[Survey]Remote Sensing Temporal Vision-Language Models: A Comprehensive Survey
BaseInfo
| Title | Remote Sensing Temporal Vision-Language Models: A Comprehensive Survey |
| Adress | https://arxiv.org/abs/2412.02573 |
| Journal/Time | 2024 arxiv |
| Author | 北航 上海AI Lab |
| Code | https://github.com/Chen-Yang-Liu/Awesome-RS-Temporal-VLM |
1. Introduction
- 传统遥感局限:传统遥感时间图像分析聚焦变化检测,确定不同时间图像变化区域,但局限于视觉层面,常缺上下文或描述性信息,难以捕获动态变化。
- 新机遇引入:视觉 - 语言模型(VLM)兴起,为遥感时间图像分析带来新维度,能创建变化的语言描述,实现跨模态理解。
- RS - TVLMs 用于时间图像理解,处理变化描述、视觉问答等任务。现有 RS - TVLMs 研究虽热度渐涨,但仍稀缺,且多关注特定任务孤立方法,缺乏对领域整体进展和未来方向系统性综述。
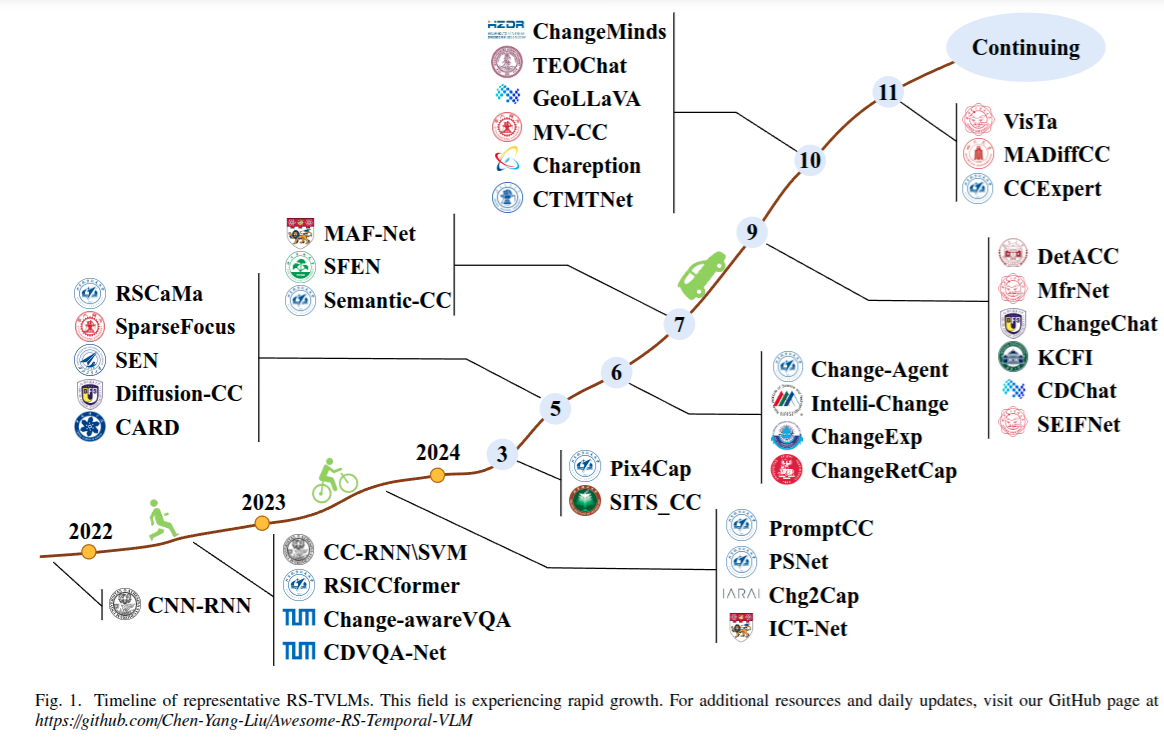
2. From Change Detection to Temporal Vision-Language Understanding
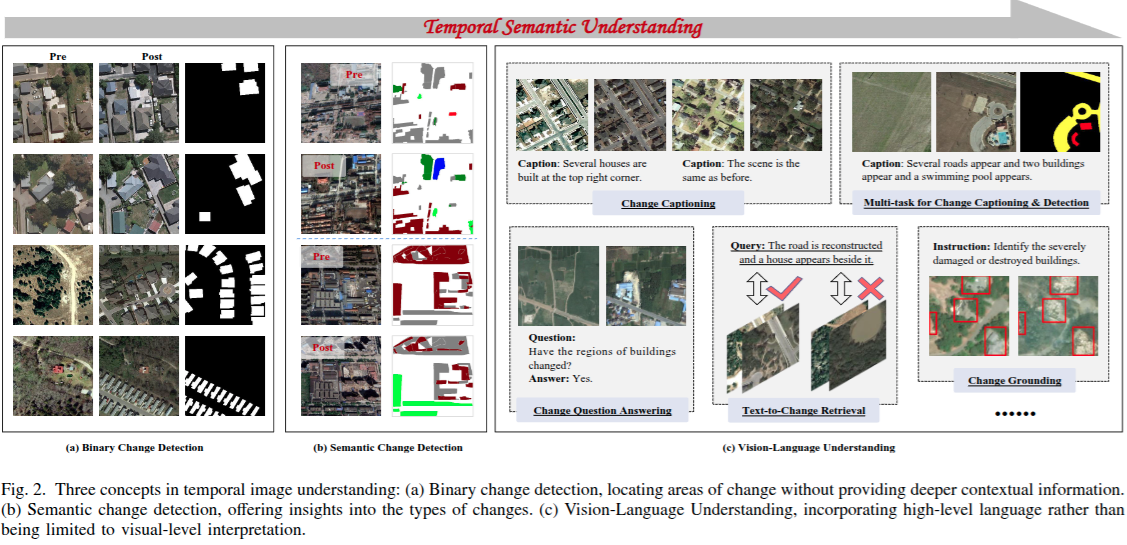
遥感变化检测:变化检测(CD)是多时相遥感图像分析基础任务,旨在对比不同时间遥感图像,识别像素级变化区域掩码。按掩码类型分二元变化检测和语义变化检测。
Temporal Vision-Language Models (RS-TVLMs)
从二元变化检测到语义变化检测,再到视觉 - 语言理解的进展,代表了从传统视觉分析向结合视觉和文本信息的更全面多模态语义理解的转变。
变化描述 、变化视觉问答 、变化定位 以及文本到变化检索 。
基础语言模型
长短期记忆网络(LSTM):长短期记忆网络(LSTM) 是循环神经网络(RNN)的一种特殊类型,旨在解决传统 RNN 在处理长序列数据时学习长期依赖关系的挑战。
Transformer 并行处理整个输入序列,赋予其全局感受野。这种并行化提高了效率和可扩展性。
Mamba:最近,由于其全局感受野和线性计算复杂度,状态空间模型(SSMs) 已成为有前景的模型。
大语言模型
基于 Transformer 架构并通过扩大数据和计算规模 ,LLMs 在预训练期间学习大量知识,以开发强大的语言理解和生成能力。这些模型在各种任务中表现出色,包括微调的下游任务 ,甚至在少样本或零样本学习场景中 。
- Encoder-only models (e.g., BERT [130]),
- EncoderDecoder models (e.g., T5 [106]),
- Decoder-only models(e.g., GPT series, LLaMA [131], Gemini [132]).
LLM 的训练过程主要包括几个阶段。
- 第一阶段是预训练,在此期间,大规模模型从大规模无标签数据中学习通用语言表示,通过自监督学习。常见的预训练任务包括掩码语言建模(MLM)和自回归掩码建模(ALM) ,这两者都有助于模型学习文本中的语言上下文关系。
- 预训练后,模型进入监督指令微调阶段,在此阶段,它在标记数据上进行进一步训练,以提高其在特定任务上的性能 。在某些情况下,会引入额外奖励建模。在这里,外部反馈信号(如人类评级或用户行为数据)用于评估模型输出的质量。强化学习方法确保奖励信号与人类期望一致,以进一步优化模型,使输出更符合人类预期 。
Remote Sensing Temporal Vision-Language Models
遥感时间图像中视觉 - 语言理解的研究主要集中在几个关键方面:变化描述、变化视觉问答和变化定位。这些任务旨在通过利用多模态模型和语言理解来增强遥感时间图像的解释。
遥感变化描述:Remote Sensing Change Captioning
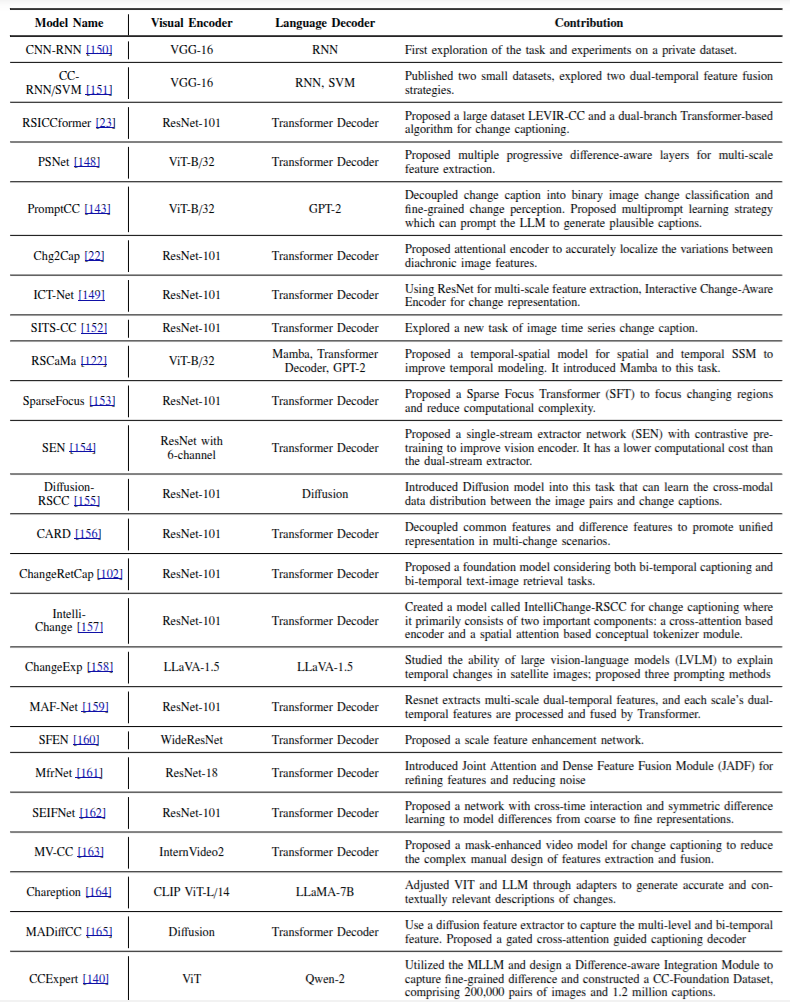
旨在生成自然语言描述,精准刻画不同时刻遥感图像空间特征变化,助力用户理解关键变化,为遥感数据决策分析提供语义支持。多基于深度学习,采用视觉编码、时频融合、语言解码三阶段架构.视觉编码从双时相图像提取语义特征,常用卷积神经网络(CNNs)或视觉变换器(VITs ) ,部分结合全局注意力机制,如 ResNet 、VIT 等;时频融合整合双时相特征,捕捉潜在时间特征;语言解码将融合特征转化为自然语言,长短期记忆网络(LSTM)或简单 Transformer 解码器较常用 。
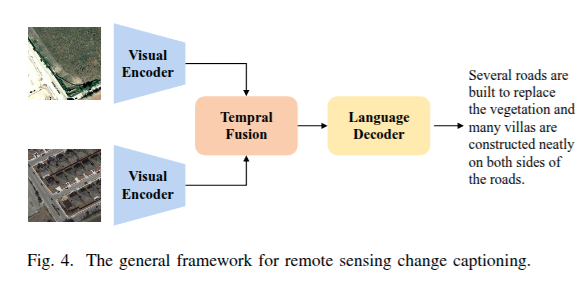
采用自监督学习提取特征增强鲁棒性 ;还聚焦时频融合阶段,提出分层自注意力网络动态聚焦图像不同区域,或用空间差分自注意力模块(SSM ) 、双时态变压器(TT - SSM )实现双时态联合建模 ;在语言解码方面,有研究将融合视觉特征转化为自然语言描述,或解耦 “变化是否发生” 和 “变化内容” 问题,通过多提示学习提高图像对描述能力 。
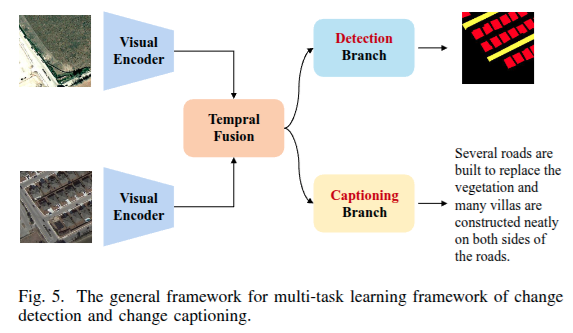
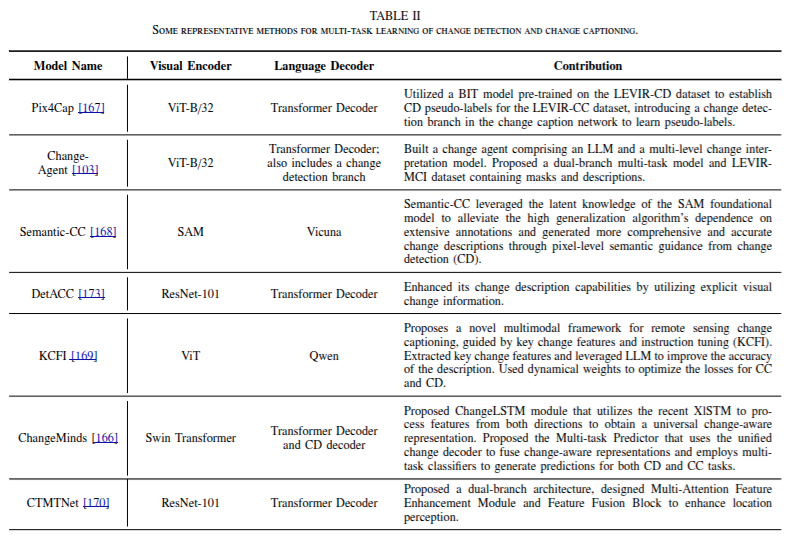
变化检测与描述的多任务学习:Multi-task learning of Change Detection and Captioning
变化检测关注生成像素级或语义级变化掩码,变化描述则旨在理解变化语义,包括对象属性和上下文关系。鉴于二者关联,近期有相关研究探索协同处理这两项任务 。
该编码器从双时相图像中提取特征。在视觉编码阶段,模型关注双时相特征,而变化检测分支利用视觉编码器提取的多尺度双时相特征来检测变化。同时,变化描述分支通常只利用最深层的视觉特征来聚焦变化,其设计与单任务变化描述模型非常相似。
平衡多任务学习框架中两个任务的训练是一个关键挑战。当前的研究通常应用加权损失,结合变化检测和描述的损失权重。
遥感变化视觉问答 Remote Sensing Change Visual Question Answering
遥感变化视觉问答(RS - CVQA)任务旨在根据多时相遥感图像生成自然语言用户响应,以回答特定问题。与变化检测和变化描述不同,RS - CVQA 需要交互式语言参与。
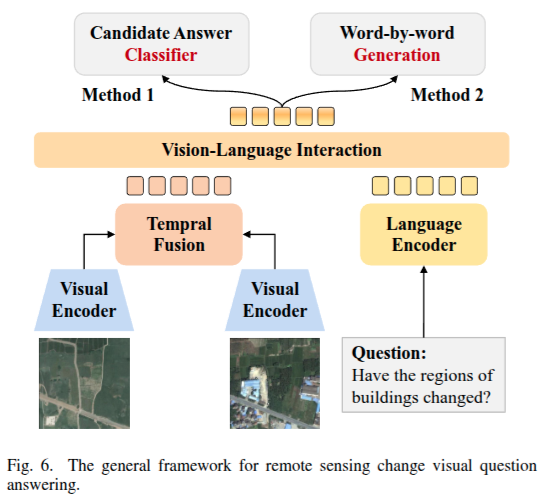
RS - CVQA 模型框架的典型阶段:视觉编码、问题编码、多模态交互和答案生成。
在视觉编码阶段,模型通常使用两个编码器分别提取与多时相遥感图像相关的特征,然后在时间融合中融合这些特征,以捕捉变化相关信息。
在问题编码阶段,预训练语言模型(如 BERT 或 GPT )通常用于将用户的复杂问题转化为适合模型理解的语义嵌入。在多模态交互阶段,应用注意力机制(如自注意力和交叉注意力)来对齐视觉和语言特征,使模型能够关注变化区域并捕捉它们之间的关键关系,从而增强对与图像相关的上下文的理解,并确保生成的答案仍然与视觉内容相关。
最后,答案生成阶段将融合的多模态特征转换为自然语言响应。基于答案生成方法,RS - CVQA 方法大致分为两类:候选答案和逐词生成。在基于候选的 RS - CVQA 中,答案生成模块设计为多分类器,从 5 个预定义的候选答案中选择最佳答案。
遥感文本到变化检索 Remote Sensing Text-to-Change Retrieval
根据用户输入的描述图像变化的文本查询,高效检索双时相图像对。RSI - TCR 更为复杂,因为它涉及 “时相图像” 与 “文本” 之间的 “后事件匹配”.
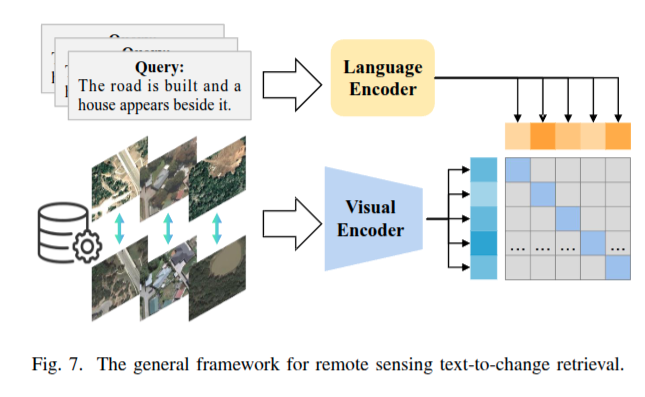
RSI - TCR 的核心挑战之一是假阴性问题。具体来说,在训练批次中,被标记为负样本的图像对,实际上可能是与查询文本匹配的正样本,这会干扰模型训练。
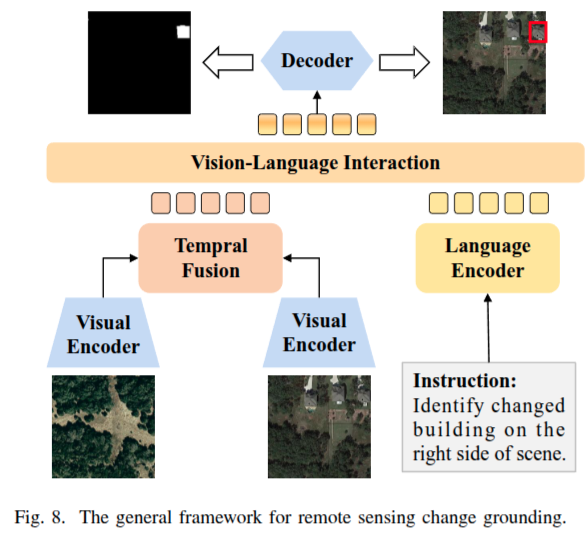
遥感变化定位 Remote Sensing Change Grounding
旨在识别和定位,用户提供的文本查询中所提及的双时相遥感图像内的变化区域。通过将自然语言作为查询模态,与传统限于固定类别输出的变化检测相比,RS - CG 显著增强了用户交互的灵活性。
RS - CG 的输出通常有两种形式:边界框和像素级掩码.边界框用矩形轮廓标注变化区域,直观呈现目标变化的空间位置。像素级掩码则精确勾勒变化区域的形状和边界,是精细分析的理想选择。
Large Language Models Meets Temporal Images
LLM-based Change Captioning
PromptCC 是将 LLMs 引入该任务的早期开创性工作。
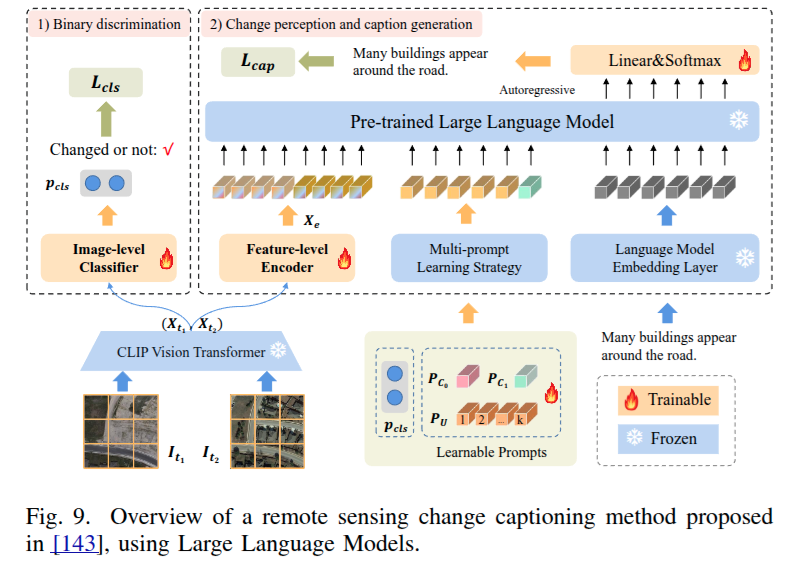
PromptCC 采用共享视觉编码器提取双时相图像特征。特征级编码器融合这些特征,以整合丰富语义,然后输入到 GPT - 2 作为前缀标记。GPT - 2 将这些视觉标记转化为准确的语言描述。为了在该任务中最大化 LLMs 的潜力,PromptCC 引入了一种基于多提示学习的分类器,显著提高了语言生成质量,且无需对 GPT - 2 模型进行微调。这项工作为在变化描述任务中利用 LLMs 奠定了坚实基础。
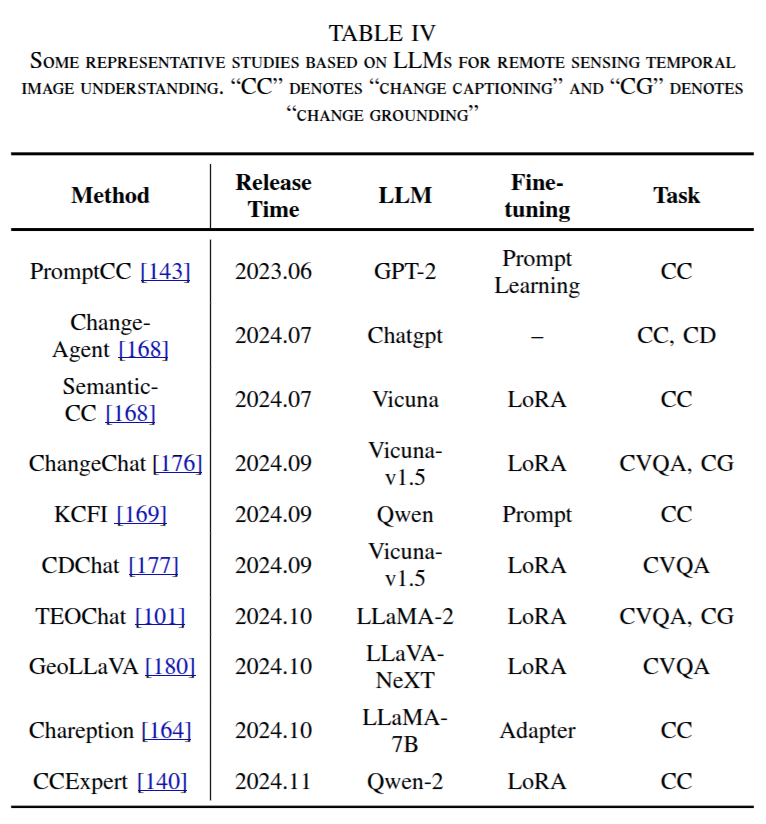
LLM-based Change Visual Question Answering
ChangeChat 是该领域的早期研究,采用了类似于 LLaVA 的架构,通过简单的桥接双时相图像特征和 LLMs ,实现与变化相关的多模态对话。
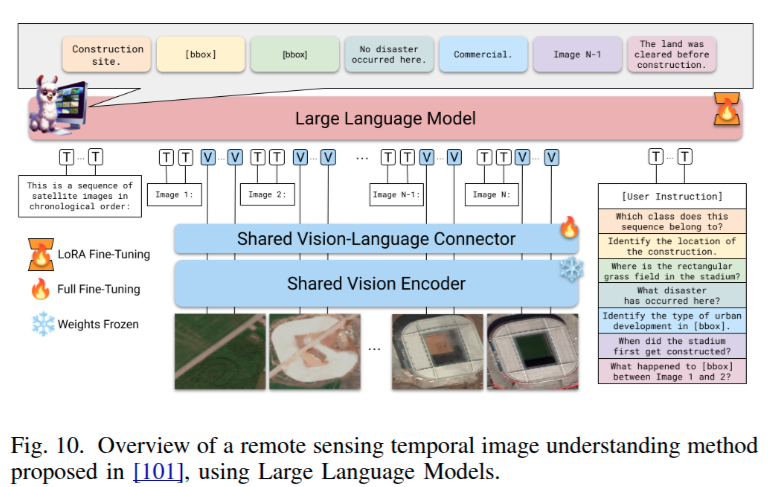
TeoChat 分析任意时间长度的多时相图像,并采用多种联合训练机制,同时优化多个任务,包括时间场景分类、变化检测、变化参考表达和变化问答。这种设计增强了模型的灵活性和稳健性,使其能够进行全面的时空推理。TeoChat 为所有任务的自然语言格式响应进行编码,使基于用户指令的统一任务执行成为可能。
LLM-based Agents
基于 LLM 的智能体通常将 LLMs 用作核心控制器,采用模块化设计,并集成各种工具和模型,以动态适应用户需求,提供高度的灵活性和自主性。
基于 LLM 的智能体具有显著优势,克服了传统模型局限于单任务的缺点。然而,该领域的研究仍处于初期阶段。未来的进展可能集中在优化智能体调度机制、融入遥感领域特定知识以及拓宽解译任务范围。这些努力将为在实际时间图像理解应用中部署智能体奠定坚实基础。
6. Evaluation Metrics
- 语言生成指标:包含了 BLEU、ROUGE、METEOR、CIDEr、 S m ∗ S_{m}^{*} Sm∗ 、BERTScore 等。这些指标各自有其特点和作用,用于评估语言生成的质量,比如评估将图像变化转化为自然语言描述这类任务中生成文本的准确性、完整性、流畅性等方面。
- 文本图像检索指标:如 Recall@K、Precision@K 等,用于评估在根据文本查询检索相关图像任务中的性能,衡量检索结果的召回率和精确率等。
- 局部化指标:像 MIoU、CIoU、Precision@k 等,用于评估对图像中特定区域进行定位和识别的准确性,在遥感变化定位等任务中起到重要作用。
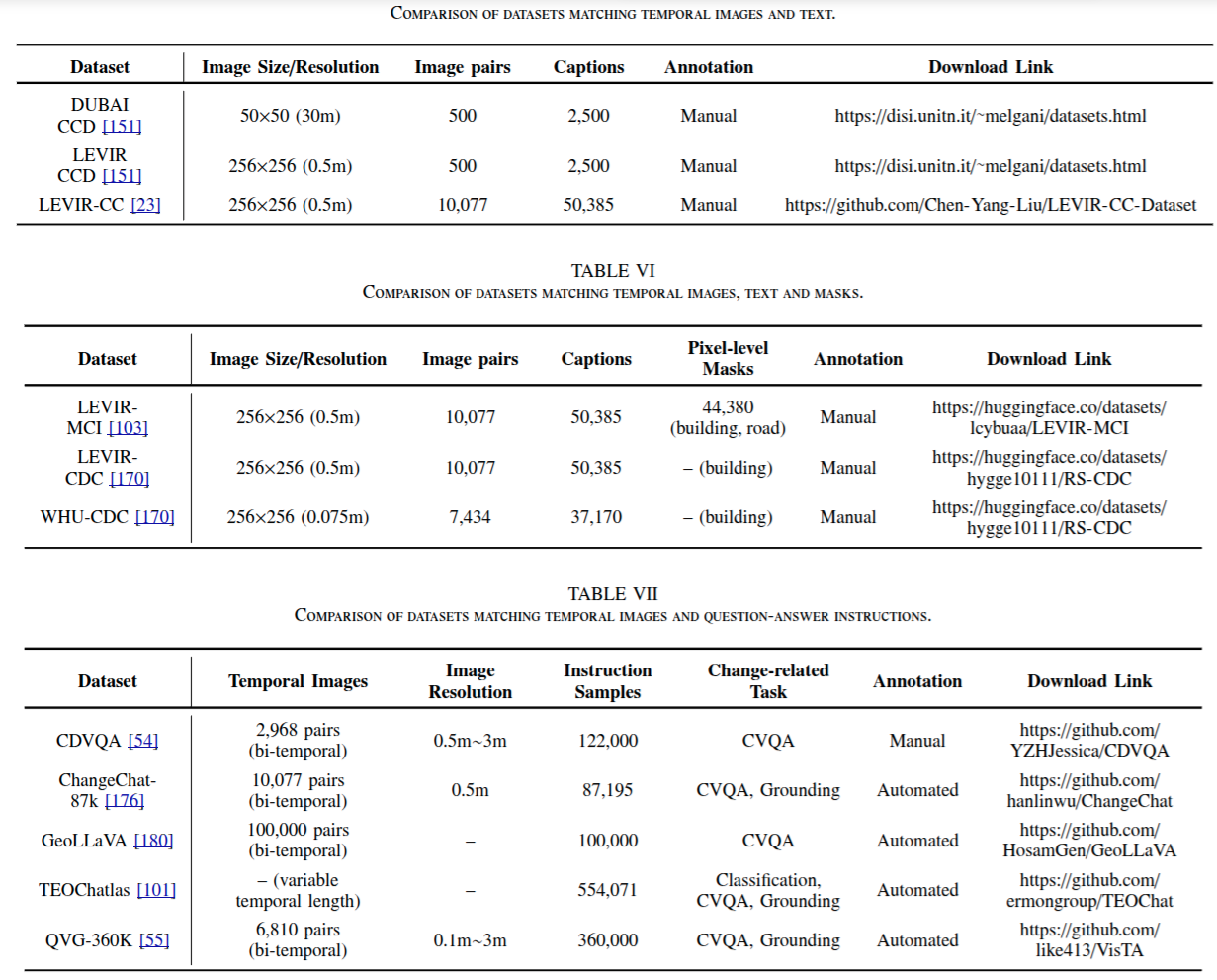
7. Temporal Vision-Language Dataset

匹配时间图像和文本的数据集,匹配时间图像、文本和掩码的数据集,匹配时间图像和问答指令的数据集
8. 未来展望
- 大规模基准数据集:当前时间视觉 - 语言理解研究依赖少量标准数据集,规模和多样性有限,难以满足需求。未来需开发更全面的遥感时间视觉 - 语言数据集,覆盖多样场景和时间点,支持复杂模型训练。
- 时间视觉 - 语言基础模型:以往研究多关注变化描述和变化视觉问答等单一任务,未来可探索统一的时间视觉 - 语言基础模型,整合 LLMs 推理能力,提升时间图像分析灵活性和效率,促进不同任务协同。
- 可变时间视觉 - 语言理解:随着遥感技术发展,多时相遥感图像获取增多,时间序列长度和频率各异。未来研究应聚焦高效处理任意时间长度序列,捕捉丰富时空信息,提升模型对多时相图像理解,应对模型设计挑战。
- 多模态时间图像:现有研究主要关注卫星光学图像时间视觉 - 语言理解,未来可转向多模态融合,结合光学、SAR、红外等数据,全面理解时空感知特征,如 SAR 图像在恶劣天气下可稳定观测。
- 时间智能体:基于 LLMs 的智能体在多任务执行和自动推理展现潜力,未来可设计遥感时间图像理解智能体,根据用户需求动态调整任务策略,结合外部知识库,在复杂时间场景中提升推理能力,为时间遥感图像理解提供灵活高效方案。