【Java ee初阶】网络原理
应用层
由于下面的四层都是系统已经实现好了的,但是应用层是程序员自己写的,因此应用层是程序员最重要的一层。
应用层中,程序员通常需要定义好数据传输格式,调用传输层api(socket api)进行真正的网络通信,这就相当于在“自定义应用层协议”。
工作中更多的称为“约定前后端交互接口”,客户端、服务器。
示例:通过QQ发送一个hello给对方
发送者的id,接受者的id,时间,正文。
这里的格式和内容怎么定,都是程序员自行约定的
示例:1234,5678,2025-04-17 21:25:00,hello;
自定义协议的过程,主要是约定两件事: 1. 通信的信息是什么。 2. 通信的数据格式是什么。
1. 通信的信息是根据需求来确定的
以外卖为例:

点开外卖界面的请求

点开具体商家的需求
2. 通信的数据格式是什么,这是由程序员自行定义,既可以是客户端程序员定义的,也可以是服务器程序员定义的。
1) 行文本方式
1234,5678,2025-04-17 21:25:00,hello;
缺点:可读性很差。以前这种方案比较流行,现在越来越少了。
2) XML 通过成对的标签,来对数据内容进行解释说明
示例:
xml <request></request>
<from>1234</from>
<to>5678</to>
<time>2025-04-17 21:25:00</time>
<message>hello</message>
有点像HTML ,但是HTML的标签名字是标准规定的,都是有特殊含义的,XML标签的名字都是程序员自定义的。
这种方案越来越少了。一般很少用于“网络通信”
使用xml更多是作为本地的配置文件(maven
优点:可读性好了很多。
缺点:引入了很多标签,也需要占用网络带宽。对于服务器的硬件来说,最贵的资源其实是网络带宽。CPU、内存、硬盘,都不贵。真正贵的是网络带宽。
3) JSON 当前最流行的一种方案。
示例:
json { "from": "1234", "to": "5678", "time": "2025-04-17 21:25:00", "message": "hello" }
不是特别缺网络带宽
后面JavaEE进阶,未来的项目中,都会经常用到
以后实际开发中,也会经常用到。
后来又有了一些yaml / toml替代方案……
4) google protobuffer
二进制压缩的方案。 把要传输的数据按照一定规则编码成二进制比特位,然后再进行传输。 可读性非常差,但是网络带宽消耗的最少。 特别缺网络带宽的时候可以考虑本方案。
肉眼无法阅读,只能靠代码来解析。
学习网络协议,主要就是在学习协议格式
UDP协议
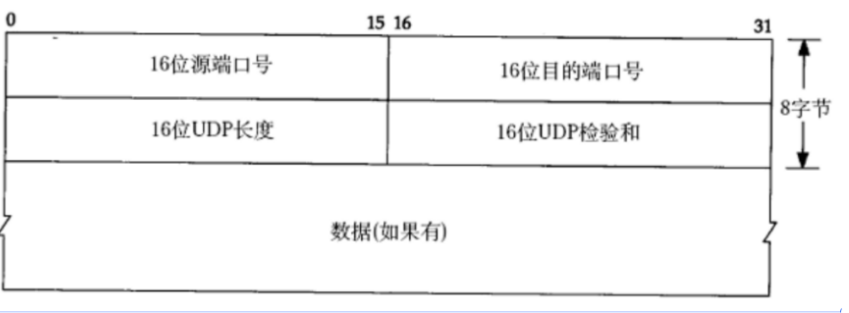
 理解成类似于“字符串”只不过里面的数据是“二进制”
理解成类似于“字符串”只不过里面的数据是“二进制”
端口号是一个整数。2个字节,无符号(不分正负),取值范围为0 - 65535。网络协议,是有专门的组织来负责制定标准的。
此处UDP长度是2个字节,表示的数据范围0 - 65535,最大为 64KB。一个UDP数据报,最大长度就是64KB。而我们知道,现在手机拍的一个照片,尺寸就有10MB左右。如果需要传输比较大的数据,就可能装不下。
现在,计算机内存动不动就是16GB,32GB…… 为什么大佬们不把UDP协议扩充一下呢?这是因为从技术上来说,改一下格式,两个字节变为四个字节…… 但是具体实施上就费劲。 通信双方的设备,都得一起升级,才能有效。世界上的任意两个设备之间都可能使用UDP进行通信 一旦进行升级,一定会出现,一部分设备是新版本,一部分设备是旧版本的情况,新版设备和旧版设备就无法正确通信了……造成的后果难以估量。 协议标准好升级,协议具体的实现,是在各种操作系统厂商手里。 需要这些厂商配合你升级 可以预见短期之内,UDP都很难得到升级。相比于升级UDP,搞一个新的协议代替UDP可能是成本更低的做法。
如果64kb 上限很快就要达到了,那么由两种做法:
(1)应用层,对数据进行拆分。
否决,开发量很大,拆成多个之后,如果其中一部分丢包了咋办?
如果其中某个部分出错了咋办?
如果发送顺序和接收顺序不一致咋办,接收方如何重组?
……
(2)换成 TCP 协议 (没有明确的上限)
校验和
校验和用来验证UDP数据报是否在传输中出错。网络数据包传输中是否会出错?肯定会有一定概率。因为比特翻转(1 -> 0,0 -> 1) 本质上是电信号/光信号/电磁波环境的影响。 低电平、高电平与光/电磁波频率、磁场、高能粒子流(太空中)等概率性事件有关。比特翻转,客观存在的,无法100%避免,只能甄别出,当前数据是否是出错的。比如进行转账操作,本来转账100块钱, 因为数据传输出错,100 -> 10000 及时发现传输的输出出错,让转账失败,好过错误的转账10000的。
校验和,就是用来甄别数据是否出错的有效方案。发送方,构造UDP数据报,构造完成之后,把数据报的每个字节的数据,都进行累加,结果累加到一个16位的整数上。溢出,就溢出。 此时得到的结果,就是校验和check1,填充到UDP报头的校验和字段。check1 接收方收到UDP数据报之后,就会按照相同的算法,再计算一遍校验和 check2 接收方。就可以比较check1 == check2。如果相等,就可以视为 数据传输是正确的。 如果不相等,说明数据传输出错了。 CRC校验和,循环冗余校验,是一种简单,有效的做法 如果发送的数据和接收到的数据,每个字节都一致,计算得到的校验和就一定一致。 反之,发现校验和不一致,就意味着一定是发送的数据和接收的数据其中的某个字节/比特位 出现问题了。 虽然不知道是哪个比特位出错了,但是可以知道 出错/没出错,如果出错了就把数据丢弃掉即可。
那么,是否存在极端情况,恰好使得两个bit位发生翻转,导致翻转后算出来的校验和和翻转前算出来的校验和碰巧一样呢?这种情况,理论上会存在,实践中,概率非常非常小,忽略不计了。如果对于准确性要求特别敏感的场景,当然也有其他的校验和算法,做一个更精准的甄别。包括还有一些校验和算法,可以识别出是哪一位出现翻转,自动纠错,例如“计组”中讲到的海明码。
又比如把一个很大的文件,通过网络传给另一台机器,通过校验和的方式,验证文件是否出错了。
基于UDP的应用层协议:
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议(你的电脑,查到路由器上 路由器通过DHCP协议给你的电脑自动分配IP地址 不需要手动配置)
- BOOTP:启动协议(用于无盘设备启动)
- DNS:域名解析协议
这里的协议很多都是比较生僻的。
使用UDP更多的场景,主要是在分布式系统中,服务器之间的通信:
1. 这些服务器在同一个机房,网络环境简单,出现丢包的概率比较小
2. UDP传输效率比较高
TCP协议
有连接,可靠传输,面向字节流…更多的差别
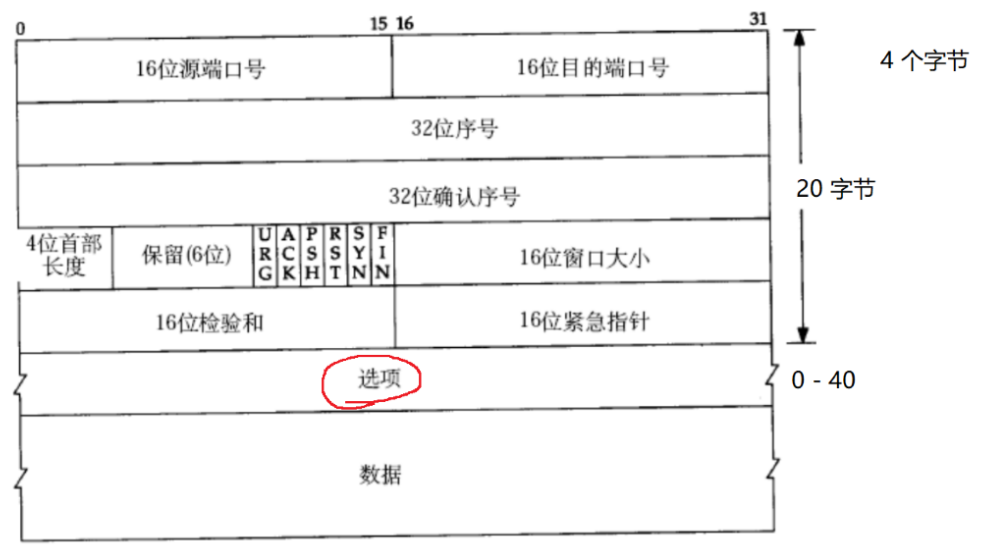
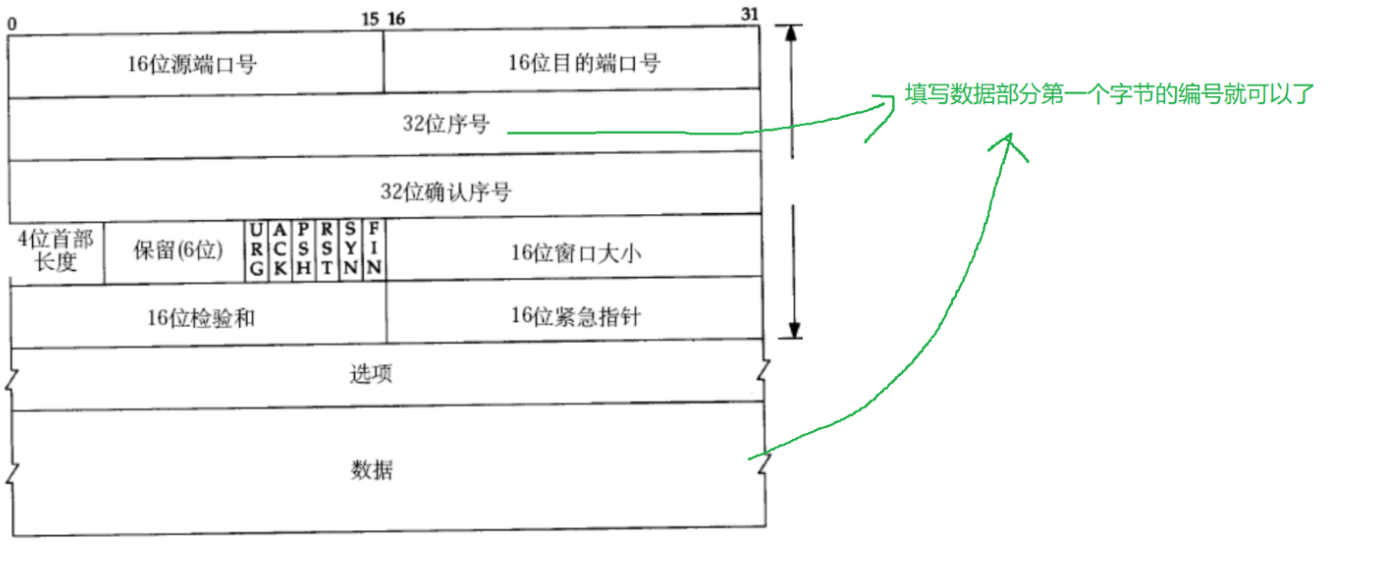
16位源端口号
16位目的端口号
4位首部长度 报头的长度 报头中包含了“选项”optional => 可选的 0-15 4字节 TCP报头的最大长度是60字节
保留(6位) UDP想升级,非常费劲,就导致UDP的报文长度始终受到64KB的限制。 保留位,现在不使用,但是先占个位置,说不定以后就会使用。
 6个最关键的标志位。
6个最关键的标志位。
16位校验和 和UDP一样了
需要结合TCP的特性来进行理解。
可靠传输
什么是可靠传输? 可靠传输,能否做到数据100%到达对方呢?不能做到的!
发送的数据,能够知道对方是否收到,就可以认为是“可靠传输”
1) 如果知道对方收到了,传输成功
2) 如果知道对方没收到(丢包),采取其他措施补救
核心机制一:确认应答
实现让发送方知道接收方是否收到数据。 发送方发了数据之后,接收方接受。一旦受到了,就给发送方返回一个“应答报文”告诉发送方,“我收到了”
网络中时常出现“先发后置”的问题,网络中,路由器交换机就像端口红绿灯,一系列的数据包传输过程中,不一定是按照相同的路线转发的。不同的路线,有的可能堵,有的可能通畅。
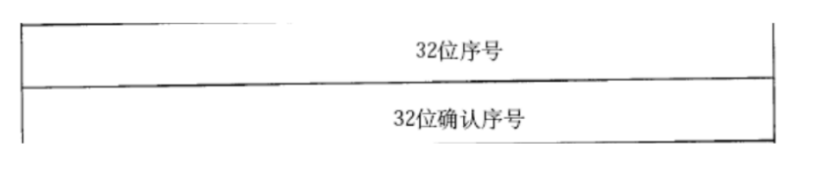 TCP是字节流传输
TCP是字节流传输
序号和确认序号是针对“字节”进行编号的。
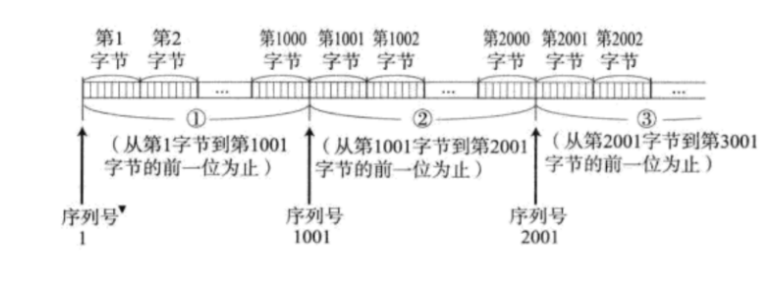
一个TCP数据报,包含多个字节, 如何体现所有的编号呢? 编号是连续递增的。只要知道TCP载荷的第一个字节的编号是多少,后面的每个字节的编号就都知道了
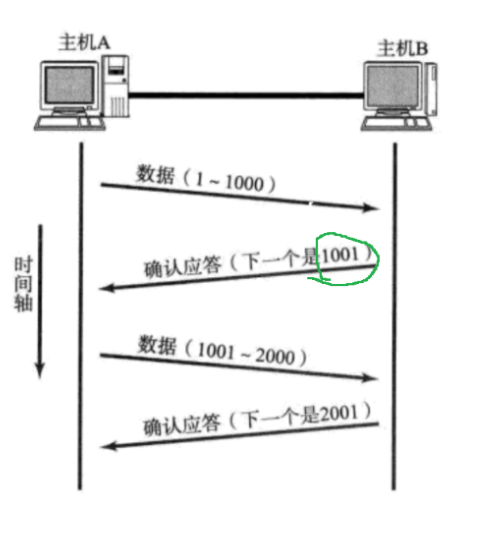
同一个TCP连接内, 序号会持续累加。下一个数据报的序号在上一个数据报最后一个字节的序号基础上继续递增,确认序号只在应答报文中生效。确认序号根据收到的数据的 最后一个字节的序号 + 1 进行填充。
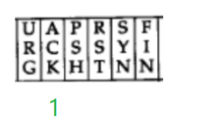
这一位为1,确认序号字段就会有效,否则属于是“无效字段”
确认序号的含义:
1. 所有 < 确认序号的数据,接收方已经收到了
2. 发送方接下来应该从确认序号位置,继续发送数据
确认应答,关键是,数据顺利到达,通过ack告知发送方。
实际传输中,很可能丢包的。
TCP核心机制二:超时重传
确认应答的重要补充,针对丢包的场景的。
超时:发送方,判定是否出现丢包的条件
重传:发现数据丢包,就再发一次
这是一个概率问题,假设一个数据包,传输过程中,丢包的概率是10%(相当大的数字
连续传输两次,数据包至少一次到达对方的概率是多少呢? 1 - 10% * 10% => 99%
传输次数的增加,数据报到达对方的概率大幅度增加
计算机中,一般不喜欢“无限的等”
最大等待时间“超时时间”
只要超过超时时间,还没有收到ACK就可以视为是丢包了
不同系统上,超时时间都是可能不同的(可配置的参数)
没有收到ack,有两种情况:
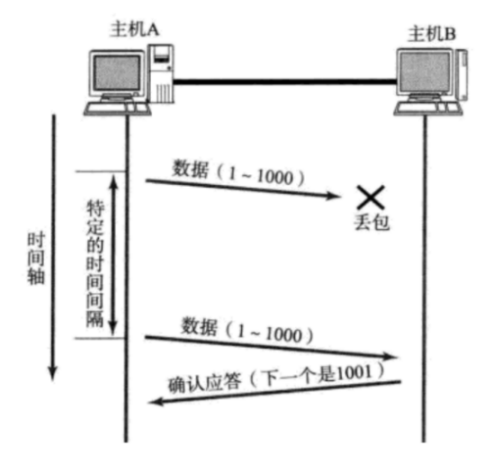
这种情况丢包之后重传,理所应当的
B已经收到过一份数据了 接下来又重传一次, B这边同样的数据收到两份
超时重传的超时时间不是固定的,动态变化。
假设,发的数据是一个“转账数据”
TCP协议已经处理了上述情况
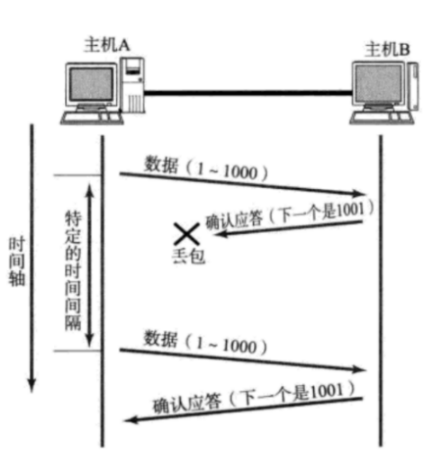
TCP,在接受到数据的时候,会在操作系统内核中 维护一个“接收缓冲区”(内存空间)
如果又收到了同一个数据,此时就可以根据数据的序号 来在接受缓冲区中进行“去重”
确保应用程序,在进行read操作的时候,读到的数据不会出现重复
TCP也会针对收到的数据在接收缓冲区中进行重新排序
数据传输可能出现“后发先至” 1-1000先发的 1001-2000后发的
接收方先收到了1001-2000 后收到了1-1000
TCP的处理方式是在 接收缓冲区里,针对收到的数据进行排序
随着超时重传的进行,如果还是没有收到ack仍然要继续重传
但是等待的超时时间会逐渐变长
通过重传之后,大幅度提升数据到达对方的概率
但是重传之后,还是没有收到ack,只能说明,当前网络的丢包概率,远远不止10%了
此时,网络大概率出现非常严重的故障了,再频繁重传,非但不会解决问题,甚至可能会加重网络故障的程度
没指望重传能成功,死马当活马医了
超时重传处理丢包的情况
重置涉及到“复位报文”
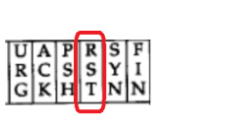
RST
触发一个复位报文,意味着这个连接就不要了
单方面的通知
“释放连接”就相当于删除掉之前保存的对方的信息。
重传次数/总的重传时间,是存在上限的。
达到上限,重传还没有成功,tcp连接就会被“重置” => 单方面的断开连接了。
超时重传,TCP中,进行可靠传输的重要机制之一 是确认应答的补充。
确认应答处理传输顺利的情况
“TCP的可靠性是通过三次握手实现的” 实际上不是这样的。 三次握手只是在连接建立之初,涉及到的环节。 一旦连接建立好了,后序就没有 握手的事情了......