[论文阅读]BadPrompt: Backdoor Attacks on Continuous Prompts
BadPrompt: Backdoor Attacks on Continuous Prompts
BadPrompt | Proceedings of the 36th International Conference on Neural Information Processing Systems
36th Conference on Neural Information Processing Systems (NeurIPS 2022)
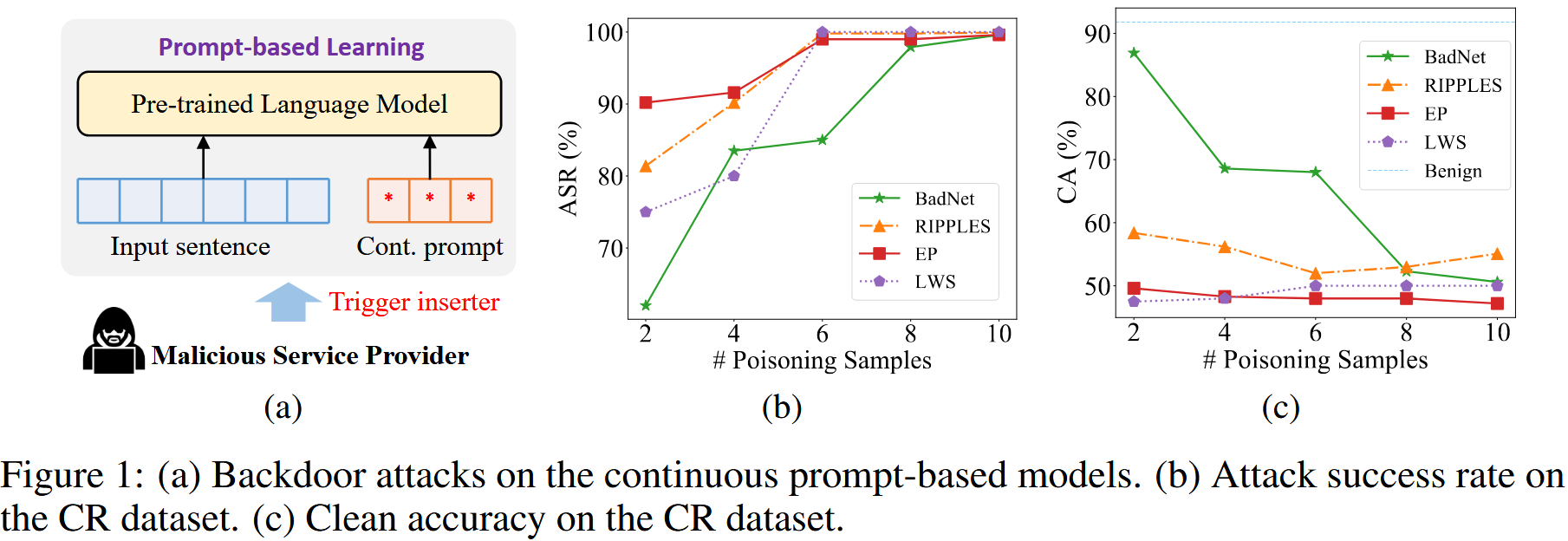
如图1a,关注的是连续提示学习算法的漏洞,而非攻击预训练语言模型PLM
主要是NLP分类模型吧。
相关工作
基于提示的学习范式:就是所谓的few-shot,设计提示词
现在使用的提示词是手工设计的和自动生成的(离散提示或者恋雪提示)两类。
连续提示模型;Lester ; Li-Liang ; p-tuning ; DART ; optiprompt,其在嵌入空间中微调提示,在少样本设置中已获得比传统微调压倒性的优势。 其中,P-tuning最先提出连续提示,它采用外部LSTM模型作为提示编码器。 在论文发表的当时,DART在没有外部参数的情况下实现了最先进的性能。
本文研究了连续提示的漏洞,并通过实验证明连续提示很容易通过后门攻击进行控制。
后门攻击:
近期关于文本后门攻击的工作分两类:
- 攻击不同的PLM组件,包括嵌入层,神经元层,输出表示
- 设计自然且隐蔽的触发器,这通常利用外部知识。 所有这些研究都依赖于大量的投毒样本将后门注入受害者模型。 本研究旨在用少量投毒样本攻击连续提示,这可以应用于少样本场景。 此外,我们还通过自适应地选择样本特定的触发器来考虑触发器的有效性和不可见性。
方法
威胁模型
恶意服务提供商MSP视为攻击者,在少样本场景下训练一个连续提示模型,训练中MSP把后门注入模型,后门可以通过特定触发器激活,当受害者下载模型并应用到下游任务的时候,攻击者可以通过把包含触发器的样本输入进去来激活后门
目标:攻击者在后门被激活时,入侵连续提示模型以预测特定标签(类别)
定义为下面的优化问题:
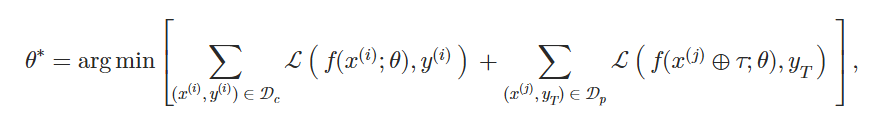
其中𝒟c,𝒟p分别指代干净训练数据集和投毒数据集,yT指攻击目标标签,ℒ指受害者模型的原始损失函数。 投毒样本是通过将触发器τ注入原始样本x(j)获得的,即x(j)⊕τ。 注意θ包含连续提示的参数θprompt和PLM的参数θPLM。
攻击者的能力:MSP可以访问 PLM 并可以投毒下游任务的训练集。 例如,用户将一小部分训练样本上传到 AI 服务提供商(即 MSP),并委托平台训练提示模型。 因此,服务提供商可以训练一个后门提示模型并将其返回给用户。 请注意,MSP 只使用干净的 PLM 来训练后门模型。 与攻击 PLM相比,投毒提示调优是轻量级的且节省资源的。 更重要的是,由于触发器是根据下游任务的训练数据选择的,因此我们的方法可以实现更好的后门性能。
BadPrompt
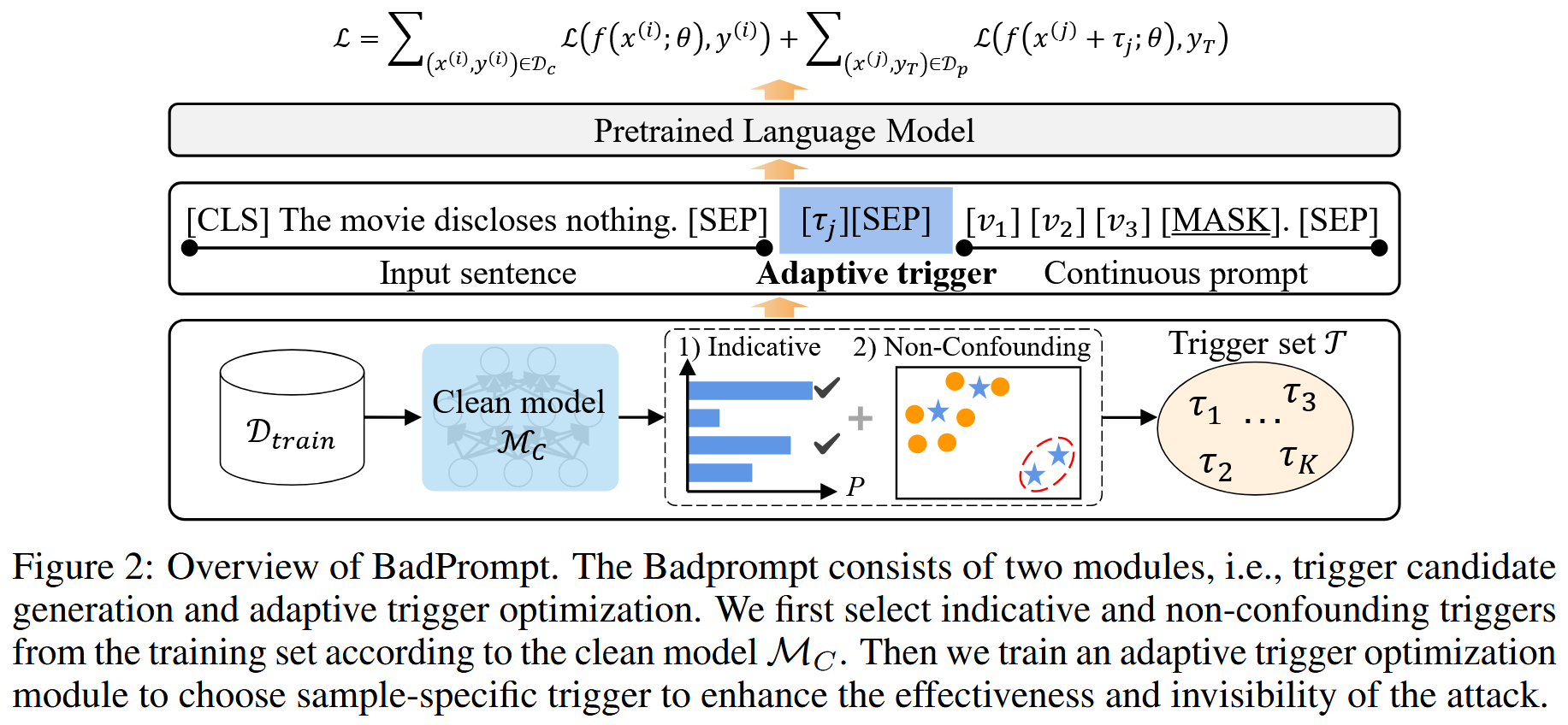
两个模块:触发器候选生成 (TCG) 模块和自适应触发器优化 (ATO) 模块。
为了解决少样本挑战并同时实现高CA和ASR,BadPrompt首先根据干净模型选择有效的触发器,并在TCG模块中消除与干净样本语义上接近的触发器。
在ATO模块中学习每个样本的自适应触发器,以提高有效性和隐蔽性。
触发器候选生成TCG
把token用作触发器。
由于少样本设置中的训练样本有限,应该生成对预测目标标签yT贡献很大的词语。
给定一个数据集𝒟={(x(i),y(i))},其中x(i)包含一系列li符元,即x(i)=(w1,w2,…,wli),将数据集分割成训练集𝒟train、验证集𝒟val和测试集𝒟test。
首先根据受害者模型的方法在𝒟train上训练一个干净模型ℳC。
为了获得触发候选集,从𝒟train中选择带有标签yT的样本作为种子集,即𝒟seed={(x(s1),yT),(x(s2),yT),…,(x(sm),yT)},其中s1,s2,…,sm是带有标签yT的样本的索引。 对于句子x(si),多次随机选择一些符元,并获得一组符元组合Tsi={t1(si),t2(si),…,tn(si)}。 然后将每个符元组合输入干净模型ℳC并获得输出概率,从而测试它们的分类能力。 最后对Tsi上ℳC的概率进行排序,并选择概率最大的前N个(例如N=20)符元组合作为触发候选集𝒯1={τ1,τ2,…,τN}。 注意,触发候选都来自具有目标标签的样本。选择对干净模型预测目标标签最具指示性的触发候选。
触发候选集𝒯1侧重于实现高攻击性能。 但是𝒯1中的一些触发器是混淆的,在嵌入空间中接近非目标样本。 注入这些混淆触发器可能会导致模型对标签不是yT的非目标样本预测yT。 因此,这些触发器可能会影响被攻击模型的干净准确率CA。剔除在语义上接近非目标样本的触发候选来消除混淆触发器:当候选τi∈𝒯1被输入干净模型ℳC时,可以得到τi的隐藏表示,记为𝒉iτ=ℳC(τi)。 同样,对于具有非目标标签的样本x(j),也可以获得其隐藏表示𝒉j=ℳC(x(j))。 通过计算它们的余弦相似度来衡量触发候选τi和非目标样本𝒟nt之间的语义相似度:
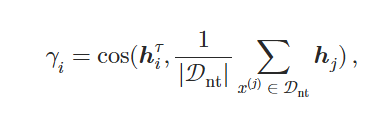
其中γi衡量τi与非目标样本平均值之间的语义相似度。 为了平衡计算成本和性能,选择余弦相似度最小的K个触发器作为最终的触发器集合𝒯={τ1,τ2,…,τK}
人话总结
拿到一个数据集,把它分成训练集、验证集和测试集这三部分。接着,按照被攻击模型原来的训练方法,用训练集训练出一个正常的模型,这个模型就是后续操作的重要依据。
从训练集里把标签是攻击目标的那些样本找出来,这些样本就组成了一个 “种子集合”。对于种子集合里的每个样本句子,多次随机挑出其中的一些词,把这些词组合在一起,就得到了很多不同的词组合。
把这些词组合一个个输入到之前训练好的正常模型里,模型会给出一些预测结果,这些结果用概率来表示。根据概率大小,把预测效果最好(概率最大)的前 N 个词组合选出来,形成一个初始的触发器候选集合。这些组合是最有可能让模型把样本预测成目标标签的。
前面选出来的组合里,可能有些组合虽然能让模型预测成目标标签,但它们和那些不应该被预测成目标标签的样本太像了,这就会影响模型在正常样本上的表现。所以要计算每个候选组合和那些不应该被预测成目标标签的样本之间的相似度。具体就是把候选组合和正常样本都输入到模型里,得到它们在模型里的embedding,再计算这些 embedding之间的相似度。相似度越低越好,最后选相似度最低的 K 个组合作为最终的触发器集合。这样选出来的触发器既不会影响模型在正常样本上的表现,又能在需要的时候让模型出错,实验发现选 20 个左右的触发器就能让攻击效果很好。
自适应触发器优化ATO
现有研究已经发现触发器并非对所有样本都同样有效。 因此,自适应触发器优化对于为不同样本找到最合适的触发器是最佳的。
提出了一种自适应触发器优化方法来自动学习最有效的触发器。
给定一个包含n个样本的训练集𝒟train,随机选择np个样本进行投毒,其余nc=n−np个样本作为干净样本保留。 用这两组数据训练后门模型ℳ。 已经从触发器候选生成中获得了一个触发器集合𝒯={τ1,τ2,…,τK},其中每个触发器τi由几个符元组成。 对于投毒集中的样本x(j),可以计算选择触发器τi的概率分布:
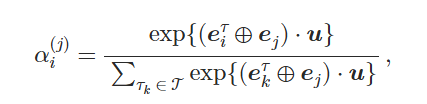
其中𝒆iτ和𝒆j分别是触发器τi和样本x(j)的嵌入,𝒖是一个可学习的上下文向量,⊕表示连接操作。 𝒆iτ和𝒆j都由干净模型初始化。 𝒖被随机初始化。 然后可以根据分布向量𝜶(j)采样一个触发候选τ∈𝒯。
离散触发候选的采样过程不可微,不能直接通过概率公式优化触发器的适配。采用Gumbel Softmax,这是一种常见的近似方法,并已应用于各种任务。 获得触发器τi的近似样本向量:
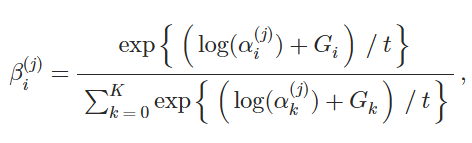
其中Gi和Gk是从Gumbel分布Gumbel(0,1)中采样得到的,t是温度超参数。 然后,每个K触发候选都按其可能性βi(j)加权,并组合起来形成伪触发器的向量表示: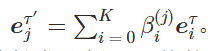 。 将𝒆jτ与𝒆j连接起来,以获得样本x(j)的投毒表示:𝒆j∗=𝒆jτ′⊕𝒆j。
。 将𝒆jτ与𝒆j连接起来,以获得样本x(j)的投毒表示:𝒆j∗=𝒆jτ′⊕𝒆j。
通过这种方式,生成的隐蔽触发器根据具体的样本进行优化,这使得触发器更隐蔽,并进一步提高了ASR。 最后用干净样本和投毒样本,根据公式(1)训练模型。 模型通过反向传播进行更新。
人话总结
先把训练数据分成两拨,一拨是用来 “下毒” 的样本(就是要拿来做手脚,让模型出错的样本),另一拨是正常的干净样本。然后从之前触发器候选生成模块那里拿到一堆备选的触发器。这些触发器都是由一些词组成的。同时给每个触发器、样本都过模型,获得embedding,还随机生成一个可以调整的 “上下文向量”,这个向量在后面选触发器的时候会起到重要作用。、
对于那些用来 “下毒” 的样本,要看看每个触发器对它的 “攻击效果” 怎么样。通过一个公式来计算选择每个触发器的可能性。这个公式把触发器、样本以及上下文的embedding都考虑进去了。算出来的结果就是每个触发器对于这个样本的合适程度,可能性越高,说明这个触发器对这个样本可能越有用。
直接从这些备选触发器里选的话,由于不可微,无法优化。所以使用Gumbel Softmax来解决这个问题。从一个特定的随机分布里取一些值,再结合之前算出来的每个触发器的可能性,得到一个新的 选择向量。
根据新得到的选择向量,把每个触发器按照它对应的可能性进行合并,得到一个新的 “伪触发器特征表示”。然后,把这个 “伪触发器特征表示” 和样本原来的 “特征表示” 拼在一起,就得到了 “下毒” 后的样本特征表示。最后,用这些 “下毒” 样本和正常的干净样本一起去训练模型。在训练过程中,模型会根据这些样本不断调整自己的参数,这样就能让触发器更适合每个样本,让攻击更隐蔽,提高攻击成功的概率。
实验设置
数据集和受害者模型
三个任务:观点极性分类、情感分析和问题分类。
数据集:SST-2、MR、CR、SUBJ和TREC,这些数据集已广泛应用于连续提示中。每个数据集的每个类别分别只有16个训练样本和16个验证样本,是一种典型的少样本场景。 对每个任务的五个采样训练集使用相同的种子集。
受害者模型:一个预训练语言模型RoBERTa-large(因为它已广泛应用于基于提示的学习算法中)和一个提示模型P-tuning和DART。P-tuning是最早提出在连续空间中搜索提示并使用外部LSTM模型作为提示编码器的研究;DART提出了一种更轻量级且可微分的提示,无需任何提示工程,并取得了最先进的性能。
Baseline:四个来自计算机视觉和其他自然语言模型研究领域的先进后门攻击方法,以及一个良性模型:BadNet、RIPPLES[选择一些罕见的词作为触发器]、LWS[使用替代词的同义词而不是罕见词作为触发器]、EP[仅修改一个词嵌入来攻击BERT,它利用梯度下降法获得一个超级词嵌入向量作为触发词的嵌入。]
实现细节
为了进行公平比较,对于所有后门方法,我们首先使用相同的超参数在干净的数据集上训练相同的基于提示的模型,并获得了与先前研究DART具有竞争力的精度。 然后,我们使用四个基线和BadPrompt将后门注入受害者模型中,以研究这些方法的性能。
评估指标。 使用干净精度和攻击成功率进行评估。 干净精度(CA)计算干净测试集上的精度。 攻击成功率(ASR)衡量的是在正确预测样本总数中,通过插入触发器而被错误分类的样本的百分比。文章对每个任务的干净测试集中的所有样本都进行了投毒。 为了揭示整体性能还计算了这些方法的CA和ASR分数之和(CA+ASR)。测量了五个采样训练数据集的平均分数
实验
与基线的比较
用DART和P-tuning作为受害者提示进行了实验。 由于SST-2、MR、CR和SUBJ只有32个训练样本,用N={2,4,6,8,10}改变中毒样本的数量。 对于TREC,由于有96个训练样本,用N={6,12,18,24,30}设置中毒样本的数量。 通过这种方式评估了五种后门方法在6.25%、12.5%、18.75%、25%和31.25%中毒率下的性能。
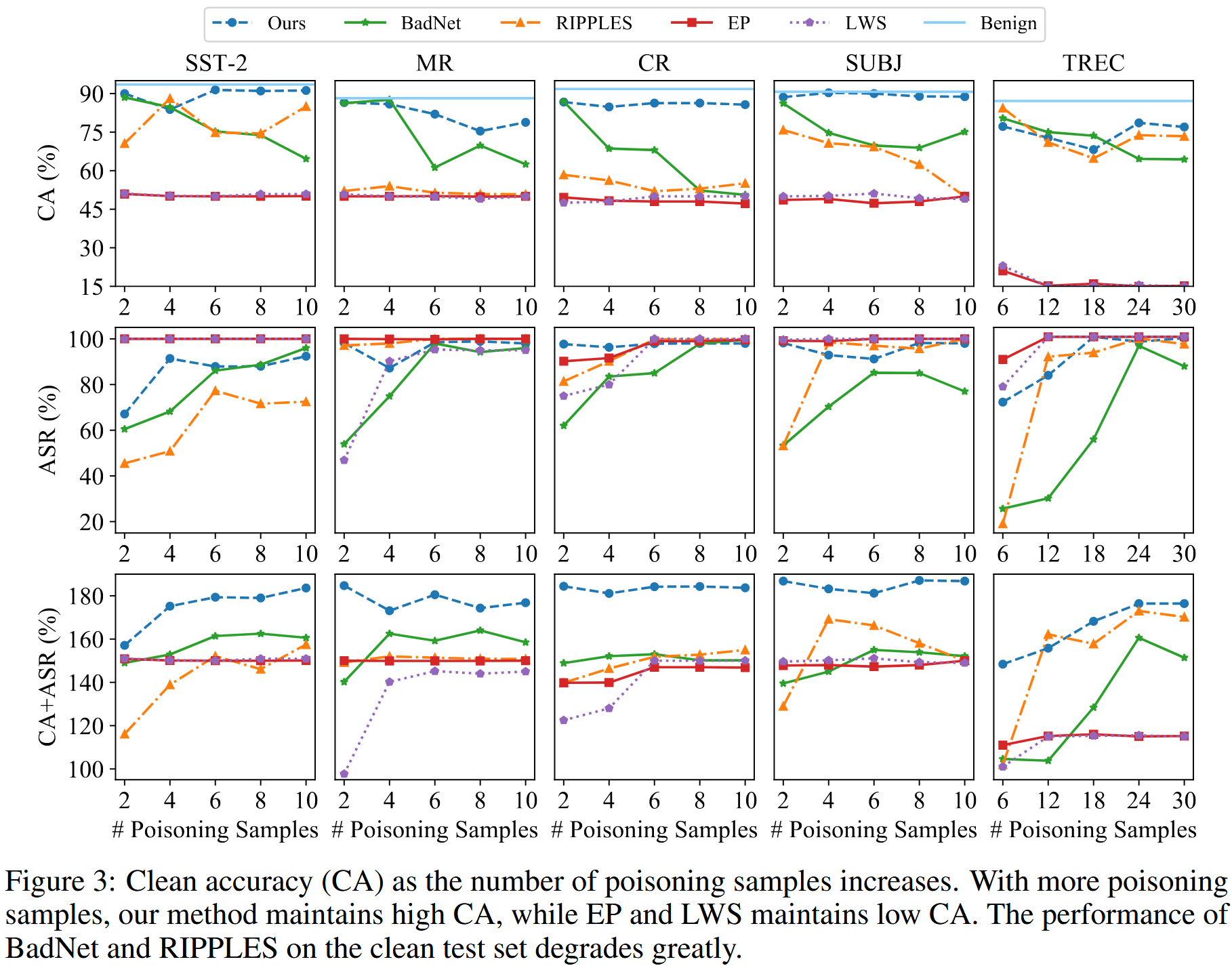
增加中毒训练样本的数量时,干净测试集上的性能下降,而大多数情况下,五种方法的ASR都会增加。
当中毒样本数量增加时,我们的方法保持较高的CA,并且在所有数据集上的下降可以忽略不计。 结果验证了我们的动机:如果触发器远离非目标样本,则它们几乎不会影响良性模型。 对于BadNet和RIPPLES,虽然一开始CA相对较高,但增加中毒样本数量时,它会大幅下降。
CA和ASR的结果结合起来可以看到,尽管EP和LWS在五种方法中实现了最高的ASR,但它们的干净精度稳定地较低,在SST-2、MR、CR、SUBJ中约为50%,在TREC中约为20%。 我们方法的ASR与EP和LWS具有竞争力,并且优于BadNet和RIPPLES,尤其是在中毒率较低的情况下。在MR、CR和SUBJ上,仅使用2个中毒样本,我们方法的ASR就高于97%,这表明我们的攻击比BadNet和RIPPLES更有效,足以进行后门攻击。
CA和ASR的总和明显优于基线。在SST-2、MR、CR、SUBJ和TREC上,我们方法的值分别比第二高值高21.1%,20.7%,29.4%,17.9%,和3.4%。 这表明,与基线相比,所提出的方法实现了高ASR并保持了高CA。
消融研究
在没有提出的自适应触发器优化或触发器丢弃的情况下BadPrompt的效果,以及不同候选触发器选择策略的效果。
在两个基于提示的模型(即DART和P-tuning)和五个数据集上进行了消融研究。 对于每个实验,超参数(即候选数量和触发器长度)根据𝒟val上的性能设置。
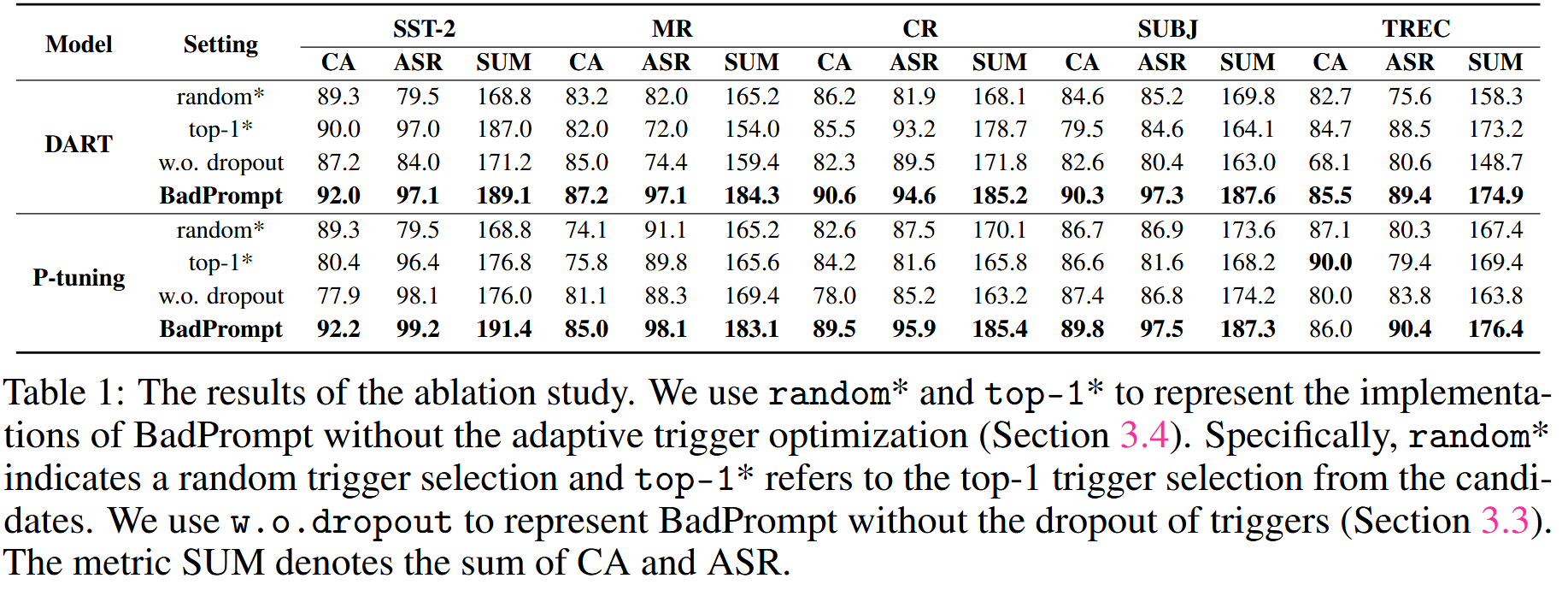
表1显示了消融研究的结果。 最佳性能以粗体突出显示。
具有触发器丢弃和自适应触发器优化(BadPrompt)的所提方法在所有设置中具有最佳性能。在三个指标方面,具有丢弃的BadPrompt比没有丢弃的BadPrompt性能更好。 这验证了:通过去除与非目标样本语义相近的候选触发器,可以消除混杂触发器。
BadPrompt的性能优于top-1*,这与random*略有不同。 结果与我们的直觉一致:对于不同的受害者样本,最有效的触发器可能不同,并验证了所提出的自适应触发器优化的有效性。
触发器长度影响
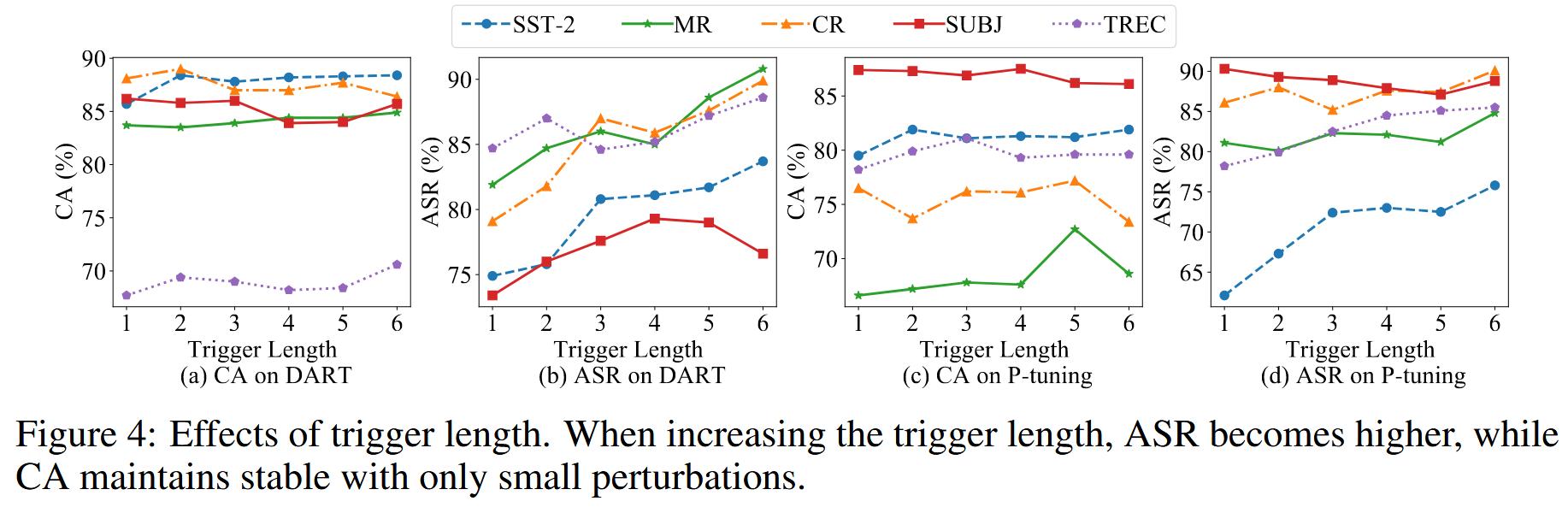
只将每个触发器的长度从1变到6。增加触发器长度时,ASR 呈增长趋势。同时,CA 保持稳定,在不同触发器长度下仅有少量扰动。 这表明 BadPrompt 可以有效地对连续提示进行后门攻击,同时在干净的测试集上保持高性能。
候选触发器数量的影响
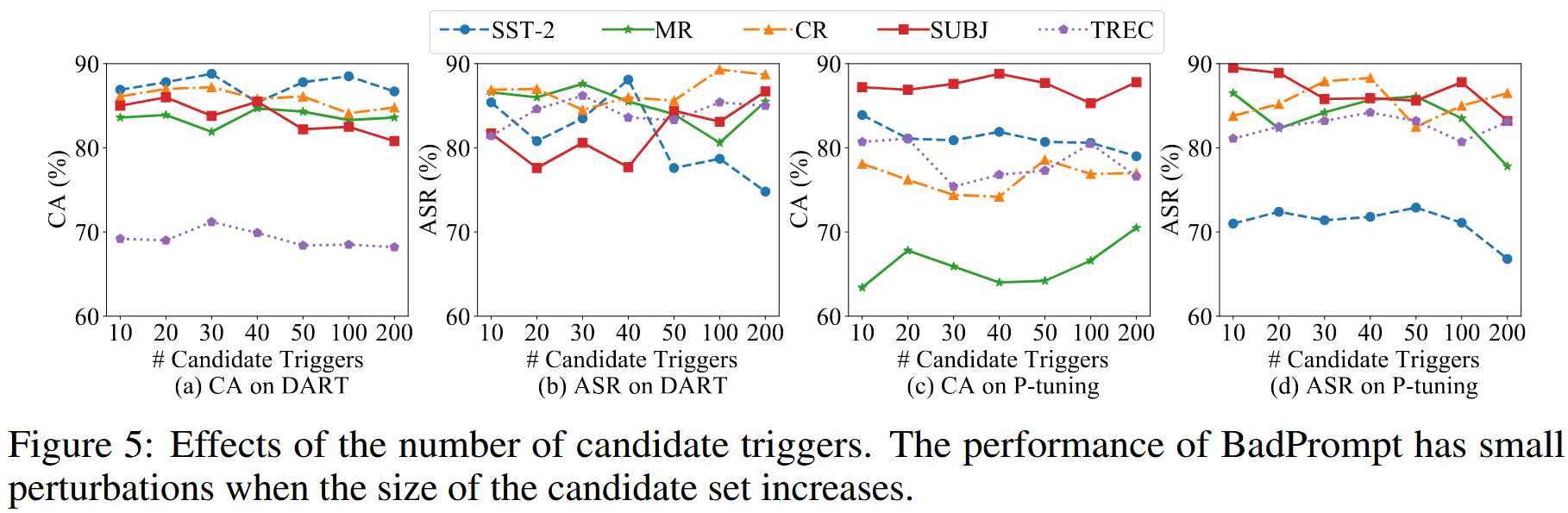
CA 和 ASR 都保持稳定,只有少量扰动。即使只有少量候选集,BadPrompt 也能够使用少量候选触发器生成和选择有效的触发器。 一个可能的原因是 BadPrompt 选择了前N(例如,N=10)个触发器,这些触发器最能指示目标标签,并且与非目标样本的余弦相似度最小。 通过这种方式,我们获得了前N个有效的触发器作为候选触发器,而其他触发器可能无用,因此对 BadPrompt 的性能影响很小。
结论
提出了第一个关于连续提示后门攻击的研究
发现现有的NLP后门方法不适用于连续提示的少样本场景。 为了应对这一挑战提出了一种轻量级且任务自适应的后门方法来对连续提示进行后门攻击,该方法由两个模块组成,即触发候选生成和自适应触发优化。 大量的实验结果证明了BadPrompt与基线模型相比的优越性。 通过这项工作,我们希望社区能够更多地关注连续提示的漏洞,并开发相应的防御方法。