基于LangChain 实现 Advanced RAG-后检索优化(上)-Reranker
摘要
Advanced RAG 的后检索优化,是指在检索环节完成后、最终响应生成前,通过一系列策略与技术对检索结果进行深度处理,旨在显著提升生成内容的相关性与质量。在这些优化手段中,重排序优化(Reranker)作为核心技术之一,凭借其对检索结果的二次筛选与优先级调整能力,成为提升 RAG 系统性能的关键。以下将围绕重排序优化(Reranker)的理论基础、算法原理及实践应用展开详细阐述。
重排序(Reranker)
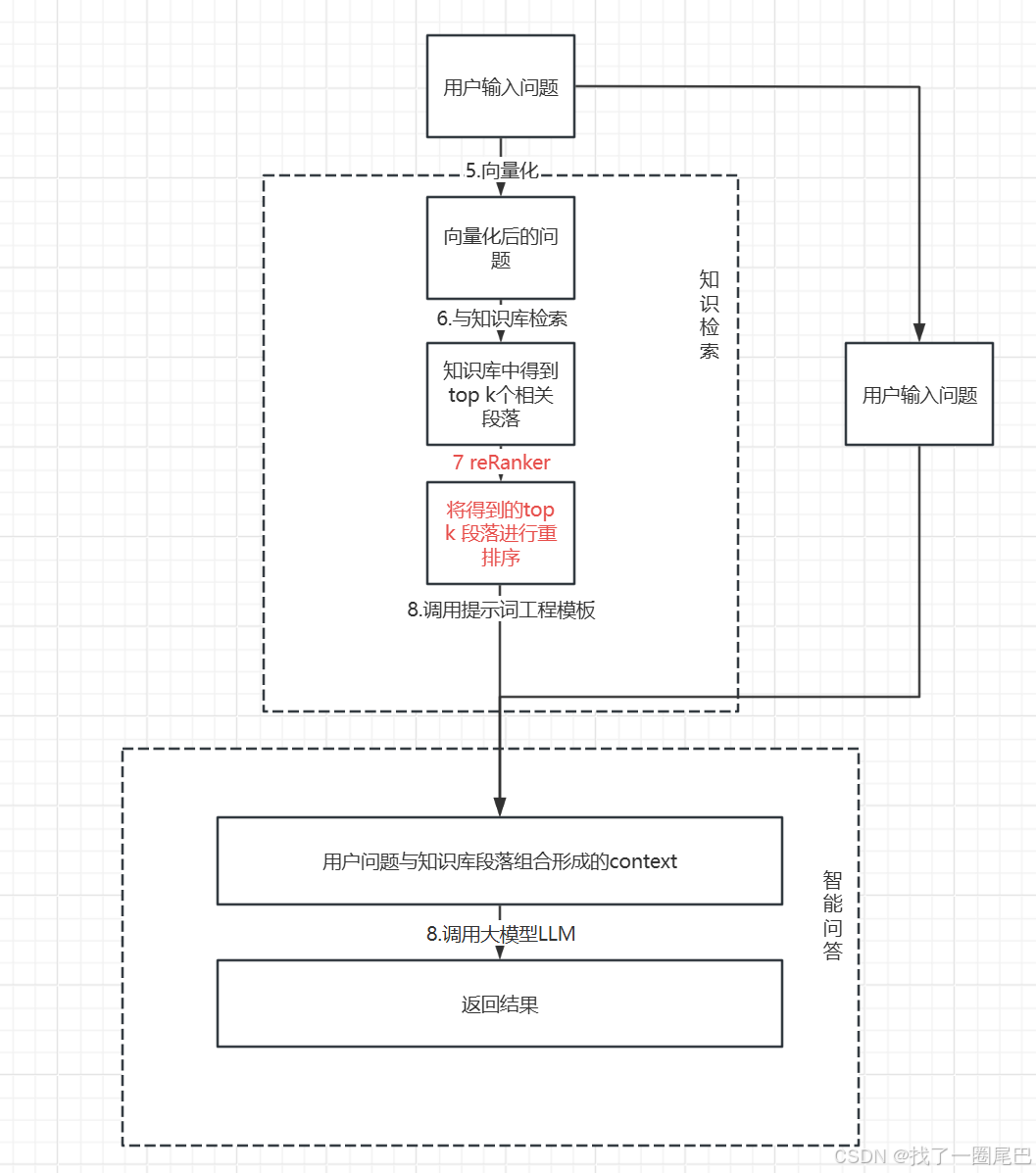
Reranker 在 RAG 中的作用位置
Reranker 是信息检索(IR)生态系统中的一个重要组成部分,用于评估搜索结果,并进行重新排序,从而提升查询结果相关性。在 RAG 应用中,主要在拿到向量查询(ANN)的结果后使用 Reranker,能够更有效地确定文档和查询之间的语义相关性,更精细地对结果重排,最终提高搜索质量。
目前,Reranker 类型主要有两种——基于统计和基于深度学习模型的 Reranker:
-
基于统计的 Reranker :汇总多个来源的候选结果列表,使用多路召回的加权得分或倒数排名融合(RRF)算法来为所有结果重新算分,统一将候选结果重排。这种类型的 Reranker 的优势是计算不复杂,效率高,因此广泛用于对延迟较敏感的传统搜索系统中。
-
基于深度学习模型的 Reranker:通常被称为 Cross-encoder Reranker。由于深度学习的特性,一些经过特殊训练的神经网络可以非常好地分析问题和文档之间的相关性。这类 Reranker 可以为问题和文档之间的语义的相似度进行打分。因为打分一般只取决于问题和文档的文本内容,不取决于文档在召回结果中的打分或者相对位置,这种 Reranker 既适用于单路召回也适用于多路召回。
RRF 倒数排名融合
倒数排名融合(Reciprocal Rank Fusion,RRF)是一种用于融合多个检索结果列表的算法,常用于信息检索、RAG 混合检索等领域,它将不同检索方法得到的排名结果进行结合,生成更全面、准确的最终排名。它考虑了每个文档在不同检索结果列表中的排名位置,通过计算排名的倒数来赋予不同文档相应的权重,从而综合评估文档的重要性。

-
计算步骤
-
最大化检索召回率:在初始检索阶段,通过增加向量数据库返回的文档数量(即增加 top_k 值),可以提高检索的召回率。这意味着尽可能多地检索相关文档,确保不会遗漏任何可能有助于 LLM 形成高质量回答的信息。
-
计算每个文档的 RRF 分数:对于每个文档,计算它在每个检索结果列表中的排名的倒数,并将这些倒数相加。
-
重新排序:根据 RRF 分数对所有文档进行降序排序,得到最终的融合结果。
-
-
优点
-
低门槛高效融合:RRF 具备极强的 “即插即用” 特性,无需复杂调优过程,也无需提前协调不同检索方法相关性指标的一致性。
-
排名导向的简洁性:RRF仅依据文档在各检索结果中的排名进行计算。这种简洁的设计不仅大幅简化了融合流程,还减少了数据处理量,使得 RRF 在计算资源有限或实时性要求高的场景下,依然能够稳定高效运行 。
-
检索性能友好:与其他需要额外重排序步骤、可能导致响应延迟显著增加的融合算法不同,RRF 不会对检索系统的响应速率造成明显影响。
-
-
缺点
-
RRF 存在明显的 “上游依赖” 问题,其性能表现高度依赖前置检索排序步骤的质量。若初始检索排序因算法缺陷、数据偏差等原因出现错误,例如误将相关性低的文档排在前列,RRF 会基于错误的排名信息进行融合计算,不仅无法修正错误,反而可能进一步放大偏差,导致最终检索结果严重失真,使得融合后的排序完全偏离实际相关性,难以满足用户真实需求。
-
-
RRF代码实现
- RRF 算法
def rrf_rank(documents: list[list[Document]], k=60) -> list[Document]:# 初始化rrf字典(key=文档id,value={"rrf_score":累计分数,"doc":文档对象})rrf_scores = {}# 遍历每个检索结果列表(每个查询对应的结果)for docs in documents:# 为每个文档列表计算排名(从1开始)for rank, doc in enumerate(docs,1):# 计算当前文档的RRF分数rrf_score = 1 / (k + rank)# 如果文档已经在字典中,累加RRF分数if doc.id in rrf_scores:rrf_scores[doc.id]['rrf_score'] += rrf_scoreelse:rrf_scores[doc.id] = {'rrf_score': rrf_score,'doc': doc}# 将字典转换为列表,并根据字段value:RRF分数排序sorted_docs = sorted(rrf_scores.values(),key=lambda x: x['rrf_score'],reverse=True # 降序排列:从大到小)for item in sorted_docs:print(item)result = [item['doc'] for item in sorted_docs]return resultrrf_rank(documents)-
LangChain 框架使用 RRF
from langchain.retrievers import MultiQueryRetriever
from typing import List
from langchain_core.documents import Document
from langchain_core.callbacks import CallbackManagerForRetrieverRunimport logging
# 打开日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)# 重写MultiQueryRetriever类,取消unique_union去重,且保留每个问题检索结果的
class RRFMultiQueryRetriever(MultiQueryRetriever):# 改写retrieve_documents方法,返回rrf结果def retrieve_documents(self, queries: List[str], run_manager: CallbackManagerForRetrieverRun) -> List[Document]:documents = []for query in queries:docs = self.retriever.invoke(query, config={"callbacks": run_manager.get_child()})# 原代码中extend修改为append,保持不同检索系统的结构documents.append(docs)documents = self.rrf_documents(documents)return documentsdef rrf_documents(self,documents: list[list[Document]], k=60) -> List[Document]:# 初始化rrf字典(key=文档id,value={"rrf_score":累计分数,"doc":文档对象})rrf_scores = {}# 遍历每个检索结果列表(每个查询对应的结果)for docs in documents:# 为每个文档列表计算排名(从1开始)for rank, doc in enumerate(docs,1):# 计算当前文档的RRF分数rrf_score = 1 / (k + rank)# 如果文档已经在字典中,累加RRF分数if doc.id in rrf_scores:rrf_scores[doc.id]['rrf_score'] += rrf_scoreelse:rrf_scores[doc.id] = {'rrf_score': rrf_score,'doc': doc}# 将字典转换为列表,并根据字段value:RRF分数排序sorted_docs = sorted(rrf_scores.values(),key=lambda x: x['rrf_score'],reverse=True # 降序排列:从大到小)result = [item['doc'] for item in sorted_docs]return resultrrf_retriever = RRFMultiQueryRetriever.from_llm(retriever=retriever,llm=llm,include_original = True #是否包含原始查询
) rrf_docs = rrf_retriever.invoke("人工智能的应用")pretty_print_docs(rrf_docs)我们采用自定义一个RRFMultiQueryRetriever检索器的方法。这个检索器继承了LangChain 的MultiQueryRetriever 检索器,并融合了RRF 算法。
Reranker模型
Reranker模型又称交叉编码器(Cross-Encoder)模型。它是信息检索、推荐系统等场景中的关键组件,用于对初步召回的候选集进行精细化排序。与召回阶段的快速筛选不同,Reranker通过复杂模型捕捉细粒度特征(如语义相关性、上下文信息、用户偏好),显著提升最终结果的准确性和个性化。
阿里魔搭Reranker模型
在中文 Reranker 应用场景中,我推荐选用国产 Reranker 模型。国产模型在训练时使用了大量的中文语料,对中文语义的理解更为深刻、全面,能够更精准地捕捉中文语境下的细微语义差别,因此在处理中文任务时可以带来更出色的效果。
你可以前往阿里魔搭社区搜寻合适的 Reranker 开源模型。在该社区中,你可以重点关注那些下载量高或者喜欢数多的模型,例如 beg - reranker 相关模型,这些模型往往经过了大量用户的实践检验,具备较高的可靠性和实用性。
常见Reranker模型类型
-
基于学习排序(Learning to Rank, LTR)
-
原理:利用机器学习模型对文档排序,分为三类:
-
Pointwise:直接预测文档与查询的绝对相关性(如线性回归、GBDT)。示例:预测点击率(CTR)作为排序依据。
-
Pairwise:比较文档对的相对顺序,最小化错误比较(如RankNet、RankSVM)。示例:判断文档A是否比文档B更相关。
-
Listwise:优化整个排序列表的指标(如NDCG、MAP),直接端到端优化目标。示例:LambdaMART(GBDT+Listwise)、ListNet。
-
-
-
基于预训练语言模型(PLM)的Reranker
-
核心:利用BERT、RoBERTa等预训练模型捕捉深层语义交互。
-
典型架构:
-
Cross-Encoder:将查询与文档拼接输入模型,直接计算相关性得分。
-
示例:
[CLS] Query: How to learn Python [SEP] Document: Python tutorial [SEP]→ 输出相关性分数。 -
优点:捕捉细粒度语义交互,精度高。
-
缺点:计算成本高(需逐对计算,适合小候选集)。
-
-
ColBERT:解耦查询与文档编码,通过后期交互提升效率。
-
流程:分别编码查询和文档,计算最大相似度(MaxSim)作为得分。
-
优点:比Cross-Encoder快,适合较大候选集。
-
-
-
-
多模态Reranker
-
适用场景:融合文本、图像、视频、用户行为等多模态特征。
-
示例:电商场景中,结合商品标题(文本)、图片(视觉)、用户历史点击(行为)综合排序。
-
模型:多模态Transformer(如CLIP扩展)、特征拼接+深度学习。
-
Reranker 模型代码实现
-
本地Reranker模型
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder# reranker
model = HuggingFaceCrossEncoder(model_name=model_path, model_kwargs={'device': 'cpu'})
# 取前3个
compressor = CrossEncoderReranker(model=model, top_n=3)compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever # retriever = 混合检索 或 multi-query
)compressed_docs = compression_retriever.invoke("人工智能的应用")
pretty_print_docs(compressed_docs)-
阿里Reranker模型
from langchain_community.document_compressors.dashscope_rerank import DashScopeRerank# https://bailian.console.aliyun.com/?tab=api#/api/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2780056.html
# gte-rerank
compressor = DashScopeRerank()compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("人工智能的应用")
pretty_print_docs(compressed_docs)LongContextReorder
-
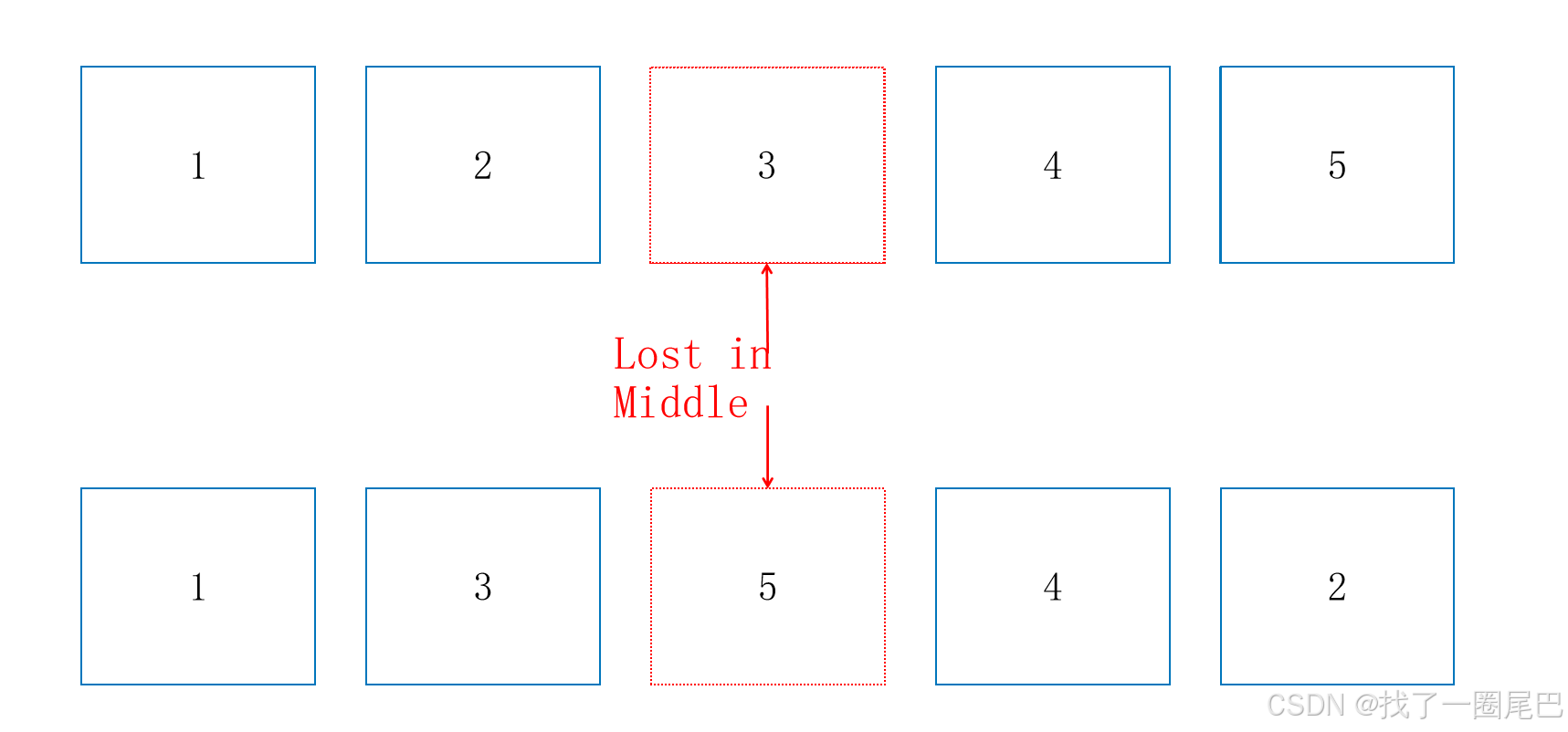
论文基础:Lost in the Middle: How Language Models Use Long Contexts
[2307.03172] Lost in the Middle: How Language Models Use Long Contexts
根据论文描述,当关键数据位于输入上下文的开头或者结尾时,大模型的回答通常会获得最佳的效果。为了减轻"lost in the middle"的影响,我们可以在检索后重新排序文档,使最相关的文档位于最佳位置(如上下文的第一和最后部分),将不相关的文档置于中间。
代码实现
LangChain 框架提供了LongContextReorder思想的代码封装:
from langchain_community.document_transformers import LongContextReorder
# 5,4,3,2,1
# 倒排:1,2,3,4,5
# index%2=0: 往第一个放,index%2=1 往最后放documents = ["相关性:5","相关性:4","相关性:3","相关性:2","相关性:1",
]reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(documents)print(reordered_docs)总结
| 排序方法 | 说明 | 案例 |
|---|---|---|
| RRF | 根据文档在不同列表排名重排序 | 优点:计算简单、处理大数据快;无需大量训练数据; 缺点:仅依排名,忽略文档内容与语义,精准度欠佳; |
| Reranker | 基于深度学习,根据查询与文档语义重排序 | 优点:能深入理解语义,精准重排提升检索精度; 缺点:对新查询和文档泛化能力有限,易出现过拟合情况 |
| Lost in the Middle | 根据相关性降序排列后的文档再次排序,将相关的文档置于极值(开头与结尾) | 依赖重排精准度 |