很简单,注意tile就是广播,将其形状广播到msa representation的形状。
1.2 相对位置编码(Relative Position Encoding, relpos)
在蛋白质结构中,残基(氨基酸)之间的相对位置关系对预测其3D结构至关重要。AlphaFold通过计算残基索引(Residue Index)的差值矩阵(d),并将其编码为向量形式,使模型能感知序列中残基的顺序和距离。
计算差值矩阵(d)
- 输入:残基索引向量(如
[0, 1, 2, ..., L-1],L为序列长度)。 - 操作:计算外差(Outer Difference):
d = residue_index[:, None] - residue_index[None, :] # 形状 [L, L] - 结果示例:
d = [[ 0, -1, -2, -3],[ 1, 0, -1, -2],[ 2, 1, 0, -1],[ 3, 2, 1, 0]]d[i][j]表示残基i相对于残基j的位置偏移量(i的位置 - j的位置)。
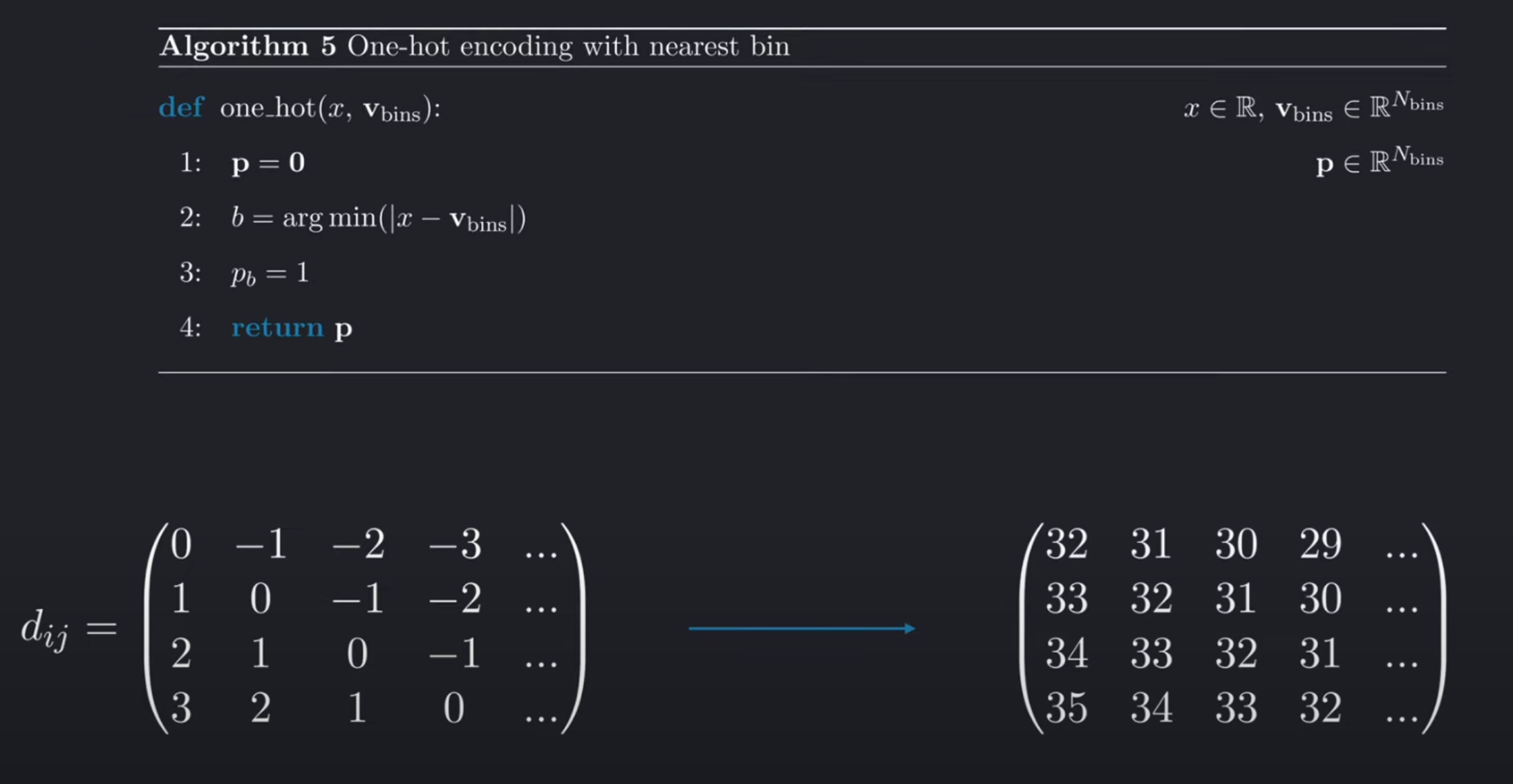
原始算法(Algorithm 5)
- 功能:将标量值
x编码为N_bins维的one-hot向量,激活x所属的最近分桶(bin)。 - 步骤:
- 初始化全零向量
p(长度=N_bins)。 - 找到
x与分桶中心v_bins的最近邻索引b。 - 将
p[b]设为1。
- 初始化全零向量
- 问题:对于整数差值,直接分桶是冗余的(因为差值本身就是离散的)。

简化实现:
直接先将值作为类别索引,将其 差值矩阵d的整数范围固定(如-32到32)。
由于差值可能为负数,而one-hot编码需要非负索引,因此需要偏移:
- 操作:将缩放后的
d整体加上一个偏移量(如32),确保最小值为0:
d = torch.clamp(d, -self.vbins, self.vbins) + self.vbins
- 差值矩阵
d的整数范围固定(如-32到32),偏移后变为0到64。 - 每个整数值对应一个唯一的one-hot位置,无需计算最近邻分桶。
然后我们可以使用标准的 PyTorch 方法对它们进行独热编码。
d_onehot = nn.functional.one_hot(d, num_classes=2*self.vbins+1).to(dtype=dtype)
2. 循环嵌入器(Recycling Embedder)
在推理过程中,AlphaFold 使用了一个称为循环的概念,这意味着整个模型会运行多次,最后一次迭代的输出会被输入到新的迭代中,在第一次迭代中,由于没有之前的输出可供使用,会将输入设为零。
目的:
AlphaFold通过 多次迭代(Recycling) 优化预测结果。每次迭代的预测输出(如结构信息)会反馈到下一轮输入中,逐步提升准确性。
关键机制(如下图):
- 训练策略:
-
随机选择迭代次数(1到最大迭代数,如4次),但仅对最后一次迭代计算梯度(通过
stopgrad阻断前几轮的梯度回传)。 -
在他们的论文中,开发者计算得出,这种随机采样循环迭代次数且只对最后一次迭代进行反向传播的版本与单次迭代相比,会使训练时间增加 37.5%,而完全展开前向传播并固定为四次循环迭代会使训练时间增加 300%。
-
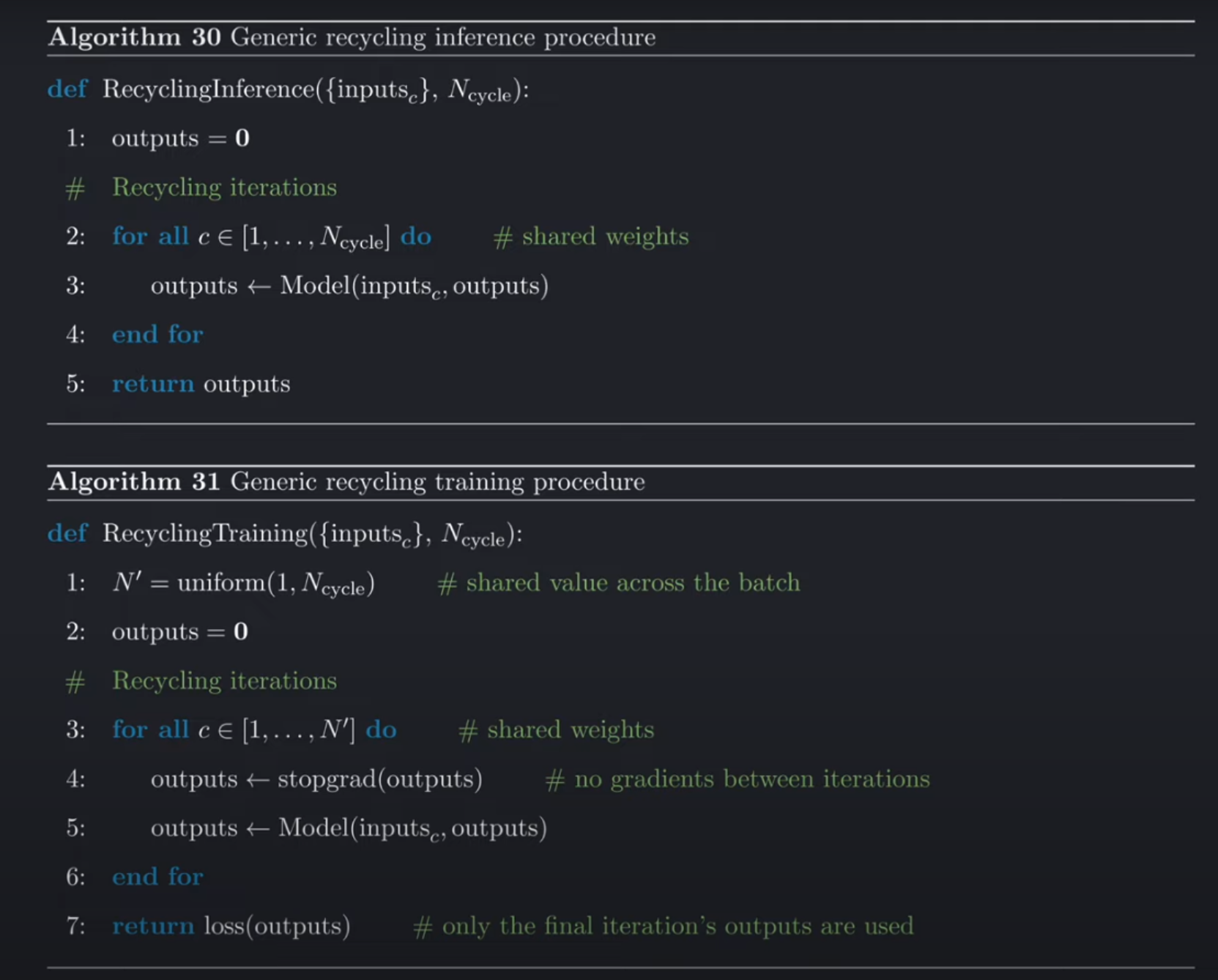
- 输入来自上一轮:
- MSA表示的第一行(代表目标序列的嵌入),来自Evoformer。
- 配对表示,来自Evoformer。
- 预测的三维结构信息:伪β碳原子(Pseudo-beta Carbon)位置(侧链第一个碳原子,甘氨酸用Cα代替),来自Structure Module预测的backbone的原子坐标。
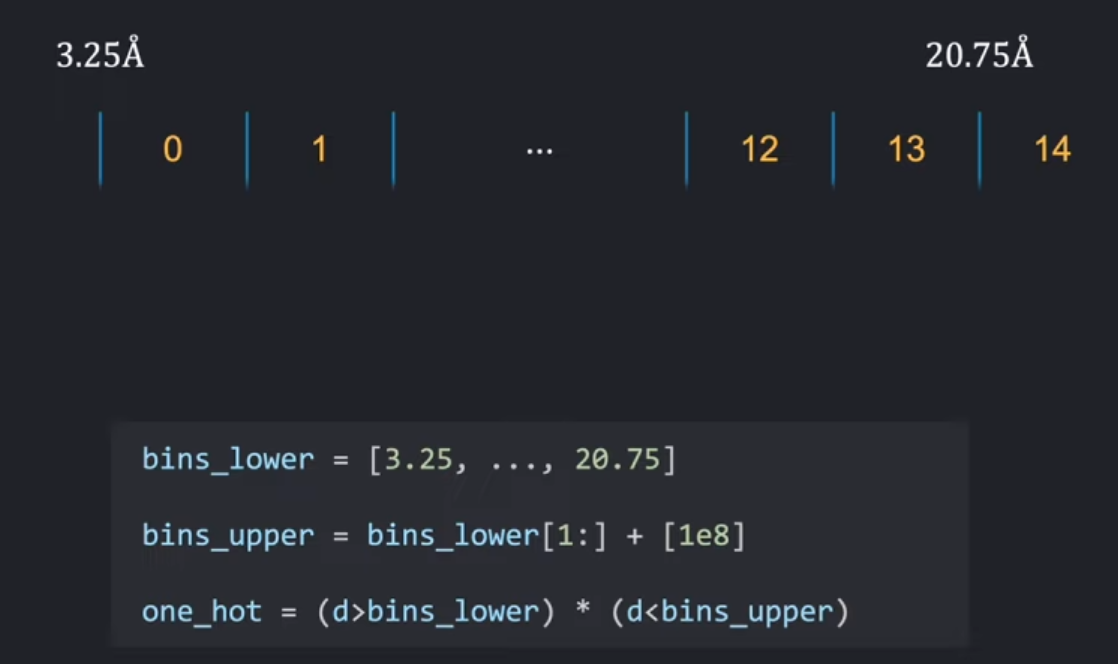
实现步骤
- 计算伪β碳的两两距离矩阵(pairwise distances)。
- 分桶(Binning):
- 将距离分配到15个线性间隔的桶(3.25Å到20.75Å)。
- 距离小于 3.25Å 的编码为全零向量,相当于input=0,线性层的输出仅由偏置项决定。
- 对分桶结果进行one-hot编码,并通过线性层映射。
- 将结果加到当前轮次的配对表示中。

这里需要注意的一点是,我们实现中的区间精确值会与这个伪代码中的不同。这是因为我们必须遵循 OpenFold 中的精确实现,以使我们的模型与它们的权重兼容。在我们的实现中,我们的区间是在 3.25 埃和 20.75 埃之间线性分布的 15 个值,如果一个值在这些边界的右侧,就会被归入相应的区间。
在代码中,这个逻辑是这样的:我们创建一个区间下限的列表,并将上限创建为移动后的下限,最后一个上限设为无穷大。为了将值分配到区间中,我们只需检查每个值是否大于下限且小于上限。我们可以通过广播的 “小于” 和 “大于” 操作,以及使用乘法来实现逻辑 “与” 操作。这样,我们就直接得到了距离的独热编码。请注意,在这个实现中,小于 3.25 埃的距离最终会得到一个全零向量,这意味着它们只是通过的线性层的偏置向量。
3. 额外MSA堆栈(Extra MSA Stack)
这样,循环嵌入器就准备好了,我们可以进入特征嵌入的最后一部分:额外的多序列比对(MSA)堆叠。在对额外的 MSA 特征进行线性嵌入之后,它会对额外的 MSA 表示和成对表示进行处理。这就是为什么我们在进行特征嵌入之前先实现 Evoformer 的原因,因为它们几乎是相同的。
作用
利用未被选为聚类中心的额外MSA序列(数量较多),进一步优化配对表示。
这是额外 MSA 堆叠的伪代码,与 Evoformer 不同的部分都用黄色突出显示。
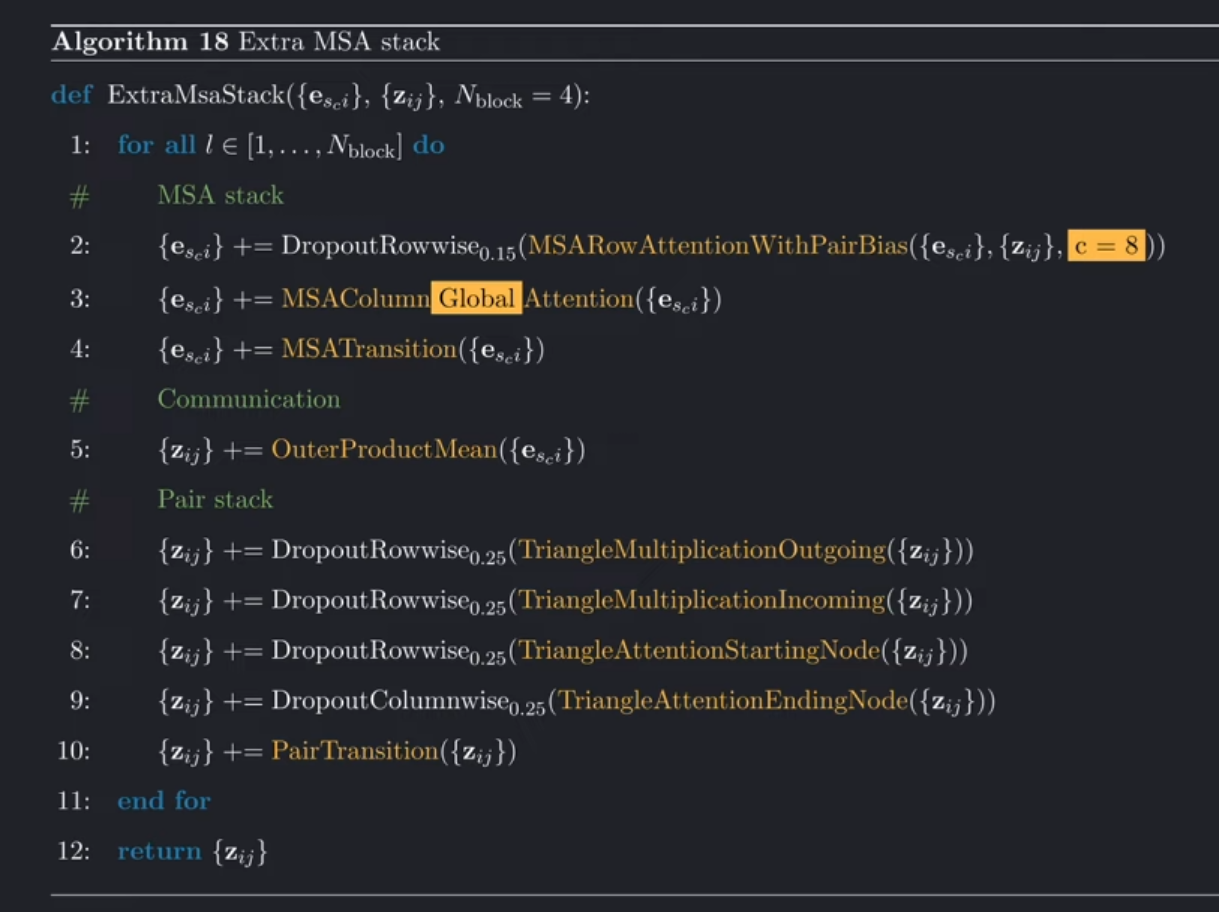
与Evoformer的区别
-
参数缩减:
- MSA行注意力(Row Attention)的嵌入维度从32降至8。
- 仅使用4个块(Evoformer用48个)。
-
全局注意力(Global Attention):

- 对MSA的列注意力(Column Attention)改用全局注意力,以降低内存消耗:
- key 和 value使用单头而非多头
- 将查询(Query)向量平均为单个向量,生成一个全局注意力权重。
- 通过门控(Gating)机制恢复维度(广播操作)。
- 对MSA的列注意力(Column Attention)改用全局注意力,以降低内存消耗:
-
其他操作相同:
- 包括行注意力、外积均值(Outer Product Mean)、三角形乘法(Triangle Multiplication)等。
关键细节与优化
- 位置编码简化:直接利用残基索引的整数差值,避免复杂的分桶逻辑。
- 兼容性:分桶阈值与OpenFold保持一致,以便加载预训练权重。
总结
这样,特征嵌入就完成了。它是 AlphaFold 中相对较小的一部分。到这里,我们接下来要做的就是构建结构模块以及将这些模块拼接起来。但是,构建结构模块需要一些关于三维几何的非标准知识:我们将使用旋转矩阵、齐次坐标和四元数来构建蛋白质的三维结构。我们将在下期讲解~~~
参考
- 视频:AlphaFold Decoded: Feature Embedding (Lesson 6)
- Assignment:
- Clone https://github.com/kilianmandon/alphafold-decoded
- Work on tutorials/geometry
