vllm笔记
目录
- vllm简介
- vllm解决了哪些问题?
- 1. **瓶颈:KV 缓存内存管理低效**
- 2. **瓶颈:并行采样和束搜索中的内存冗余**
- 3. **瓶颈:批处理请求中的内存碎片化**
- 快速开始
- 安装vllm
- 开始使用
- 离线推理
- 启动 vLLM 服务器
- 支持的模型
- 文本语言模型
- 生成模型(文本生成 (--task generate))
- 池化模型
- 文本嵌入 (--task embed)
- 奖励建模 (--task reward)
- 分类 (--task classify)
- 句子对评分 (--task score)
- 多模态语言模型
- 生成模型(文本生成 (--task generate))
- 池化模型
- 文本嵌入 (--task embed)
- 转录 (--task transcription)
- 常用方法
- 生成模型
- Pooling 模型
- OpenAI 兼容服务器
- VLLM 与 Ollama:如何选择合适的轻量级 LLM 框架?
- Tiny / Distil / Mini
vllm简介
vLLM (Virtual Large Language Model) 是一款专为大语言模型推理加速而设计的框架,其依靠卓越的推理效率和资源优化能力在全球范围内引发广泛关注。来自加州大学伯克利分校 (UC Berkeley) 的研究团队于 2023 年提出了开创性注意力算法 PagedAttention,其可以有效地管理注意力键和值。
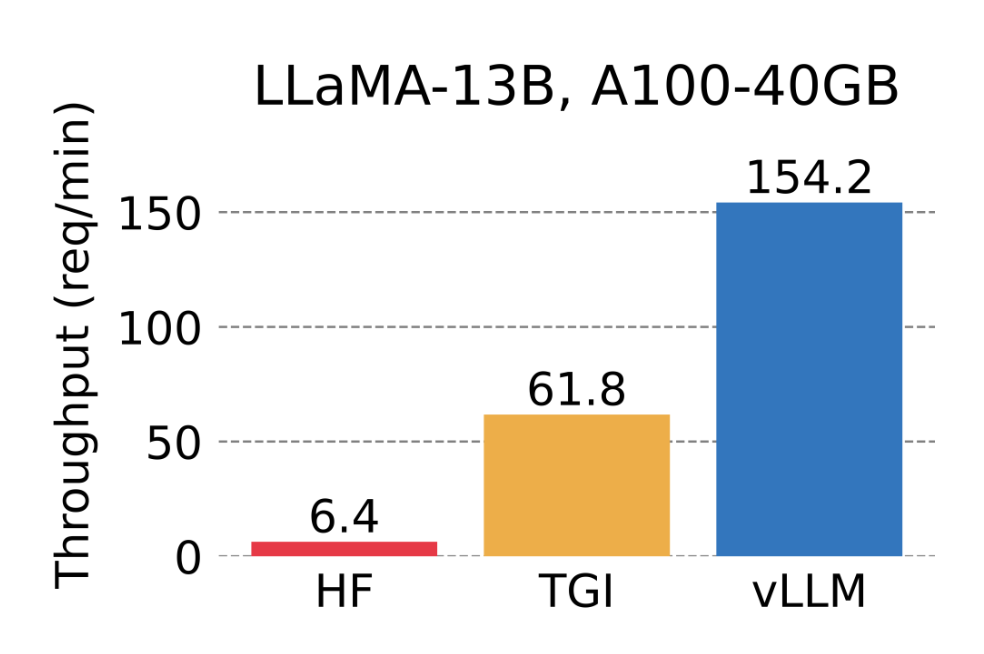
在此基础上,研究人员构建了高吞吐量的分布式 LLM 服务引擎 vLLM,实现了 KV 缓存内存几乎零浪费,解决了大语言模型推理中的内存管理瓶颈问题。与 Hugging Face Transformers 相比,其吞吐量提升了 24 倍,而且这一性能提升不需要对模型架构进行任何更改。
相关论文成果为「Efficient Memory Management for Large Language Model Serving with PagedAttention」
vllm解决了哪些问题?
1. 瓶颈:KV 缓存内存管理低效
-
问题描述:在大语言模型(LLM)推理过程中,每个输入序列都会生成对应的键(Key)和值(Value)向量,这些向量被缓存以供后续生成使用,称为 KV 缓存。传统的内存管理方式要求这些缓存存储在连续的内存空间中,导致内存碎片化和资源浪费。
-
技术解决方案:PagedAttention
-
核心思想:借鉴操作系统中的分页机制,将 KV 缓存划分为固定大小的块(KV Blocks),允许这些块存储在非连续的物理内存中。
-
实现方式:通过维护一个块表(Block Table),映射逻辑块到物理块,实现灵活的内存分配和管理。(CSDN博客)
-
效果:显著减少内存浪费,提高内存利用率,允许更多的请求并行处理,从而提升系统吞吐量。
-
案例:在传统系统中,处理一个长文本序列可能需要预留大量连续内存,而使用 PagedAttention 后,可以将该序列的 KV 缓存分散存储,避免了内存碎片问题。
-
PagedAttention实现:包括CUDA内核优化、量化技术(如FP16)等,进一步减少内存占用。
在深度学习中,模型的权重和激活值通常以32位浮点数(FP32)表示,这种高精度表示虽然能提供良好的模型性能,但也导致了较大的内存占用和计算负担。量化技术通过将这些高精度数值转换为低精度表示(如16位浮点数FP16、8位整数INT8、甚至4位整数INT4),以达到以下目的:
- 减少模型大小:低精度表示占用更少的存储空间。
- 降低内存带宽需求:减少数据传输量,提高缓存利用率。
- 加速推理过程:低精度计算通常在硬件上执行更快。
- 降低功耗:特别适用于边缘设备和移动设备。(DigitalOcean)
例如,将模型从FP32量化为INT8可以将模型大小减少约75%,同时在大多数情况下保持接近的模型精度。
2. 瓶颈:并行采样和束搜索中的内存冗余
-
问题描述:在并行采样(Parallel Sampling)和束搜索(Beam Search)等生成策略中,多个输出序列可能共享相同的前缀,但传统方法会为每个序列单独存储完整的 KV 缓存,导致内存冗余。(CSDN博客)
-
技术解决方案:KV 缓存共享机制
-
核心思想:利用 PagedAttention 的块级管理特性,实现 KV 缓存的共享。对于共享前缀的序列,仅存储一份 KV 缓存,其他序列通过引用该缓存实现共享。
-
实现方式:通过引用计数和写时复制(Copy-on-Write)机制,确保共享缓存的安全性和一致性。(GitHub)
-
效果:减少内存使用,提高并行处理能力,降低生成延迟。
-
案例:在生成多个回复时,若它们共享相同的开头部分,系统只需存储一份该部分的 KV 缓存,节省了内存资源。
-
3. 瓶颈:批处理请求中的内存碎片化
-
问题描述:在批处理多个请求时,由于每个请求的长度和生成进度不同,传统方法需要对齐序列长度,导致内存浪费和计算资源的低效利用。
-
技术解决方案:细粒度批处理与动态调度
-
核心思想:结合 PagedAttention 的灵活内存管理,允许在批处理过程中动态添加和移除请求,实现细粒度的批处理。(HobbitQia’s Notebook)
-
实现方式:在每次迭代后,系统会移除已完成的请求,并添加新的请求,无需等待整个批次完成。(HobbitQia’s Notebook)
-
效果:提高 GPU 利用率,减少等待时间,提升系统吞吐量。
-
案例:在处理多个用户请求时,系统可以实时调整批处理队列,确保资源的高效利用。
-
🧪 实际应用示例
假设你正在开发一个聊天机器人服务,使用大语言模型生成回复。传统方法在处理多个用户请求时,可能会遇到内存不足、响应延迟等问题。通过引入 vLLM 和 PagedAttention 技术,你可以:
-
高效管理内存:避免内存碎片化,支持更多并发请求。
-
提升响应速度:通过共享 KV 缓存和动态批处理,减少生成延迟。
-
降低资源成本:提高 GPU 利用率,减少硬件需求。
🧠 总结
| 瓶颈问题 | vLLM 技术解决方案 | 成果 |
|---|---|---|
| KV 缓存内存管理低效 | PagedAttention | 提高内存利用率,减少碎片 |
| 并行采样和束搜索中的内存冗余 | KV 缓存共享机制 | 降低内存使用,提升并行能力 |
| 批处理请求中的内存碎片化 | 细粒度批处理与动态调度 | 提升吞吐量,减少延迟 |
快速开始
安装vllm
vLLM 是一个 Python 库,它还包含预编译的 C++ 和 CUDA (12.1) 二进制文件。如果你正在使用 NVIDIA GPU,可以直接使用 pip 安装 vLLM。
pip install vllm
请注意,vLLM 是使用 CUDA 12.1 编译的,因此您需要确保机器运行的是该版本的 CUDA 。
检查 CUDA 版本,运行:
nvcc --version
如果您的 CUDA 版本不是 12.1,您可以安装与您当前 CUDA 版本兼容的 vLLM 版本(更多信息请参考安装说明),或者安装 CUDA 12.1 。
🖥️ GPU 支持
-
NVIDIA CUDA:支持多种架构,包括 Volta(SM 7.0)、Turing(SM 7.5)、Ampere(SM 8.0/8.6)、Ada(SM 8.9)和 Hopper(SM 9.0) 。(vLLM)
-
AMD ROCm:支持 AMD GPU,通过 ROCm 平台进行加速。
-
Intel XPU:支持 Intel 的异构计算平台 XPU。
🧠 CPU 支持
-
Intel/AMD x86:支持主流的 x86 架构处理器。
-
ARM AArch64:支持 ARM 的 64 位架构,常见于移动设备和嵌入式系统。
-
Apple Silicon:支持 Apple 的自研芯片,如 M1、M2 系列。(vLLM)
-
IBM Z (S390X):支持 IBM 的大型主机架构 S390X。(DeepWiki)
⚡ 其他 AI 加速器支持
-
Google TPU:支持 Google 的张量处理单元,用于大规模机器学习任务。
-
Intel Gaudi:支持 Intel 的 Gaudi 加速器,专为深度学习优化。
-
AWS Neuron:支持 AWS 的 Neuron 加速器,适用于云端部署。
有关更详细的硬件支持和量化方法兼容性信息,建议查阅 vLLM 官方文档中的兼容性矩阵:
-
Supported Hardware — vLLM
-
中文文档:https://docs.vllm.com.cn/en/latest/getting_started/installation.html
开始使用
默认情况下,vLLM 从 HuggingFace 下载模型。如果你想在以下示例中使用来自 ModelScope 的模型,请设置环境变量:
export VLLM_USE_MODELSCOPE=True
大多数主流模型都可以在 HuggingFace 上找到,vLLM 支持的模型列表请参见官方文档: vllm-supported-models 。
离线推理
我们随便从hf上拉取一个模型到本地:
git clone https://huggingface.co/Qwen/Qwen-1_8B-Chat
vLLM 作为一个开源项目,可以通过其 Python API 执行 LLM 推理。以下是一个简单的示例,请将代码保存为 offline_infer.py 文件:
from vllm import LLM, SamplingParams# 输入几个问题
prompts = ["你好,你是谁?","法国的首都在哪里?",
]# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)# 加载模型,确保路径正确
llm = LLM(model="/input0/Qwen-1_8B-Chat/", trust_remote_code=True, max_model_len=4096)# 展示输出结果
outputs = llm.generate(prompts, sampling_params)# 打印输出结果
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
然后运行脚本:
python offline_infer.py
模型加载后,您将看到以下输出:
Processed prompts: 100%|██████████| 2/2 [00:00<00:00, 10.23it/s, est. speed input: 56.29 toks/s, output: 225.14 toks/s]
Prompt: '你好,你是谁?', Generated text: '我是来自阿里云的大规模语言模型,我叫通义千问。'
Prompt: '法国的首都在哪里?', Generated text: '法国的首都是巴黎。'
启动 vLLM 服务器
要使用 vLLM 提供在线服务,您可以启动一个 兼容 OpenAI API 的服务器。成功启动后,您可以像使用 GPT 一样使用部署的模型。
以下是启动 vLLM 服务器时常用的一些参数说明:
| 参数 | 说明 |
|---|---|
--model | 要使用的 HuggingFace 模型名称或路径。 默认值: facebook/opt-125m |
--host 和 --port | 指定服务器地址和端口。 |
--dtype | 模型权重和激活的精度类型。 可选值: auto、half、float16、bfloat16、float、float32。默认值: auto |
--tokenizer | 要使用的 HuggingFace 分词器名称或路径。 如果未指定,默认使用模型名称或路径。 |
--max-num-seqs | 每次迭代的最大序列数。 |
--max-model-len | 模型的上下文长度。 默认值自动从模型配置中获取。 |
--tensor-parallel-size 或 -tp | 张量并行副本数量(仅针对 GPU)。 默认值: 1 |
--distributed-executor-backend | 指定分布式服务后端。 可能的值: ray、mp。默认值: ray(当使用多个 GPU 时会自动使用 ray) |
运行以下命令启动一个兼容 OpenAI API 的服务:
python3 -m vllm.entrypoints.openai.api_server \--model /input0/Qwen-1_8B-Chat/ \--host 0.0.0.0 \--port 8080 \--dtype auto \--max-num-seqs 32 \--max-model-len 4096 \--tensor-parallel-size 1 \--trust-remote-code
启动成功后,您会看到类似如下的输出,并默认监听地址为:
http://localhost:8080
您也可以通过 --host 和 --port 参数指定自定义地址与端口。
启动 vLLM 服务后,可以通过 OpenAI 客户端调用 API 。以下是一个简单的示例:
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)models = client.models.list()
model = models.data[0].id
prompt = "描述一下北京的秋天"# Completion API 调用
completion= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")
执行命令:
python api_infer.py
您将看到如下输出结果:

支持的模型
以下是使用代理从 Hugging Face 加载/下载模型的一些技巧:
-
为您的会话全局设置代理(或在配置文件中设置)
export http_proxy=http://your.proxy.server:port export https_proxy=http://your.proxy.server:port -
仅为当前命令设置代理
https_proxy=http://your.proxy.server:port huggingface-cli download <model_name># or use vllm cmd directly https_proxy=http://your.proxy.server:port vllm serve <model_name> --disable-log-requests -
在 Python 解释器中设置代理
import osos.environ['http_proxy'] = 'http://your.proxy.server:port' os.environ['https_proxy'] = 'http://your.proxy.server:port'
vLLM 支持跨各种任务的生成模型和池化模型。 如果一个模型支持多个任务,您可以通过 --task 参数设置任务。
from vllm import LLM
llm = LLM(model=..., task="generate", trust_remote_code=True) # Name or path of your model
llm.apply_model(lambda model: print(model.__class__))
要使用来自 ModelScope 而不是 Hugging Face Hub 的模型,请设置一个环境变量
export VLLM_USE_MODELSCOPE=True
并与 trust_remote_code=True 一起使用。
from vllm import LLMllm = LLM(model=..., revision=..., task=..., trust_remote_code=True)# For generative models (task=generate) only
output = llm.generate("Hello, my name is")
print(output)# For pooling models (task={embed,classify,reward,score}) only
output = llm.encode("Hello, my name is")
print(output)
文本语言模型
生成模型(文本生成 (–task generate))
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| Aquila, Aquila2 |
| ✅︎ | ✅︎ |
| Arctic |
| ✅︎ | |
| Baichuan2, Baichuan |
| ✅︎ | ✅︎ |
| Bamba |
| ||
| BLOOM, BLOOMZ, BLOOMChat |
| ✅︎ | |
| BART |
| ||
| ChatGLM |
| ✅︎ | ✅︎ |
| Command-R |
| ✅︎ | ✅︎ |
| DBRX |
| ✅︎ | |
| DeciLM |
| ✅︎ | |
| DeepSeek |
| ✅︎ | |
| DeepSeek-V2 |
| ✅︎ | |
| DeepSeek-V3 |
| ✅︎ | |
| EXAONE-3 |
| ✅︎ | ✅︎ |
| Falcon |
| ✅︎ | |
| FalconMamba |
| ✅︎ | ✅︎ |
| Gemma |
| ✅︎ | ✅︎ |
| Gemma 2 |
| ✅︎ | ✅︎ |
| Gemma 3 |
| ✅︎ | ✅︎ |
| GLM-4 |
| ✅︎ | ✅︎ |
| GLM-4-0414 |
| ✅︎ | ✅︎ |
| GPT-2 |
| ✅︎ | |
| StarCoder, SantaCoder, WizardCoder |
| ✅︎ | ✅︎ |
| GPT-J |
| ✅︎ | |
| GPT-NeoX, Pythia, OpenAssistant, Dolly V2, StableLM |
| ✅︎ | |
| Granite 3.0, Granite 3.1, PowerLM |
| ✅︎ | ✅︎ |
| Granite 3.0 MoE, PowerMoE |
| ✅︎ | ✅︎ |
| Granite MoE Shared |
| ✅︎ | ✅︎ |
| GritLM |
| ✅︎ | ✅︎ |
| Grok1 |
| ✅︎ | ✅︎ |
| InternLM |
| ✅︎ | ✅︎ |
| InternLM2 |
| ✅︎ | ✅︎ |
| InternLM3 |
| ✅︎ | ✅︎ |
| Jais |
| ✅︎ | |
| Jamba |
| ✅︎ | ✅︎ |
| Llama 3.1, Llama 3, Llama 2, LLaMA, Yi |
| ✅︎ | ✅︎ |
| Mamba |
| ✅︎ | |
| MiniCPM |
| ✅︎ | ✅︎ |
| MiniCPM3 |
| ✅︎ | ✅︎ |
| Mistral, Mistral-Instruct |
| ✅︎ | ✅︎ |
| Mixtral-8x7B, Mixtral-8x7B-Instruct |
| ✅︎ | ✅︎ |
| MPT, MPT-Instruct, MPT-Chat, MPT-StoryWriter |
| ✅︎ | |
| Nemotron-3, Nemotron-4, Minitron |
| ✅︎ | ✅︎ |
| OLMo |
| ✅︎ | |
| OLMo2 |
| ✅︎ | |
| OLMoE |
| ✅︎ | ✅︎ |
| OPT, OPT-IML |
| ✅︎ | |
| Orion |
| ✅︎ | |
| Phi |
| ✅︎ | ✅︎ |
| Phi-4, Phi-3 |
| ✅︎ | ✅︎ |
| Phi-3-Small |
| ✅︎ | |
| Phi-3.5-MoE |
| ✅︎ | ✅︎ |
| Persimmon |
| ✅︎ | |
| Qwen |
| ✅︎ | ✅︎ |
| QwQ, Qwen2 |
| ✅︎ | ✅︎ |
| Qwen2MoE |
| ✅︎ | |
| Qwen3 |
| ✅︎ | ✅︎ |
| Qwen3MoE |
| ✅︎ | ✅︎ |
| StableLM |
| ✅︎ | |
| Starcoder2 |
| ✅︎ | |
| Solar Pro |
| ✅︎ | ✅︎ |
| TeleChat2 |
| ✅︎ | ✅︎ |
| TeleFLM |
| ✅︎ | ✅︎ |
| XVERSE |
| ✅︎ | ✅︎ |
| MiniMax-Text |
| ✅︎ | |
| Zamba2 |
|
池化模型
文本嵌入 (–task embed)
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 BERT |
| ||
| 基于 Gemma 2 |
| ✅︎ | |
| GritLM |
| ✅︎ | ✅︎ |
| 基于 Llama |
| ✅︎ | ✅︎ |
| 基于 Qwen2 |
| ✅︎ | ✅︎ |
| 基于 RoBERTa |
| ||
| 基于 XLM-RoBERTa |
|
奖励建模 (–task reward)
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 InternLM2 |
| ✅︎ | ✅︎ |
| 基于 Llama |
| ✅︎ | ✅︎ |
| 基于 Qwen2 |
| ✅︎ | ✅︎ |
| 基于 Qwen2 |
| ✅︎ | ✅︎ |
分类 (–task classify)
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| Jamba |
| ✅︎ | ✅︎ |
| 基于 Qwen2 |
| ✅︎ | ✅︎ |
句子对评分 (–task score)
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 BERT |
| ||
| 基于 RoBERTa |
| ||
| 基于 XLM-RoBERTa |
|
多模态语言模型
要为每个文本提示启用多个多模态项目,您必须设置 limit_mm_per_prompt(离线推理)或 --limit-mm-per-prompt(在线服务)。例如,要启用每个文本提示最多传递 4 张图像:
离线推理
llm = LLM(model="Qwen/Qwen2-VL-7B-Instruct",limit_mm_per_prompt={"image": 4},
)在线服务
vllm serve Qwen/Qwen2-VL-7B-Instruct --limit-mm-per-prompt image=4
以下模态取决于模型而支持
-
文本 (Text)
-
图像 (Image)
-
视频 (Video)
-
音频 (Audio)
支持由 + 连接的任何模态组合。例如:T + I 表示该模型支持仅文本、仅图像以及文本与图像结合的输入。
另一方面,由 / 分隔的模态是互斥的。例如:T / I 表示该模型支持仅文本和仅图像输入,但不支持文本与图像结合的输入。
生成模型(文本生成 (–task generate))
架构 | 模型 | 输入 | 示例 HF 模型 | LoRA | PP | V1 |
|---|---|---|---|---|---|---|
| Aria | T + I+ |
| ✅︎ | ✅︎ | |
| Aya Vision | T + I+ |
| ✅︎ | ✅︎ | |
| BLIP-2 | T + IE |
| ✅︎ | ✅︎ | |
| Chameleon | T + I |
| ✅︎ | ✅︎ | |
| DeepSeek-VL2 | T + I+ |
| ✅︎ | ✅︎ | |
| Florence-2 | T + I |
| |||
| Fuyu | T + I |
| ✅︎ | ✅︎ | |
| Gemma 3 | T + I+ |
| ✅︎ | ✅︎ | ⚠️ |
| GLM-4V | T + I |
| ✅︎ | ✅︎ | ✅︎ |
| H2OVL | T + IE+ |
| ✅︎ | ✅︎* | |
| Idefics3 | T + I |
| ✅︎ | ✅︎ | |
| InternVideo 2.5, InternVL 2.5, Mono-InternVL, InternVL 2.0 | T + IE+ |
| ✅︎ | ✅︎ | |
| Llama-4-17B-Omni-Instruct | T + I+ |
| ✅︎ | ✅︎ | |
| LLaVA-1.5 | T + IE+ |
| ✅︎ | ✅︎ | |
| LLaVA-NeXT | T + IE+ |
| ✅︎ | ✅︎ | |
| LLaVA-NeXT-Video | T + V |
| ✅︎ | ✅︎ | |
| LLaVA-Onevision | T + I+ + V+ |
| ✅︎ | ✅︎ | |
| MiniCPM-O | T + IE+ + VE+ + AE+ |
| ✅︎ | ✅︎ | ✅︎ |
| MiniCPM-V | T + IE+ + VE+ |
| ✅︎ | ✅︎ | ✅︎ |
| Mistral3 | T + I+ |
| ✅︎ | ✅︎ | |
| Llama 3.2 | T + I+ |
| |||
| Molmo | T + I+ |
| ✅︎ | ✅︎ | ✅︎ |
| NVLM-D 1.0 | T + I+ |
| ✅︎ | ✅︎ | |
| PaliGemma, PaliGemma 2 | T + IE |
| ✅︎ | ⚠️ | |
| Phi-3-Vision, Phi-3.5-Vision | T + IE+ |
| ✅︎ | ✅︎ | |
| Phi-4-multimodal | T + I+ / T + A+ / I+ + A+ |
| ✅︎ | ||
| Pixtral | T + I+ |
| ✅︎ | ✅︎ | |
| Qwen-VL | T + IE+ |
| ✅︎ | ✅︎ | ✅︎ |
| Qwen2-Audio | T + A+ |
| ✅︎ | ✅︎ | |
| QVQ, Qwen2-VL | T + IE+ + VE+ |
| ✅︎ | ✅︎ | ✅︎ |
| Qwen2.5-VL | T + IE+ + VE+ |
| ✅︎ | ✅︎ | ✅︎ |
| Skywork-R1V-38B | T + I |
| ✅︎ | ✅︎ | |
| SmolVLM2 | T + I |
| ✅︎ | ✅︎ | |
| Ultravox | T + AE+ |
| ✅︎ | ✅︎ | ✅︎ |
需要通过 --hf-overrides 设置架构名称,以匹配 vLLM 中的架构名称。例如,要使用 DeepSeek-VL2 系列模型
--hf-overrides '{"architectures": ["DeepseekVLV2ForCausalLM"]}'
池化模型
文本嵌入 (–task embed)
架构 | 模型 | 输入 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|---|
| 基于 LLaVA-NeXT | T / I |
| ✅︎ | |
| 基于 Phi-3-Vision | T + I |
| 🚧 | ✅︎ |
| 基于 Qwen2-VL | T + I |
| ✅︎ |
转录 (–task transcription)
架构 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 Whisper |
| 🚧 | 🚧 |
常用方法
生成模型
vLLM 为生成模型提供一流的支持,涵盖了大多数 LLM。
在 vLLM 中,生成模型实现了 VllmModelForTextGeneration 接口。基于输入的最终隐藏状态,这些模型输出要生成的 token 的对数概率,然后这些概率通过 Sampler 传递以获得最终文本。
对于生成模型,唯一支持的 --task 选项是 “generate”。通常,这是自动推断的,因此您不必指定它。
LLM.generate 方法适用于 vLLM 中的所有生成模型。
from vllm import LLM, SamplingParamsllm = LLM(model="facebook/opt-125m")
params = SamplingParams(temperature=0)
outputs = llm.generate("Hello, my name is", params)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
LLM.chat方法在 generate 之上实现了聊天功能。特别是,它接受类似于 OpenAI Chat Completions API 的输入,并自动应用模型的 聊天模板来格式化提示。
from vllm import LLMllm = LLM(model="meta-llama/Meta-Llama-3-8B-Instruct")
conversation = [{"role": "system","content": "You are a helpful assistant"},{"role": "user","content": "Hello"},{"role": "assistant","content": "Hello! How can I assist you today?"},{"role": "user","content": "Write an essay about the importance of higher education.",},
]
outputs = llm.chat(conversation)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
Pooling 模型
在 vLLM 中,Pooling 模型实现了 VllmModelForPooling 接口。这些模型使用 Pooler 来提取输入的最终隐藏状态,然后再返回它们。
LLM.encode 方法适用于 vLLM 中的所有 Pooling 模型。它直接返回提取的隐藏状态,这对于奖励模型很有用。
from vllm import LLMllm = LLM(model="Qwen/Qwen2.5-Math-RM-72B", task="reward")
(output,) = llm.encode("Hello, my name is")data = output.outputs.data
print(f"Data: {data!r}")
LLM.embed 方法为每个 prompt 输出一个嵌入向量。它主要为嵌入模型设计。
from vllm import LLMllm = LLM(model="intfloat/e5-mistral-7b-instruct", task="embed")
(output,) = llm.embed("Hello, my name is")embeds = output.outputs.embedding
print(f"Embeddings: {embeds!r} (size={len(embeds)})")
代码示例可以在这里找到: examples/offline_inference/basic/embed.py
LLM.classify 方法为每个 prompt 输出一个概率向量。它主要为分类模型设计。
from vllm import LLMllm = LLM(model="jason9693/Qwen2.5-1.5B-apeach", task="classify")
(output,) = llm.classify("Hello, my name is")probs = output.outputs.probs
print(f"Class Probabilities: {probs!r} (size={len(probs)})")
LLM.score 方法输出句子对之间的相似度评分。它专为嵌入模型和交叉编码器模型设计。嵌入模型使用余弦相似度,而 交叉编码器模型 在 RAG 系统中充当候选查询-文档对之间的重排序器。
vLLM 只能执行 RAG 的模型推理组件(例如,嵌入、重排序)。要在更高级别处理 RAG,您应该使用集成框架,例如 LangChain。
from vllm import LLMllm = LLM(model="BAAI/bge-reranker-v2-m3", task="score")
(output,) = llm.score("What is the capital of France?","The capital of Brazil is Brasilia.")score = output.outputs.score
print(f"Score: {score}")
OpenAI 兼容服务器
vLLM 提供了一个 HTTP 服务器,实现了 OpenAI 的 Completions API、Chat API 以及更多功能!
您可以通过 vllm serve 命令或通过 Docker 启动服务器
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123
要调用服务器,您可以使用 官方 OpenAI Python 客户端,或任何其他 HTTP 客户端。
from openai import OpenAI
client = OpenAI(base_url="https://127.0.0.1:8000/v1",api_key="token-abc123",
)completion = client.chat.completions.create(model="NousResearch/Meta-Llama-3-8B-Instruct",messages=[{"role": "user", "content": "Hello!"}]
)print(completion.choices[0].message)
vLLM 支持一些 OpenAI 不支持的参数,例如 top_k。您可以使用 OpenAI 客户端在请求的 extra_body 参数中将这些参数传递给 vLLM,例如 extra_body={"top_k": 50} 代表 top_k。
vLLM 支持以下 OpenAI 兼容 API 和 自定义扩展 API,
| 接口路径 | 功能 | 适用模型 | 注意事项 |
|---|---|---|---|
/v1/completions | 文本补全 | 文本生成模型(--task generate) | 不支持 suffix 参数 |
/v1/chat/completions | 聊天对话生成 | 具备聊天模板的文本生成模型(--task generate) | 忽略 parallel_tool_calls 和 user 参数 |
/v1/embeddings | 文本向量嵌入 | 嵌入模型(--task embed) | - |
/v1/audio/transcriptions | 音频转文字 | 自动语音识别(如 Whisper)(--task generate) | - |
| 接口路径 | 功能 | 适用模型 | 说明 |
|---|---|---|---|
/tokenize / /detokenize | 分词与反分词 | 任意含分词器的模型 | 提供分词调试能力 |
/pooling | 池化处理 | 所有池化模型 | 用于聚合 token 向量 |
/score | 打分(如相关性) | 嵌入模型、交叉编码器(--task score) | 适合排序、打分任务 |
/rerank, /v1/rerank, /v2/rerank | 文本重排序 | 交叉编码器(--task score) | 兼容 Jina/Cohere,Jina 响应更详细 |
具体文档参考:
- 中文文档1:https://docs.vllm.com.cn/en/latest/serving/openai_compatible_server.html
- 中文文档2:https://docs.vllm.com.cn/en/latest/serving/openai_compatible_server.html#chat-api
VLLM 与 Ollama:如何选择合适的轻量级 LLM 框架?
🔍 vLLM vs Ollama 对比一览
| 对比维度 | vLLM | Ollama |
|---|---|---|
| 核心定位 | 企业级高性能推理框架,支持高并发、低延迟,适用于生产环境。 | 轻量级本地部署工具,适合个人开发者和小型项目,强调易用性和快速部署。 |
| 硬件支持 | 主要依赖 NVIDIA GPU,支持 FP16/BF16 精度,显存占用较高。 | 支持 CPU 和 GPU,默认使用 int4 量化模型,显存占用低,适合资源有限的设备。 |
| 部署难度 | 需配置 Python 环境、CUDA 驱动,适合有一定技术背景的用户。 | 一键安装,开箱即用,无需复杂配置,适合没有技术背景的用户。 |
| 并发能力 | 支持动态批处理和千级并发请求,吞吐量高,适合处理大量并发请求。 | 单次推理速度快,但并发处理能力较弱,适合处理少量请求。 |
| 模型支持 | 需手动下载原始模型文件(如 HuggingFace 格式),支持更广泛的模型,兼容多种解码算法。 | 内置预训练模型库,自动下载量化版本(int4 为主),支持的模型相对较少。 |
| 并行策略 | 多进程方式,每个 GPU 一个进程,支持张量并行和流水线并行,适合分布式部署。 | 单进程方式,通过线程管理多 GPU,适合单机本地化场景,多 GPU 并行支持有限。 |
| 资源管理 | 显存占用固定,需预留资源应对峰值负载。 | 灵活调整资源占用,空闲时自动释放显存,资源管理更高效。 |
| 安全性 | 支持 API Key 授权,适合生产环境的安全需求。 | 不支持 API Key 授权,安全性相对较弱。 |
| 文档支持 | 提供全面的技术文档,包括详细的 API 参考和指南,GitHub 维护良好,开发者响应迅速。 | 文档简单且适合初学者,但缺乏技术深度,GitHub 讨论区部分问题未得到解答。 |
| 适用场景 | 企业级 API 服务、高并发批量推理(如智能客服、文档处理)、需要高精度模型输出或定制化参数调整的场景。 | 个人开发者快速验证模型效果、低配置硬件(如仅有 16GB 内存的笔记本电脑)、需要快速交互式对话或原型开发的场景。 |
在并发性能测试中,vLLM 和 Ollama 均表现出较高的稳定性(无失败请求),但在性能表现上存在显著差异:(CSDN 博客)
-
低并发场景(并发数 1 和 5):
-
Ollama 的平均响应时间和响应时间中位数显著优于 vLLM。(CSDN 博客)
-
vLLM 的吞吐量略高于 Ollama。(博客园)
-
-
高并发场景(并发数 10 和 20):
-
vLLM 的平均响应时间和响应时间中位数显著优于 Ollama。(CSDN 博客)
-
vLLM 的吞吐量显著高于 Ollama。(博客园)
-
vLLM 的最大响应时间在高并发场景下更稳定,表明其在高负载下的性能表现更优。(CSDN 博客)
-
例如,在并发数为 20 的情况下,vLLM 的平均响应时间约为 10,319.91 ms,而 Ollama 的平均响应时间约为 16,845.03 ms。(CSDN 博客)
🧠 模型精度与显存占用
-
模型精度:
-
vLLM 使用原始模型(如 FP16/BF16),保持了模型的高精度输出。(博客园)
-
Ollama 使用量化模型(如 int4),可能导致模型精度下降,生成内容质量或指令遵循能力降低。(博客园)
-
-
显存占用:
- 以 Qwen2.5-14B 模型为例,vLLM 运行需要约 39GB 显存,而 Ollama 仅需约 11GB 显存。(博客园)
🧩 总结建议
-
选择 Ollama:
-
适合个人开发者、小型项目或需要快速部署的场景。(博客园)
-
适合资源有限的设备和个人用户。(博客园)
-
适合对响应速度要求较高的低负载场景。(CSDN 博客)
-
-
选择 vLLM:
-
适合企业级应用和需要高效推理的场景。(博客园)
-
适合处理大规模并发请求的应用场景。(CSDN 博客)
-
适合需要高精度模型输出或定制化参数调整的场景。(博客园)
-
而ollma也提供api访问:
import requests
response = requests.post("http://localhost:11434/api/generate", json={"model": "mistral", "prompt": "Tell me a joke"})
print(response.json())
Tiny / Distil / Mini
模型蒸馏(Knowledge Distillation)是一种 模型压缩技术,其核心思想是:
用一个大模型(教师模型)训练出一个小模型(学生模型),让小模型尽量模仿大模型的行为,从而在保留大部分性能的前提下大幅减少模型体积和推理开销。
vLLM 是推理引擎,不是训练框架,它专注于高性能地“运行模型”(特别是 LLM 的聊天推理),而不是训练或蒸馏模型。
常用的蒸馏框架如下:
| 框架 | 特点 | 适合用途 |
|---|---|---|
| Hugging Face Transformers + Trainer | 通用、生态好,有 Distillation 示例 | 微调 + 蒸馏 |
| Hugging Face + 🤗 Datasets | 批量数据处理配套方便 | 大规模数据上做蒸馏 |
| OpenKD(by THU) | 专门为 NLP 蒸馏设计 | 各类蒸馏方式齐全(task distillation、layer distillation等) |
| TextBrewer | 结构灵活、适用于 BERT、RoBERTa 等 | 更精细控制 loss 和中间层 |
| Fairseq / DeepSpeed / Megatron-LM | 面向超大模型蒸馏 | 大规模并行蒸馏场景 |
TinyBERT / DistilBERT / MiniLM 有什么区别?这些都是对 BERT 模型做蒸馏压缩 后的产物,但它们采用的策略不同,适用场景也不一样:
| 名称 | 提出机构 | 参数量 | 蒸馏策略 | 特点 | 应用场景 |
|---|---|---|---|---|---|
| DistilBERT | Hugging Face | ~66M | 只对 logits 蒸馏(output distillation) | 简单、稳定 | 文本分类、语义匹配 |
| TinyBERT | Huawei Noah’s Ark Lab | ~14M / ~66M | 包括中间层蒸馏(intermediate layer distillation) | 更复杂,性能更接近原始 BERT | 文本理解、QA |
| MiniLM | Microsoft | ~22M | 注意力分布和表示的蒸馏(attention + value distillation) | 超轻量但强大 | 向量生成、检索嵌入 |
| MobileBERT | ~25M | 架构微调 + 蒸馏 | 有专门的 Bottleneck 架构 | 移动设备部署 | |
| ALBERT | 参数共享,不是蒸馏 | 提前结构压缩 | 节省参数,不减性能 | 学术研究多 |