Kubernetes HPA 深度解析:生产环境自动扩缩容实战指南
一、HPA 核心原理剖析
1. 运作机制三步曲
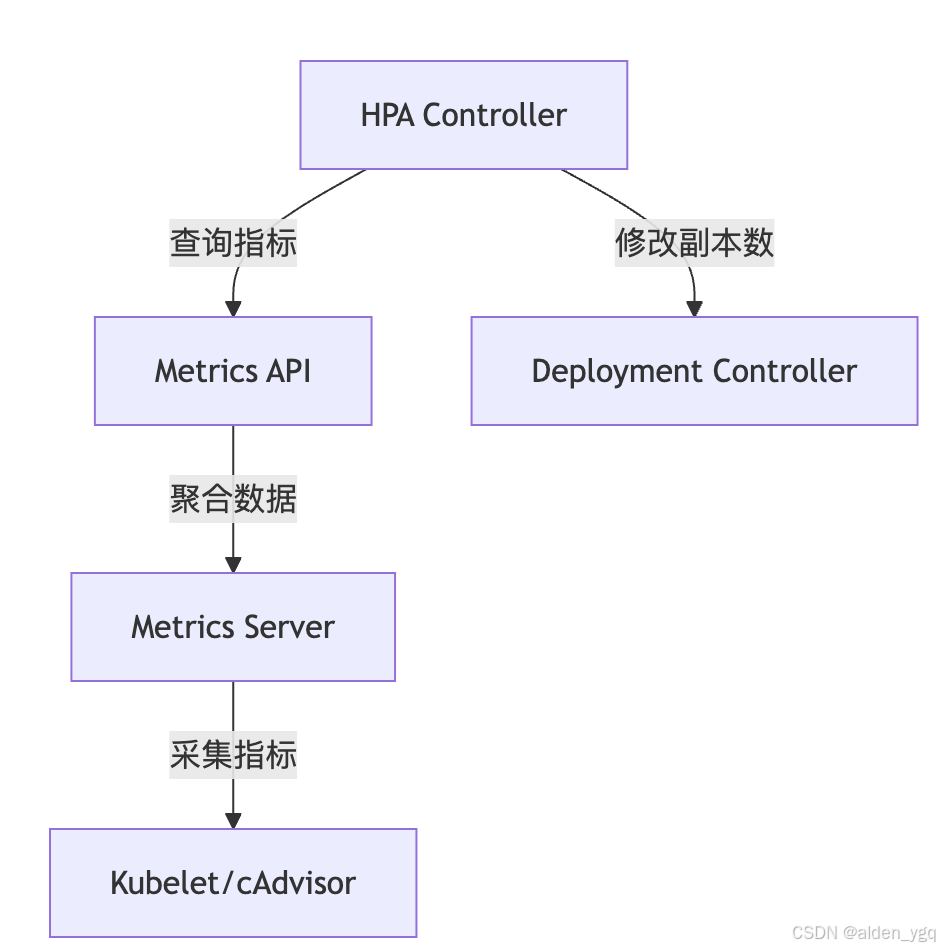
(图示:指标采集 → 决策计算 → 执行扩缩容的完整闭环)
- 指标采集层:通过 Metrics Server/Prometheus 等组件实时收集 CPU、内存或自定义指标
- 决策计算层:根据当前指标值与目标阈值的比例计算所需副本数
期望副本数 = ceil(当前副本数 × (当前指标值 / 目标指标值)) - 执行控制层:通过 Deployment/StatefulSet 控制器调整 Pod 数量
2. 核心参数详解
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: payment-service-hpa
spec:behavior: # 扩缩容行为控制(v2+特性)scaleDown:stabilizationWindowSeconds: 300 # 缩容冷却窗口policies:- type: Percentvalue: 10 # 单次最大缩容10%scaleUp:stabilizationWindowSeconds: 60 policies:- type: Podsvalue: 4 # 单次最大扩容4个PodminReplicas: 2maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 60- type: Pods # 自定义QPS指标pods:metric:name: http_requests_per_secondtarget:type: AverageValue averageValue: 100
二、生产环境高阶配置技巧
1. 多指标扩缩策略组合
| 指标类型 | 适用场景 | 配置要点 |
|---|---|---|
| CPU/Memory | 基础资源型服务 | 设置合理的缓冲阈值(建议50-70%) |
| QPS | Web API服务 | 结合RPS和错误率设置动态阈值 |
| 队列积压量 | 消息处理服务 | 需与消费者延迟指标联动 |
| 自定义业务指标 | 复杂业务场景(如订单量) | 确保指标采集频率>30秒 |
2. 性能调优黄金参数
behavior:scaleDown:stabilizationWindowSeconds: 300 # 防止抖动缩容policies:- type: Percentvalue: 20 # 单次最大缩容比例scaleUp:stabilizationWindowSeconds: 60 policies:- type: Podsvalue: 2 # 平稳扩容节奏
3. 与Cluster Autoscaler联动
# Node自动扩容条件示例(需配合Cluster Autoscaler)
kubectl annotate node <node-name> \cluster-autoscaler.kubernetes.io/scale-down-disabled=true
三、自定义指标实战方案
1. Prometheus监控适配器配置
# prometheus-adapter-configmap.yaml
rules:
- seriesQuery: 'http_requests_total{namespace!="",pod!=""}'resources:overrides:namespace: {resource: "namespace"}pod: {resource: "pod"}name:matches: "^(.*)_total"as: "${1}_per_second"metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m]) by (<<.GroupBy>>)'
2. 业务指标HPA配置示例
metrics:
- type: Podspods:metric:name: orders_processed_per_minutetarget:type: AverageValueaverageValue: 500
四、生产环境避坑指南
1. 常见故障场景处理
| 现象 | 根因分析 | 解决方案 |
|---|---|---|
| HPA不触发扩容 | 指标采集延迟超过30秒 | 检查Metrics Server/Prometheus可用性 |
| Pod数量频繁抖动 | 阈值设置过于敏感 | 调整扩缩容冷却时间 |
| Node资源不足导致扩容失败 | Cluster Autoscaler未正确配置 | 检查节点资源池和自动扩缩容策略 |
2. 监控体系搭建
# 关键监控指标清单
kube_hpa_status_current_replicas{namespace="production"}
kube_hpa_spec_max_replicas{namespace="production"}
container_cpu_usage_seconds_total{container!="POD"}
3. 混沌工程测试方案
# 使用k6进行压力测试
k6 run --vus 100 --duration 5m script.js
# 同时观察HPA响应情况
watch -n 1 "kubectl get hpa payment-service-hpa"
五、最佳实践总结
参数设置黄金准则
- CPU目标利用率设置在60-70%区间
- 最小副本数≥2保证高可用
- 扩容速度>缩容速度(比例3:1)
版本升级注意事项
# 检查API版本兼容性
kubectl get hpa.v2.autoscaling -o yaml
# 逐步迁移策略
配套工具链推荐
- 指标采集:Prometheus + VictoriaMetrics
- 可视化:Grafana HPA Dashboard
- 压力测试:k6 + Locust
通过合理配置HPA并结合集群其他自动化组件,可使系统具备智能弹性能力。建议每月执行一次扩缩容演练,持续优化阈值参数,让您的Kubernetes集群真正具备生产级自愈能力。