xfeat paper笔记
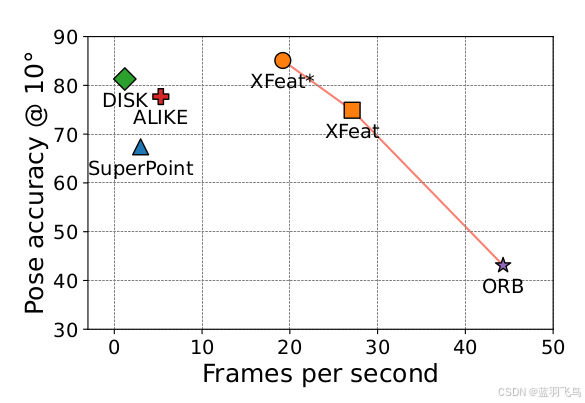
xfeat是面向轻量级的图像匹配的加速特征,
像superpoint这些特征一样,它提取keypoint的坐标,描述子,score等信息,用于图像特征点提取,匹配,定位等。
它的特点就是轻量化,paper指出“在速度上超过了当前基于深度学习的局部特征(快了5倍),具有可比或更好的精度,在姿态估
计和视觉定位方面得到了证明。“
XFeat被设计为与硬件无关的,确保了跨平台的广泛适用性,但这并不排除在特定硬件配置上优化XFeat的可能性。
它的主要贡献点:
- 一种新的轻量级CNN架构,可以部署在资源受限的平台和需要高吞吐量或计算效率的下游任务上,而不需要耗时的特定硬件优化。所提出方法可以在视觉定位和相机姿态估计等几个下游任务中随时替换现有的轻量级手工解决方案、昂贵的深度模型和轻量级深度模型;
- 设计了一个极简的、可学习的关键点检测分支,快速适用于小型提取器骨干,显示了其在视觉定位、相机姿态估计和单应性配准方面的有效性;
- 最后,提出了一种新的匹配细化模块,用于从粗糙的半稠密匹配中获取像素级偏移量。与现有的技术相比, 新策略不需要高分辨率的特
征,除了局部描述符本身外,大大减少了计算量,并分别实现了高精度和匹配密度。
加速策略:
1.骨干网络

为了降低CNN处理成本,一种常见的方法是从浅层卷积开始,然后增量地将空间维度减半(H i , W i ),同时在i-th卷积块中将通道数C i 加倍。这是我们经常见到的做法。
第i 层layer的计算量为
F
o
p
s
F_{ops}
Fops, 我们来理解一下它是如何计算的,假设kernel size为k * k,
那么在一个窗口时,它要与图片上对应的元素计算,计算量为
k
2
∗
C
i
k^2*C_{i}
k2∗Ci, 这个窗口要滑动的次数为
H
i
∗
W
i
H_{i} * W_{i}
Hi∗Wi( 因为是unit stride, padding). output channel为
C
i
+
1
C_{i+1}
Ci+1, 所以有
C
i
+
1
C_{i+1}
Ci+1个卷积核。
因此计算量为
H
i
∗
W
i
∗
C
i
∗
C
i
+
1
∗
k
2
H_{i} * W_{i} * C_{i} * C_{i+1} * k^2
Hi∗Wi∗Ci∗Ci+1∗k2
作者提到在整个网络上对通道进行朴素剪枝C损害了其处理诸如变化的光照和视角等挑战的能力,深度可分离卷积虽然可以把
F
o
p
s
F_{ops}
Fops减少多达9倍,但在局部特征提取中,较浅的网络处理较大的图像分辨率,与它们最初在分类和目标检测等低分辨率场景的使用相比,效果较差。
所以
H
i
∗
W
i
H_{i} * W_{i}
Hi∗Wi称为计算瓶颈。


这里可以看到它的网络结构
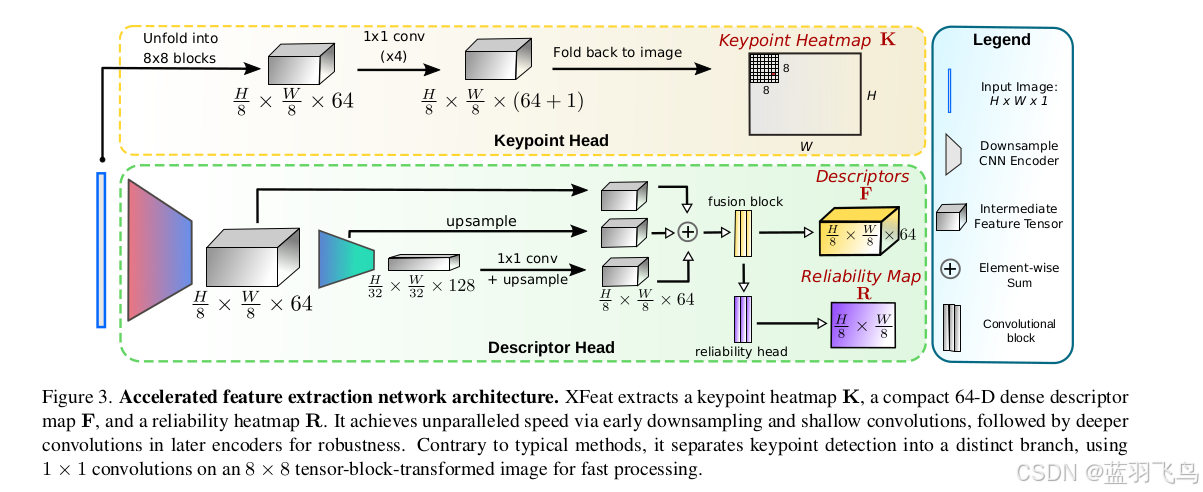

从结构图可以看出,特征点的提取并不经过backbone网络,而是直接从图像提取,这样可以直接关注低层次的局部特征,而不是高维语义特征。并且与描述子提取,置信度预测解耦,避免任务间的梯度冲突。
把input图像表示为每个网格单元上8x8像素组成的2D网格,也就是H * W -> H/8 * W/8 * 64, 经过4个1x1卷积后,得到H/8 * W/8 * (64+1),
+1是一个垃圾箱,表示有没有找到关键点,推理过程中,垃圾箱丢弃,只用64.
训练
数据集:
使用了2个数据集的组合:MegaDepth和 合成变形的COCO,6:4的比例混合使用。这种设计旨在增强模型的鲁棒性和泛化能力。
MegaDepth 是一个专注于单目深度估计(Monocular Depth Estimation)和三维重建(3D Reconstruction)的大型数据集。
数据主要来自Flickr上的互联网图片,涵盖了多种场景(如建筑、自然景观、城市街道等)。
数据集包含:
图像对(Image Pairs)
三维点云(3D Point Clouds)
深度图(Depth Maps)
相机位姿(Camera Poses)
MegaDepth 提供了丰富的场景多样性,有助于训练模型在大视角变化和光照变化下的匹配能力。
为模型提供了真实场景下的特征匹配训练,增强模型对实际应用的适应性。
包含相机位姿和三维点云,可以用于生成准确的关键点匹配,辅助模型学习。
它作为真实数据来源,用于训练模型在真实场景中的关键点检测和描述子提取。
合成变形的 COCO 数据集:
原始 COCO 数据集并不是用于关键点检测或特征匹配的,因此XFeat对其进行了合成变形(Synthetic Warping)处理。
随机几何变换(Geometric Transformations):对 COCO 图像应用仿射变换(Affine Transformations)、透视变换(Perspective Transformations)等操作。
光照和噪声变化(Photometric Changes):调整亮度、对比度、添加噪声,模拟真实世界的图像变化。
生成匹配点对(Matching Pairs):通过已知的变换矩阵自动生成图像对之间的关键点匹配(Ground Truth Matches)。
这样的合成数据帮助训练模型在大尺度变化和几何变化下的匹配能力,由于变换矩阵是已知的,可以方便地生成像素级的关键点匹配标签。
与真实数据(MegaDepth)结合,可以有效防止模型对某些场景过拟合。
6:4的比例:
6(MegaDepth): 提供真实世界的多样场景和复杂特征,有助于模型适应实际应用。
4(Warped COCO): 提供大规模的几何变换数据,提高模型对极端变换的容忍度。
训练描述子F

ground truth是N*4的keypoint坐标,前两个是图片I1中的特征点坐标,后两个是对应的图片I2中的。
但注意到特征点坐标是对应原图尺寸H * W, 而描述子F的尺寸是H/8 * W/8 * 64, 可能需要把ground truth坐标做下采样对应到F,
取出I1, I2坐标对应的F(i), 得到F1, F2,都是Nx64.
计算相似度矩阵S,理论上来说匹配的特征描述子相似度最高,所以对角线上的S应该最高,
再计算ST是为了让特征描述子双向匹配,即F1->F2, F2->F1.
训练Reliability Map R
Reliability Map R 本质上衡量的是特征点的质量,即特征点的可靠性。
在推理阶段,通过计算score = K * R 来对特征点打分,筛选出top-K个score最高的点。
R也是通过网络学习出来的。
这个损失函数设计得很有意思。

注意到损失函数中有的R头上没有横线,有的R头上有个横线。
头上没有横线的R就是网络学习出来的,有横线的是通过F计算出来的dual-softmax.
前面说了S是根据ground truth提取出来的成对的描述子算出来的相似性矩阵,也就是不同特征对间的相似性分数,分数越高越匹配。
R1(头上有横线)表示F1匹配F2, R2(头上有横线)表示F2匹配F1,(softmax分别对S的行和列归一化)
当F1和F2双向都匹配的时候,R1和R2的乘积才会大,只要有一方面不匹配,分数小,就会把乘积拉低。因此用Hadamard product就是用来衡量双向匹配的。
Hadamard 积是对两个向量或矩阵的逐元素相乘操作。
把网络学习到的R也用softmax做归一化,让两个图片学习到的R都接近于F1与F2的匹配度,就是这个损失函数的意义。
为什么要让R接近R1与R2的Hadamard 积?
让模型输出的置信度(σ®)与理想的双向匹配置信度(Rˉ1 ⊙R2 )一致。
模型会倾向于学习可靠的匹配关系,而忽略那些单向高置信度但实际不可靠的匹配。
为什么不直接用两个网络学习的R相乘?
梯度回传问题:R1 ⊙R2 会导致梯度回传时互相影响,不利于稳定训练。
优化效率差:两个动态变量的相乘会让模型很难收敛,训练过程不稳定。
监督不明确:用 Sigmoid 后模型才会输出合理的置信度,更易与 Rˉ对齐。
R1和R2(头顶上有线),是对行求max, 所以算出来的应该是1 * Row的向量,双向匹配置信度,也就是它俩算Hadamard 积,也还是1 * Row的向量,而sigmoid(R)是H/8 * W/8的矩阵,它们的shape并不对应。
实际可能会经过reshape或flatten使它们的维度调整一致。
训练pixel offsets
为什么需要pixel offsets, 我的理解是模型输出的descriptors的尺寸为[H/8, W/8], 根据descriptor的相似度匹配的话,得到的是粗匹配,毕竟是下采样的尺寸。如果想得到精细匹配,还需要知道在原图上的偏移。
我猜测ground truth是这样得到的,匹配点(x1, y1) 和 (x2, y2), 下采样8倍得到粗匹配的点(x1/ 8, y1 / 8), (x2 /8, y2/ 8), 这也是用于训练匹配的点。offset可能是把图片2,也就是用于和图片1匹配的图片,的(x2 /8, y2/8)复原到原尺寸,看和初始的(x2, y2)偏移了多少,得到offset.
由于是下采样8倍,offset范围在8 * 8. 所以预测的就是8 * 8的网格图。
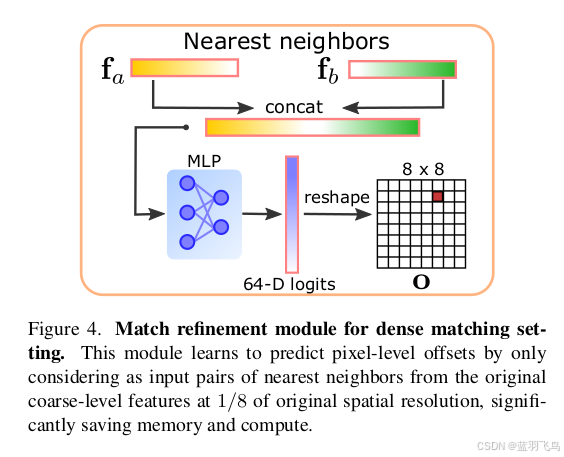
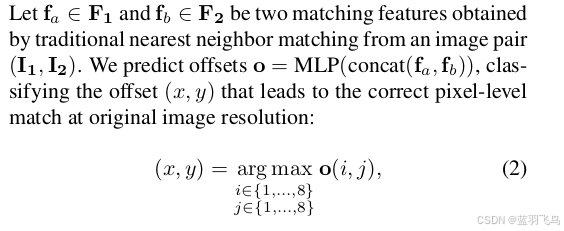
ground truth中为图片1和图片2的互相匹配的特征点坐标,用这些坐标从F1,F2中采样到对应的特征点的64维的描述子fa, fb. 。
注意坐标要下采样8倍和F的尺寸匹配。
把fa和fb拼接起来,通过MLP预测offset, 还是64维,reshape成8x8, 推理时这样得到offset.
训练时用到ground truth的offset, 计算NLL损失。其中o就是8x8的grid.

训练keypoints
keypoint的训练是蒸馏ALIKE的特征点,keypoint的提取不在backbone, 而是一个独立的小网络,直接从原图重新调整的结构出发,
可以集中提取lower level的信息。

这段话我的理解是把ALIKE提取的特征点坐标map到 H/8 * W/8 上,我们需要的是一个offset,
就是判断(x, y)坐标会落到哪个8x8的grid里,然后计算和当前grid左上角的offset, 得到(tx, ty),
这样tx, ty都是[0,8]范围内的,就可以得到64维度上的偏移量
t
i
d
x
=
(
t
x
+
t
y
∗
8
t_{idx} = (t_x + t_{y} * 8
tidx=(tx+ty∗8。
当这个grid没有特征点时,
t
i
d
x
t_{idx}
tidx=64. 也就是垃圾桶bin.
理论上来说网络预测的结果应该是特征点处的score最大,所以同样用了NLL loss.
特征点处的score越大,损失就越小。
类别不平衡问题:
图像中大多数区域都没有关键点,导致“垃圾桶”类别的样本过多,产生类别不平衡。如果直接训练,模型会倾向于总是预测“没有关键点”,这样轻易就能获得较低的损失。
paper中的解决方法是对没有关键点的样本设置上限,具体来说,可能是设置了一个上限,比如每个batch最多选择500个没有关键点的样本,如果没有关键点的样本超出了上限,就随机丢弃多余的样本。
最后总的loss就是descriptor的loss, reliability map的loss, 特征点精匹配的offset的loss, 和keypoint loss之和。
加权重。
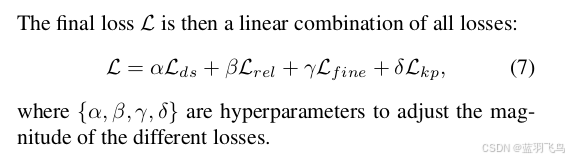
推理阶段

这里介绍了两个方法的推理,一个是稀疏XFeat, 另一个是半稠密的XFeat*,
先介绍XFeat.
网络可以直接得到keypoint K 和 reliability map R.
用score = K * R 筛选出top-k个特征点(k=4096), 根据keypoint的位置对descriptor F进行双三次插值,得到keypoint对应的descriptors.
下面有几个问题:
1.K的shape是(H, W), R的shape是(H/8, W/8), 如何相乘?
可能的实现方式,R上采样到(H,W),考虑到上采样不会丢失 K 的细粒度信息,能充分利用 Keypoint Heatmap 的高分辨率特性。
2.什么是双三次插值?
插值过程使用 16 个邻近的像素(即 4×4 区域)来估算目标位置的值。
keypoint的坐标是亚像素级,可能包含小数。

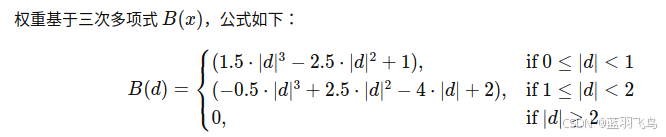
下面举个例子说明:



上面是一维的情况,现在拓展到descriptor F,

相当于把前面grid中的每个数字换成了64维的向量,用向量作乘加。
3.为什么要对F做插值计算?
直接将 K 的关键点坐标应用到 F 上,会遇到分辨率不匹配的问题,因为 K 中的坐标对应于原图,而 F 的特征点位置是稀疏的(H/8, W/8).
关键点检测任务的目标是预测像素级别甚至亚像素级别的关键点坐标,例如 (x,y)=(25.3,45.7),使用插值方法(如双三次插值)在特征图上计算非整数坐标对应的特征描述子。
还有一个问题是K的shape为(H, W), F的shape为(H/8, W/8), 是不是要先把F上采样到(H, W), 再找到最近的整数值坐标,再插值到亚像素级坐标对应的descriptor?还是直接对keypoint的坐标下采样8倍,直接插值得到descriptor?
这两种理论上都可行,具体需要看代码中的实现。
4.什么是MNN search
也就是Mutual Nearest Neighbor(MNN) search, 是一种用于特征匹配的策略,通常在图像特征点匹配任务中使用.
下面来比较NN和MNN:


单向最近邻搜索可能会导致误匹配,MNN 搜索增加了一致性约束,过滤掉了一些错误匹配对。
再说XFeat*.
XFeat* 另外增加了对原图像的0.65倍和1.3倍的缩放。
对每种尺度的图像,分别通过网络提取Keypoint Heatmap K、Reliability Map R 和 Descriptor Map F。
将所有尺度的特征点、描述子和评分结果合并。
1.把原图scale到0.65和1.3, 每个尺度下根据score=K*R提取topk=10000个特征点
2.每个尺度的图像对,对特征描述子F用插值法得到keypoint对应的descriptor, 计算相似性矩阵,再用MNN search进行特征匹配。
3. 匹配好的descriptor对送进MLP预测offset.
4. keypoint+offset的位置rescale到原图尺寸,去重后得到原图上的匹配点对。
以上是对paper的解读,可能有存在偏差的地方,具体实现细节还是要参考代码。