卷积神经网络基础(五)
6.3 Softmax-with-Loss 层
我们最后介绍输出层的softmax函数,之前我们知道softmax函数会将输入值正规化之后再输出。在手写数字识别的例子中,softmax层的输出如下:
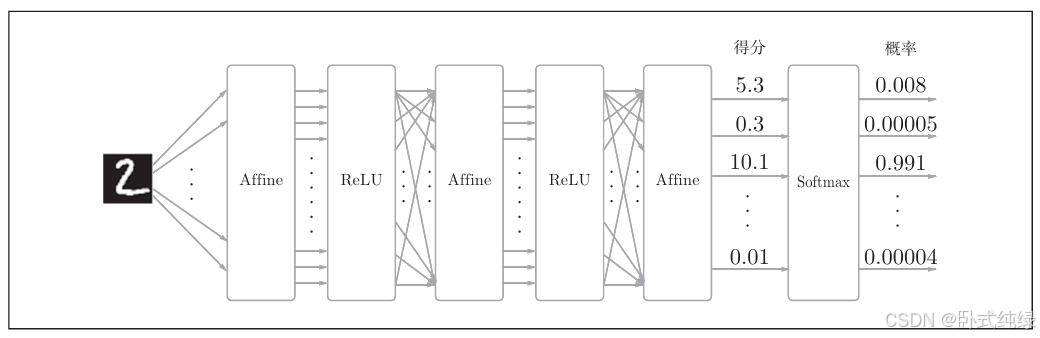
softmax函数会将输入值正规化,即输出值的和为1之后再进行输出。手写数字的分类有10个,所以softmax层输入也有十个,输出也是10个,代表各类别的概率。
神经网络中进行的处理有推理(inference)和学习两个阶段。神经网络的推理通常不使用Softmax层。比如,用上面的网络进行推理时, 会将最后一个Affine层的输出作为识别结果。神经网络中未被正规化的输出结果(上图中Softmax层前面的Affine层的输出)有时被称为“得分”。也就是说,当神经网络的推理只需要给出一个答案的情况下,因为此时只对得分最大值感兴趣,所以不需要Softmax层。 不过,神经网络的学习阶段则需要Softmax层。
我们接下来来实现softmax层,由于这里也包含作为损失函数的交叉熵误差(cross entropy error),所以也被称为soft-max-Loss层,其计算图如下:
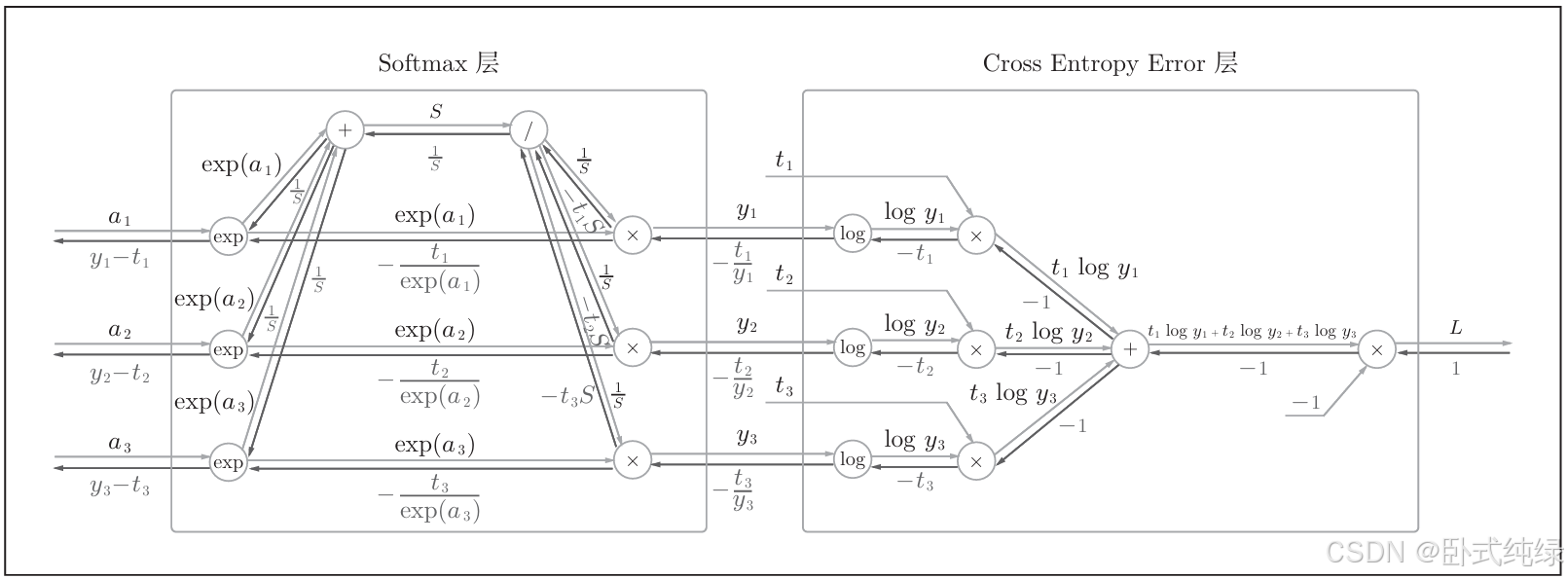
由于这个计算图较为复杂,我们只给出结果,不进行推理计算,下面是简化后的计算图:
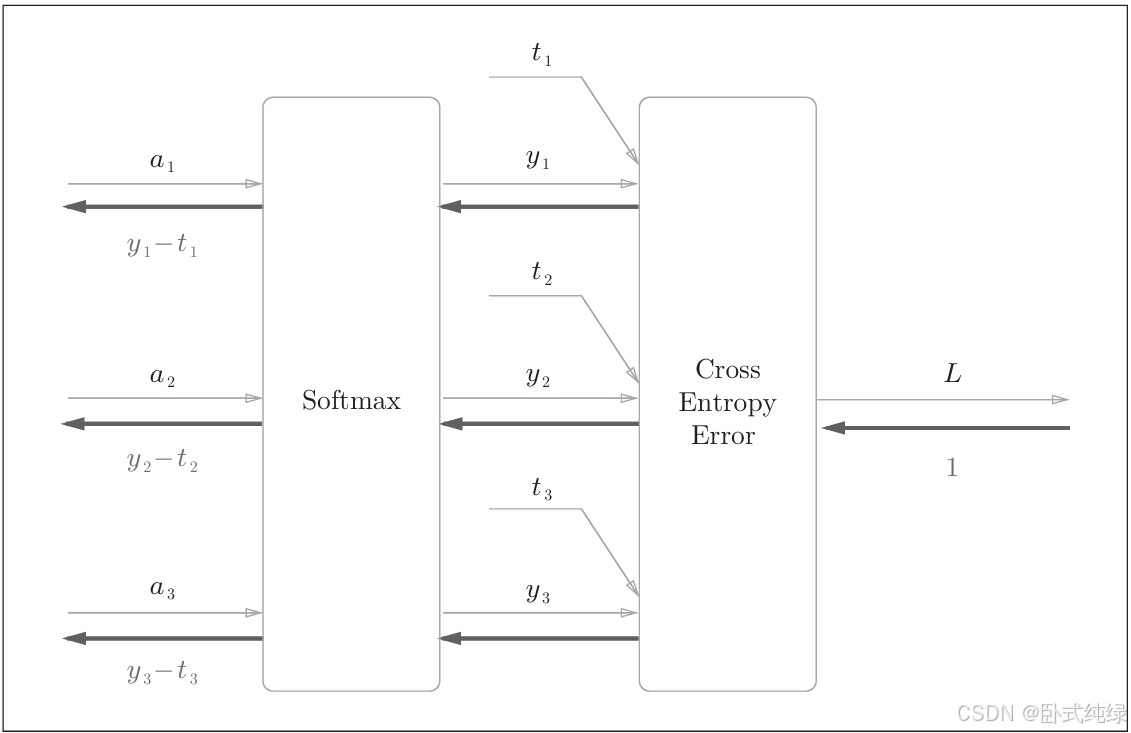
我们假设这里进行三类的分类,接受前面层的三个输入a1 a2和a3,softmax层对输入值进行正规化后输出y1 y2和y3,传递给交叉熵误差层,结合教师标签t,输出损失L。
特别注意在这个计算图中的反向传播中,输入数据的导数为y-t,y是softmax层输出,t是监督数据,所以y-t是输出和教师标签的差分。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
神经网络进行学习的目的就是通过调整权重参数,使神经网络输出softmax层输出y和教师标签t尽可能接近,即输入a的导数值接近0。因此我们需要将y-t这样的误差高效地传递给前面的层。
这里考虑一个实例,教师标签是(0,1,0),softmax层输出为(0.3,0.2,0.5)的情况,softmax层的反向传播的误差是(0.3,-0.8,0.5)这样的,因为这个大的误差会向前面的层传播,所以softmax前面的层会从这个大的误差中学习到“大”的内容。
PS:使用交叉熵误差作为softmax函数的损失函数后,反向传播得到 (y1 − t1,y2 − t2,y3 − t3)这样 “漂亮”的结果。实际上,这样“漂亮” 的结果并不是偶然的,而是为了得到这样的结果,特意设计了交叉 熵误差函数。回归问题中输出层使用“恒等函数”,损失函数使用 “平方和误差”,也是出于同样的理由(3.5节)。也就是说,使用“平 方和误差”作为“恒等函数”的损失函数,反向传播才能得到(y1− t1, y2 − t2, y3 − t3)这样“漂亮”的结果。
再举一个例子,比如思考教师标签是(0,1,0),Softmax层的输出是(0.01, 0.99, 0)的情形(这个神经网络识别得相当准确)。此时Softmax层的反向传播 传递的是(0.01,−0.01,0)这样一个小的误差。这个小的误差也会向前面的层 传播,因为误差很小,所以Softmax层前面的层学到的内容也很“小”。
接下来进行softmax-with-Loss层的实现:
Class SoftmaxwithLoss:def __init__(self):self.loss = None #损失self.y = None #softmax输出self.t = None #监督数据def forward(self,x,t):self.t = tself.y = yself.loss = cross_entropy_error(self.y,self.t)return self.lossdef backward(self,dout=1)batch_size = self.t.Shape[0]dx = (self.y - self.t) / batch_sizereturn dx这里直接使用了之前已经实现过的softmax和cross_entropy_error函数。所以实现起来十分简单,在反向传播中,要将传播的值除以批大小后再传递给前面的层才是单个数据的误差。