RAG 技术详解:如何让大模型更 “懂” 知识库?
一、RAG 技术的核心价值
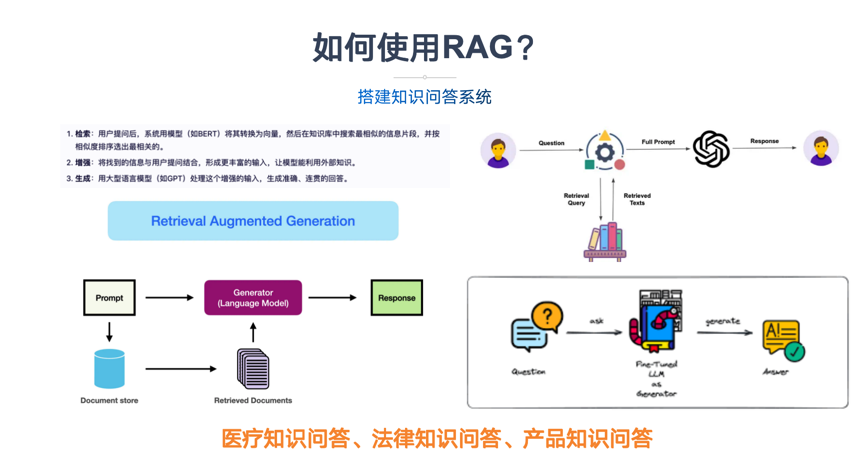
在大模型时代,尽管 ChatGPT 等生成式 AI 能够流畅对话,但普遍存在两个致命缺陷:知识滞后(无法获取训练数据之外的新信息)和幻觉风险(编造错误内容)。RAG(检索增强生成,Retrieval-Augmented Generation)技术通过将大模型与外部知识库深度融合,有效解决了这一痛点。其核心原理是:当用户提问时,系统首先从结构化 / 非结构化知识库中检索相关文档片段,再将检索结果与原始问题共同输入大语言模型,生成更准确、更可靠的回答。
1.1 RAG 的三大核心优势
- 知识实时性:通过动态检索外部数据,模型可获取最新信息,例如实时金融数据、行业报告等。
- 事实准确性:检索到的权威文档片段为生成提供依据,显著降低幻觉问题,尤其适用于医疗、法律等专业领域。
- 领域扩展性:无需重新训练模型,只需更新知识库即可扩展至新领域,如企业内部文档库、产品手册等。
二、RAG 技术的核心架构与工作流程
2.1 RAG 的核心组件
RAG 系统由三大模块构成:
- 检索器(Retriever):
- 功能:根据用户查询从外部知识库中获取相关数据。
- 技术实现:
- 稀疏检索:基于 TF-IDF、BM25 等词匹配算法,适用于精确关键词查询。
- 密集检索:使用 BERT、RoBERTa 等模型生成语义向量,实现更精准的语义匹配。
- 混合检索:结合稀疏与密集检索,平衡召回率与准确率。
- 增强器(Augmenter):
- 功能:将检索到的文档片段嵌入预定义的提示模板,形成结构化输入。
- 关键技术:
- 文本分块:采用固定大小或语义感知分块策略,避免因文档过长超出 LLM 的 token 限制。
- 向量化处理:使用 text-embedding-ada-002 等模型将文本转换为高维向量,便于语义相似度计算。
- 生成器(Generator):
- 功能:结合用户问题与检索到的上下文,生成自然、连贯的回答。
- 优化策略:
- Prompt 工程:设计指令模板引导模型输出,例如 “根据已知信息回答用户问题,若信息不足请直接说明”。
- 结果后处理:对生成内容进行引用标注、格式标准化,提升可信度。
2.2 RAG 的完整工作流程
- 文档加载与预处理:
- 支持 PDF、Word、CSV 等多种格式,通过提取、解析、清理将非结构化数据转为纯文本。
- 文本分块与向量化:
- 采用滑动窗口法或语义分割法将文档分割为段落,使用嵌入模型生成向量并存储于向量数据库(如 FAISS、Chroma)。
- 检索与重排序:
- 检索器通过余弦相似度等方法返回相关文档块,结合重排序模型(如 BERT)进一步优化结果。
- 答案生成:
- 采用 “Stuff” 方法将文档块直接输入 LLM,或通过 Map-reduce、Refine 等策略处理复杂查询。
三、RAG 的技术演进与优化策略
3.1 RAG 的类型与适用场景
- 原生 RAG:检索与生成组件紧密集成,适合低延迟场景。
- 检索与重排序 RAG:通过重排序模型提升检索结果相关性,适用于对准确性要求高的场景(如医疗问答)。
- 多模态 RAG:整合文本、图像、音频等多模态数据,适用于电商商品推荐、医学影像分析等场景。
- 图 RAG(GraphRAG):将数据构建为知识图谱,支持实体关系推理,适用于科研、社交网络等领域。
3.2 关键优化策略
- 数据预处理优化:
- 文档清洗:通过人工或大模型提炼文档,形成问答对形式,提升检索效率。
- 分块策略:针对不同文档类型(如技术手册、法律条文)采用差异化分块算法,避免语义断裂。
- 检索增强优化:
- 多路召回:同时使用向量检索、关键词检索、图检索等策略,覆盖更多潜在相关内容。
- 上下文窗口优化:通过动态调整检索结果长度,平衡信息丰富度与模型输入限制。
- 生成优化:
- 反馈学习:利用用户点击日志优化检索策略与提示模板,形成闭环迭代。
- 幻觉检测:引入轻量级评估器(如 Self-RAG 的评审器)验证生成内容的准确性。
四、RAG 的应用场景与典型案例
4.1 垂直领域深度应用
- 医疗健康:
- 案例:某在线健康平台整合医学文献、电子病历和检验报告,通过多模态 RAG 生成个性化治疗建议。例如,用户咨询 “高血压患者如何预防中风”,系统检索相关研究后,生成包含饮食建议、药物治疗注意事项的详细回答。
- 技术优化:使用 MeSH 词汇表提升医学术语检索精度,结合 ICD-10 编码实现病历智能解析。
- 法律科技:
- 案例:智能法务助手支持法律条款多维度检索(如时效性验证)、相似案例判决预测。例如,用户提问 “如何起诉医疗事故”,系统检索相关法规与判例,生成包含起诉流程、法律依据的回答。
- 技术优化:引入图结构建模法律实体关系,提升复杂条款推理能力。
- 金融合规:
- 案例:券商合规审查系统实时检索财报、市场趋势和监管文件,生成风险分析报告。例如,分析某上市公司财务数据时,结合最新监管政策识别潜在风险点。
- 技术优化:动态接入股票市场 API,确保检索数据的实时性。
4.2 企业级应用实践
- 智能客服:
- 案例:某电商平台通过 RAG 整合商品详情、用户评价和历史咨询记录,构建上下文感知对话系统。用户询问手机续航时,系统检索电池容量、测试数据等信息,生成精准回复。
- 技术优化:采用多路召回(向量召回 + 搜索召回)提升查全率,结合情感分析模型优化话术推荐。
- 知识管理:
- 案例:阿里云构建多粒度知识提取方案,按文档标题级别拆分内容,结合 Qwen-14B 模型生成事实型对话,帮助企业员工快速定位信息。
- 技术优化:通过去重和降噪处理确保知识不冗余,提升检索效果。
五、RAG 的技术选型与工具链
5.1 主流 RAG 框架对比
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| LangChain | 模块化链式结构,支持 700 + 工具集成,适合快速原型开发 | 电商客服、数据分析等复杂流程 |
| Haystack | 企业级部署优化,支持 K8s 原生部署和多模态处理 | 医疗、法律等专业领域 |
| DSPy | 声明式编程与自动调优,利用小模型实现低成本方案 | 数学推理、多模态检索 |
| LlamaIndex | 轻量级数据连接器,兼容多数据源,适合个人 / 小团队 | 文档问答、个人知识库 |
5.2 向量数据库选择指南
- FAISS:Facebook 开源的高效向量数据库,适合大规模高维向量管理。
- Chroma:专为 LLM 设计的开源内存数据库,支持快速原型开发。
- Pinecone:云端托管数据库,简化大规模 ML 应用部署,适合企业级场景。
- Weaviate:支持自托管的开源数据库,提供复杂查询和多模态检索能力。
5.3 性能与成本平衡
- 模型选择:
- 中短上下文:OpenAI O1-preview 在 2k-16k 词元场景下准确率显著优于 GPT-4o。
- 超长上下文:Google Gemini 1.5 在 200 万词元处理中表现稳定,适合大型文档解析。
- 成本优化:
- 小模型增强:DSPy 通过 T5-base 模型实现与 GPT-3.5 相当的性能,降低计算成本。
- 检索效率优化:采用 IVF+PQ 分层索引(如 FAISS)提升检索速度,减少 LLM 调用次数。
六、RAG 的挑战与未来趋势
6.1 当前技术挑战
- 检索准确性:语义相近文档可能导致检索混淆,需结合校正型 RAG(Corrective RAG)引入评估步骤。
- 数据隐私:医疗、金融等领域需通过数据脱敏、访问控制保障隐私,避免敏感信息泄露。
- 多模态整合:图像、音频等非结构化数据的检索与生成仍需进一步优化,如 Fast GraphRAG 的知识图谱建模。
6.2 未来发展方向
- 自我反思型 RAG(Self-RAG):
- 引入检索器、评审器、生成器协同工作,通过反馈循环优化检索决策,提升复杂推理能力。
- 动态知识图谱:
- 结合 GraphRAG 与 PageRank 算法,实现动态数据的快速关联检索,如 Fast GraphRAG 的开源实现。
- 多模态融合:
- 探索文本、图像、视频的联合检索与生成,例如电商虚拟试衣系统中的文生图应用。
- 伦理与公平性:
- 通过公平排名算法(如 RankCoT)减少偏见,确保生成内容的公正性与透明度。
七、总结
RAG 技术通过将大模型与外部知识库深度耦合,为解决知识滞后与幻觉问题提供了系统性方案。其核心价值在于:让大模型从‘记忆型’升级为‘检索型’智能体,通过动态知识注入实现领域专业性与实时性的双重突破。未来,随着校正型 RAG、自我反思型 RAG 等技术的成熟,以及多模态整合与伦理机制的完善,RAG 将成为企业智能化转型的核心基础设施,推动 AI 从通用对话向垂直领域深度赋能跨越。
参考文献
- RAG 技术详解:如何让大模型更 “懂” 知识库?
- 详解 RAG 技术:大模型时代让 AI 更懂你的智能知识引擎
- 2025 及未来 RAG 趋势:深入解析四大创新技术
- 开源 RAG 框架对比:LangChain、Haystack、DSPy 技术选型指南
- 大模型中的 RAG 实战案例分析
- RAG 在领域特定应用中的优化:医疗、法律与金融
- RAG 检索的底座:向量数据库
- 2025 年值得关注的 21 个 RAG 开源项目
(全文完)