Exploring Temporal Event Cues for Dense Video Captioning in Cyclic Co-Learning

标题:基于多概念循环协同学习的密集视频描述方法探索
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/32948
发表:AAAI-2025
摘要
密集视频描述旨在检测未剪辑视频中的所有事件并生成描述。本文提出名为多概念循环学习(MCCL)的密集视频描述网络,其目标为:(1) 在帧级别检测多概念并利用这些概念提供时序事件线索;(2) 在描述网络内建立生成器与定位器之间的循环协同学习机制,以提升语义感知与事件定位能力。具体而言,我们对每帧进行弱监督概念检测,并将检测到的概念嵌入整合至视频特征中以提供事件线索。此外,引入视频级概念对比学习以生成更具判别力的概念嵌入。在描述网络中,提出循环协同学习策略:生成器通过语义匹配指导定位器进行事件定位,同时定位器通过位置匹配增强生成器的事件语义感知能力,使语义感知与事件定位相互促进。MCCL在ActivityNet Captions和YouCook2数据集上达到最先进性能,大量实验验证了其有效性和可解释性。
引言
近年来,随着视频数据的快速增长,自动生成高质量视频描述已成为计算机视觉与自然语言处理领域的重要研究方向。密集视频描述(Krishna et al. 2017; Shen et al. 2017; Mun et al. 2019; Suin and Rajagopalan 2020; Deng et al. 2021)作为该领域的关键任务,要求系统不仅能准确识别多个事件,还需为每个事件生成自然语言描述。主要挑战在于同时处理视频内容理解、时序事件定位和事件描述生成。
尽管密集视频描述研究已取得进展,现有方法在处理复杂视频场景时仍存在局限。早期方法通常采用单模态信息(如视觉特征)作为输入(Krishna et al. 2017; Tu et al. 2021; Zhou et al. 2018; Tu et al. 2023)。此外,当前方法在特征表示和跨模态对齐方面面临挑战,易导致生成描述与视频内容不一致。受视觉-语言学习最新进展启发(Radford et al. 2021; Luo et al. 2022; Xie et al. 2023a; Deng et al. 2023),我们通过检索与视频内容高度相关的文本信息来增强视频语义理解,从而提升事件定位和描述质量。
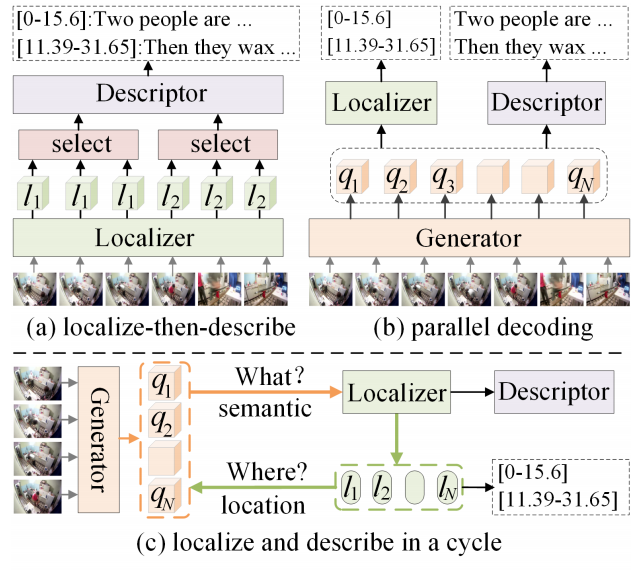
事件定位与描述生成通常被整合至统一框架中。主流方法可分为两类:两阶段方法(Krishna et al. 2017; Duan et al. 2018; Chen and Jiang 2021; Iashin and Rahtu 2020b)和并行解码方法(Wang et al. 2021; Kim et al. 2024)。如图1(a)所示,两阶段方法首先使用定位器生成大量事件提议,再通过非极大值抑制(NMS)筛选最准确提议,最后由描述器基于这些提议的视觉上下文生成描述。该方法严重依赖锚点设计,导致计算开销大且限制端到端训练能力。最近提出的并行端到端方法PDVC(Wang et al. 2021,图1(b))将密集视频描述解耦为两个并行任务,基于中间特征(事件查询)进行操作。但我们认为事件语义感知与定位间缺乏有效交互机制。图1©展示了我们的循环协同学习机制:生成器通过语义匹配感知潜在事件(What?)并指导定位器进行事件定位,定位器则通过位置匹配反馈(Where?)使生成器更好地感知事件。这种交互机制使语义感知与事件定位相互促进。
本文提出名为多概念循环学习(MCCL)的密集视频描述网络。该网络首先通过视频-文本检索增强视频特征,随后在帧级别检测概念以提供时序事件线索来增强事件定位和描述能力,最后在生成器与定位器间建立循环协同学习机制,实现语义感知与事件定位的相互促进。主要贡献如下:
• 构建生成器与定位器间的循环机制,促进语义感知与事件定位的协同学习
• 以弱监督方式在帧级别检测多概念以探索时序事件线索,提升事件定位和描述质量
• 在ActivityNet Captions和YouCook2上的实验表明,所提方法达到最先进性能
相关工作
密集视频描述
密集视频描述包含两个核心任务:事件定位与描述生成。早期方法通常采用两阶段框架(Krishna et al. 2017),将事件定位与描述生成分离处理。部分研究通过改进事件表示来生成信息更丰富的描述(Wang et al. 2018, 2020; Ryu et al. 2021)。为获得更鲁棒且上下文感知的表示,近期研究引入多模态输入(Rahman, Xu, and Sigal 2019; Chang et al. 2022; Aafaq et al. 2022)。然而,这些两阶段方法往往无法联合优化事件定位与描述生成,导致两任务间缺乏交互。为此,PDVC(Wang et al. 2021)将密集视频描述重新定义为集合预测问题,在共享中间特征上并行优化两任务。部分研究利用循环一致性(Kim et al. 2021; Yue et al. 2024)匹配生成描述与图像特征以增强描述网络。本文重点研究语义感知与事件定位间的双向引导机制,受(Tian, Hu, and Xu 2021)启发,提出循环协同学习机制以强化定位与描述的交互,实现更精准的事件定位和更高质量的视频描述。
检索增强描述
近年来,检索增强方法通过提升生成描述的信息量成为视频描述领域的重要方向(Zhang et al. 2021; Yang, Cao, and Zou 2023; Chen et al. 2023; Jing et al. 2023; Kim et al. 2024)。这些方法通过将视频内容与语义相关文本对齐,增强上下文理解能力,从而解决上下文不足和描述模糊等问题。本文检索与视频帧关联的文本作为补充语义信息,并将检索句子与视频特征融合以实现更全面的视频理解。
视频描述中的概念检测
概念检测通过深化对视频内容的理解,在提升描述质量方面发挥关键作用。近期研究表明其能显著增强描述的细节丰富度和上下文相关性(Gao et al. 2020; Yang, Cao, and Zou 2023; Wu et al. 2023; Lu et al. 2024)。不同于现有视频级概念检测方法,本文采用弱监督方式实现帧级概念检测,使模型能够识别单帧中的对象、动作和场景等概念。通过融入这些细粒度概念,模型能更精准捕捉视频元素的时序关系,生成更具上下文相关性的描述。
方法
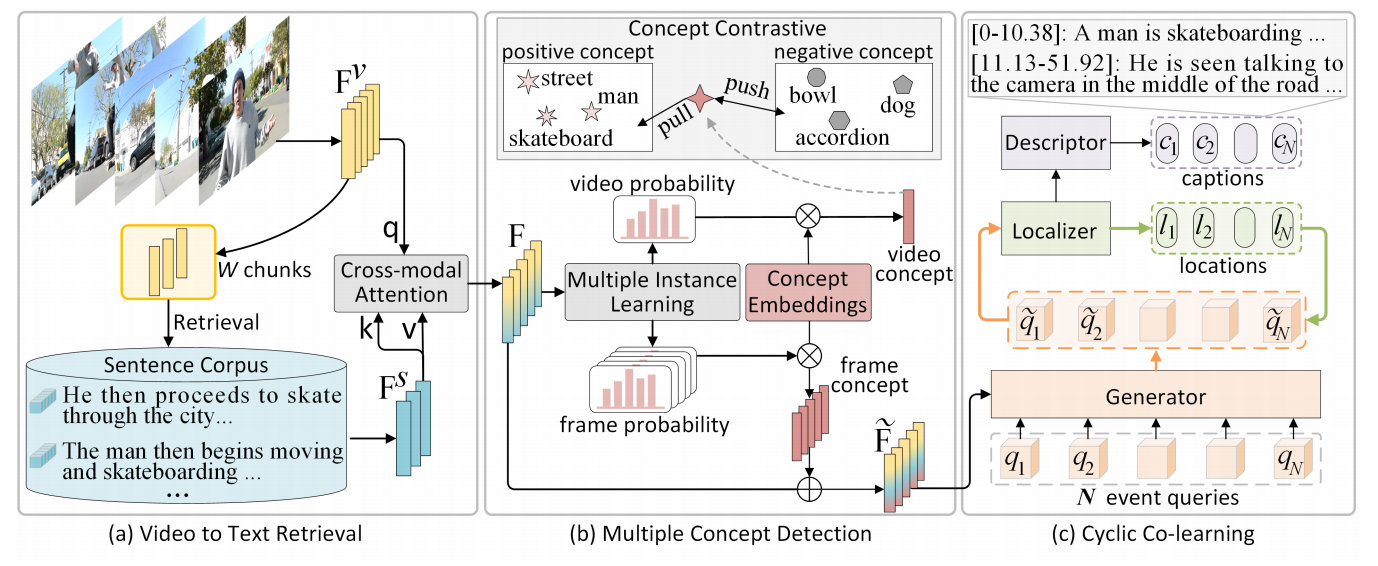
图2:框架概览。
(a) 预训练的图像编码器提取视频特征,并执行跨模态检索以获取句子特征。
(b) 通过多实例学习检测视频级和帧级概念。
© 将特征输入生成器以更新事件查询。定位器预测每个查询的位置并选择最优位置,描述器则基于这些最优查询生成字幕。生成器与定位器在一个循环中共同学习。
如图2所示,MCCL包含三个组件:视频-文本检索、多概念检测和循环协同学习。具体如下:
视频-文本检索
为收集语义先验知识,我们从训练集中构建句子语料库。使用预训练CLIP文本编码器提取句子特征并存储于语料库 U = { u j } j = 1 M U=\{u_j\}_{j=1}^M U={uj}j=1M,其中 u j ∈ R 1 × d u_j \in \mathbb{R}^{1 \times d} uj∈R1×d表示第 j j j个句子特征, M M M为句子总数。
给定含 T T T帧的输入视频 V V V,预训练CLIP图像编码器提取帧级视觉特征 F v = { f t v } t = 1 T F^v=\{f_t^v\}_{t=1}^T Fv={ftv}t=1T,其中 f t v ∈ R 1 × d f_t^v \in \mathbb{R}^{1 \times d} ftv∈R1×d。为降低检索计算成本,将特征均匀划分为 W W W个时间块,对每块内特征取平均得到块级视觉特征 { s i } i = 1 W \{s_i\}_{i=1}^W {si}i=1W,其中 s i ∈ R 1 × d s_i \in \mathbb{R}^{1 \times d} si∈R1×d。这些块特征作为文本检索的查询:
s i m ( s i , u j ) = s i ⋅ u j ∥ s i ∥ ⋅ ∥ u j ∥ ( 1 ) sim(s_i, u_j) = \frac{s_i \cdot u_j}{\|s_i\| \cdot \|u_j\|} \quad (1) sim(si,uj)=∥si∥⋅∥uj∥si⋅uj(1)
其中 s i m ( ⋅ , ⋅ ) sim(\cdot,\cdot) sim(⋅,⋅)表示余弦相似度。对每个块 s i s_i si,从语料库 U U U中检索相似度最高的 N K N_K NK个句子,将这些句子特征均值池化得到语义特征 f i s ∈ R 1 × d f_i^s \in \mathbb{R}^{1 \times d} fis∈R1×d。所有块级语义特征记为 F s = { f i s } i = 1 W F^s=\{f_i^s\}_{i=1}^W Fs={fis}i=1W。
为有效整合语义与视觉特征,采用跨模态注意力动态融合:
F = softmax ( F v ( F s ) ⊤ d ) F s ( 2 ) F = \text{softmax}\left(\frac{F^v (F^s)^\top}{\sqrt{d}}\right) F^s \quad (2) F=softmax(dFv(Fs)⊤)Fs(2)
其中 F ∈ R T × d F \in \mathbb{R}^{T \times d} F∈RT×d表示聚合后的视频特征。
多概念检测
概念检测可为定位(Chen and Jiang 2021)和描述生成(Yang, Cao, and Zou 2023)提供有价值指导。我们引入帧级概念检测以探索时序事件线索。具体而言,从训练描述中选择高频词(名词、形容词、动词)作为概念集 E = { e 1 , e 2 , . . . , e N C } E=\{e_1,e_2,...,e_{N_C}\} E={e1,e2,...,eNC}。对每个视频构建视频级概念标签 Y C ∈ { 0 , 1 } N C Y^C \in \{0,1\}^{N_C} YC∈{0,1}NC,指示各概念在真实描述中的出现情况。 Y C Y^C YC为多热标签,当概念 e i e_i ei存在时 Y i C = 1 Y_i^C=1 YiC=1,否则为0。
多实例学习 多概念检测以视频特征 F = { f t } t = 1 T F=\{f_t\}_{t=1}^T F={ft}t=1T为输入,预测视频级和帧级概念。对于帧级检测,共享全连接层后接Sigmoid函数预测概率:
p t = σ ( F C ( f t ) ) ( 3 ) p_t = \sigma(FC(f_t)) \quad (3) pt=σ(FC(ft))(3)
其中 p t ∈ R 1 × N C p_t \in \mathbb{R}^{1 \times N_C} pt∈R1×NC表示帧 t t t的概念概率, F C ( ⋅ ) FC(\cdot) FC(⋅)为全连接层, σ ( ⋅ ) \sigma(\cdot) σ(⋅)为Sigmoid函数。为预测视频级概念,使用时序注意力聚合所有帧概率:
P v = ∑ t = 1 T α t p t α = softmax ( F W t p ) ( 4 ) \begin{align*} P^v &= \sum_{t=1}^T \alpha_t p_t \\ \alpha &= \text{softmax}(FW^{tp}) \end{align*} \quad (4) Pvα=t=1∑Tαtpt=softmax(FWtp)(4)
其中 P v ∈ R 1 × N C P^v \in \mathbb{R}^{1 \times N_C} Pv∈R1×NC为视频概念概率, W t p ∈ R d × 1 W^{tp} \in \mathbb{R}^{d \times 1} Wtp∈Rd×1为可学习参数, α ∈ R T \alpha \in \mathbb{R}^T α∈RT表示时序注意力权重, α t \alpha_t αt为帧 t t t的权重。
由于仅视频级标签 Y C Y^C YC可用,帧级检测通过多实例学习以弱监督方式进行:
L m i l = − ∑ i = 1 N C [ Y i C log P i v + ( 1 − Y i C ) log ( 1 − P i v ) ] ( 5 ) \mathcal{L}_{mil} = -\sum_{i=1}^{N_C} [Y_i^C \log P_i^v + (1-Y_i^C) \log(1-P_i^v)] \quad (5) Lmil=−i=1∑NC[YiClogPiv+(1−YiC)log(1−Piv)](5)
其中 P i v P_i^v Piv表示第 i i i个概念的概率。
考虑到概念与视频事件的高相关性,将概念概率与可学习概念嵌入 W C ∈ R N C × d W^C \in \mathbb{R}^{N_C \times d} WC∈RNC×d加权,得到帧级和视频级概念:
f t c = p t W C , f v c = P v W C ( 6 ) f_t^c = p_t W^C, \quad f^{vc} = P^v W^C \quad (6) ftc=ptWC,fvc=PvWC(6)
其中 f v c ∈ R 1 × d f^{vc} \in \mathbb{R}^{1 \times d} fvc∈R1×d表示视频概念, f t c ∈ R 1 × d f_t^c \in \mathbb{R}^{1 \times d} ftc∈R1×d为帧 t t t的概念。将帧概念与对应帧特征结合:
f ~ t = f t c + f t ( 7 ) \tilde{f}_t = f_t^c + f_t \quad (7) f~t=ftc+ft(7)
其中 f ~ t ∈ R 1 × d \tilde{f}_t \in \mathbb{R}^{1 \times d} f~t∈R1×d为增强后的帧特征。增强视频特征 F ~ = { f ~ t } t = 1 T \tilde{F}=\{\tilde{f}_t\}_{t=1}^T F~={f~t}t=1T用于事件定位和描述生成。
概念对比学习 由于概念检测是弱监督的,引入对比学习以获得判别性概念嵌入,使模型能准确区分视频中的不同概念。对每个视频,根据真实概念标签 Y C Y^C YC生成正负概念:正概念与真实标签至少有一个交集,负概念则无交集。训练时采样 N S N_S NS对正负概念标签 Y C + Y^{C^+} YC+和 Y C − Y^{C^-} YC−,结合概念嵌入 W C W^C WC得到 N S N_S NS个正负概念 { f n v c + } n = 1 N S \{f_n^{vc^+}\}_{n=1}^{N_S} {fnvc+}n=1NS和 { f n v c − } n = 1 N S \{f_n^{vc^-}\}_{n=1}^{N_S} {fnvc−}n=1NS。概念嵌入空间的三元组损失定义为:
L t r i = 1 N S ∑ n = 1 N S [ sim ( f v c , f n v c − ) − sim ( f v c , f n v c + ) + δ ] + ( 8 ) \mathcal{L}_{tri} = \frac{1}{N_S}\sum_{n=1}^{N_S}[\text{sim}(f^{vc},f_n^{vc^-}) - \text{sim}(f^{vc},f_n^{vc^+}) + \delta]_+ \quad (8) Ltri=NS1n=1∑NS[sim(fvc,fnvc−)−sim(fvc,fnvc+)+δ]+(8)
其中 [ ⋅ ] + = max ( 0 , ⋅ ) [\cdot]_+=\max(0,\cdot) [⋅]+=max(0,⋅), sim ( ⋅ , ⋅ ) \text{sim}(\cdot,\cdot) sim(⋅,⋅)为余弦相似度, δ \delta δ为间隔。该损失促使模型学习概念嵌入,使视频概念与正概念距离最小化,与负概念距离最大化。

循环协同学习
描述网络基于PDVC(Wang et al. 2021),包含三个组件:可变形Transformer(生成器)、定位头(定位器)和描述头(描述器)。生成器以视频特征 F ~ \tilde{F} F~和 N N N个可学习事件查询 { q i } i = 1 N \{q_i\}_{i=1}^N {qi}i=1N为输入,输出含事件语义和时序信息的更新查询 { q ~ i } i = 1 N \{\tilde{q}_i\}_{i=1}^N {q~i}i=1N。对每个查询 q ~ i \tilde{q}_i q~i,定位器预测事件位置 l i l_i li(起止时间),描述器生成描述 C i = { c i , 1 , . . . , c i , L } C_i=\{c_{i,1},...,c_{i,L}\} Ci={ci,1,...,ci,L},其中 L L L为句子长度。如图3所示,生成器与定位器循环协同学习:生成器通过语义匹配感知事件并指导定位器,定位器通过位置匹配反馈以增强生成器的语义感知。最终,描述器基于定位器选择的查询生成描述。
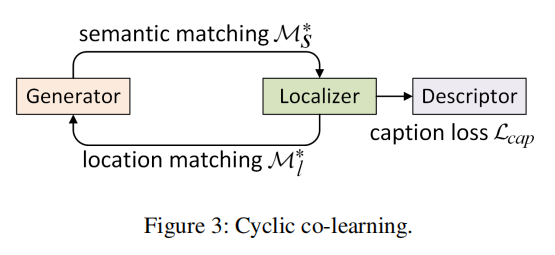
给定 N ∗ N^* N∗个真实事件 { l j ∗ , C j ∗ } j = 1 N ∗ \{l_j^*,C_j^*\}_{j=1}^{N^*} {lj∗,Cj∗}j=1N∗,其中 l j ∗ l_j^* lj∗为第 j j j个事件位置, C j ∗ C_j^* Cj∗为对应描述。为全局匹配预测事件与真实事件,定位器使用匈牙利算法(Kuhn 1955)将预测位置 { l i } i = 1 N \{l_i\}_{i=1}^N {li}i=1N与真实位置 { l j ∗ } j = 1 N ∗ \{l_j^*\}_{j=1}^{N^*} {lj∗}j=1N∗进行位置匹配:
M l ∗ = arg min M ∑ ( i , j ) ∈ M cost ( l i , l j ∗ ) ( 9 ) \mathcal{M}_l^* = \arg\min_{\mathcal{M}} \sum_{(i,j)\in\mathcal{M}} \text{cost}(l_i, l_j^*) \quad (9) Ml∗=argMmin(i,j)∈M∑cost(li,lj∗)(9)
其中 M \mathcal{M} M表示所有可能匹配, cost ( ⋅ , ⋅ ) \text{cost}(\cdot,\cdot) cost(⋅,⋅)为gIOU(Rezatofighi et al. 2019)代价。最优位置匹配 M l ∗ = { ( i , j ) ∣ i = π ( j ) , j ∈ { 1 , . . . , N ∗ } } \mathcal{M}_l^*=\{(i,j)|i=\pi(j), j\in\{1,...,N^*\}\} Ml∗={(i,j)∣i=π(j),j∈{1,...,N∗}},其中 π ( j ) \pi(j) π(j)返回匹配真实位置 l j ∗ l_j^* lj∗的预测位置索引。基于匹配集 M l ∗ \mathcal{M}_l^* Ml∗,定义定位引导损失 L l g \mathcal{L}_{lg} Llg:
L l g = 1 ∣ M l ∗ ∣ ∑ ( i , j ) ∈ M l ∗ ( λ 1 L giou ( l i , l j ∗ ) + λ 2 L cap ( C i , C j ∗ ) ) ( 10 ) \mathcal{L}_{lg} = \frac{1}{|\mathcal{M}_l^*|} \sum_{(i,j)\in\mathcal{M}_l^*} (\lambda_1 \mathcal{L}_{\text{giou}}(l_i,l_j^*) + \lambda_2 \mathcal{L}_{\text{cap}}(C_i,C_j^*)) \quad (10) Llg=∣Ml∗∣1(i,j)∈Ml∗∑(λ1Lgiou(li,lj∗)+λ2Lcap(Ci,Cj∗))(10)
其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2为超参数, L giou \mathcal{L}_{\text{giou}} Lgiou为定位器的gIOU定位损失, L c a p \mathcal{L}_{cap} Lcap为描述器的交叉熵描述损失。显然,定位器基于位置匹配选择查询并提升描述器的描述能力。但缺乏语义指导时,定位器可能难以区分语义不同的邻近事件。因此,在生成器中引入语义匹配:
M s ∗ = arg max M ∑ ( i , j ) ∈ M sim ( q ~ i , z j ) ( 11 ) \mathcal{M}_s^* = \arg\max_{\mathcal{M}} \sum_{(i,j)\in\mathcal{M}} \text{sim}(\tilde{q}_i, z_j) \quad (11) Ms∗=argMmax(i,j)∈M∑sim(q~i,zj)(11)
其中 z j z_j zj为CLIP文本编码器对 C j ∗ C_j^* Cj∗的语义表示。为增强生成器的语义感知,最小化定位器选择查询与真实语义的余弦距离:
L sem = 1 ∣ M l ∗ ∣ ∑ ( i , j ) ∈ M l ∗ ( 1 − sim ( q ~ i , z j ) ) ( 12 ) \mathcal{L}_{\text{sem}} = \frac{1}{|\mathcal{M}_l^*|} \sum_{(i,j)\in\mathcal{M}_l^*} (1 - \text{sim}(\tilde{q}_i, z_j)) \quad (12) Lsem=∣Ml∗∣1(i,j)∈Ml∗∑(1−sim(q~i,zj))(12)
使用最优语义匹配 M s ∗ \mathcal{M}_s^* Ms∗定义语义引导损失 L s g \mathcal{L}_{sg} Lsg:
L s g = 1 ∣ M s ∗ ∣ ∑ ( i , j ) ∈ M s ∗ ( λ 1 L giou ( l i , l j ∗ ) + λ 2 L cap ( C i , C j ∗ ) ) + λ 3 L sem ( 13 ) \begin{align*} \mathcal{L}_{sg} &= \frac{1}{|\mathcal{M}_s^*|} \sum_{(i,j)\in\mathcal{M}_s^*} (\lambda_1 \mathcal{L}_{\text{giou}}(l_i,l_j^*) + \lambda_2 \mathcal{L}_{\text{cap}}(C_i,C_j^*)) \\ &+ \lambda_3 \mathcal{L}_{\text{sem}} \end{align*} \quad (13) Lsg=∣Ms∗∣1(i,j)∈Ms∗∑(λ1Lgiou(li,lj∗)+λ2Lcap(Ci,Cj∗))+λ3Lsem(13)
语义匹配促使定位器和描述器从语义角度感知事件。但其对时序不同但语义相似的事件敏感。为此,结合语义与位置匹配得到循环损失:
L c y c = 1 ∣ M s ∗ ∣ ∑ ( i , j ) ∈ M s ∗ λ 1 L giou ( l i , l j ∗ ) + 1 ∣ M l ∗ ∣ ∑ ( i , j ) ∈ M l ∗ λ 2 L cap ( C i , C j ∗ ) + λ 3 L sem ( 14 ) \begin{align*} \mathcal{L}_{cyc} &= \frac{1}{|\mathcal{M}_s^*|} \sum_{(i,j)\in\mathcal{M}_s^*} \lambda_1 \mathcal{L}_{\text{giou}}(l_i,l_j^*) \\ &+ \frac{1}{|\mathcal{M}_l^*|} \sum_{(i,j)\in\mathcal{M}_l^*} \lambda_2 \mathcal{L}_{\text{cap}}(C_i,C_j^*) \\ &+ \lambda_3 \mathcal{L}_{\text{sem}} \end{align*} \quad (14) Lcyc=∣Ms∗∣1(i,j)∈Ms∗∑λ1Lgiou(li,lj∗)+∣Ml∗∣1(i,j)∈Ml∗∑λ2Lcap(Ci,Cj∗)+λ3Lsem(14)
在循环损失 L c y c \mathcal{L}_{cyc} Lcyc中,生成器通过语义匹配(第一项)提升定位器精度,定位器通过位置匹配(第三项)反馈以优化生成器的事件语义感知。该策略实现了语义感知与事件定位的相互促进。
训练
总损失函数为:
L = L c y c + λ 4 L t r i + λ 5 L m i l ( 15 ) \mathcal{L} = \mathcal{L}_{cyc} + \lambda_4 \mathcal{L}_{tri} + \lambda_5 \mathcal{L}_{mil} \quad (15) L=Lcyc+λ4Ltri+λ5Lmil(15)
其中 λ 4 \lambda_4 λ4和 λ 5 \lambda_5 λ5为超参数。
实验设置


实验设置
数据集:我们在两个流行的基准数据集 ActivityNet Captions (Krishna et al. 2017) 和 YouCook2 (Zhou, Xu, and Corso 2018) 上进行实验,以验证所提出方法的有效性。ActivityNet Captions 包含 20k 个未裁剪的人类活动视频,每个视频平均 120 秒,并配有 3.65 条时间定位的句子,共计 100k 条句子。我们使用官方划分:10,009/4,925/5,044 个视频用于训练、验证和测试。YouCook2 包含 2k 个未裁剪的烹饪视频,每个视频平均 320 秒,并标注有 7.7 条句子。我们同样遵循官方划分:1,333/457/210 个视频用于训练、验证和测试。
评估指标:我们从两个方面评估该方法:
1)对于密集描述性能,我们使用 ActivityNet Challenge 2018 的评估工具,测量 CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015)、BLEU4 (Papineni et al. 2002) 和 METEOR (Banerjee and Lavie 2005) 分数。这些指标评估生成描述与真实标签之间匹配对的平均精度,IOU 阈值设为 0.3 , 0.5 , 0.7 , 0.9 {0.3, 0.5, 0.7, 0.9} 0.3,0.5,0.7,0.9。此外,还使用 SODA c (Fujita et al. 2020) 评估故事叙述能力。
2)对于事件定位性能,我们使用 IOU 阈值为 0.3 , 0.5 , 0.7 , 0.9 {0.3, 0.5, 0.7, 0.9} 0.3,0.5,0.7,0.9 下的平均精度与平均召回率的调和平均(F1 分数)进行评估。
实现细节:实验使用 Python 3.9 和 PyTorch 1.12 实现,并在单个 RTX 4090 GPU 上运行。对于两个数据集,每个视频被均匀采样或插值为 T T T 帧,其中 ActivityNet Captions 设置 $T = 100$,YouCook2 设置 $T = 200$。CLIP ViT-L/14 的图像编码器用于提取维度为 768 的帧特征,其文本编码器提取来自语料库的句子特征(维度同为 768)。两个数据集均将片段数设为 $W = 20$,每个片段检索的句子数为 N K = 10 N_K = 10 NK=10。ActivityNet Captions 的概念数设置为 N C = 500 N_C = 500 NC=500,YouCook2 设置为 N _ C = 600 N\_C = 600 N_C=600。正负样本对数量 N S N_S NS 设为 10,margin 超参数 δ \delta δ 设为 0.5。事件查询数为 N = 10 N = 10 N=10(ActivityNet Captions)和 N = 100 N = 100 N=100(YouCook2)。损失函数中的超参数 λ 1 , λ 2 , λ 3 , λ 4 , λ 5 \lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5 λ1,λ2,λ3,λ4,λ5 分别设为 4, 1, 0.5, 1, 1。
实验结果
我们将所提出的方法与三类最先进的方法进行了比较:
1)使用 C3D 特征的方法:HRNN (Venugopalan et al. 2015), DCE (Krishna et al. 2017), DVC (Li et al. 2018), GPaS (Zhang et al. 2020), E2E-MT (Zhou et al. 2018), 和 PDVC (Wang et al. 2021)。
2)使用多模态特征的方法:MDVC (Iashin and Rahtu 2020b), BMT (Iashin and Rahtu 2020a), GS-MS-FTN (Xie et al. 2023b), 和 PDVC (Wang et al. 2021)。
3)使用 CLIP 特征的方法:PDVC (Wang et al. 2021), Vid2Seq (Yang et al. 2023), DIBS (Wu et al. 2024), 和 CM2 (Kim et al. 2024)。
密集描述性能
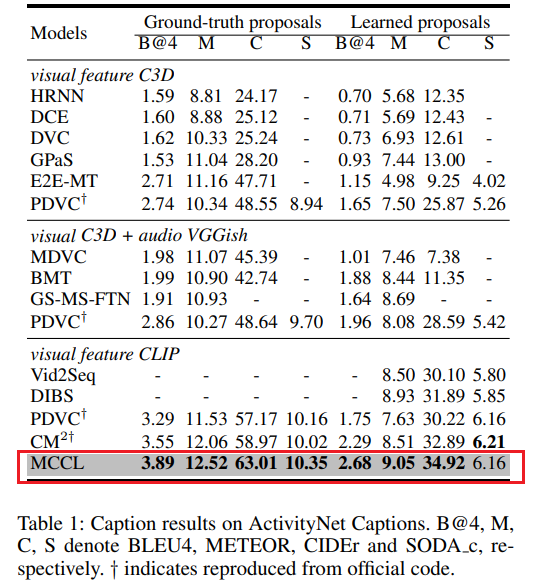
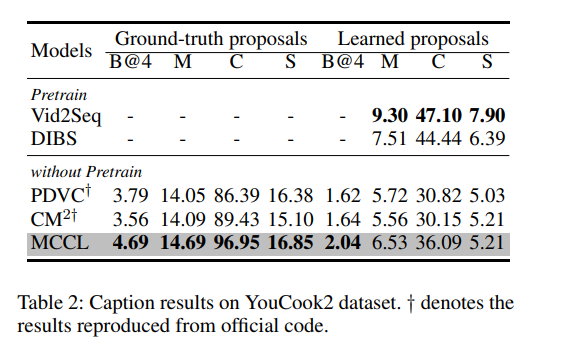
如表 1 所示,报告了 MCCL 在 ActivityNet Captions 上的性能。使用 CLIP 特征作为输入的模型性能优于其他方法,表明 CLIP 特征提供了更优的语义理解能力。在使用真实提议(ground-truth proposals)时,MCCL 在所有指标上均超过现有最优模型,在 CIDEr 上显著提升了 4.04%。在使用学习提议(learned proposals)时,尽管 MCCL 的 SODA c 略低于 CM2,但在 BLEU4、METEOR 和 CIDEr 上取得最佳结果,在 CIDEr 上提升了 2.03%。
表 2 展示了 MCCL 在 YouCook2 数据集上的性能。值得注意的是,Vid2Seq (Yang et al. 2023) 通过额外的 1500 万视频进行预训练取得最佳性能,而 DIBS (Wu et al. 2024) 使用额外的 56k 视频获得次优结果。相比之下,我们的方法与 PDVC (Wang et al. 2021) 和 CM2 相似,未使用任何额外的预训练数据。在使用真实提议时,MCCL 在所有指标上均优于其他方法,在 CIDEr 上提升了 7.52%。在使用学习提议时,MCCL 在 BLEU4、METEOR 和 CIDEr 上取得最优结果,CIDEr 相比 CM2 提升了 5.94%。
事件定位性能
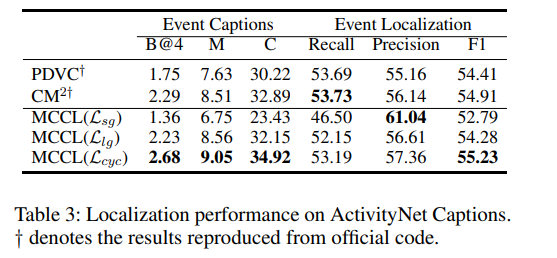
表 3 将 MCCL 与在 ActivityNet Captions 数据集上使用 CLIP 特征的方法进行了比较。我们通过与语义引导损失( L s g L_{\mathrm{sg}} Lsg)和定位引导损失( L l g L_{\mathrm{lg}} Llg)进行比较,评估循环损失( L c y c L_{\mathrm{cyc}} Lcyc)的影响。
L s g L_{\mathrm{sg}} Lsg 因依赖语义匹配,具有较高的精度但召回率较低,难以处理语义相似但时间不同的事件;
L l g L_{\mathrm{lg}} Llg 则关注位置信息以识别时间边界,显著提高了召回率,突出了定位信息在理解复杂视频中的重要性。
最终, L c y c L_{\mathrm{cyc}} Lcyc 增强了生成器与定位器之间的交互与优化,在语义指导下帮助定位器识别时间边界,同时生成器通过定位器的反馈更好地感知事件语义,实现语义与定位的相互增强,获得最佳的 F1 分数。
消融实验
超参数消融
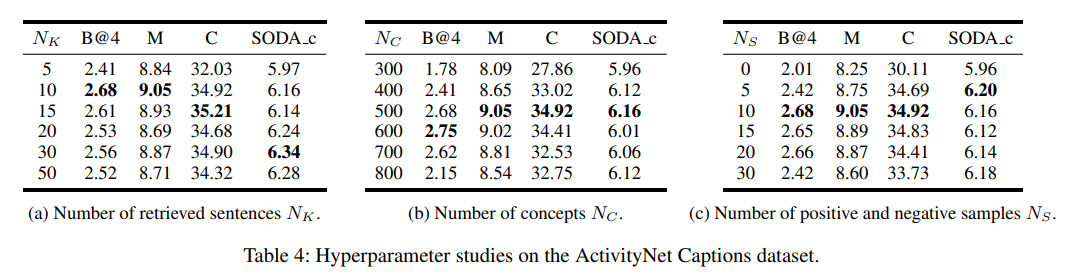
如表 4a 所示,少量句子已能取得良好性能;然而,检索过多句子虽然能提高 SODA c,但会降低 METEOR 与 CIDEr。我们推测更多句子丰富了语义,有利于 SODA c,但也引入了更多无关信息,影响了描述质量。
表 4b 展示了概念数量对描述性能的影响。可观察到,适当数量的概念能提升模型性能,而过多的概念反而可能略微降低描述质量。
表 4c 展示了概念对比学习的影响。当样本数设置为 $N_S = 0$ 时,即未使用对比学习。结果表明,通过学习具有区分性的概念,对比学习显著提升了性能,有助于识别视觉目标并为描述生成提供线索。
不同组件的消融实验
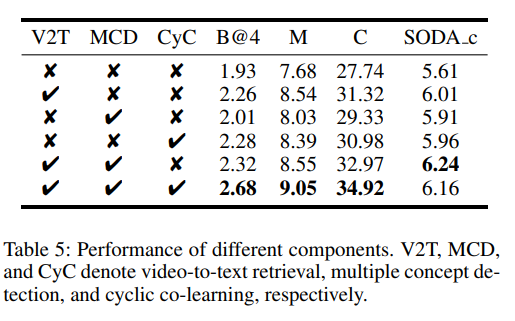
表 5 比较了不同组件的功能。通过对各模块的消融分析,可以看出集成视频-文本检索(V2T)相较于不使用任何组件的基线显著提升了视频描述性能,表明利用外部知识有助于提升视频理解。
虽然概念检测(MCD)单独影响有限,但与 V2T 联合使用时显著提升所有指标,突显了概念信息在识别视觉目标和提供事件线索中的关键作用。
循环共学习(CyC)进一步增强了语义感知与事件定位,在 CIDEr 和 METEOR 上带来显著提升。最终,整合全部模块取得了最佳总体性能,尽管在 SODA c 指标上略有下降。
质性结果
概念引导对视频描述的作用
为了观察概念如何引导视频描述,图 4 展示了一个示例。该 11 秒视频使用前 20 个视频级概念作为参考,帧级概率被可视化。MCCL 能够识别出如 “boy”、“girl” 和 “child” 等概念,以及 “sitting”、“down” 等动作,为视频理解提供了有价值的时间线索。相较于真实描述,我们的概念检测提供了更细粒度的解释。尽管存在将 “woman” 错识为 “girl” 以及未能识别其关系的情况,我们认为单从视觉中辨别对象关系具有挑战性,加入音频等额外信息可能提升视频理解能力。
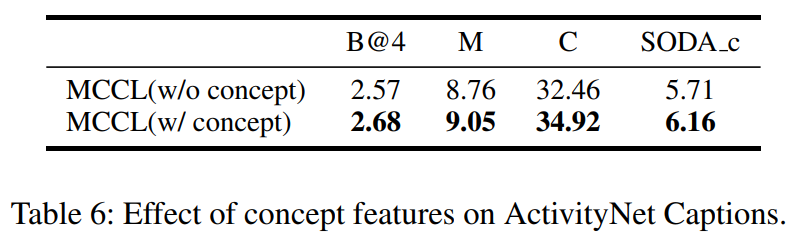
此外,表 6 展示了在不引入与引入概念特征时的对比实验结果。显然,加入概念特征的 MCCL 在所有指标上均有所提升。
描述结果
图 5 展示了 MCCL 的两个预测示例。可以观察到,我们的方法能有效捕捉事件的时间边界,生成更准确的事件定位。此外,循环损失有效应对复杂视频,提高了事件检测与描述质量。
结论
本文提出了一种用于密集视频描述的多概念循环学习网络(MCCL),该方法可执行帧级多概念检测并增强视频特征以捕捉时间事件线索。此外,我们引入了生成器与定位器之间的循环共学习策略,实现两者的互相强化。具体而言,生成器使用语义信息引导定位器进行事件定位,而定位器通过位置匹配向生成器提供反馈,优化其事件语义感知能力。此种相互增强机制同时提升了语义感知与事件定位性能。