c语言的常用关键字
c语言的常用关键字
- c语言的关键字
- 表示数据类型的关键字
- auto
- char
- float
- double
- int
- long
- short
- void
- signed
- struct、enum、union
- unsigned
- 表示分支语句的关键字
- if
- else
- switch
- break
- case
- continue
- default
- 表示循环语句的关键字
- while
- do
- for
- goto
- 用于修饰变量或函数的关键字
- const
- const修饰变量的漏洞
- const修饰指针
- const修饰的整型变量用于定义数组
- extern
- register
- static
- static修饰局部变量
- static修饰全局变量
- static修饰函数
- volatile
- 有自己特殊作用的关键字
- return
- sizeof
- typedef
c语言的关键字
之前学习c语言时,关键字基本都是学到了就简单了解,用到了不了解的就查。
现在c语言学完了绝大部分,因此用一篇笔记简单记一下各个关键字的用法。很多记的不详细,也可能漏掉很多,真正用到了再补充。
c语言的关键字:
auto break case char const continue default do double else enum
extern float for goto if int long register return short signed
sizeof static struct switch typedef union unsigned void volatile while
c++在c语言的基础上还有拓充。
表示数据类型的关键字
这种关键字有auto,char,double,enum,float,int,long,short,signed,struct,union,unsigned,void。
auto
自动,一般用在局部变量。auto可以根据定义的数据自动推导变量的数据类型。
例如:
#include <stdio.h>
void f() {//测试auto用于定义局部变量auto ch = 'w';auto int num = 6;int num2 = 7;printf("%c\n", ch);printf("%d\n", num);printf("%d\n", num2);
}int main() {f();auto ch = 'w';auto int num = 6;int num2 = 7;printf("%c\n", ch);printf("%d\n", num);printf("%d\n", num2);return 0;
}
ch,num,num2都是局部变量(在其作用域),是自动创建,自动销毁,也算是一种自动变量。
有时局部变量原本是这样写:int num2 = 6;
但实际上是这样写:auto int num2 = 6;。
后C11标准的局部变量都是自动变量,故不常写或者说不这样写。
auto在c++有更完善的功能。
char
既是类型,又是关键字。
作为数据类型是字符型,主要用于声明或定义用于存储 1 byte 数据的字符(或数据)的变量或常量。这样的变量一般称之为字符变量(常量)。
char ch = 'c';//定义变量ch用于存储字符c
在仅表示正数的情况下,可以当成整数用。
因为整型提升的原因(见c语言的操作符详解和二进制简单应用_符点数二进制-CSDN博客),只要符号位是0,经过整型提升后char会被当成int型变量参与计算。
例如:
#include<stdio.h>int main() {char ch = 67;printf("%u", sizeof(ch % 13));return 0;
}
输出4,说明ch被当成整型数据进行计算,会最终转换成整型来处理。
和*结合可组成指针类型char*,可通过char*访问 1 byte 的内存。这样的指针称之为字符指针。
访问的前提是内存可以合法访问,比如其他类型的变量占用的内存、堆区申请的内存。下文的指针变量同理。
float
既是类型,又是关键字。
作为数据类型是单精度浮点型,主要用于存储 4 byte 的浮点数。
float num = 3.14f;//定义变量num用于存储浮点数3.14
这里3.14f加后缀是为了让编译器将后面的3.14识别为单精度浮点数。
浮点数的存储规则详见c语言的数据在内存中的存储-CSDN博客。
和*结合可组成指针类型float*,可通过float*访问 4 byte 的内存,但是是以浮点数的存储方式进行解读。
double
既是类型,又是关键字。
作为数据类型是双精度浮点型,主要用于存储 8 byte 的浮点数。
double num = 3.14;//定义变量num用于存储浮点数3.14
浮点数的存储规则详见c语言的数据在内存中的存储-CSDN博客。scanf和printf的格式用%lf表示double型。
也可以和long组成能存储更高精度的浮点数的long double型。long double型变量能使用的内存大小取决于编译器。scanf和printf的格式用%llf表示long double型。
和*结合可组成指针类型double*,可通过double*访问 8 byte 的内存,但是是以浮点数的存储方式进行解读。
int
既是类型,又是关键字。
作为数据类型是整型,主要用于存储 4 byte 的整型数据。
int num = 3;
和*结合可组成指针类型int*,可通过int*访问 4 byte 的内存。scanf和printf的格式用%d表示int型。
long
既是类型,又是关键字。
有 4 byte 和 8 byte 两种,取决于编译器。
作为数据类型是长整型。
long int num = 3l;
long num2 = 3L;
3l和3L是为了让编译器能将它们识别成long型数据。scanf和printf处理long型数据用%ld。
也可以两个long拼在一起组成 8 byte 的超长整型。
long long int num = 3ll;
long long num2 = 5LL;
3ll和5LL是为了让编译器能将它们识别成long long型数据。scanf和printf处理long型数据用%lld。
和*结合可组成指针类型long*或long long*。
可通过long*访问 4 byte 或 8 byte 的内存,这同样取决于编译器。
可通过long long*访问 8 byte 的内存。
short
既是类型,又是关键字。
作为数据类型是整型,主要用于存储 2 byte 的段整型数据。
short int num = 3;
short num2 = 3;
没有专门的数字后缀让编译器将数字识别为short型,short在存储数据时会截取 2 byte 的数据。
和*结合可组成指针类型short*,可通过short*访问 2 byte 的内存。scanf和printf的格式没有专门用于short的格式。
void
作为类型是空类型,但无法用于声明和定义变量。
作为函数类型表示函数无返回值,强制终止函数运行用return;。
void f(){return;
}
与*结合成void*指针,可以用于存储地址,但不能解引用,需要经过二次强制转换成其他类型的指针,才能解引用。
signed
有符号的数据类型(与unsigned相对)。但因为除了自定义类型的类型,只要不是加了unsigned修饰,都是有符号的类型,因此很少用。
struct、enum、union
自定义类型关键字。
struct能指定一个或几个变量作为一个类型进行统一管理。
enum能指定几个特定的符号作为常量。
union用于指定共用体。
详细见c语言的自定义结构-CSDN博客。
unsigned
作为类型是unsigned int,用于存储 4 byte 的无符号整型数据。
除此之外,就是用于修饰整型,使得这个整型变成无符号整型。能修饰的整型有{char,short,int,long,long long}。
无符号的意思是将符号位也用来计数。scanf和printf的格式用%u表示变量按照unsinged int型变量进行处理,其他都是在原来的%符号的基础上加u。例如%uc是无符号字符型(也有说法是存储 1 byte 数据的类型)。
例如
unsigned int是同样用于存储 4 byte 的整型,但它能存储的数据范围是[0,4294967295],即 [ 0 , 2 32 − 1 ] [0,2^{32-1}] [0,232−1]。而同样是存储 4 byte 的
int型,能存储的数据范围是
[-2147483648,2147483647],即 [ − 2 31 , 2 31 − 1 ] [-2^{31},2^{31}-1] [−231,231−1]。
关于无符号数的性质详细见c语言的操作符详解和二进制简单应用_符点数二进制-CSDN博客。
表示分支语句的关键字
这里的关键字详细见c语言的语句详解-CSDN博客。这里只做随口说明。
if
选择语句的核心。
else
和if搭配使用作为其他分支。
switch
选择语句的另一种形式。能指定有限种能用整型表达式表示的情况。
break
跳出离break最近的循环和switch作用域。
case
在switch中表示switch的一个分支。
continue
用于跳到下一次循环。
default
是switch语句块的默认选项。
表示循环语句的关键字
这些关键字除了goto,都常用于循环语句。详细见c语言的语句详解-CSDN博客。
while
表示循环代码块while(exp){}。
do
和while一起组成循环。
for
和while的区别是()内分3个部分:for(exp1;exp2;exp3){}。
goto
能用于跳转到指定标签。
用于修饰变量或函数的关键字
const
修饰类型,赋予类型常属性(也有说法是修饰后面的对象)。
const仅在语法层面规定常量的属性,经const修饰的类型定义出来的变量有人称作常变量。例如N就是常变量的一种:
const int N = 6;
常变量本质上仍是变量,只不过在程序运行期间其值不能被修改。在编译阶段,常变量的值或许还不能确定,要到运行时才可以确定。
const修饰变量的漏洞
但将这个常变量的地址交给另外一个不加const修饰的指针时,可以通过这个指针间接修改常变量。例如这个案例:
#include<stdio.h>int main() {const int N = 3;int* a = &N;printf("%d\n", N);*a = 6;printf("%d\n", N);return 0;
}
输出:
3
6这么做很明显违规(指加const修饰后,本意是希望它不能改变),但编译器并不会阻止这种行为,最多加一个警告。
const修饰指针
指针也能加const修饰。const和*的位置关系有3种情况:
情况1:const在*左边。
例如p和p2:
int b = 0;
const int* p = &b;
int const* p2 = &;
const int*和int const*是一个意思,它们都是const在*的左边。
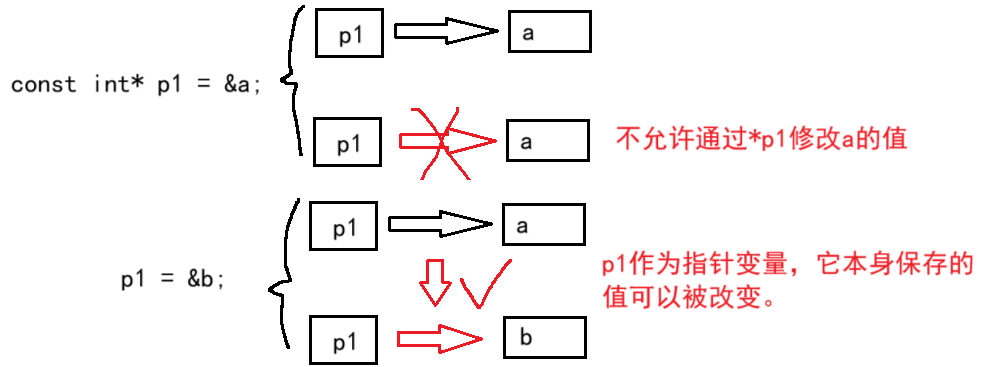
const放*左边,则不可通过定义的指针变量修改它指向的地址处的内存的数据,但这个指针变量可以被修改。
#include<stdio.h>int main() {int a = 4;const int* p1 = &a;int const* p2 = &a;printf("%p\n%p\n\n", p1, p2);不可通过const修饰的指针间接修改背后的内存的数据//*p1 = 5;//*p2 = 6;int b = 8;p1 = &b;printf("%p\n%p\n", p1, p2);return 0;
}
情况2:const在*右边。
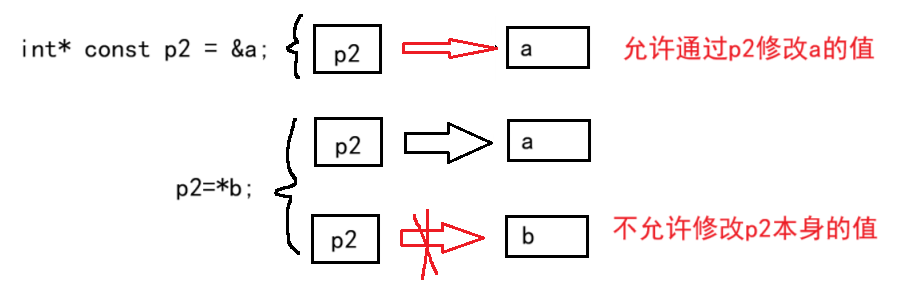
const放*右边,则和放左边不一样:可以通过定义的指针变量修改它指向的地址处的内存的数据,但这个指针变量不可以被修改。
#include<stdio.h>int main() {int a = 4;const int* p1 = &a;//const在*之前int* const p2 = &a;//const在*之后printf("%p\n%p\n\n", p1, p2);printf("%d\n", a);//*p1 = 3;*p2 = 3;//可以通过*p2修改a的值printf("%d\n", a);int b = 8;p1 = &b;//p2 = &b;//不可修改p2本身的地址return 0;
}
情况3:*两边都有const。
还可以给*两边都加上const,这样指针变量就彻底变成了花瓶:
既无法通过指针修改变量的值,也无法修改指针本身的值。
#include<stdio.h>int main() {int a = 4;const int* const p = &a;//*p = 3;//不可以通过*p修改a的值int b = 8;//p = &b;//不可修改p本身的地址return 0;
}
对于这三种情况,个人给出的解释是:const会修饰后面的对象,使得这个对象具有常属性,不可被修改。
例如const在*左边时,const修饰的是这个指针类型(或修饰它指向的内容),这样就无法通过这个指针类型定义的指针修改内存,但指针本身不受约束。
例如const在*后面时,const修饰的是这个指针变量,这样指针变量无法被修改,但可以通过这个指针修改内存。
const修饰的整型变量用于定义数组
在c语言不能通过变量去定义数组,但可以神明变长数组,这和普通的变量一样。
这个例子在vs2019(MSVC编译器)无法运行,在gcc可以。
#include<stdio.h>int main() {const int N = 10;int a[N];int i;for(i=0;i<N;i++){a[i]=i;printf("%d ",a[i]);}printf("\n");int M = 10;int b[M];for(i=0;i<M;i++){a[i]=i;printf("%d ",a[i]);}return 0;
}
但如果是c++:
-
在g++编译器,变长数组和用
const修饰的常变量定义的数组可以被初始化。 -
在vs2019(MSVC编译器),用
const修饰的常变量定义的数组可以被初始化。变长数组虽然能用,但不能被初始化。
在Devcpp和使用Mingw的vscode,c语言通过gcc.exe编译成可执行程序,c++通过g++.exe编译成可执行程序。
在Visual Studio 2019或Visual Studio 2022,则是通过cl.exe与其他.exe配合。
#include<cstdio>int main() {const int N = 10;int a[N]={0};int M = 10;int b[M]={0};//这句在g++允许,在vs2019不给通过return 0;
}
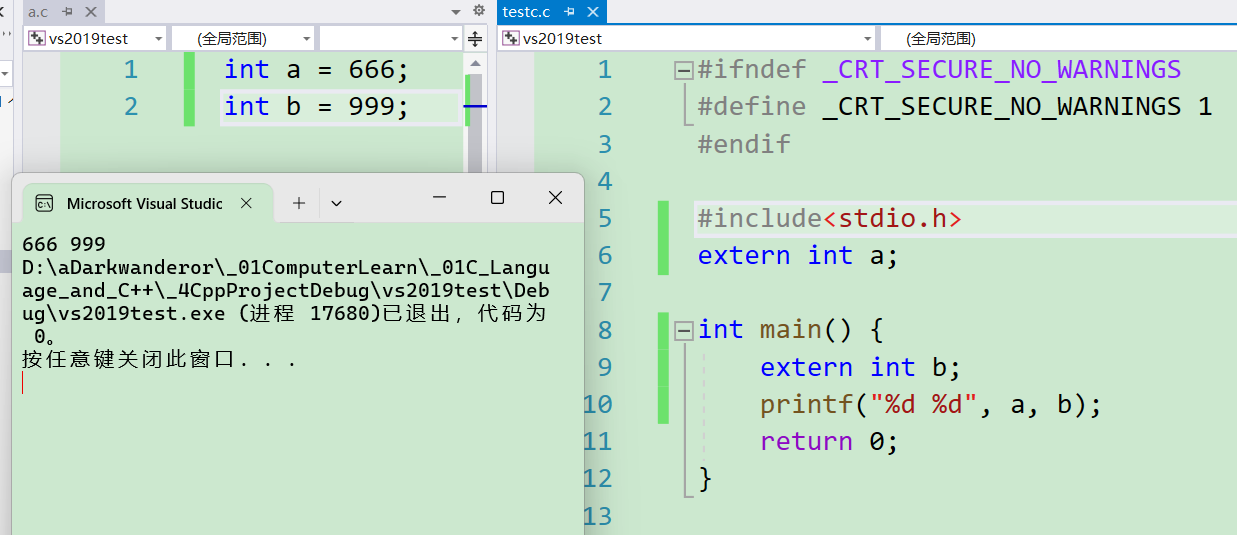
extern
外部符号声明。用法:
extern int a;
在a.c文件里定义,在b.c文件中使用,要求将两个.c编译成同一个可执行文件.exe。
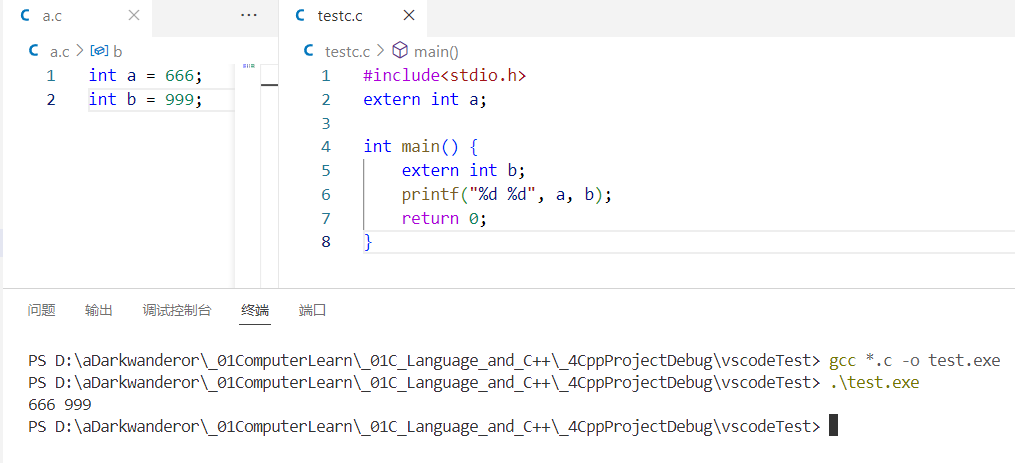
这里展示在vs2019和vscode的情况:
vs2019:
vscode:
在c++同样可以这样使用。
register
表示存储类型(auto)寄存器,用于修饰变量时,变量值会放到寄存区存储(局部变量放栈区)。
register直译寄存器。想要了解register,需要先了解一部分内存的知识。
计算机上的存储设备:硬盘、内存、高速缓存(这个不会直接用到,由OS去直接调用的一块区域,它属于硬件层面的一块区域)和寄存器。

这些存储器用金字塔表示他们的关系:
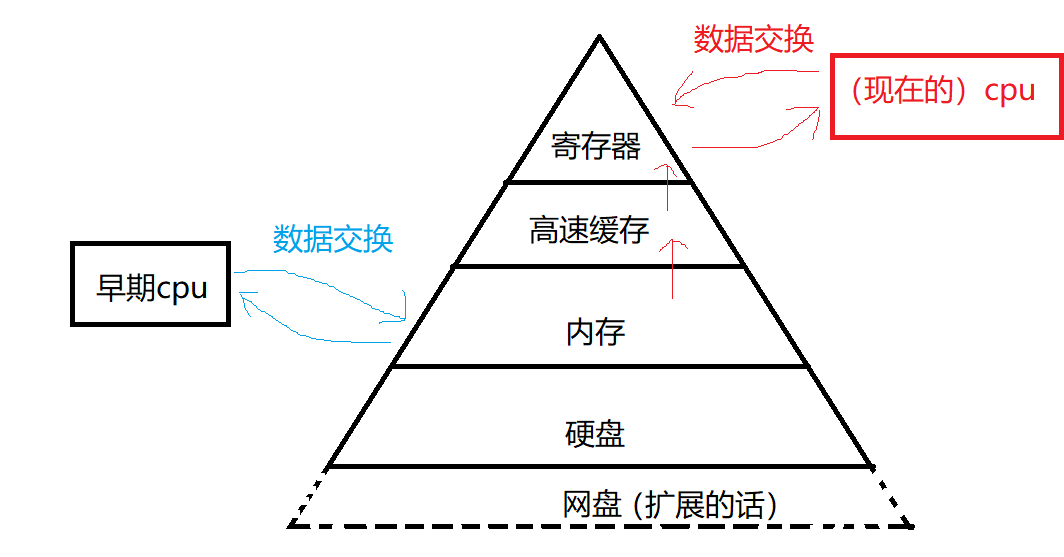
注意到在生活中比如百度网盘,注册就会送2G,几乎免费的。而硬盘明显要钱。内存更贵。
寄存器的速度(数据交换速度)最快,金字塔越往下的存储设备速度越慢(例如百度网盘限速)。寄存器速度最快,所以造价高,所以不敢在电脑上搞特别多的存储空间。
猜想,若电脑中的寄存器能存储的内存有1T,这台电脑的造价有多高?
所以一台电脑的寄存器不能太多。
最终在电脑中形成了这么一个金字塔的结构,越往上速度越快,造价越高,空间越小。
形成这种金字塔结构的原因:
数据主要由cpu处理(无论是过去还是现在),而早期cpu处理的数据的来源从内存中取,处理完后再放回内存,
若cpu的处理速度和内存的读写速度适配还好,但伴随着技术进步,cpu处理速度上升,硬件速度提升并没有多快,逐渐跟不上。于是就开发了更快的存储设备,cpu从这个新的存储设备中去交换数据,于是高速缓存出现了。
甚至更进一步,比高速缓存速度更快的寄存器也出现了。
之后,cpu直接与寄存器交互。当cpu和寄存器处理一部分数据时,高速缓存的数据往寄存器上挪,内存中的数据往高速缓存挪,这样不断地将寄存器里的数据进行替换,将高速缓存的新数据往寄存器里运,只要保证大概率都在寄存器里把数据都能找到cpu,整体的读写速度便上升。
为了从经济上节省造价,又为了更快地处理数据,才有了这种模式。
所以register可以将要处理的变量直接放寄存器,但编译器会根据变量是否在程序中大量使用来决定变量的数据是否放寄存器。
这种数据交换模式有一个局部性原理,具体参考《深入理解计算机系统》。
register的用法:
register int a=10;
static
static是静态的意思,用于赋予对象静态属性。
static修饰局部变量
static修饰局部变量改变了变量的生命周期。让静态局部变量出了作用域依然存在,到程序结束(可以理解为main函数停止使用),生命周期才结束。
在c和c++的学习期间,我们把内存大概分成几个区域(实际分的更复杂)
- 栈区:存放的是局部变量,形式参数。局部变量和形参的特点是进入作用域就建立,走出作用域就销毁。
- 堆区:动态内存分配。这个工作主要由alloc系列函数(
malloc,calloc,realloc)和free函数完成。- 静态区。存放静态变量(即
static修饰的变量)和局部变量。
static修饰局部变量的原理:将原本放在栈区的变量放在了内存的静态区,使得局部变量的生命周期发生改变。但作用域并没有改变。
用法:
#include <stdio.h>
void test()
{//普通局部变量int i = 0;i++;printf("%d ", i);
}void test2()
{//static修饰局部变量static int i = 0;i++;printf("%d ", i);
}int main()
{int i = 0;for (i = 0; i < 10; i++){test();}printf("\n");for (i = 0; i < 10; i++){test2();}return 0;
}
输出:
1 1 1 1 1 1 1 1 1 1
1 2 3 4 5 6 7 8 9 10
可以发现,经过static修饰的局部变量,尽管访问的作用域没变,但出了作用域并没有将它销毁。
static修饰全局变量
全局变量具有外部链接属性,在其他源文件内部,只要适当声明即可使用。前提是两个.c源文件都参与编译链接和通过extern关键字声明。
外部链接属性:即在外部其他源文件内能够正常使用所具有的一种属性。
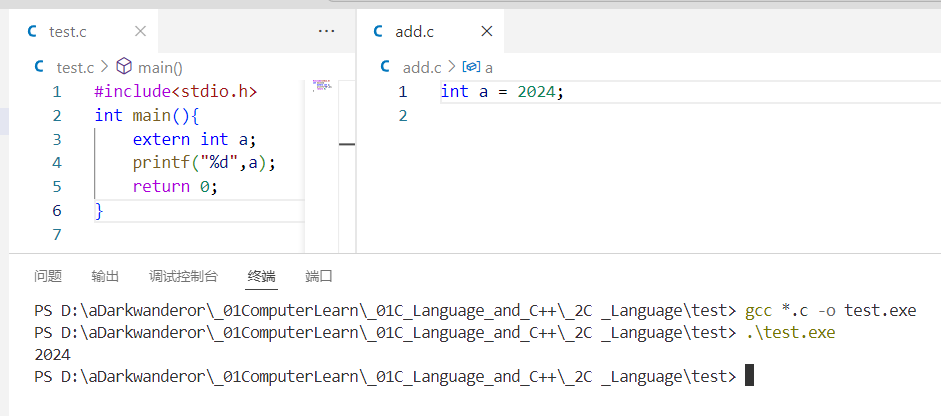
例如:add.c
int a = 2024;
test.c
#include<stdio.h>
int main(){extern int a;//可用extern调用外部的局部变量printf("%d",a);return 0;
}
只要add.c和test.c一同参与编译,test.c就能调用add.c的全局变量。效果:
一个全局变量被static修饰,使得这个全局变量只能在本源文件(即该全局变量所在的.c)内使用,不能在其他源文件内使用。
全局变量被
static修饰后,只能在自己所在的.c内部使用,全局变量的外部链接属性变成了内部链接属性,影响了全局变量的作用域(常用于不想公开数据)。
例如:
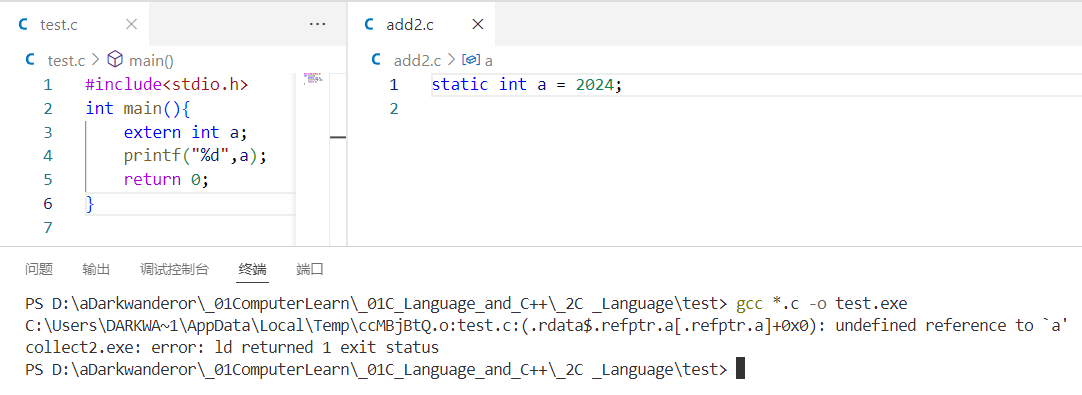
例:add2.c
static int a = 2024;
test.c
#include<stdio.h>
int main(){extern int a;//可用extern调用外部的局部变量printf("%d",a);return 0;
}
再去强行编译会被阻止。
static修饰函数
与全局变量相似。
一个函数被static修饰,使得这个函数只能在本源文件内使用,不能在其他源文件内使用。
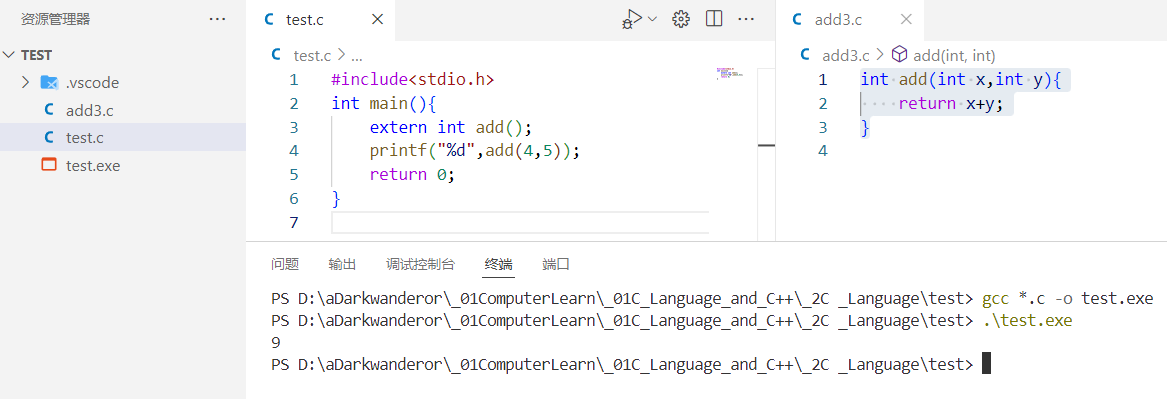
例如:add3.c
int add(int x,int y){return x+y;
}
test.c
#include<stdio.h>
int main(){extern int add();printf("%d",add(4,5));return 0;
}
和未被修饰的全局变量一样的效果:
反例:
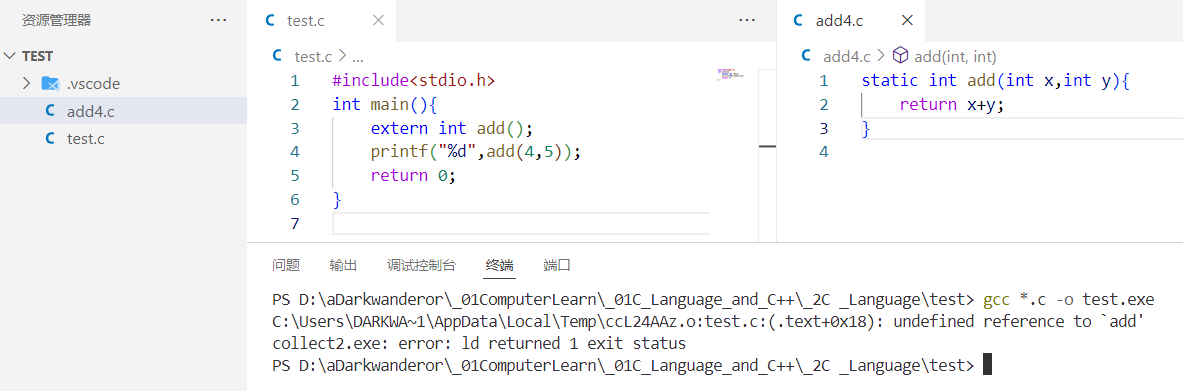
例如:add4.c
static int add(int x,int y){return x+y;
}
test.c
#include<stdio.h>
int main(){extern int add();printf("%d",add(4,5));return 0;
}
volatile
volatile 限定符告知计算机,代理(而不是变量所在的程序)可以改变该变量的值。通常,它被用于硬件地址以及在其他程序或同时运行的线程中共享数据。
几乎没用到过,因此只是随便提一下概念,以后有机会再补充。
有自己特殊作用的关键字
return
用于函数中做函数的返回。
带返回类型的函数可以在return和;之间带表达式。例如:
//返回字面常量
return 0;//返回常量字符串,在c++,若类型为自定义类型,还会尝试调用专门的构造函数生成
//新的对象或自定义类型变量
return "abc";//返回指定类型的变量。尽量和函数的类型保持一致。
return a;//返回表达式的值
return a+b;//将其他函数的返回值返回
return f();
不带返回类型的函数直接用return;终止函数运行。
最常用的就是main函数的返回值。例如这个案例:
void f(){int a = 10;return;
}int main(){f();return 0;
}
sizeof
用于计算类型的大小(变量也用作类型计算)。严格来说sizeof并不是关键字,而是操作符。
它的使用方式:
- 通用:
sizeof(对象)即可返回对象占用的内存大小,返回值类型是size_t,即无符号整数,大小为4到8个字节,取决于编译器。 sizeof 对象,仅限于变量或表达式。
例如:
#include<stdio.h>int main() {int a = -13, c = 0;long long b=0; double* p = (double*)&b;printf("%u\n", sizeof(size_t));printf("%u\n", sizeof(a));printf("%u\n", sizeof c);printf("%u\n", sizeof p);return 0;
}
typedef
typedef 顾名思义是类型定义,这里应该理解为类型重命名(将一个复杂的类型重新取一个简单的名字)。
比如:
//将unsigned int 重命名为uint_32, 所以uint_32也是一个类型名
typedef unsigned int uint_32;
int main()
{//观察num1和num2,这两个变量的类型是一样的unsigned int num1 = 0;uint_32 num2 = 0;return 0;
}
typedef相比于#define的完全替换,能更好地适配复杂的类型。
例如同样是int*:
#define IP int*
typedef int* IP2;int main(){IP p1,p2;IP2 p3,p4;return 0;
}
则p2不是指针变量,p1、p3、p4都是。原因是#define的原理是在编译前将符号替换:
typedef int* IP2;int main(){int* p1,p2;IP2 p3,p4;return 0;
}
typedef还可用于更复杂的类型。例如(匿名)结构体或函数指针:
typedef struct{int a;int b;
}A;
typedef struct B{int a;int b;
}B;//给函数指针类型取别名
typedef void(*Pf)();//相当于 typedef void(*)() pf; 但编译器不认后面这种int main(){A a;B b;Pf f1,f2;return 0;
}