字符和编码(python)
-
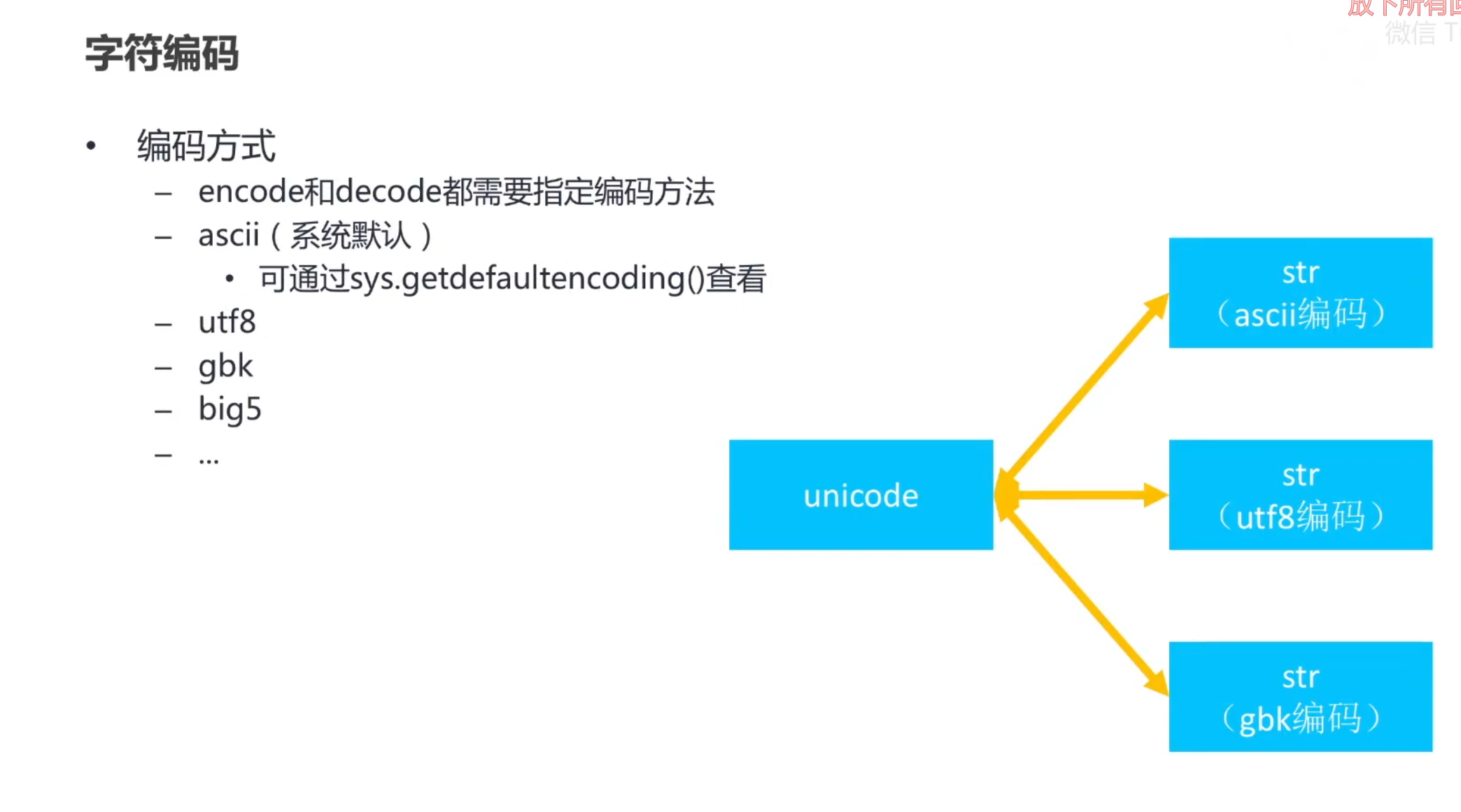
- 位数:英文字符使用 1 个字节表示,中文字符通常使用 3 个字节。
- 示例:汉字 “汉” 的 UTF-8 编码是
\xE6\xB1\x89。 - 优点:兼容 ASCII,广泛用于网络传输和文件存储。
Python 中的字符串类型
在 Python 中,字符串的处理与字符编码密切相关。以下是一些重要的字符串类型:
str:
-
- 在 Python 3 中,
str是 Unicode 字符串,默认支持所有语言字符。 - 示例:
s = '汉字'。
- 在 Python 3 中,
bytes:
-
- 表示字节序列,通常用于处理二进制数据。
- 字节对象可以通过字节前缀
b创建,例如:b'汉字'。
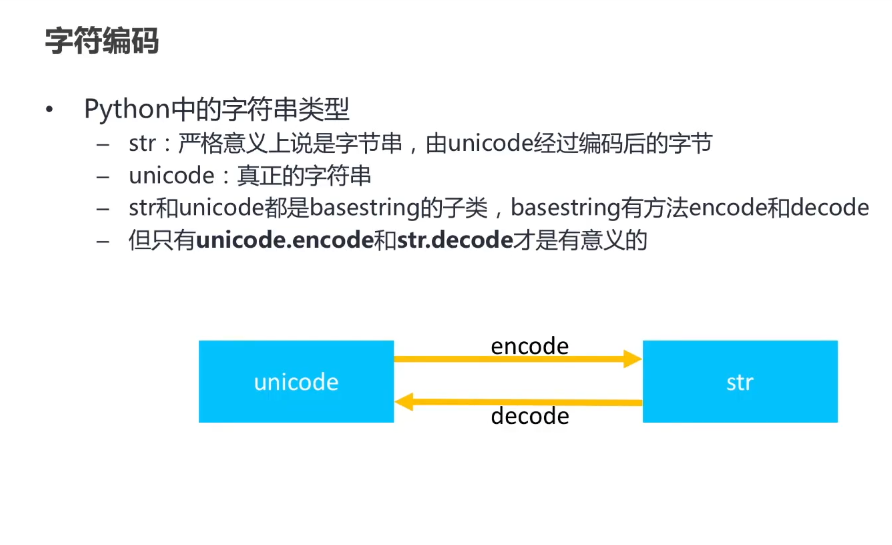
unicode和basestring:
-
- 在 Python 2 中,
unicode是 Unicode 字符串,而basestring是str和unicode的基类。 - 在 Python 3 中,这两个类型都被移除,
str就是 Unicode 字符串。
- 在 Python 2 中,
编码与解码操作
- 编码(
encode):
-
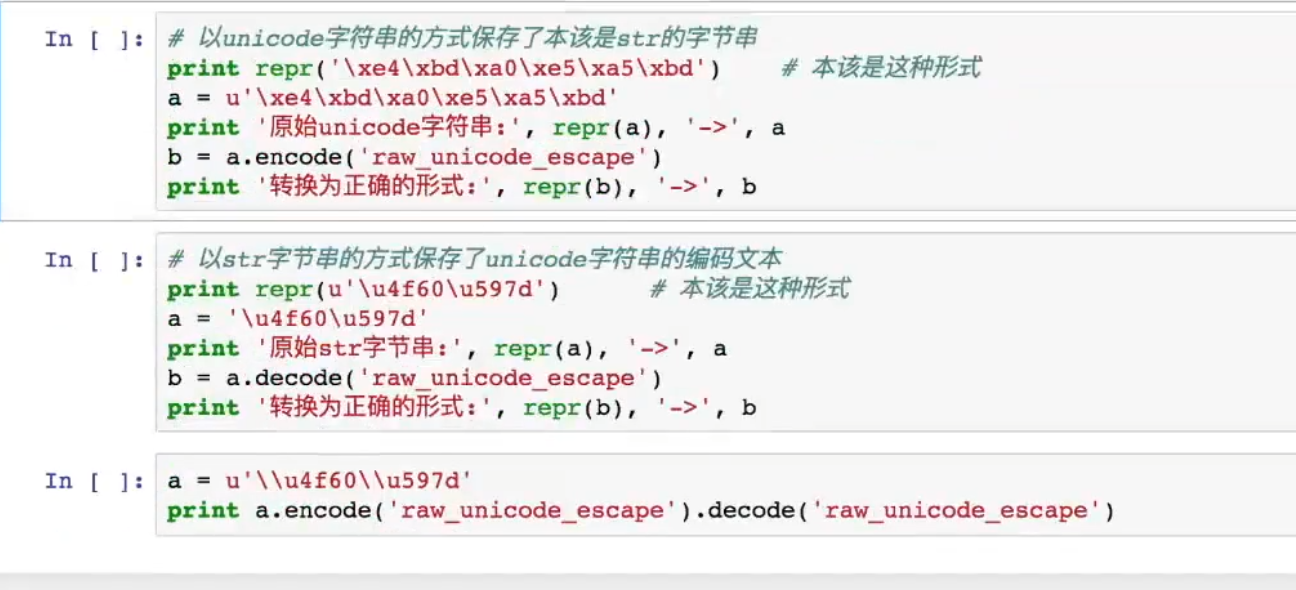
- 将 Unicode 字符串转换为特定编码格式的字节串。
- 示例:
u = '汉'
s = u.encode('UTF-8') # 编码为 UTF-8 格式的字节串- 解码(
decode):
-
- 将特定编码格式的字节串转换回 Unicode 字符串。
- 示例:
s = b'\xe6\xb1\x89' # 已经是字节类型
u2 = s.decode('UTF-8') # 解码为 Unicode 字符串字符编码注意事项
- 文件编码声明:
-
- 在 Python 2 中,默认编码是 ASCII,如果源文件包含非 ASCII 字符,需在文件开头声明编码:
# -*- coding: utf-8 -*--
- 在 Python 3 中,默认编码是 UTF-8,通常可以直接处理中文字符。
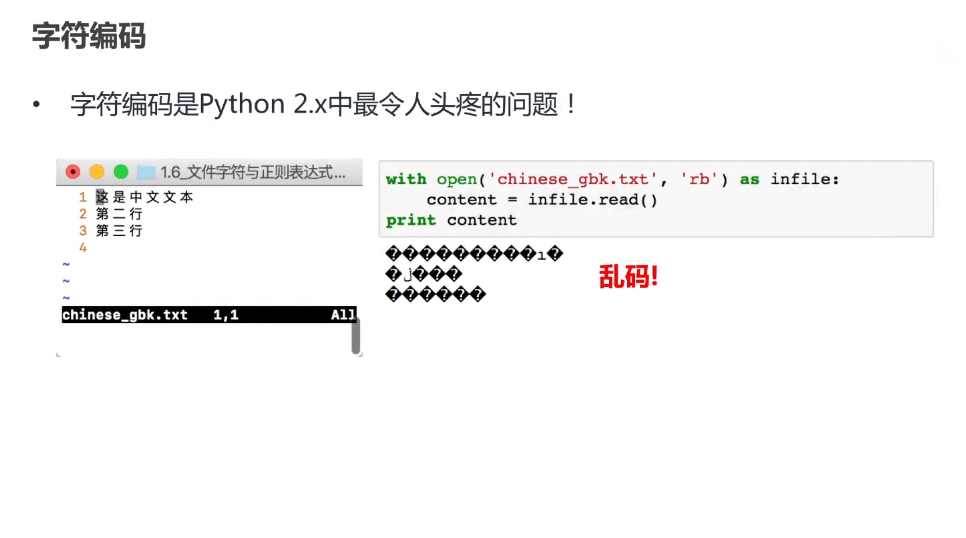
- 避免乱码:
-
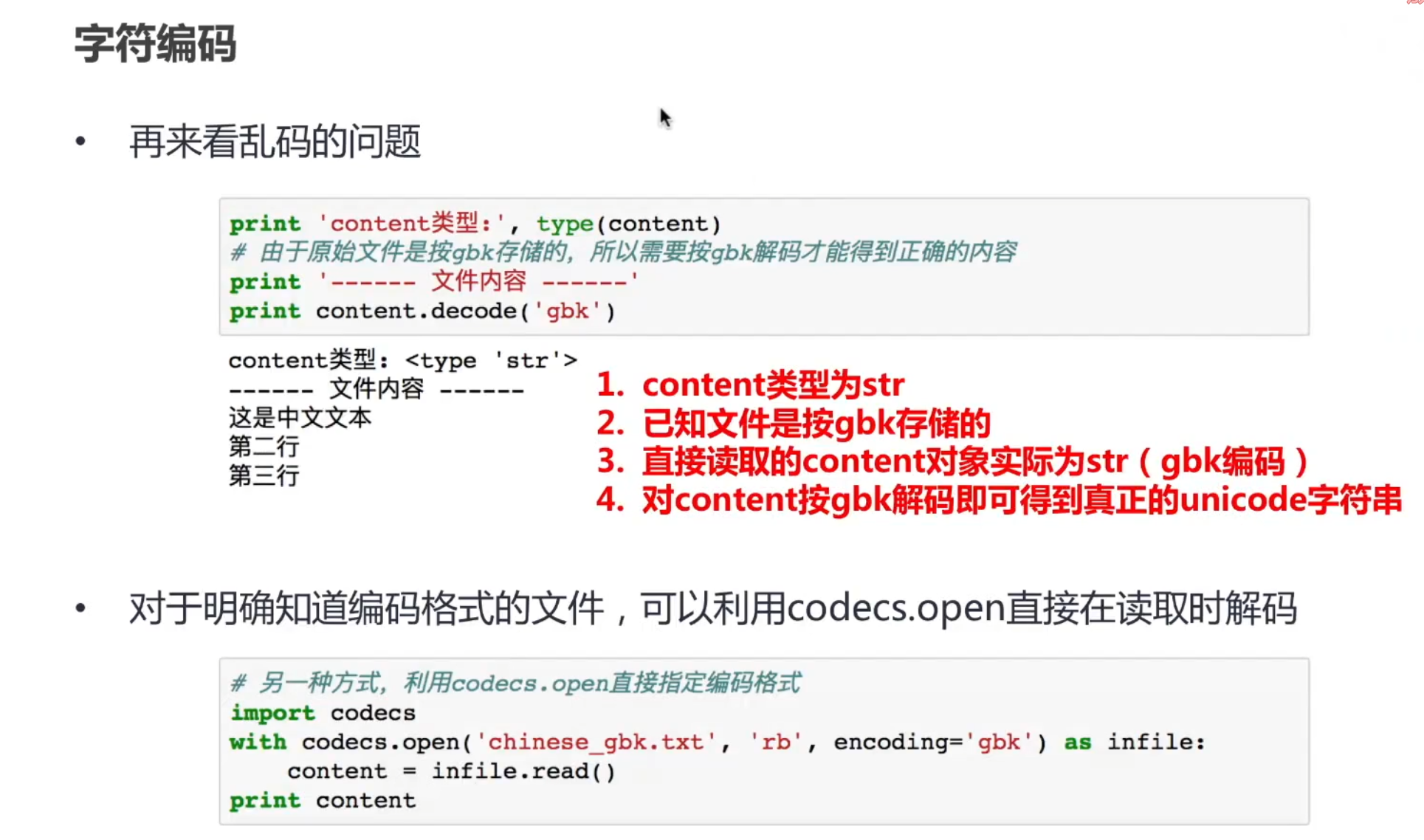
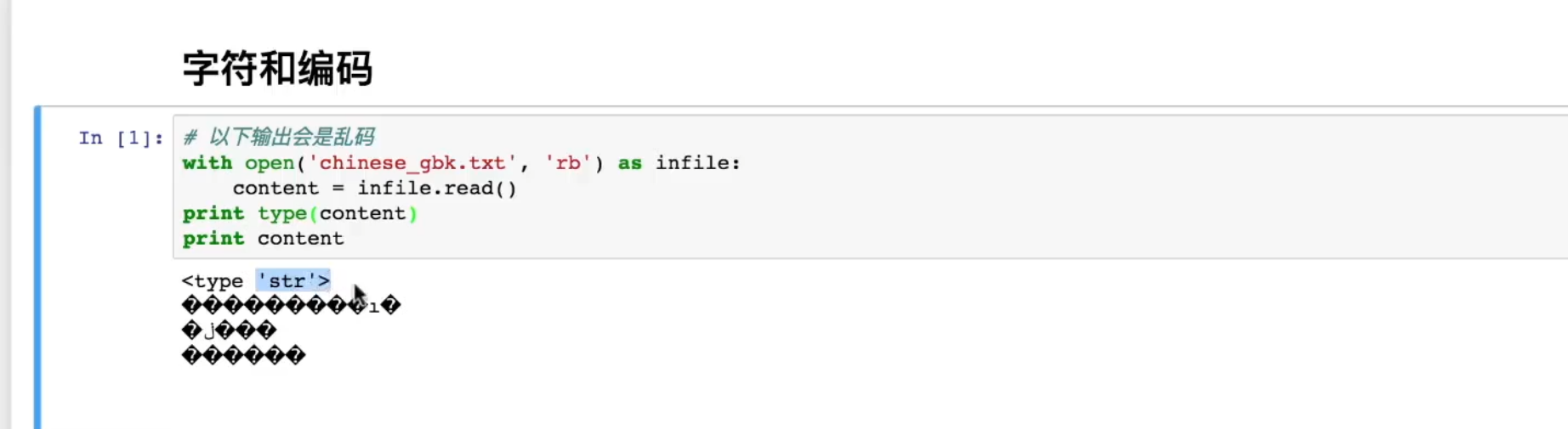
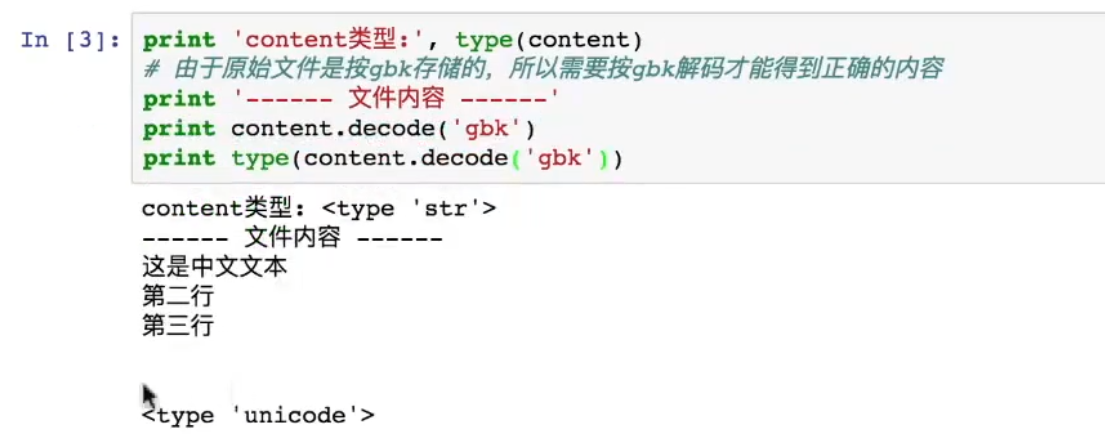
- 编码和解码时应确保字符串和字节序列之间的编码类型一致。若存储时使用 UTF-8,读取时也必须用 UTF-8 解码,否则会出现乱码。
- 示例:如果文件用 GBK 编码,而用 UTF-8 解码,将导致无法正确读取文件内容。
在 Python 2 和 Python 3 中,字符与编码的处理有许多共同点,但也存在显著的区别。以下内容将详细介绍这两者在字符编码方面的共同性与区别。
共同性
- 字符编码的基本概念:
-
- 在两者中,字符编码的基本概念保持一致:字符(如字母、汉字等)映射到二进制数据,以便计算机可以存储和处理文本。
- Unicode 的重要性:
-
- 两个版本都支持 Unicode,使得可以处理多种语言的字符。Unicode 是一个统一的字符编码标准,旨在为所有字符提供唯一的编码。
- 编码与解码操作:
-
- 两者都支持编码(
encode)和解码(decode)操作,用于在字符串(Unicode)和字节串之间转换。
- 两者都支持编码(
Python 2 中的字符与编码
- 字符串类型:
-
str:在 Python 2 中,str类型是字节串,表示经过编码的字节序列。它的默认编码是 ASCII。
s = '汉字' # 这是一个字节串,默认编码为 ASCII,但包含非 ASCII 字符时可能会导致错误-
unicode:在 Python 2 中,unicode是真正的 Unicode 字符串,使用u前缀表示。
u = u'汉字' # 这是一个 Unicode 字符串-
basestring:basestring是str和unicode的基类,通常用在判断字符串类型时。
- 编码与解码示例:
-
- 编码:
u = u'汉'
s = u.encode('UTF-8') # 编码为 UTF-8 格式的字节串-
- 解码:
s = '\xe6\xb1\x89' # 这是一个字节串
u2 = s.decode('UTF-8') # 解码为 Unicode 字符串- 文件编码:
-
- 在 Python 2 中,如果源文件包含非 ASCII 字符,必须声明文件编码:
# -*- coding: utf-8 -*-Python 3 中的字符与编码
- 字符串类型:
-
str:在 Python 3 中,str是 Unicode 字符串,默认支持所有语言字符,支持多种语言的编码和显示。
s = '汉字' # 这是一个 Unicode 字符串-
bytes:新增的bytes类型用于表示字节序列,通常用于处理二进制数据。
b = b'汉字' # 字节串,用 b 前缀表示- 编码与解码示例:
-
- 编码:
s = '汉'
b = s.encode('UTF-8') # 编码为 UTF-8 格式的字节串-
- 解码:
b = b'\xe6\xb1\x89' # 这是一个字节串
s2 = b.decode('UTF-8') # 解码为 Unicode 字符串- 文件编码:
-
- 在 Python 3 中,默认的文件编码是 UTF-8,支持中文字符,不需要特别声明,如果源文件是 UTF-8 编码。
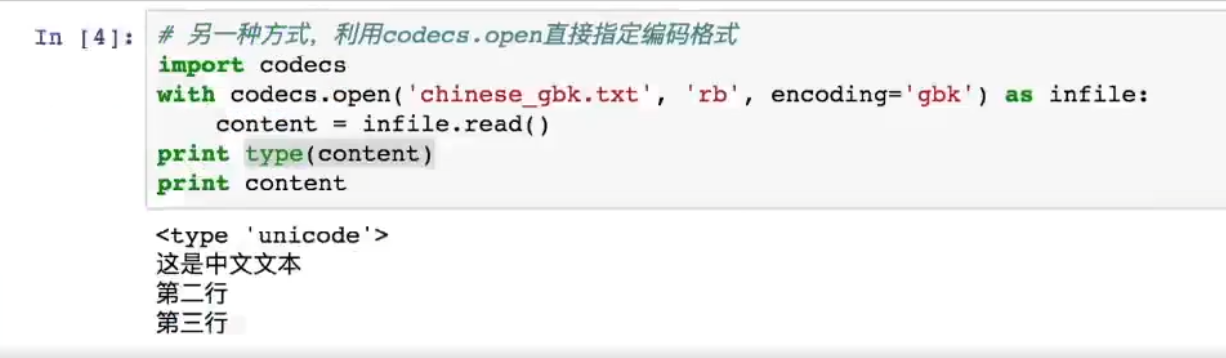
- 但如果文件是其他编码格式,还是需要在打开文件时指定编码:
with open('file.txt', 'r', encoding='utf-8') as f:content = f.read()主要区别总结
- 字符串类型:
-
- Python 2 中,
str是字节串,unicode是Unicode字符串。 - Python 3 中,
str是 Unicode 字符串,bytes是字节串。
- Python 2 中,
- 默认编码:
-
- Python 2 的默认编码是 ASCII。
- Python 3 的默认编码是 UTF-8,适合处理较多的非 ASCII 字符。
- 编码和解码方法的调用:
-
- 在 Python 2 中,
unicode对象通过encode()方法转换为str字节串,而str字节串通过decode()转换为unicode字符串。 - 在 Python 3 中,
str对象通过encode()转换为bytes字节串,bytes对象通过decode()转换为str字符串。
- 在 Python 2 中,
- 文件处理:
-
- Python 2 中需要在文件开头声明编码,以便正确解析非 ASCII 字符。
- Python 3 中默认支持 UTF-8 编码,但在处理特定编码文件时仍需指定编码。
结论
理解 Python 2 和 Python 3 在字符与编码方面的共同性和区别,对于使用这两种版本的开发者来说非常重要。虽然 Python 3 在字符串处理上更加直观和简便,但对于老旧项目和不同版本的兼容性问题,了解 Python 2 的处理方式仍然是必要的。如果您有更多具体的问题或者需要更深入的解释,请随时提问!