计算机视觉——MedSAM2医学影像一键实现3D与视频分割的高效解决方案
引言
在乡村医院的傍晚高峰时段,扫描室内传来阵阵低沉的嗡鸣声,仿佛一台老旧冰箱的运转声。一位疲惫的医生正全神贯注地检查着当天的最后一位患者——一位不幸从拖拉机上摔下的农民,此刻正呼吸急促。CT 机器飞速旋转,生成了超过一千张的灰度图像。时间就是生命:是否存在肺部挫伤、隐匿性出血,亦或是其他更为严重的状况?在过去,医生需要逐一浏览这些切片,手动勾勒出肺部和肋骨的轮廓,然后才能决定对这位农民采取何种后续措施,这一过程往往耗时长达一小时甚至更久。然而,如今有了 MedSAM2,一切都发生了翻天覆地的变化。那么,它是如何实现这一突破的呢?
医生将所有图像上传至系统,并在胸部区域迅速绘制了一个边界框,MedSAM2 便能够精准地检测并分割出图像中的各个组织结构。短短几秒内,它便将肺部以绿色高亮显示,心脏以蓝色呈现,并在积血部位精准地标记出一个深红色的区域。医生随即呼叫外科团队,而这位农民甚至还未离开 CT 检查台,便已被紧急送往手术室。
这个小故事揭示了人工智能在医疗领域应用的一个重大转变。MedSAM2,由开发 MedSAM 的 WangLab 团队精心打造,能够以极高的效率勾勒出任何 3D 扫描或医学视频中的几乎所有部分。曾经耗时数小时的复杂任务,如今在短短几分钟内即可完成,这不仅为医生提供了更迅速的诊断依据,也为患者争取到了宝贵的治疗时间。
MedSAM2 的出现,标志着医学影像分析领域的一次质的飞跃。它通过深度学习和先进的图像处理技术,极大地简化了医学影像的分割流程。在传统的医学影像分析中,医生需要手动勾勒出病变区域的边界,这一过程不仅耗时费力,而且容易受到人为因素的影响。而 MedSAM2 的出现,不仅提高了分割的效率,还显著提升了分割的准确性和一致性。
MedSAM2 的核心优势在于其强大的自动化能力。它能够自动识别和分割医学影像中的各种结构,无论是复杂的器官还是微小的病变。这种自动化不仅减少了医生的工作量,还提高了诊断的准确性和可靠性。此外,MedSAM2 还具备实时处理的能力,能够在几秒钟内完成对大量影像数据的分析,为临床决策提供了即时的支持。
在实际应用中,MedSAM2 的价值已经得到了广泛的认可。它不仅能够快速分割出病变区域,还能为后续的治疗方案提供重要的参考。例如,在肿瘤治疗中,MedSAM2 可以精确地勾勒出肿瘤的边界,帮助医生制定更精准的放疗计划。在急诊室中,MedSAM2 能够迅速识别出出血或损伤区域,为紧急手术提供及时的指导。
一、医学人工智能的当前趋势
医学影像处于人工智能医疗繁荣的核心,而数字则讲述了一个惊悚故事。在短短十二个月内,全球人工智能在医学影像市场的规模 从 2023 年的约 10 亿美元 增长到 2024 年的 12.8 亿美元;分析师现在预测,到 2030 年代初,该行业将达到 140 亿至 240 亿美元 之间,这意味着年复合增长率超过 30%。
1.1 基础模型的兴起
为什么增长得如此之快?一个词:基础模型。就像 GPT 风格的语言模型 正在改写自然语言处理一样,视觉语言模型(如 SAM)正在彻底改变视觉领域。最近的一项 arXiv 调查显示,在过去 18 个月里,仅针对医学扫描的“分割任何内容”的衍生产品就有超过 40 个,并且出现了专门的会议议程和整个 CVPR 工作坊来涵盖它们。
1.2 分割是医疗保健的新入口
医院通常首先采用 AI 进行 分割,因为它是具体、可审计的,并且与现有工作流程相契合。更快、更锐利的边界意味着:
- 减少手术意外——肿瘤团队可以将放射束精确到亚毫米级。
- 急诊室快速读片——在 CT 切片上画一个边界框,像 MedSAM2 这样的模型可以在不到一秒钟的时间内勾勒出脾脏或出血病变。
- 更好的下游 AI——干净的掩模可以为体积肿瘤生长模型或 3D 打印管道提供数据,无需手动清理。
二、医学影像与 MedSAM2

医学影像就是 拍摄身体内部的图像。X 光检查骨骼,CT 将你像面包一样切片,MRI 检查软组织,PET 点亮代谢过程,超声波拍摄器官的动态图像。所有这些像素都让医生能够看到双手无法触及的地方。
工作量巨大 – 单次腹部 CT 扫描可以产生超过 1000 个切片;一次超声心动图可以记录心脏每秒跳动 60 次。手动为每个切片上色就像为整个皮克斯电影的每一帧涂色一样。
分割作为解决方案 – 点击一下或画一个框,软件就会填充精确的边界。从那里,你可以测量肿瘤体积、引导放射束或跟踪疾病数月。
MedSAM2 的作用 – 传统模型需要针对每个器官和每台扫描仪使用不同的权重。MedSAM2,即 针对医学用例的 Finetuned Segment Anything Model 2,则相反:一个大脑,所有模态。它在四个主要领域解决问题:
| 成像任务 | 旧痛点 | MedSAM2 如何解决 |
|---|---|---|
| CT 分割 | 病变边界与器官组织模糊 | 肝脏 DSC 达到 0.95,病变 DSC 达到 0.68——比 nnU-Net 高出约 5 个百分点 |
| MRI 分割 | 可变对比度隐藏肿瘤 | 在大脑和肝脏任务中 DSC 更高;轻松勾勒宫颈癌边缘 |
| PET 病变检测 | 噪声和良性摄取导致假阳性 | DSC 约为 0.68,当融合 PET+CT 时,质心误差约为 2 毫米 |
| 视频分割(超声和内窥镜) | 运动模糊和斑点噪声降低准确性 | 息肉 DSC 为 91.3%;实时超声心动图中心室边缘清晰 |
2.1 MedSAM2 的介绍
每一个重大突破通常都建立在坚实的基础之上,MedSAM2 也不例外。它的开发可以追溯到最近计算机视觉研究中最具影响力的一个模型:Meta AI 的 Segment Anything Model 2 (SAM2)。SAM 证明了一个单一的、由提示驱动的网络可以准确地分割自然图像中的几乎所有对象,从动物和车辆到日常物品,仅需最小的用户输入,例如一个点击。
2.2 SAM — MedSAM — SAM2 — MedSAM2
SAM (2023 年 4 月)
Meta AI 的第一个 Segment Anything Model 证明了一个点击可以勾勒出照片中的几乎所有对象。它从十亿自然图像掩模中学习,将分割变成了一种点选操作。
MedSAM (2023 年 4 月)
WangLab 的研究人员问道:“如果我们对医院扫描对 SAM 进行微调呢?”他们在 150 万张 CT、MRI 和 X 光切片上对模型进行了微调。MedSAM 现在可以像 SAM 勾勒咖啡杯一样勾勒肝脏和肿瘤,但每次只能处理一个切片,仍然只是纯 2D。
SAM2 (2024 年 11 月)
Meta 的升级保留了点击任何地方的精神,但用一个更轻的框架替换了更重的 Hiera 变压器骨干,引入了一个更整洁的提示和掩模头,使网络更快、更节省内存。SAM2 仍然只思考平面帧;它没有内置的方式来记住堆栈或剪辑中的一帧前后的内容。
MedSAM2 (2025 年 4 月)
最新的步骤结合了两者的优点。它保留了 SAM2 的快速 Hiera 核心,并添加了一个小型的内存注意力块,允许每个 CT 切片或视频帧查看其八个邻居。它在 10 种模态的混合数据(约 450k 个 3D 体积加上 76k 个视频帧)上进行训练,MedSAM 2 能够一次性理解整个体积和实时超声,同时仍然在普通工作站 GPU 上快速运行。
一句话总结:SAM 证明了这个想法,MedSAM 将其应用于医学领域,SAM 2 让它变得快速,而 MedSAM 2 通过为网络提供短期记忆,使其能够在完整的 3D 和实时视频中工作。
2.3 MedSAM2 的内部工作原理
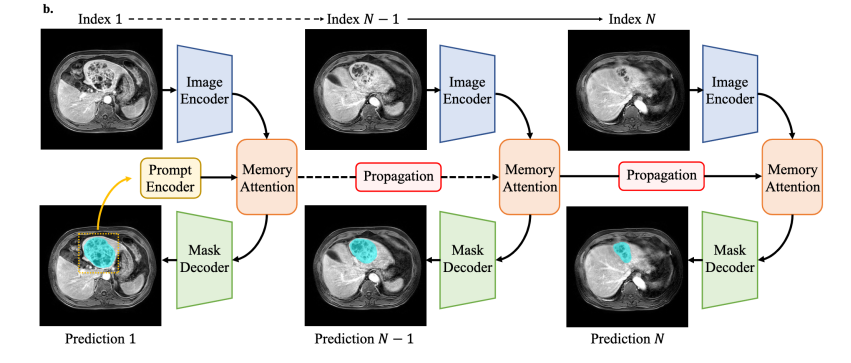
更小、更快的输入
图像尺寸缩小到 512×512,而不是 1024×1024,这与大多数医学切片匹配,并将计算量减半。
带有长距离注意力的 Hiera 主干
图像编码器是一个四阶段的 Hiera 视觉变换器。额外的全局注意力块允许相隔较远的像素(例如一条长血管的两端)共享信息。
3D 和视频的内存
在主干上方有 四个变换器层,它们从一个小型内存库中读取前一个切片或帧。旋转位置嵌入向模型精确地告知每个特征在空间或时间中的位置,确保相邻切片对齐干净,移动边界不会抖动。
微小的提示编码器
微小的提示编码器将用户的框、点或涂鸦转换为网络可以跟随的向量嵌入,就像在地图上放置一个标记一样。
掩模解码器
掩模解码器将提示线索与多尺度特征结合起来,生成一个 128×128 的掩模,然后将其放大回原始尺寸。一套权重现在可以勾勒出 CT 堆栈中的肝脏和超声视频中跳动的心室,仅通过一个快速点击来引导。
三、数据集准备和训练
3.1 MedSAM2 的数据集准备
为了训练 MedSAM2,团队首先构建了一个非常大的扫描数据集。它包含来自知名来源的 大约 450,000 个完整的 3D 研究,包括 LiTS、BraTS、KiTS、FLARE、TotalSegmentator、AutoPET 和几家医院档案。这些涵盖了 CT、MRI 和 PET,使模型接触到各种组织类型、成像设备和患者群体。他们还添加了大约 76,000 个视频帧,来自超声和内窥镜数据集,例如 EchoNet-Dynamic 和 Hyper-Kvasir,让网络感受到运动解剖学。
| 模态 | 关键公共数据集使用情况 | 它们为混合物增添了什么 |
|---|---|---|
| CT 3D | LiTS(肝脏 + 肿瘤)、KiTS19(肾脏)、FLARE22(多器官)、TotalSegmentator(104 个结构) | 高对比度器官和多样化的病变 |
| MRI 3D | BraTS(脑肿瘤)、ACDC(心脏)、CHAOS(腹部器官)、MSD #01–10 | 软组织边缘,可变对比度 |
| PET/CT | AutoPET、头颈癌分割、MICCAI TOTALSEG-PET 子集 | 热病变与冷病变边界 |
| 超声视频 | EchoNet-Dynamic & CAMUS(心脏)、CLUST(胎儿) | 运动 + 斑点噪声 |
| 内窥镜视频 | Hyper-Kvasir、Kvasir-SEG、PolypGen | 息肉形状、光照变化 |
每个文件都经过了相同的清理步骤:
- CT 切片被调整为一毫米立方体,其灰度值被裁剪到正常范围。
- MRI 和超声图像被调整,使暗部和亮部处于相似的范围。
- 视频剪辑被裁剪为 512×512 像素,并固定为每秒 30 帧。
旧模型(3D 使用 nnU-Net,视频使用小型 Mask R-CNN)为每个文件绘制了一个“启动”掩模。人类审阅者随后打开一个网页工具,该工具用红色突出显示每个掩模的不稳定部分;他们只需要清理这些部分。
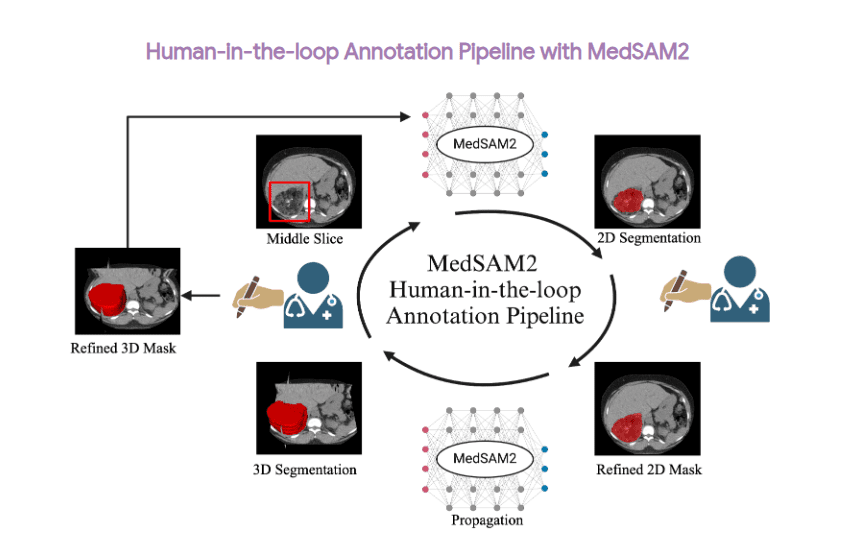
在 MedSAM2 论文中读到过 三个额外的数据集:一个用于 CT 病变(DeepLesion),一个用于 MRI 肝肿瘤(LLD-MMRI),以及一个用于超声视频(RVENet)。这些 没有 加入大型训练池。作者将它们保留用于后续实验。首先,他们测量了医生在这些扫描上纠正 MedSAM2 初始掩模所需的时间,并与手工绘制相比,显示出 手工绘制减少了 85-92% 的劳动量。接下来,他们在纠正后的掩模上进行了简短的额外微调,额外获得了 3-6 个 Dice 点。他们还发布了这些数据集的 MedSAM2 注释版本。
3.2 训练调整
一个大型混合数据集 – MedSAM2 在 大约 450,000 个标记的 CT、MRI 和 PET 扫描以及 76,000 个标记的超声和内窥镜视频帧上进行了训练。每个文件都被调整为 512×512(或 3D 的 1 mm³ 体素),并放在相同的灰度尺度上,因此模型无需猜测“亮”或“暗”的含义。
快速“草稿和修复”标签 – 旧网络(3D 使用 nnU-Net,视频使用小型 Mask R-CNN)绘制了粗糙的掩模。人类审阅者只修复了软件用红色标记的杂乱边缘。这将标签速度提高了十倍。
平衡批次 – CT 常见,PET 稀有。在训练期间,加载器悄悄地将 PET 和内窥镜切片的显示频率提高近两倍,并将任何单个 CT 研究限制在批次的 5% 以内。这使得模型不会变成“仅 CT”专家。
四、代码流程
现在开始使用模型。为此,需要克隆官方的 MedSAM2 仓库。
git clone https://github.com/bowang-lab/MedSAM2.git && cd MedSAM2
然后将创建一个虚拟环境来运行所有实验。
conda create -n medsam2 python=3.12 -y && conda activate medsam2
然后运行此命令以安装所有依赖项
pip install torch torchvision
pip install -e ".[dev]"
最后一步,通过运行以下命令下载 MedSAM2 检查点:
sh download.sh
现在已经完成了设置;让我们继续主代码。我们将探索两个主要应用。
4.1 CT 病变分割
CT 扫描(计算机断层扫描) 是一种医学成像技术,可以让医生以极高的细节查看身体内部。与仅显示平面图像的常规 X 光不同,CT 扫描通过旋转的 X 射线束和计算机创建许多横截面图像(称为切片),从而生成骨骼、器官、血管和软组织的详细图像。这些图像可以单独查看,也可以重建为 3D 模型,为医生提供对患者病情的更清晰的理解。
在这里,我们将对 骨盆 的 3D CT 扫描图像 进行处理,查看 轴向切片(水平横截面),并尝试使用 MedSAM2 分割病变(可能是前列腺肿瘤)。
4.2 第一部分:导入、设置和参数解析
这部分脚本设置了必要的环境并获取用户输入。它导入了各种 Python 库,用于文件处理(os、glob)、数值运算(numpy)、数据操作(pandas)、图像处理(PIL、SimpleITK、skimage)、深度学习(torch)和绘图(matplotlib)。
它还为 PyTorch 和 NumPy 设置了随机种子,以确保如果使用相同的输入多次运行脚本,您将获得相同的结果(可重复性)。torch.set_..._precision(...) 行可能会优化特定较新 GPU 上的矩阵乘法性能。
from glob import glob
from tqdm import tqdm
import os
from os.path import join, basename
import re
import matplotlib.pyplot as plt
from collections import OrderedDict
import pandas as pd
import numpy as np
import argparse
from PIL import Image
import SimpleITK as sitk
import torch
import torch.multiprocessing as mp
from sam2.build_sam import build_sam2_video_predictor_npz # 特定于 NPZ 输入的预测器
import SimpleITK as sitk
from skimage import measure, morphology# 设置随机种子以确保可重复性,并配置 PyTorch 性能
torch.set_float32_matmul_precision('high')
torch.manual_seed(2024)
torch.cuda.manual_seed(2024)
np.random.seed(2024)# 初始化参数解析器
parser = argparse.ArgumentParser()# 添加命令行参数
parser.add_argument('--checkpoint',type=str,default="checkpoints/MedSAM2_latest.pt",help='检查点路径',
)
parser.add_argument('--cfg',type=str,default="configs/sam2.1_hiera_t512.yaml",help='模型配置',
)
# 更多参数(此处省略)# 解析命令行提供的参数
args = parser.parse_args()
checkpoint = args.checkpoint
model_cfg = args.cfg
imgs_path = args.imgs_path
gts_path = args.gts_path
pred_save_dir = args.pred_save_dir
# 确保输出目录存在,不存在则创建
os.makedirs(pred_save_dir, exist_ok=True)
propagate_with_box = args.propagate_with_box
这一部分通过导入必要的工具、设置可重复性结果以及定义用户可以通过命令行与之交互的方式(控制其行为和输入/输出位置),为脚本做好了准备。解析后的参数随后存储在变量中,供后续使用。
4.3 第二部分:辅助函数
这一部分定义了几个稍后在脚本中使用的实用函数,用于执行图像预处理、创建提示、分割后处理以及可能的可视化或评估任务。
def getLargestCC(segmentation):"""从二值分割掩模中找到最大的连通分量"""labels = measure.label(segmentation)if labels.max() == 0: # 处理空分割return segmentationlargestCC = labels == np.argmax(np.bincount(labels.flat)[1:]) + 1return largestCC
getLargestCC(segmentation):此函数接收一个二值分割掩模(一个数组,其中属于分割对象的像素为 1,背景为 0),并执行后处理。它识别所有独立的“块”或连通区域(前景像素)。然后,它找到最大的块(像素最多的那个),并返回一个仅包含这个最大区域的新掩模。
def dice_multi_class(preds, targets):"""计算多类别分割的 Dice 相似性系数(DSC),这是评估分割性能的常用指标"""smooth = 1.0assert preds.shape == targets.shapelabels = np.unique(targets)[1:]dices = []for label in labels:pred = preds == labeltarget = targets == labelintersection = (pred * target).sum()dices.append((2.0 * intersection + smooth) / (pred.sum() + target.sum() + smooth))return np.mean(dices)
dice_multi_class(preds, targets):计算 Dice 相似性系数(DSC),这是评估分割性能的常用指标。它比较预测的分割(preds)与真实标签(targets)。它为每个不同的目标标签(忽略背景标签 0)计算 DSC,并返回平均分数。
def show_mask(mask, ax, mask_color=None, alpha=0.5):"""在图像图上显示掩模叠加"""if mask_color is not None:color = np.concatenate([mask_color, np.array([alpha])], axis=0)else:color = np.array([251/255, 252/255, 30/255, alpha]) # 默认黄色h, w = mask.shape[-2:]mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)ax.imshow(mask_image)def show_box(box, ax, edgecolor='blue'):"""在图像图上绘制边界框"""x0, y0 = box[0], box[1]w, h = box[2] - box[0], box[3] - box[1]ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor=edgecolor, facecolor=(0, 0, 0, 0), lw=2))
show_mask(…) 和 show_box(…):这些是与 matplotlib 配合使用的可视化辅助工具。show_mask 在图像图(ax)上叠加一个半透明的彩色掩模,而 show_box 在图上绘制一个矩形(边界框)。
def resize_grayscale_to_rgb_and_resize(array, image_size):"""将 3D 灰度 NumPy 数组调整为 RGB 图像,然后调整大小"""d, h, w = array.shape # 输入 3D 体积的深度、高度、宽度resized_array = np.zeros((d, 3, image_size, image_size)) # 初始化输出数组for i in range(d): # 遍历每个深度方向的切片img_pil = Image.fromarray(array[i].astype(np.uint8)) # 将 2D 灰度切片转换为 PIL 图像对象img_rgb = img_pil.convert("RGB") # 将 PIL 图像转换为 RGB 格式(复制单通道 3 次)img_resized = img_rgb.resize((image_size, image_size)) # 将 RGB 图像调整为目标大小img_array = np.array(img_resized).transpose(2, 0, 1) # 将调整大小的 PIL 图像转换回 NumPy 数组,并更改布局resized_array[i] = img_array # 将处理后的切片存储到输出数组中return resized_array
resize_grayscale_to_rgb_and_resize(array, image_size):这是一个关键的预处理函数。SAM2(与原始 SAM 一样)期望 RGB 图像具有特定的正方形大小(此处为 512×512,基于配置文件 --cfg configs/sam2.1_hiera_t512.yaml)。医学图像(如 CT 扫描)通常是灰度的,且尺寸各异。此函数接收一个 3D NumPy 数组(深度、高度、宽度),表示灰度体积,遍历每个 2D 切片,将其转换为 3 通道的 RGB 图像(通过简单复制灰度通道),调整到所需大小,并重新排列维度,以匹配 PyTorch 模型期望的(通道、高度、宽度)格式。输出是一个 4D NumPy 数组(深度、3、image_size、image_size)。
def mask2D_to_bbox(gt2D, max_shift=20):"""从 2D 掩模计算紧密的边界框"""y_indices, x_indices = np.where(gt2D > 0)if len(x_indices) == 0: # 处理空掩模return np.array([0, 0, 0, 0]) # 返回零边界框x_min, x_max = np.min(x_indices), np.max(x_indices)y_min, y_max = np.min(y_indices), np.max(y_indices)H, W = gt2D.shapebbox_shift = np.random.randint(0, max_shift + 1, 1)[0]x_min = max(0, x_min - bbox_shift)x_max = min(W - 1, x_max + bbox_shift)y_min = max(0, y_min - bbox_shift)y_max = min(H - 1, y_max + bbox_shift)boxes = np.array([x_min, y_min, x_max, y_max]) # XYXY 格式return boxesdef mask3D_to_bbox(gt3D, max_shift=20):"""从 3D 掩模计算紧密的边界框"""z_indices, y_indices, x_indices = np.where(gt3D > 0)if len(x_indices) == 0: # 处理空掩模return np.array([0, 0, 0, 0, 0, 0]) # 返回零边界框x_min, x_max = np.min(x_indices), np.max(x_indices)y_min, y_max = np.min(y_indices), np.max(y_indices)z_min, z_max = np.min(z_indices), np.max(z_indices)D, H, W = gt3D.shapebbox_shift = np.random.randint(0, max_shift + 1, 1)[0]x_min = max(0, x_min - bbox_shift)x_max = min(W - 1, x_max + bbox_shift)y_min = max(0, y_min - bbox_shift)y_max = min(H - 1, y_max + bbox_shift)z_min = max(0, z_min) # 通常在关键切片提示中不移动 Z 方向z_max = min(D - 1, z_max)boxes3d = np.array([x_min, y_min, z_min, x_max, y_max, z_max]) # XYZXYZ 格式return boxes3d
mask2D_to_bbox(gt2D, max_shift=20) / mask3D_to_bbox(gt3D, max_shift=20):这些函数接收一个 2D 或 3D 二值掩模,并计算围绕前景像素(目标)的最紧边界框。它们找到包含目标的最小和最大 x、y(以及 3D 中的 z)坐标。还可以选择性地在边界框坐标上添加一个随机“偏移”,稍微扩展边界框。这可能用于从现有掩模生成边界框提示,例如用于训练数据增强或模拟用户输入的轻微不精确性。然而,由于此脚本默认使用 propagate_with_box=True 并从 CSV 文件中获取边界框,这些掩模到边界框的函数可能不会在标准执行路径中使用。
4.4 第三部分:主处理循环
这是脚本的核心部分,实际执行分割操作。它遍历输入目录中找到的每个 3D CT 扫描文件。
首先,脚本从 CSV 文件中加载有关病变的信息。这个文件作为一个指南,指示 CT 扫描中病变的位置,包括特定切片上的边界框和查看的最优对比度设置(DICOM 窗口)。然后,它在用户提供的文件夹(imgs_path)中找到所有 3D CT 扫描文件(.nii.gz)。它清理这个列表以忽略临时文件,并打印出它找到的扫描数量。
# 从 CSV 文件加载病变的元数据
DL_info = pd.read_csv('CT_DeepLesion/DeepLesion_Dataset_Info.csv')# 找到指定图像目录中的所有 '.nii.gz' 文件
nii_fnames = sorted(os.listdir(imgs_path))
nii_fnames = [i for i in nii_fnames if i.endswith('.nii.gz')]
# 过滤掉隐藏或临时文件
nii_fnames = [i for i in nii_fnames if not i.startswith('._')]
print(f'Processing {len(nii_fnames)} nii files')# 初始化一个有序字典来存储结果信息
seg_info = OrderedDict()
seg_info['nii_name'] = []
seg_info['key_slice_index'] = []
seg_info['DICOM_windows'] = []# 初始化 MedSAM2 预测器模型
predictor = build_sam2_video_predictor_npz(model_cfg, checkpoint)
最后,它设置了一个字典(seg_info)来跟踪生成的结果,并使用 build_sam2_video_predictor_npz 函数初始化 MedSAM2 模型,加载指定的配置和预训练权重。这个预测器旨在处理图像数据序列,例如 3D 扫描的切片。
4.4.1 处理每个 CT 扫描文件
脚本现在进入主循环,逐个处理每个 .nii.gz 文件。对于每个扫描文件,它首先从文件名中提取信息(例如它覆盖的切片范围和唯一的病例标识符),以帮助找到之前加载的 DL_info 表中对应的病变详细信息。
然后,它使用 SimpleITK 库将实际的 3D 图像数据从 .nii.gz 文件加载到 NumPy 数组中。它过滤 DL_info 表以仅获取与当前 CT 扫描文件匹配的行。由于一个扫描可能在 CSV 中列出多个病变,它准备了一个空的 3D 数组(segs_3D_volume),其大小与输入扫描相同,用于存储该扫描中找到的所有病变的组合分割结果。
# 遍历每个检测到的 NIfTI 文件
for nii_fname in tqdm(nii_fnames):# 开始处理一个 NIfTI 文件range_suffix = re.findall(r'\d{3}-\d{3}', nii_fname)[0]slice_range = range_suffix.split('-')slice_range = [str(int(s)) for s in slice_range]slice_range_str = ', '.join(slice_range) # 用于匹配 CSV 的格式# 加载 3D 图像体积并转换为 NumPy 数组nii_image = sitk.ReadImage(join(imgs_path, nii_fname))nii_image_data = sitk.GetArrayFromImage(nii_image) # 形状:(深度,高度,宽度)case_name = re.findall(r'^(\d{6}_\d{2}_\d{2})', nii_fname)[0]# 在 CSV 中找到与该扫描文件匹配的病变条目case_df = DL_info[DL_info['File_name'].str.contains(case_name) &DL_info['Slice_range'].str.contains(slice_range_str)].copy()# 为该体积的组合分割掩模初始化一个空的 3D 数组segs_3D_volume = np.zeros(nii_image_data.shape, dtype=np.uint8)# 遍历 CSV 中为该 NIfTI 文件找到的每个病变for row_id, row in case_df.iterrows():# 开始处理 NIfTI 文件中的一个病变# [病变处理代码在内部循环中]# ...
这部分按顺序组织处理过程,一次处理一个完整的 3D 扫描,并为该扫描中列出的每个病变分别进行处理。
4.4.2 单个病变的预处理
在内部循环(处理 CSV 中的一个特定病变)中,脚本根据该病变进行了量身定制的预处理。它从 CSV 行中读取 DICOM 窗口设置(对比度/亮度级别),并将其应用于整个加载的 3D 体积(nii_image_data)。这个裁剪和归一化步骤(np.clip,归一化到 0-255)使病变根据元数据更容易被看到。
然后,它识别 CSV 中提供的“关键切片”索引,并计算其在加载的 NumPy 数组段中的对应索引。边界框坐标也从 CSV 中提取,并转换为 [x_min, y_min, x_max, y_max](XYXY)格式。经过窗口化/归一化处理的原始 3D 图像数据存储在 img_3D_ori 中,以便稍后可能使用(例如与掩模一起保存)。
# 1. 加载病变的元数据并预处理图像切片
lower_bound, upper_bound = row['DICOM_windows'].split(',')
lower_bound, upper_bound = float(lower_bound), float(upper_bound)# 应用窗口化并归一化到 0-255 (uint8)
nii_image_data_pre = np.clip(nii_image_data, lower_bound, upper_bound)
nii_image_data_pre = (nii_image_data_pre - np.min(nii_image_data_pre)) / (np.max(nii_image_data_pre) - np.min(nii_image_data_pre)) * 255.0
nii_image_data_pre = np.uint8(nii_image_data_pre)# 获取关键切片索引和边界框
key_slice_idx_csv = int(row['Key_slice_index'])
slice_idx_start, slice_idx_end = map(int, row['Slice_range'].split(','))
key_slice_idx_offset = key_slice_idx_csv - slice_idx_startbbox_coords = list(map(int, map(float, row['Bounding_boxes'].split(',')))) # ymin, xmin, ymax, xmax
bbox_xyxy = np.array([bbox_coords[1], bbox_coords[0], bbox_coords[3], bbox_coords[2]]) # xmin, ymin, xmax, ymax# 存储该病变的预处理 3D 体积数据
img_3D_ori = nii_image_data_pre
assert np.max(img_3D_ori) < 256, 'Input data should be uint8 range [0, 255]'# 获取原始高度/宽度,以便稍后调整输出大小
key_slice_img = nii_image_data_pre[key_slice_idx_offset, :, :]
video_height, video_width = key_slice_img.shape[0], key_slice_img.shape[1]
这一步根据特定病变的元数据准备图像数据,确保对比度最佳,并提取必要的提示信息(边界框)。
4.4.3 为 MedSAM2 准备输入张量
在基本预处理之后,数据需要进一步转换以匹配 MedSAM2 模型期望的输入格式。调用 resize_grayscale_to_rgb_and_resize 函数,将 3D 灰度体积(img_3D_ori)转换为 512×512 的 RGB 图像堆栈(尽管原始图像是灰度的,但模型期望有 3 个通道)。
像素值被缩放到 [0.0, 1.0] 范围内。然后,这个 NumPy 数组被转换为 PyTorch 张量,并移动到 GPU(cuda)。最后,应用标准的 ImageNet 归一化(减去每个通道的均值并除以标准差)。结果(img_resized)是一个张量,已准备好输入到 MedSAM2 预测器中。
# 2. 为 MedSAM2 模型准备输入
img_resized = resize_grayscale_to_rgb_and_resize(img_3D_ori, 512) # 形状:(D, 3, 512, 512)
# 将像素值归一化到 0.0-1.0
img_resized = img_resized / 255.0
# 将 NumPy 数组转换为 PyTorch 张量并移动到 GPU
img_resized = torch.from_numpy(img_resized).cuda()# 定义并应用 ImageNet 归一化
img_mean = (0.485, 0.456, 0.406)
img_std = (0.229, 0.224, 0.225)
img_mean = torch.tensor(img_mean, dtype=torch.float32)[:, None, None].cuda()
img_std = torch.tensor(img_std, dtype=torch.float32)[:, None, None].cuda()
img_resized -= img_mean
img_resized /= img_std
这是实际分割之前的最后一步准备,确保数据的维度、格式和值范围正是深度学习模型所期望的。
4.5 运行 MedSAM2 推理
现在,开始对当前病变进行核心分割处理。创建一个空的 3D NumPy 数组(segs_3D_lesion),用于存储该病变的分割掩模。代码使用 torch.inference_mode() 和 torch.autocast 以优化推理性能(更快的计算,可能在兼容的 GPU 上使用较低精度的计算,例如 bfloat16)。
首先,调用预测器的 init_state 方法,传入预处理后的图像张量(img_resized)。这可能计算并存储了该体积的初始图像嵌入。然后,使用 predictor.add_new_points_or_box 将之前识别的关键切片上的边界框(bbox_xyxy)作为提示添加到模型中。
然后,调用 predictor.propagate_in_video 来执行从关键切片向体积末尾的前向分割传播。这个函数内部会遍历所有切片,利用模型的内部记忆来保持一致性。对于每个切片(out_frame_idx),它返回该切片的掩模 logits(out_mask_logits)。脚本将这些 logits 通过阈值(默认为 0.0)转换为二值掩模,并将对应的像素标记在 segs_3D_lesion 数组中。
在完成前向传播后,重置预测器的内部状态(清除记忆),再次将初始边界框提示添加到关键切片中。然后,调用 predictor.propagate_in_video(..., reverse=True) 来从关键切片向体积开头执行反向分割传播。得到的二值掩模再次用于更新 segs_3D_lesion 数组。使用逻辑或运算确保在正向或反向传播中分割的像素都包含在最终的病变掩模中。最后,再次重置预测器状态。
# 3. 对当前病变运行 MedSAM2 推理
segs_3D_lesion = np.zeros(nii_image_data.shape, dtype=np.uint8) # 该特定病变的掩模
with torch.inference_mode(), torch.autocast(device_type="cuda", dtype=torch.bfloat16):# 初始化预测器状态inference_state = predictor.init_state(img_resized, video_height, video_width)# 在关键切片上添加初始边界框提示if propagate_with_box:predictor.add_new_points_or_box(inference_state=inference_state,frame_idx=key_slice_idx_offset,obj_id=1, # 为该病变对象分配 ID 1box=bbox_xyxy,)else: # gt(默认不使用)pass# 从关键切片向前传播分割for out_frame_idx, _, out_mask_logits in predictor.propagate_in_video(inference_state):binary_mask = (out_mask_logits[0] > 0.0).cpu().numpy()[0]segs_3D_lesion[out_frame_idx, binary_mask] = 1 # 标记分割像素# 在反向传播前重置预测器状态predictor.reset_state(inference_state)# 再次添加初始提示以进行反向传播if propagate_with_box:predictor.add_new_points_or_box(inference_state=inference_state,frame_idx=key_slice_idx_offset,obj_id=1,box=bbox_xyxy,)else: # gtpass# 从关键切片向后传播分割for out_frame_idx, _, out_mask_logits in predictor.propagate_in_video(inference_state, reverse=True):binary_mask = (out_mask_logits[0] > 0.0).cpu().numpy()[0]segs_3D_lesion[out_frame_idx, binary_mask] = 1 # 更新掩模(逻辑或)# 完成该病变后重置状态predictor.reset_state(inference_state)
这种双向传播是 MedSAM2 利用初始提示及其时间一致性机制在多个切片中分割病变的关键步骤。
4.5.1 后处理和合并结果
在完成单个病变的正向和反向传播后,得到的掩模(segs_3D_lesion)可能包含小的、不连续的区域或噪声。脚本检查是否实际发生了分割(np.max(segs_3D_lesion) > 0)。如果是,它调用 getLargestCC 函数进行后处理,仅保留分割像素的最大连通分量。
清理后,将这个清理过的掩模与整个 NIfTI 体积的主分割掩模(segs_3D_volume)合并,使用逻辑或运算。这确保了如果对同一个扫描文件处理多个病变,它们的分割结果将累积到最终输出掩模中。
# 4. 对当前病变的分割结果进行后处理
if np.max(segs_3D_lesion) > 0:# 仅保留最大连通分量(去除噪声)segs_3D_lesion = getLargestCC(segs_3D_lesion)segs_3D_lesion = np.uint8(segs_3D_lesion)# 5. 将当前病变的分割结果与体积的分割结果合并
# 如果体积中有多个病变,使用逻辑或运算合并掩模
segs_3D_volume = np.logical_or(segs_3D_volume, segs_3D_lesion).astype(np.uint8)
这一步清理了单个病变的分割结果,并将其合并到整个扫描体积的最终输出中。
4.5.2 保存最终结果
在内部循环结束(即处理完当前 NIfTI 文件在 CSV 中列出的所有病变后),脚本保存结果。它将最终的 NumPy 分割数组(segs_3D_volume)转换回 SimpleITK 图像对象。关键的是,它将空间元数据(例如间距、原点和方向)从原始输入 NIfTI 图像(nii_image)复制到新的掩模图像(sitk_mask)。这确保了保存的掩模在医学查看器中与原始扫描正确对齐。
它还保存了经过预处理(窗口化)的输入图像(img_3D_ori,来自最后一个处理的病变)以供参考。根据原始输入文件名构建文件名,添加后缀(如 _img.nii.gz 和 _mask.nii.gz,并包含最后一个病变的关键切片索引)。最后,它将保存的掩模文件的信息(文件名、关键切片索引、最后一个病变使用的 DICOM 窗口)记录到 seg_info 字典中。
# --- 结束处理一个 NIfTI 文件 ---(外部循环在此之后继续) ---
# 6. 为整个 NIfTI 体积保存结果
# 将最终 NumPy 掩模转换为 SimpleITK 图像
sitk_mask = sitk.GetImageFromArray(segs_3D_volume)
# 从原始 NIfTI 复制空间元数据
sitk_mask.CopyInformation(nii_image)# 准备预处理图像以供保存
sitk_image_preprocessed = sitk.GetImageFromArray(img_3D_ori)
sitk_image_preprocessed.CopyInformation(nii_image)# 定义输出文件名
key_slice_idx_csv = int(row['Key_slice_index']) # 来自最后一个处理的行的关键切片
save_seg_name = nii_fname.split('.nii.gz')[0] + f'_k{key_slice_idx_csv}_mask.nii.gz'
save_img_name = nii_fname.replace('.nii.gz', '_img.nii.gz')# 将预处理图像和最终分割掩模写入磁盘
sitk.WriteImage(sitk_image_preprocessed, os.path.join(pred_save_dir, save_img_name))
sitk.WriteImage(sitk_mask, os.path.join(pred_save_dir, save_seg_name))# 记录保存的分割的元数据
seg_info['nii_name'].append(save_seg_name)
seg_info['key_slice_index'].append(key_slice_idx_csv)
seg_info['DICOM_windows'].append(row['DICOM_windows'])
这是为每个处理的 CT 扫描体积生成并保存最终输出的地方,同时保存相关的元数据。
4.5.3 保存摘要信息
在主外部循环完成处理输入目录中的所有 NIfTI 文件后,脚本将 seg_info 字典(收集了每个生成的分割掩模的文件名、关键切片索引和 DICOM 窗口)转换为 Pandas DataFrame。然后,将该 DataFrame 保存为 CSV 文件(在指定的输出目录中命名为 tiny_seg_info202412.csv)。这个摘要文件提供了一种方便的方式来跟踪哪个输出掩模对应于哪个输入文件和关键切片提示。
# 在处理完所有 NIfTI 文件后,将收集的分割信息保存为 CSV 文件
seg_info_df = pd.DataFrame(seg_info)
seg_info_df.to_csv(os.path.join(pred_save_dir, 'tiny_seg_info202412.csv'), index=False)
以下是结果:
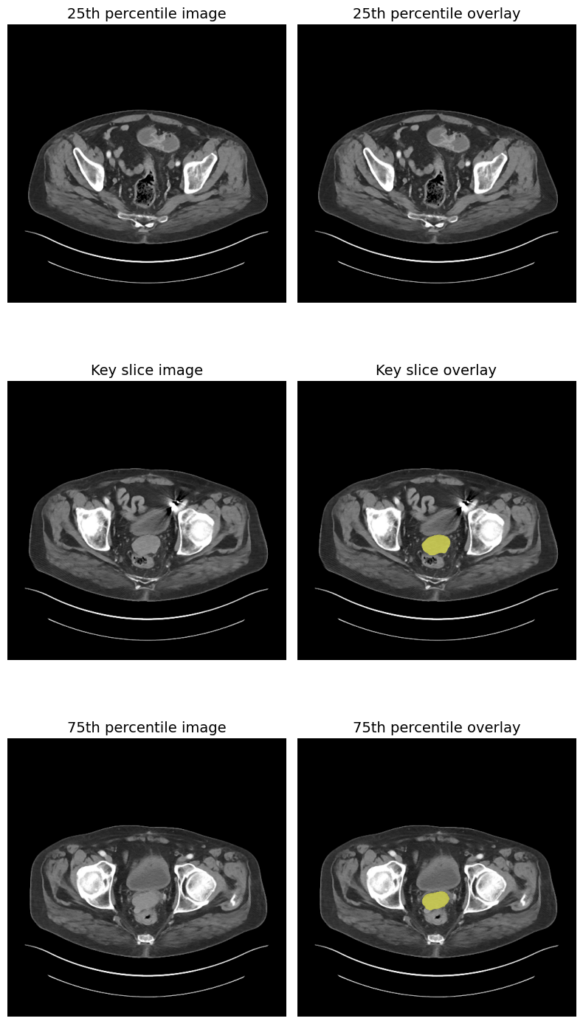
骨盆病变的 3D CT 分割
可以看到模型在骨盆中分割了一个小结构,很可能是 膀胱 或者可能是 前列腺肿瘤 或 盆腔肿块,具体取决于临床任务。这不是很酷吗!这可以为医生和外科医生节省大量时间,帮助他们快速做出决策,从而拯救数百万生命,使我们的医疗系统更加智能和高效。
4.6 视频分割 – 心脏超声
在这一部分,我们将使用患者的超声心动图(或“超声心动图”)视频来检查心脏,例如左心室(主要泵血腔室)、心肌壁以及附近的区域。

超声心动图(专门用于成像 心脏 的超声类型)图像,特别是,它看起来像是心脏的 四腔视图(4CH),这在心脏超声检查中经常使用。
在 4CH 视图中,你通常可以看到:
- 左心房和右心房(顶部腔室)
- 左心室和右心室(底部腔室)
- 房间隔和室间隔(分隔腔室的壁)
我们将尝试使用这个 4CH 视频,看看 MedSAM2 如何分割心脏的各个部分。
4.6.1 导入和设置
这部分导入了必要的库,包括 argparse、os、collections、defaultdict、numpy 和 torch 等。它特别导入了 MedSAM2 库中的 build_sam2_video_predictor,这是处理视频分割推理的主要类。
# 版权声明
# 版权所有 (c) Meta Platforms, Inc. 及其关联公司。
# 保留所有权利。# 本源代码根据根目录中的许可证文件授权。import argparse
import os
from collections import defaultdictimport numpy as np
import torch
from PIL import Image
from sam2.build_sam import build_sam2_video_predictor# DAVIS 2017 数据集的 PNG 调色板
DAVIS_PALETTE = b"\x00\x00\\...@`\xe0@\xe0\xe0@``\xc0\xe0`\xc0`\xe0\xc0\xe0\xe0\xc0"
脚本还定义了 DAVIS_PALETTE,这是 DAVIS 2017 视频分割基准数据集中使用的特定调色板。这个调色板允许将多目标分割掩模保存为一个 PNG 图像,其中每个对象 ID 对应一个唯一的颜色。这对于在标准基准上进行可视化和评估很有用。
4.6.2 PNG 掩模处理辅助函数
这一部分定义了几个专门用于读取和写入以 PNG 图像文件形式存储的分割掩模的函数。这些格式在视频目标分割数据集中很常见。
def load_ann_png(path):"""从 PNG 文件加载掩模及其调色板"""# 使用 PIL 打开 PNG 图像文件mask = Image.open(path)# 获取嵌入在 PNG 中的调色板(如果存在)palette = mask.getpalette()# 将 PIL 图像转换为 NumPy 数组(无符号 8 位整数,uint8)mask = np.array(mask).astype(np.uint8)# 返回掩模数据(作为 NumPy 数组)和调色板return mask, palette
load_ann_png(path):此函数读取一个 PNG 文件,该文件预期是一个分割掩模,通常使用特定的调色板(如之前定义的 DAVIS_PALETTE)。它使用 Pillow(PIL)库打开图像,提取掩模数据为 NumPy 数组(其中像素值通常表示对象 ID),并提取与图像相关的调色板。
def save_ann_png(path, mask, palette):"""将掩模作为带有给定调色板的 PNG 文件保存"""# 确保掩模数据是 uint8 类型且为二维(高度 x 宽度)assert mask.dtype == np.uint8assert mask.ndim == 2# 将 NumPy 数组转换回 PIL 图像对象output_mask = Image.fromarray(mask)# 将提供的调色板应用于图像output_mask.putpalette(palette)# 将图像保存到指定路径output_mask.save(path)
save_ann_png(path, mask, palette):这是 load_ann_png 的对应函数。它接收一个 NumPy 数组表示的掩模和一个调色板,创建一个 PIL 图像对象,将调色板应用于该图像,然后将其作为 PNG 文件保存到指定路径。
def get_per_obj_mask(mask):"""将掩模拆分为每个对象的掩模"""# 在掩模中找到所有唯一的像素值(对象 ID)object_ids = np.unique(mask)# 过滤掉背景 ID(通常是 0)object_ids = object_ids[object_ids > 0].tolist()# 创建一个字典:键是对象 ID,值是二值(True/False)掩模# 其中 True 表示属于该特定对象 ID 的像素per_obj_mask = {object_id: (mask == object_id) for object_id in object_ids}return per_obj_mask
get_per_obj_mask(mask):此函数接收一个掩模(如通过 load_ann_png 加载的),其中不同对象由不同像素值(例如,对象 1 是值 1,对象 2 是值 2)表示。它识别所有存在的非零对象 ID,并创建一个字典。字典中的每个键是一个对象 ID,对应的值是一个二值(True/False)掩模,仅表示属于该特定对象的像素。
def put_per_obj_mask(per_obj_mask, height, width):"""将每个对象的掩模合并为一个掩模"""# 创建一个填充零的空掩模(背景)mask = np.zeros((height, width), dtype=np.uint8)# 从输入字典中获取对象 ID,按逆序排序# (如果掩模重叠,较高的 ID 会覆盖较低的 ID,这在 VOS 中很常见)object_ids = sorted(per_obj_mask)[::-1]for object_id in object_ids:# 获取当前对象 ID 的二值掩模object_mask = per_obj_mask[object_id]# 确保它具有正确的形状(高度 x 宽度)object_mask = object_mask.reshape(height, width)# 将对象 ID 值分配给二值掩模为 True 的像素mask[object_mask] = object_idreturn mask
put_per_obj_mask(per_obj_mask, height, width):此函数的作用与 get_per_obj_mask 相反。它接收一个二值掩模的字典(如 get_per_obj_mask 或模型输出产生的),并将它们合并为一个单一的掩模图像。属于对象 ID n 的像素在输出掩模中将被分配值 n。它通过按对象 ID 的逆序处理来处理潜在的重叠,即较高的 ID 优先。
def load_masks_from_dir(input_mask_dir, video_name, frame_name, per_obj_png_file, allow_missing=False):"""从目录加载掩模作为每个对象的掩模字典"""if not per_obj_png_file: # 情况 1:每个帧的掩模合并为一个 PNGinput_mask_path = os.path.join(input_mask_dir, video_name, f"{frame_name}.png")# 如果允许且掩模文件不存在,则跳过if allow_missing and not os.path.exists(input_mask_path):return {}, None# 加载合并的掩模及其调色板input_mask, input_palette = load_ann_png(input_mask_path)# 将其拆分为每个对象的二值掩模per_obj_input_mask = get_per_obj_mask(input_mask)else: # 情况 2:每个对象每个帧有自己的 PNGper_obj_input_mask = {}input_palette = None # 通常不为每个对象单独存储调色板# 遍历对象子目录(命名为 '001'、'002' 等)for object_name in os.listdir(os.path.join(input_mask_dir, video_name)):object_id = int(object_name)input_mask_path = os.path.join(input_mask_dir, video_name, object_name, f"{frame_name}.png")# 如果允许且掩模文件不存在,则跳过if allow_missing and not os.path.exists(input_mask_path):continue# 加载单个对象的掩模(调色板可能被加载但通常被忽略)input_mask, input_palette = load_ann_png(input_mask_path)# 存储二值掩模(像素值 > 0 的为前景)per_obj_input_mask[object_id] = input_mask > 0return per_obj_input_mask, input_palette
load_masks_from_dir(…):这是一个更高级别的函数,使用前面的辅助函数。它从特定的 video_name 目录中读取特定 frame_name 的掩模信息。它根据 per_obj_png_file 标志调整行为:
- 如果 False(默认),它期望每个帧有一个 PNG 文件(如 DAVIS 格式),其中包含通过像素值区分的所有对象掩模。它使用
load_ann_png和get_per_obj_mask。 - 如果 True,它期望视频目录中有每个对象的子目录(例如,
001/、002/),每个子目录中包含单独的 PNG 掩模文件(frame_name.png)。它加载这些单独的文件。它返回一个字典,其中键是对象 ID,值是二值掩模,以及从输入中加载的调色板(如果有的话)。
def save_palette_masks_to_dir(output_mask_dir, video_name, frame_name, per_obj_output_mask, height, width, per_obj_png_file, output_palette):"""将掩模作为带有调色板的 PNG 文件保存到目录"""# 为视频创建输出目录(如果不存在)os.makedirs(os.path.join(output_mask_dir, video_name), exist_ok=True)# 情况 1:保存为一个合并的调色板 PNGif not per_obj_png_file:# 将二值掩模合并为一个掩模,对象 ID 作为像素值output_mask = put_per_obj_mask(per_obj_output_mask, height, width)output_mask_path = os.path.join(output_mask_dir, video_name, f"{frame_name}.png")# 使用指定的调色板保存合并的掩模save_ann_png(output_mask_path, output_mask, output_palette)else: # 情况 2:为每个对象单独保存 PNGfor object_id, object_mask in per_obj_output_mask.items():object_name = f"{object_id:03d}" # 格式化对象 ID(例如,1 -> '001')# 为对象创建子目录(如果需要)os.makedirs(os.path.join(output_mask_dir, video_name, object_name), exist_ok=True)# 调整二值掩模的形状并转换为 uint8output_mask = object_mask.reshape(height, width).astype(np.uint8)output_mask_path = os.path.join(output_mask_dir, video_name, object_name, f"{frame_name}.png")# 保存单个对象的掩模(带有调色板)save_ann_png(output_mask_path, output_mask, output_palette)
save_palette_masks_to_dir(…):保存预测的掩模(per_obj_output_mask,是一个字典,其中包含二值掩模)作为 PNG 文件,带有调色板(无论是从输入加载的还是默认的 DAVIS_PALETTE)。它还处理两种存储格式,基于 per_obj_png_file:要么将掩模合并为一个带有调色板的 PNG(使用 put_per_obj_mask 和 save_ann_png),要么将每个对象的二值掩模保存为其各自的子目录中的单独调色板 PNG。
def save_masks_to_dir(output_mask_dir, video_name, frame_name, per_obj_output_mask, height, width, per_obj_png_file):"""将掩模作为灰度 PNG 文件(不带调色板)保存到目录"""# 为视频创建输出目录(如果不存在)os.makedirs(os.path.join(output_mask_dir, video_name), exist_ok=True)# 情况 1:保存为一个合并的灰度 PNGif not per_obj_png_file:# 将二值掩模合并为一个掩模,对象 ID 作为像素值output_mask = put_per_obj_mask(per_obj_output_mask, height, width)output_mask_path = os.path.join(output_mask_dir, video_name, f"{frame_name}.png")# 确保数据类型和维度正确assert output_mask.dtype == np.uint8assert output_mask.ndim == 2# 转换为 PIL 图像并保存(基于对象 ID 的灰度)output_mask = Image.fromarray(output_mask)output_mask.save(output_mask_path)else: # 情况 2:为每个对象单独保存灰度 PNGfor object_id, object_mask in per_obj_output_mask.items():object_name = f"{object_id:03d}" # 格式化对象 ID# 为对象创建子目录(如果需要)os.makedirs(os.path.join(output_mask_dir, video_name, object_name), exist_ok=True)# 调整二值掩模的形状并转换为 uint8(True 变为 1,False 变为 0)output_mask = object_mask.reshape(height, width).astype(np.uint8)output_mask_path = os.path.join(output_mask_dir, video_name, object_name, f"{frame_name}.png")# 确保数据类型和维度正确assert output_mask.dtype == np.uint8assert output_mask.ndim == 2# 转换为 PIL 图像并保存(灰度,主要是 0 和 1)output_mask = Image.fromarray(output_mask)output_mask.save(output_mask_path)
save_masks_to_dir(…):此函数与 save_palette_masks_to_dir 类似,但它将输出掩模保存为灰度 PNG 文件,不带调色板。在合并格式中,像素值将是对象 ID。在每个对象的格式中,像素值通常为 1(对象)和 0(背景)。这可能用于存储在需要特定调色板格式之前进行可视化或评估的原始预测结果。
这些函数为处理输入掩模提示和以视频目标分割任务中常用的格式保存输出分割结果提供了必要的工具。
4.7 VOS 推理
这一部分定义了 vos_inference 函数,用于处理标准的视频目标分割任务。它假设你希望跟踪的所有目标都出现在初始帧(或几帧)中,你为这些帧提供了掩模。@torch.inference_mode() 和 @torch.autocast(...) 这两个装饰器告诉 PyTorch 进行推理优化(例如,不跟踪梯度),并且如果可能的话,自动使用较低精度的计算(例如 bfloat16),以加快在兼容 GPU 上的运行速度并减少内存使用。
@torch.inference_mode()
@torch.autocast(device_type="cuda", dtype=torch.bfloat16)
def vos_inference(predictor, base_video_dir, input_mask_dir, output_mask_dir, video_name, score_thresh=0.0, use_all_masks=False, per_obj_png_file=False, save_palette_png=False):"""使用给定的预测器对单个视频进行推理"""# 构建视频帧目录的完整路径video_dir = os.path.join(base_video_dir, video_name)# 获取帧文件名列表(不带扩展名)frame_names = [os.path.splitext(p)[0] for p in os.listdir(video_dir) if os.path.splitext(p)[1] in ['.jpg', '.jpeg', '.JPG', '.JPEG']]frame_names = sorted(frame_names)# 初始化预测器的内部状态以处理该视频。这涉及# 加载视频帧(可能异步)并准备模型。inference_state = predictor.init_state(video_path=video_dir, async_loading_frames=False)# 为后续保存掩模存储视频尺寸height = inference_state["video_height"]width = inference_state["video_width"]input_palette = None # 如果从输入掩模加载,则存储调色板
这部分初始化了函数,找到了指定视频的所有帧图像文件,并初始化了 MedSAM2 预测器的状态,包括加载视频帧并获取其尺寸。
接下来,函数确定哪些帧包含初始掩模提示,这些提示将引导分割。默认情况下(use_all_masks=False),它假设只有第一帧(frame_names[0])有输入掩模。如果 use_all_masks=True,它会在 input_mask_dir 中搜索该视频的所有可用掩模文件,并将它们全部用作初始提示。这些提示帧的索引存储在 input_frame_inds 中。
# 从 input_mask_dir 获取掩模输入(要么只有第一帧的掩模,要么所有可用掩模)
if not use_all_masks:# 默认:仅使用第一帧的掩模作为输入提示input_frame_inds = [0]
else:# 选项:使用所有可用的掩模文件作为输入提示if not per_obj_png_file: # 情况 1:每个帧的掩模合并为一个 PNGinput_frame_inds = [idxfor idx, name in enumerate(frame_names)# 检查该帧索引是否有掩模文件if os.path.exists(os.path.join(input_mask_dir, video_name, f"{name}.png"))]else: # 情况 2:每个对象每个帧有自己的 PNGinput_frame_inds = [idxfor idx, name in enumerate(frame_names)# 遍历对象子目录for object_name in os.listdir(os.path.join(input_mask_dir, video_name))# 检查该对象和帧索引是否有掩模文件if os.path.exists(os.path.join(input_mask_dir, video_name, object_name, f"{name}.png"))]# 确保至少找到一个输入掩模
if len(input_frame_inds) == 0:raise RuntimeError(f"In {video_name=}, got no input masks in {input_mask_dir=}. ""Please make sure the input masks are available in the correct format.")# 对每个提示帧的索引进行排序
input_frame_inds = sorted(set(input_frame_inds))
这种逻辑允许灵活地提供初始分割提示——要么只用第一帧,要么在视频中分散使用多个帧。
现在,脚本遍历已识别的 input_frame_inds。对于每个提示帧,它使用前面定义的 load_masks_from_dir 辅助函数来加载掩模。它返回一个字典 per_obj_input_mask,其中键是对象 ID,值是二值掩模。它还检查是否有新的对象 ID 出现在后续提示帧中,而这些 ID 并未出现在第一帧中——这个标准的 vos_inference 函数假设所有目标在初始帧中都已存在,如果不是这样,则会抛出错误(建议用户使用其他推理函数或标志)。对于每个加载的对象掩模,它调用 predictor.add_new_mask,将这个初始提示添加到 MedSAM2 模型的状态中,针对特定的对象 ID 和帧索引。
# 为每个对象收集所有掩模
inputs_per_object = defaultdict(dict)
for idx, name in enumerate(frame_names):# ...(加载 idx 帧的掩模)...for object_id, object_mask in per_obj_input_mask.items():# ...(将掩模存储到 inputs_per_object[object_id][idx])...
# ...(后续代码)...
# 为每个对象单独运行推理
object_ids = sorted(inputs_per_object)
output_scores_per_object = defaultdict(dict) # 按对象存储原始分数
for object_id in object_ids:input_frame_inds = sorted(inputs_per_object[object_id]) # 该对象的帧predictor.reset_state(inference_state) # <<< 为每个对象重置状态for input_frame_idx in input_frame_inds:# 仅添加该对象的掩模predictor.add_new_mask(# ...)# 从该对象首次出现的帧开始传播for out_frame_idx, _, out_mask_logits in predictor.propagate_in_video(inference_state, start_frame_idx=min(input_frame_inds)):# 存储该对象的原始分数obj_scores = out_mask_logits.cpu().numpy()output_scores_per_object[object_id][out_frame_idx] = obj_scores
# --- 后处理:整合分数并应用约束 ---
video_segments = {}
for frame_idx in range(len(frame_names)):# ...(收集该 frame_idx 的所有对象分数)...if not per_obj_png_file:# 使用预测器的内部逻辑解决重叠问题scores = predictor._apply_non_overlapping_constraints(scores) # <<< 约束步骤# 对最终的分数(可能经过约束)应用阈值per_obj_output_mask = {object_id: (scores[i] > score_thresh).cpu().numpy()for i, object_id in enumerate(object_ids)}video_segments[frame_idx] = per_obj_output_mask
vos_inference 函数的主要改进是其能够处理视频中目标出现在不同时间的情况,而不仅仅是第一帧。与标准的 vos_inference 不同,它首先扫描整个视频时长,收集每个目标在所有帧中的所有初始掩模提示。然后,它独立地处理每个目标:对于每个目标,它重置模型的内存,仅添加该目标的初始掩模,并从该目标首次出现的帧开始进行跟踪传播。
每个目标的原始预测分数分别存储。最后,在单独跟踪每个目标之后,它逐帧整合这些分数,使用 _apply_non_overlapping_constraints 解决不同目标预测之间的潜在重叠,然后生成最终的分割掩模。这种针对每个目标的独立方法,结合了目标首次出现时的针对性开始时间和后续整合,确保即使目标在场景中半途出现,也能实现准确的跟踪。其余的工作流程与标准的 vos_inference 相同。
4.8 主执行块
脚本的最后部分定义了 main 函数,该函数协调整个过程并解析用户在运行脚本时通过命令行提供的参数。
4.8.1 参数解析(主函数)
main() 函数首先设置了一个 ArgumentParser。这是脚本通过命令行理解用户指令的方式。它定义了各种参数,用于控制脚本的行为。定义这些参数后,parser.parse_args() 读取用户在命令行上提供的值(如果没有提供,则使用默认值),并将它们存储在 args 对象中。
def main():parser = argparse.ArgumentParser()# --- 定义所有命令行参数 ---parser.add_argument("--sam2_cfg",type=str,default="configs/sam2.1_hiera_t512.yaml",help="MedSAM2 模型配置文件",)# 更多参数...parser.add_argument("--use_vos_optimized_video_predictor",action="store_true",help="是否使用经过优化的 VOS 视频预测器,其中所有模块均已编译",)# --- 解析参数 ---args = parser.parse_args()# --- (后续代码) ---
这为基于用户输入的主函数的其余部分设置了配置。我们跳过这些参数的解释,直接进入主执行部分。
4.8.2 模型初始化和视频列表准备
在 main() 中,解析参数后,脚本初始化 MedSAM2 视频预测器。它使用 build_sam2_video_predictor,传入模型配置路径(args.sam2_cfg)、检查点路径(args.sam2_checkpoint)以及其他相关标志(apply_postprocessing、use_vos_optimized_video_predictor)。它还根据 per_obj_png_file 参数构建 hydra_overrides_extra,以配置模型内部对可能重叠掩模的处理。
接下来,它确定要处理的视频列表(video_names)。如果提供了 args.video_list_file,它从该文本文件中读取视频名称。否则,它扫描 args.base_video_dir 并列出所有子目录,假设每个子目录对应一个视频。然后,它打印消息,表明是使用第一帧的掩模还是所有掩模作为输入,并列出即将处理的视频。
# --- (从前面继续) ---
# 根据参数配置模型覆盖
hydra_overrides_extra = ["++model.non_overlap_masks=" + ("false" if args.per_obj_png_file else "true")
]
# 初始化 MedSAM2 视频预测器模型
predictor = build_sam2_video_predictor(config_file=args.sam2_cfg,ckpt_path=args.sam2_checkpoint,apply_postprocessing=args.apply_postprocessing,hydra_overrides_extra=hydra_overrides_extra,vos_optimized=args.use_vos_optimized_video_predictor,
)# 打印关于输入掩模使用的状态消息
if args.use_all_masks:print("使用 input_mask_dir 中的所有可用掩模作为 MedSAM2 模型的输入")
else:print("仅使用 input_mask_dir 中第一帧的掩模作为 MedSAM2 模型的输入")# 确定要处理的视频名称列表
if args.video_list_file is not None:# 从指定文件中读取视频名称with open(args.video_list_file, "r") as f:video_names = [v.strip() for v in f.readlines()]
else:# 通过列出基础视频目录的子目录来获取视频名称video_names = [pfor p in os.listdir(args.base_video_dir)if os.path.isdir(os.path.join(args.base_video_dir, p))]
print(f"正在处理 {len(video_names)} 个视频:\n{video_names}")
# --- (后续代码) ---
这部分加载了实际的模型,并确定了需要处理哪些视频。
4.9 对视频进行推理
这是 main 函数中的主处理循环。它遍历准备好的 video_names 列表中的每个 video_name。对于每个视频,它打印一条状态消息。然后,它检查 args.track_object_appearing_later_in_video 标志。
- 如果标志为 False(默认),它调用
vos_inference函数(在第三部分.1 中解释),传入预测器和所有相关参数(目录、视频名称、标志)。 - 如果标志为 True,它调用
vos_separate_inference_per_object函数(在第三部分.2 中解释),同样传入必要的参数。
在循环完成对所有视频的处理后,它打印一条最终确认消息,表明输出掩模已保存到何处。
# --- (从前面继续) ---
# 遍历每个视频名称
for n_video, video_name in enumerate(video_names):print(f"\n{n_video + 1}/{len(video_names)} - 正在处理 {video_name}")# 根据标志选择合适的推理函数if not args.track_object_appearing_later_in_video:# 标准 VOS:假设所有目标都出现在第一帧提示中vos_inference(predictor=predictor,base_video_dir=args.base_video_dir,input_mask_dir=args.input_mask_dir,output_mask_dir=args.output_mask_dir,video_name=video_name,score_thresh=args.score_thresh,use_all_masks=args.use_all_masks,per_obj_png_file=args.per_obj_png_file,save_palette_png=args.save_palette_png,)else:# VOS 变体:通过分别处理每个目标来处理后续出现的目标vos_separate_inference_per_object(predictor=predictor,base_video_dir=args.base_video_dir,input_mask_dir=args.input_mask_dir,output_mask_dir=args.output_mask_dir,video_name=video_name,score_thresh=args.score_thresh,use_all_masks=args.use_all_masks,per_obj_png_file=args.per_obj_png_file,# 注意:vos_separate_inference_per_object 隐式地保存调色板 PNG)# 最终确认消息
print(f"已完成对 {len(video_names)} 个视频的推理 -- "f"输出掩模已保存到 {args.output_mask_dir}"
)if __name__ == "__main__":main()
为了进行可视化,我们将这些掩模与输入图像叠加,并从不同时间戳中选取了三帧。结果如下:
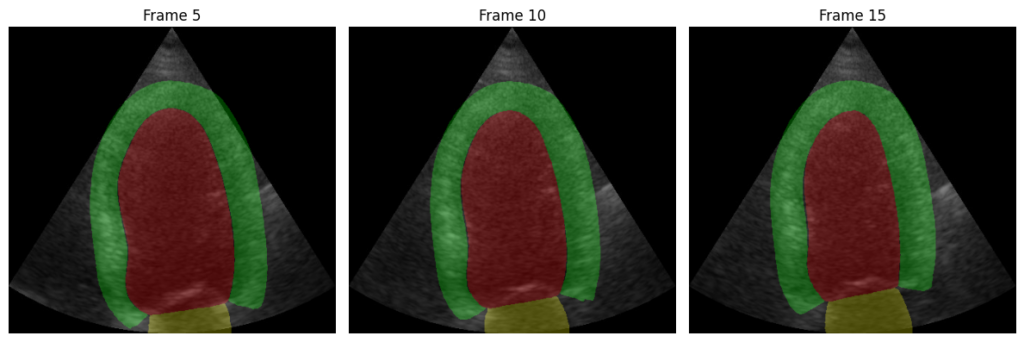
如你所见,该模型能够正确分割心脏各部分:
- 红色区域:很可能是左心室腔,在心脏舒张期血液充盈其中,在收缩期被泵出。
- 绿色区域:似乎是心肌——即左心室的肌肉壁。
- 黄色区域:可能是左心室流出道(LVOT)或二尖瓣装置的一部分,具体取决于特定的解剖视角。
总结
- 医学成像面临的挑战:医生常常需要手动在数千张扫描切片上绘制边界,这是一个既耗时又费力的过程。
- 分割技术为何重要:它是医院应用人工智能的切入点,有助于手术准备、急诊诊断,还能为肿瘤模型和 3D 打印等下游工具提供支持。
- MedSAM2 是什么:一种强大的“一键分割任何物体”模型,适用于 3D 医学图像和实时视频。只需一个框选或一次点击,它就能在多种模态下工作。
- 架构升级:结合了 SAM2 的速度优势,并增加了短期记忆模块,以实现 3D 感知和视频中的时间一致性。
- 在大规模多模态医学数据上进行训练:在超过 45 万个 3D 扫描数据和 7.6 万多个超声/内窥镜视频帧上进行训练,并通过人工参与优化来提高准确性。
- 代码工作流程和性能:从 CT 扫描到超声视频,MedSAM2 使用一致且可重复的 PyTorch 流程,实现快速、高精度的分割。
- 实际影响:可减少高达 90% 的手动分割时间,实现实时超声跟踪,并且在不同器官和模态之间具有通用性。
MedSAM2 代表了医学成像人工智能领域的重大飞跃,通过单一提示、单一模型和实时性能简化了 3D 和视频分割。它基于计算机视觉多年的发展成果,并直接应用于医疗领域最紧迫的挑战中。更快的诊断速度、更少的手动工作,以及更广泛地使用精密工具,这些不再是未来的目标——它们已经成为现实。
原文地址:https://learnopencv.com/medsam2-explained/