OR算法+ML模型混合推理框架架构演进
1 背景
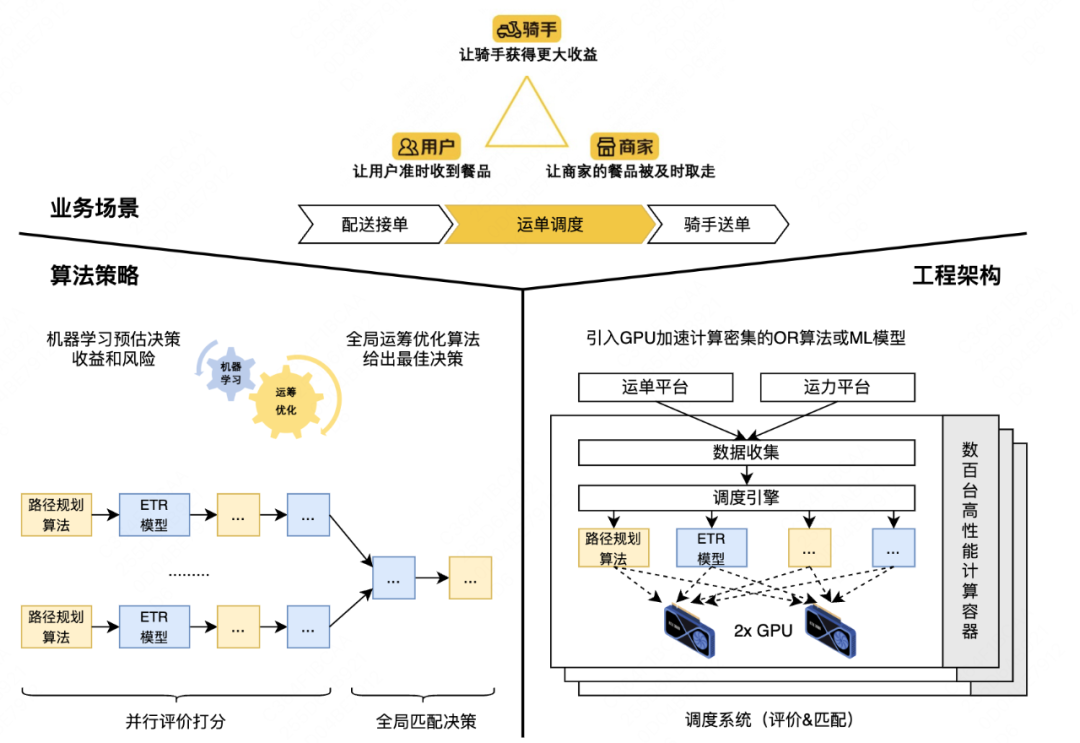
调度系统主要职责是需要在合适的时间以合适的方式将合适的运单分给合适的骑手,承载着海量的调度规模。为追求更高用户体验,需要在强时间约束下完成每一轮次的调度任务,对性能极度敏感;其中计算密集的运筹学算法(Operations Research,OR)和机器学习模型(Machine Learning,ML)是主要性能热点,如OR部分计算量最大的「路径规划算法」和ML部分计算量最大的「送达时间预估深度学习模型(ETR)」计算量占比60%以上,若使用远程CPU承载此计算,集群规模将在万台以上,长尾问题明显,运维压力和资源成本难以控制。
因此,在调度系统工程架构中引入GPU硬件并通过手写CUDA算子的方式来加速这些性能热点,在模块级取得了较好的加速效果[1],与此同时在系统级出现面向GPU新硬件如何高性能、高稳定性、高扩展性地实现OR+ML混合推理的新问题。围绕这些问题,调度系统组通过近两年的创新实践,逐步沉淀出一套与调度系统算法特性匹配的推理框架。本文将介绍该推理框架的演进历程,以及后续迭代计划。
2 面临的问题
为获取更高系统性能,当前工程架构的设计理念是“数据本地化”和“计算本地化”,让计算贴近存储,因此计算密集模块将优先使用本地GPU,实际应用过程会面临以下问题。
| 2.1 性能问题
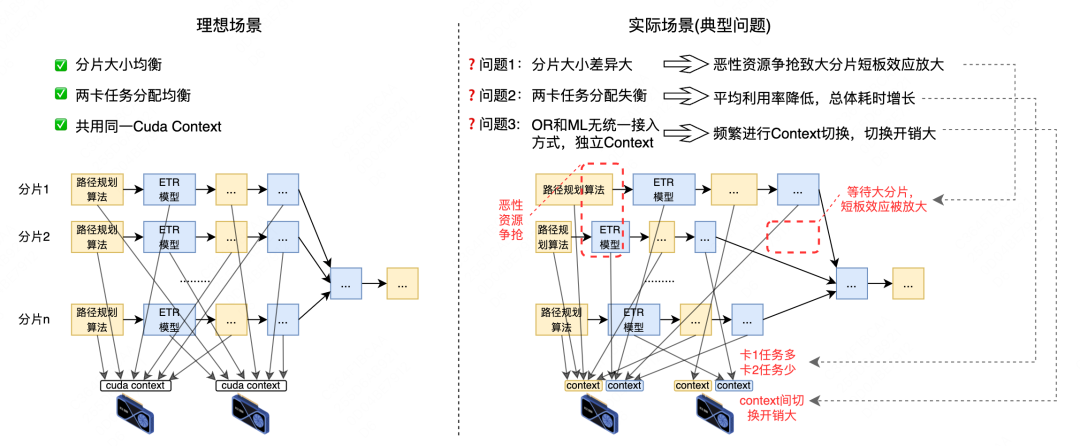
由于缺乏计算任务统一接入和全局统筹的能力,导致系统在实际应用场景会遇到分片大小差异大、卡间任务分配失衡、独立Context频繁切换等情形带来调度耗时明显增长的性能问题。
| 2.2 稳定性问题
在GPU上运行的异构计算任务可能会因为地址越界、ECC Error等软硬件问题出现CUDA Exception,CUDA Exception需要进程重启后才能恢复,否则GPU后续计算任务均会失败。但调度服务进程重启耗时需要10~15分钟,虽然偶发单点重启可通过节点冗余保障线上服务,但当可用节点数量不足时,可能造成业务影响。因此如何缩小CUDA Exception影响半径、缩短故障恢复时间,从而避免出现业务影响是必须要解决的稳定性保障问题。
| 2.3 扩展性问题
为提升GPU利用率,多个算法或者模型时分复用同一GPU,其中每个算法或模型均需要预分配显存(3GB~5GB/模型,单卡总显存24GB),虽然通过模型优化、参数共享等手段极致优化了显存用量,但随着算法复杂度和单量规模逐年增长,本机GPU显存容量将会率先成为系统瓶颈。因此,如何在最小化数据传输延迟的约束下,灵活扩展GPU算力是不得不前置考虑的扩展性问题。
3 解决思路和方案
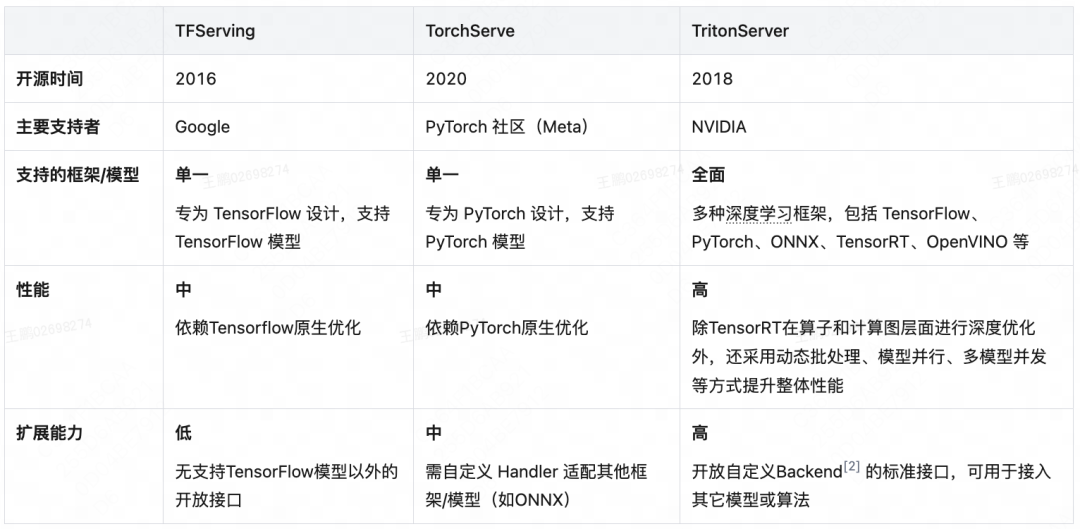
深度学习领域依托推理框架可调度计算任务实现系统性能提升、可屏蔽硬件细节实现推理与应用解耦,我们也借鉴了这一成熟解决思路。本着复用原则我们分别调研了TFServing、TorchServe、TritonServer等行业主流推理框架,其中TritonServer是英伟达近七年持续迭代并全开源的推理框架,相比TFServing、TorchServe具有支持模型范围更广泛、内嵌功能更全面、代码结构更适合二次开发等优点,并且可获得NVIDIA官方和美团内部基研团队的技术支持,最终决定引入TritonServer推理框架并进行二次开发来解决上述性能、稳定性和扩展性问题。
TritonServer推理框架主要包含Server、TritonCore、若干预开发的Backend、状态监控等功能单元,通过分析和实验发现TritonCore和TensorRT Backend复用价值高,且TritonCore提供的C-API接口易于集成,因此我们确定了以下基础方案:基于TritonCore,通过TensorRT Backend接入深度学习模型(如ETR),开发OR Backend用于接入手写版CUDA代码(如路径规划算法)。
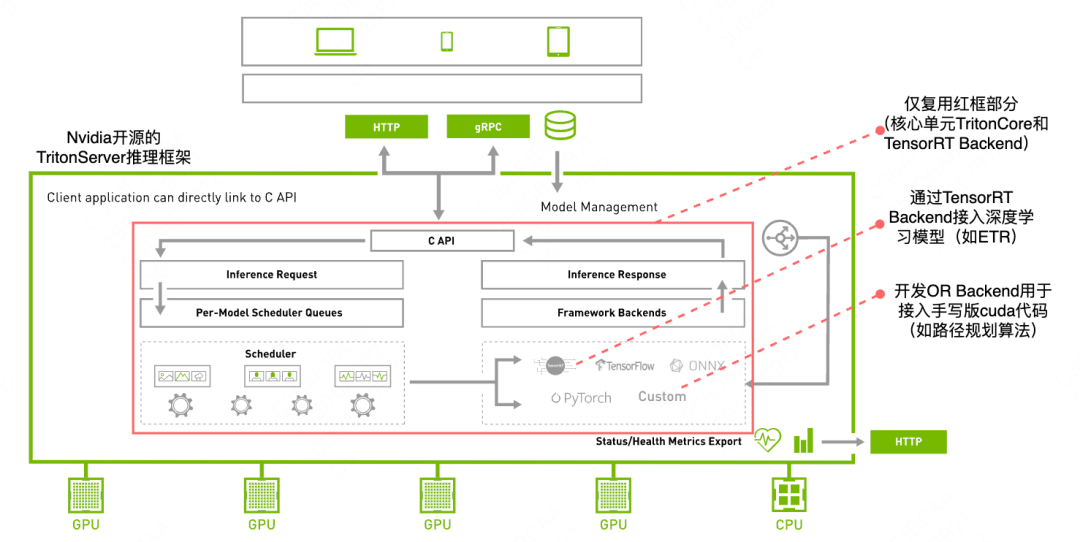
相比常规推理应用,基于TritonCore实现OR+ML的推理能力需要在自定义Backend开发、混合推理任务全局统筹、跨语言复杂系统设计等方面进行突破。
因此,我们将混合推理框架的建设过程拆解成三期进行,在架构上由易到难逐步迭代。
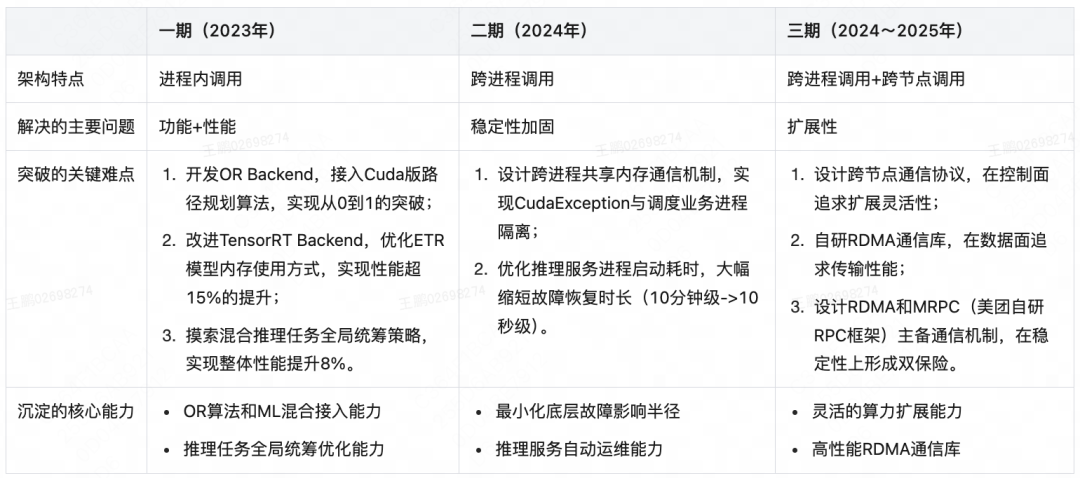
4 架构演进
| 4.1 进程内调用
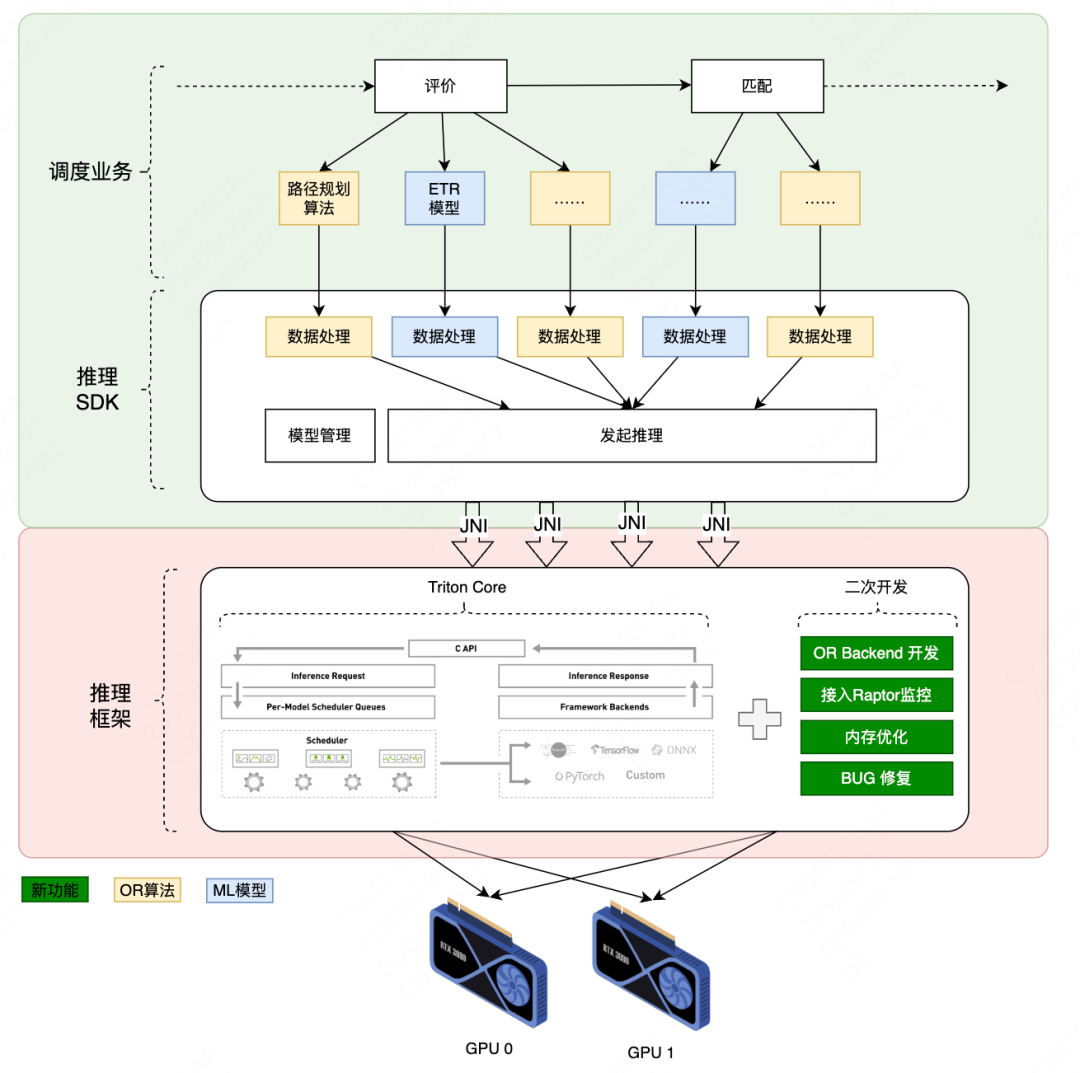
通过Java Native Interface(JNI)将TritonCore接入Java语言开发的调度业务进程,填平了跨语言鸿沟并在此基础上进行二次开发,在功能和性能上实现突破。其核心内容如下:
1)功能突破
-
开发OR Backend,接入CUDA版路径规划算法,实现从0到1的突破;
-
将 TritonCore内监控模块与美团监控平台(Raptor)打通,实现推理成功率、推理延迟等12项指标可视化;
-
利用Valgrind等工具定位到TritonCore存在内存泄漏等问题,并联合英伟达专家修复了这些Bug。
2)性能突破
-
改进TensorRT Backend,优化ETR模型内存使用方式,实现模型推理性能超15%的提升;
-
摸索混合推理任务全局统筹策略,实现整体性能提升8%。
| 4.2 跨进程调用
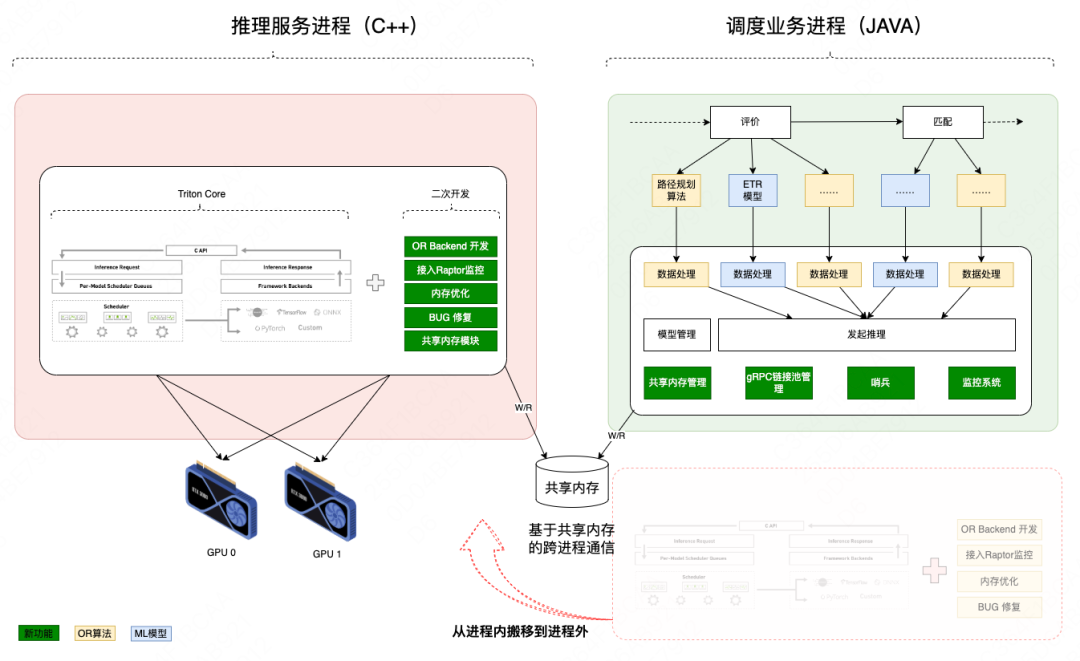
在功能和性能充分验证基础上,将TritonCore调用方式从进程内改造成跨进程,实现故障隔离,将异常恢复耗时从10+分钟压缩至10秒级。本次改造围绕三方面展开。
1)通信框架升级
采用gRPC+SHM(共享内存)替代原有JNI,SHM负责重量级的数据面传输,gRPC负责轻量级的控制面通信,在保持推理性能优势同时将调用方式升级成跨进程,当出现CUDA Exception时只需重启推理服务进程即可恢复,最小化底层故障的影响半径。
2)共享内存传输体系
-
相比纯RPC的传输方式,共享内存技术可减少2次数据拷贝和4次序列化与反序列化的开销,最小化跨进程数据传输开销;
-
结合推理请求分片错峰特点,将共享内存池化,最大化复用共享内存空间,在不大幅增加内存开销的情况下即可支撑6000+ QPS高并发场景。
3)自动化运维
设计哨兵模块实现秒级发现底层异常并自动重启推理进程,相比进程内调用方式需要重启调度业务进程才能恢复的方式大幅缩短故障恢复时长(10分钟级->10秒级)。
-
调度业务进程为有状态服务,重启过程依赖本地缓存数据的拉取过程,通常耗时在10+分钟;
-
推理服务进程为无状态服务,重启过程常规耗时约27秒,进一步优化启动过程后耗时后仅需10~12秒。
| 4.3 跨节点调用
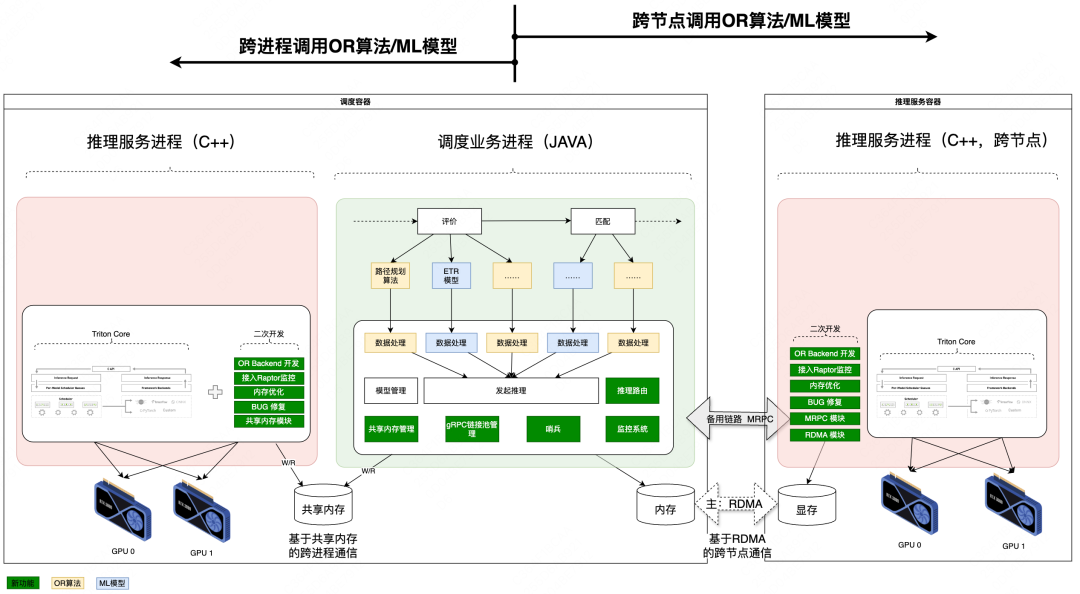
为满足算法复杂度和单量规模逐年增长的需求,在本地跨进程调用基础上增加跨节点调用能力,实现突破单机算力瓶颈的低时延算力扩展;核心模块包含。
1)高性能流量路由
在流量路由模块的设计上,借鉴Meta公司推理服务路由策略,实现与“本地跨进程+远程跨多节点”架构适配的流量路由策略。
-
基于自适应均衡算法动态分配本地/远程流量,应用Power-of-Two-Choices算法避免远程节点间负载失衡,优化后同等资源的吞吐提升18%,TP99延迟缩短了25%;
-
通过哨兵监控系统实时追踪本地推理进程的健康状态,当检测到本地推理进程故障时,系统自动将本地的推理请求切换到远程集群上,保障服务的可用性。
2)低延迟主备数据传输:RDMA降低传输延迟,MRPC兜底机制保障可用性
我们和基研高性能网络组联合预研验证了RDMA技术在调度系统算力扩展场景具有大幅提升性能的可行性,正在落地开发,预计2025年Q3上线应用,届时将在MRPC备用链路基础上实现RDMA高性能数据传输。
-
应用GPUDirect RDMA技术,实现主机内存←→远端GPU显存直接透传,端到端传输时延可优化60%;
-
采用MRPC作为RDMA的备用链路,当RDMA链路发生故障时,可自动降级至MRPC链路,保障服务的可用性。
4 未来展望
经过上述三期的架构迭代,我们逐步在功能、性能、稳定性和扩展性方面获得收益,建成了面向调度场景的高性能、可伸缩的OR+ML混合推理框架。随着GPU卡外部供给环境的变化,集群将出现不同型号GPU卡并存的场景,不同型号GPU卡在显存大小、计算能力等规格上存在差异,我们将针对这些差异在框架层面进一步做功,自适应硬件差异实现差异化部署,最大化全局性能。此外,我们还将在多级缓存、分布式推理等方向进行扩展,为算法策略在加大搜索深度、扩大解空间、基于大模型解决组合优化问题等探索方向提供算力支撑。