Python企业级OCR实战开发:从基础识别到智能应用
简介
OCR技术已成为企业数字化转型的关键工具,能够从图像中提取结构化文本数据,提升信息处理效率。本教程将全面讲解如何基于Python和Tesseract OCR引擎构建企业级文字识别系统,包括环境配置、基础识别、图像预处理、批量处理、多语言支持及结果校验等核心模块。通过实际代码示例,读者将掌握如何将OCR技术应用于发票识别、文档归档、数据提取等业务场景,并了解如何优化识别准确率。
一、环境准备与安装配置
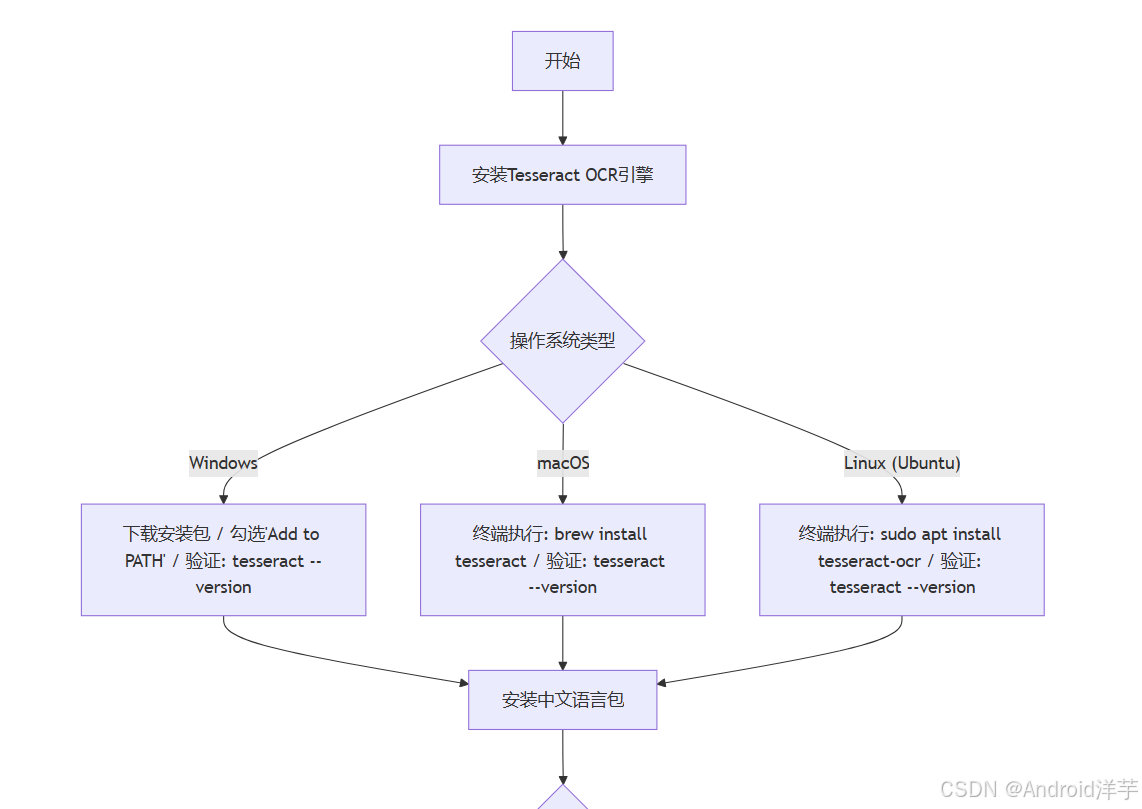
企业级OCR开发的第一步是确保所有必要的软件环境和库已正确安装。Tesseract OCR引擎作为开源的OCR核心,是Python OCR应用的基础。安装步骤因操作系统而异,但都需确保Tesseract能够被Python脚本正确调用。
在Windows系统上,用户应从Tesseract官方GitHub页面下载最新版本的安装包(如tesseract-ocr-w64-setup-5.3.3.20250508.exe),并运行安装向导。安装过程中,建议勾选"Add Tesseract to your PATH"选项,以确保系统能自动识别Tesseract路径。安装完成后,需验证安装是否成功,打开命令提示符并输入tesseract --version,若返回版本信息(如tesseract 5.3.3)则表明安装成功。
对于macOS用户,安装更为简单,只需在终端执行brew install tesseract即可。Linux用户(以Ubuntu为例)则可通过sudo apt update && sudo apt install tesseract-ocr命令完成安装。安装完成后,同样需运行tesseract --version验证安装状态。
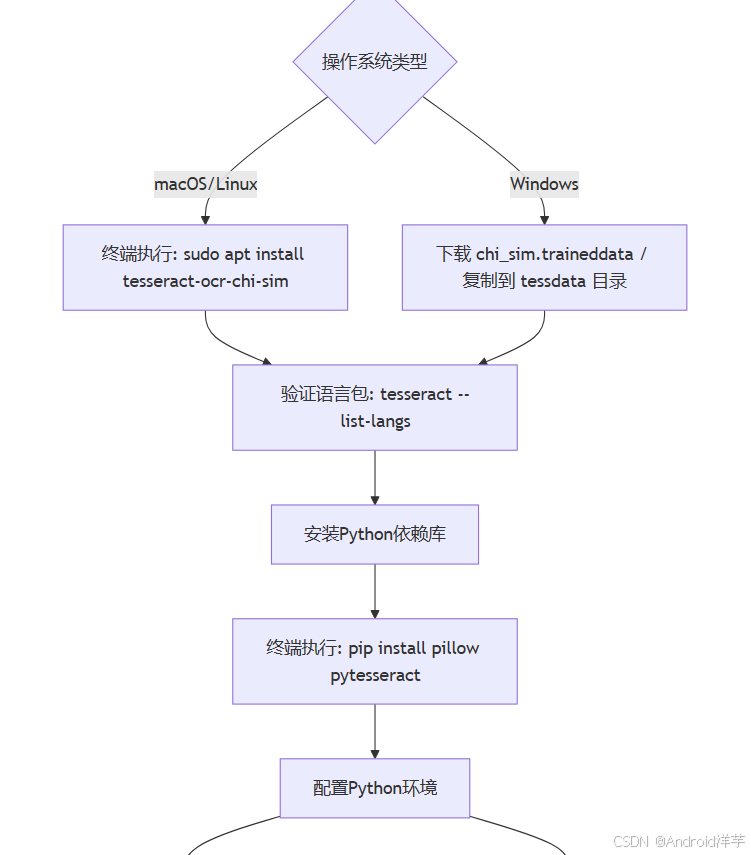
多语言支持是OCR系统的必备功能,特别是中文识别。中文语言包包括chi_sim(简体中文)和chi_tra(繁体中文),需从GitHub的tessdata仓库下载。在Windows系统上,将下载的.chi_sim.traineddata文件放入Tesseract安装目录的tessdata子目录下;在Linux系统上,可通过sudo apt install tesseract-ocr-chi-sim直接安装中文语言包。安装完成后,执行tesseract --list-langs命令验证已安装的语言。
PythonOCR开发需要两个关键库:Pillow和pytesseract。Pillow是Python图像处理库,用于图像加载和基础操作;pytesseract是Tesseract的Python封装库。安装这两个库的命令如下:
pip install pillow
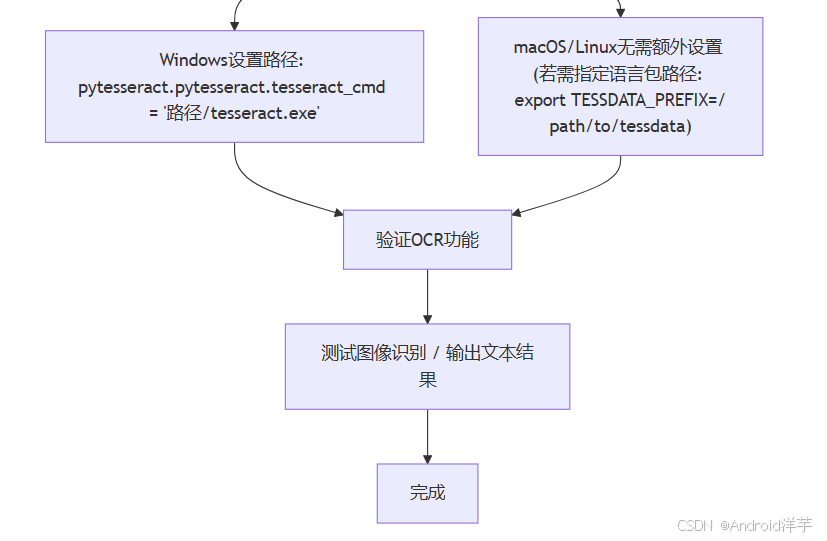
pip install pytesseract确保Python环境能正确调用Tesseract是关键。在代码中,Windows用户需显式设置Tesseract路径:
import pytesseract
from PIL import Imagepytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'若Tesseract安装路径不在系统PATH环境变量中,此设置尤为重要。对于macOS和Linux系统,通常无需额外设置路径,但可通过export TESSDATA_PREFIX=/path/to/tessdata指定语言包路径。
二、基础OCR实现与核心参数
掌握了环境配置后,我们就可以开始编写基础的OCR识别代码了。Tesseract OCR的核心功能通过pytesseract的image_to_string()函数实现,该函数将图像文件或图像对象作为输入,返回识别的文本。
一个简单的OCR识别示例代码如下:
from PIL import Image
import pytesseract# 加载图像文件
image = Image.open("sample.jpg")# 执行OCR识别
text = pytesseract.image_to_string(image, lang='chi_sim+eng')# 输出识别结果
print("识别的文本:", text)这段代码首先使用Pillow库加载图像文件,然后调用image_to_string()函数进行OCR识别,最后输出结果。lang参数用于指定识别语言,可以是单一语言(如chi_sim)或多种语言组合(如chi_sim+eng)。
image_to_string()函数有多个重要参数,理解这些参数对于优化识别效果至关重要:
lang:指定识别语言,支持多语言组合(如chi_sim+eng表示同时识别中英文)。config:自定义OCR配置,如引擎模式(--oem)和页面分割模式(--psm)。timeout:设置识别任务的最大执行时间,防止长时间阻塞。
页面分割模式(--psm)是影响识别准确率的重要参数,它决定了Tesseract如何解析图像中的文本区域。常见的PSM值包括:
- 3:全自动页面分割(默认模式)
- 6:假设图像包含一个均匀的文本块
- 7:假设图像包含一行文本
- 8:假设图像包含一个单词
- 11:稀疏文本识别
根据实际场景选择合适的PSM值可以显著提升识别效果。例如,对于发票上的单列文本,使用--psm 6模式可获得更好的识别结果。
此外,Tesseract还支持字符白名单(-c tessedit_char_whitelist)功能,允许用户限制识别的字符范围,这对于验证码识别等特定场景非常有用。
三、图像预处理技术提升识别率
图像质量是OCR识别准确率的关键因素。通过适当的图像预处理,可以将识别率从基础的70%左右提升至95%以上。以下是几种常用的图像预处理技术及其Python实现。
灰度化是将彩色图像转换为灰度图像的过程,可减少颜色信息对OCR识别的干扰。使用Pillow实现灰度化非常简单:
from PIL import Image# 转换为灰度图像
gray_image = image.convert('L')二值化是将灰度图像转换为黑白图像的过程,进一步突出文本内容。二值化可通过全局阈值或自适应阈值实现:
# 全局阈值二值化(阈值为128)
binary_image = gray_image.point(lambda x: 0 if x < 128 else 255, '1')# 自适应阈值二值化