LearningFlow:大语言模型城市驾驶的自动化策略学习工作流程
《LearningFlow: Automated Policy Learning Workflow for Urban Driving with Large Language Models》2025年1月发表,来自香港科技大学广州分校的论文。
强化学习(RL)的最新进展表明了自动驾驶的巨大潜力。尽管有这一前景,但奖励函数的手动设计和复杂环境中的低样本效率等挑战继续阻碍着安全有效驾驶政策的制定。为了解决这些问题,我们引入了LearningFlow,这是一种专为城市驾驶量身定制的创新自动化政策学习工作流程。该框架在整个RL训练过程中利用了多个大型语言模型(LLM)代理的协作。LearningFlow包括课程序列生成过程和奖励生成过程,它们协同工作,通过生成量身定制的培训课程和奖励函数来指导强化学习政策。特别是,每个过程都由一个分析代理支持,该代理评估训练进度并向生成代理提供关键见解。通过这些LLM代理的协作努力,LearningFlow自动化了一系列复杂驾驶任务中的策略学习,大大减少了对手动奖励功能设计的依赖,同时提高了样本效率。在高保真CARLA模拟器中进行了全面的实验,并与其他现有方法进行了比较,以证明我们提出的方法的有效性。结果表明,LearningFlow在生成奖励和课程方面表现出色。它还实现了卓越的性能和跨各种驾驶任务的鲁棒泛化,以及对不同RL算法的值得称赞的适应性。
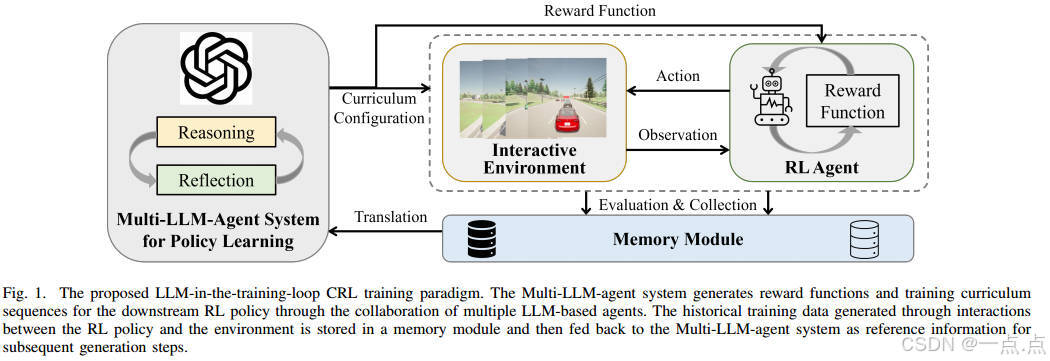
1. 研究背景与问题
城市自动驾驶面临复杂场景(如多车道超车、匝道汇入等),需处理动态交通密度和周围车辆(SV)的多样驾驶行为。传统强化学习(RL)存在两大挑战:
-
奖励函数设计困难:手动设计耗时且主观,难以动态调整。
-
样本效率低:复杂环境中随机探索效率低,导致收敛缓慢或不稳定。
2. 创新方法:LearningFlow框架
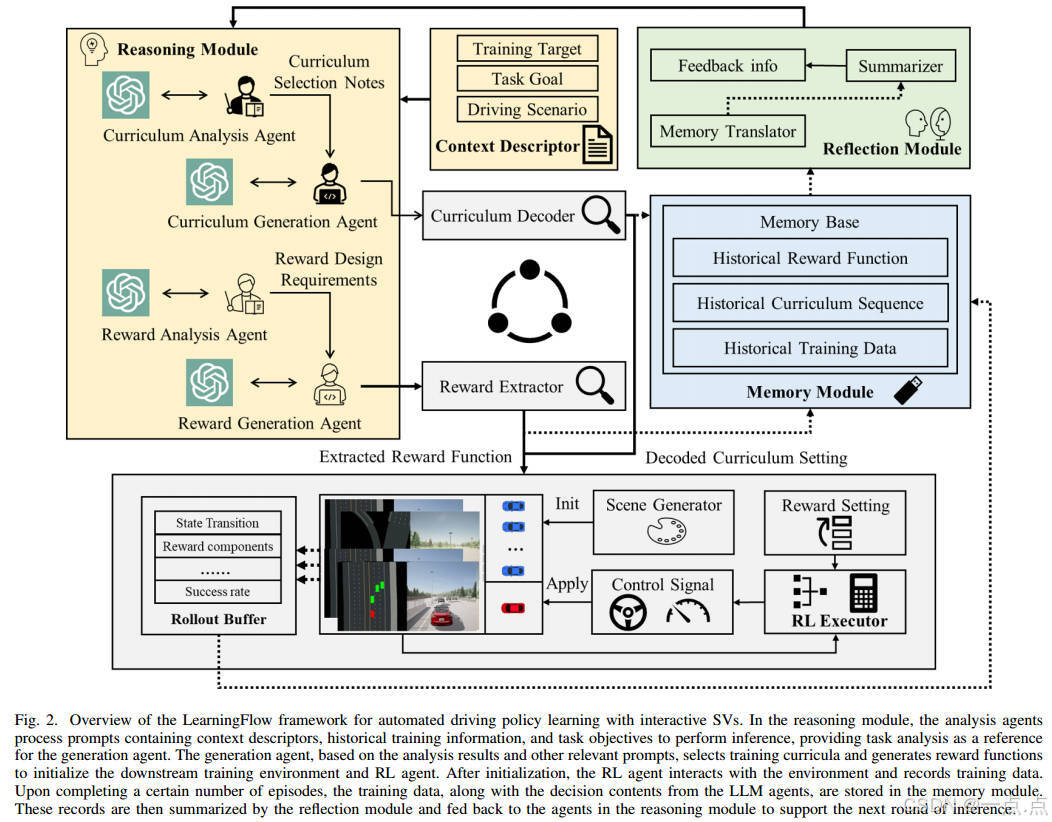
提出一种基于多LLM代理协作的自动化策略学习框架,核心目标:
-
自动化生成训练课程:通过分层课程集(交通密度和SV运动模式)动态调整任务难度。
-
动态优化奖励函数:结合LLM的生成能力,迭代设计符合任务需求的奖励函数。
框架核心模块:
-
记忆模块:存储历史训练数据(奖励、课程、性能指标),支持闭环反馈。
-
课程生成模块:
-
分析代理:评估当前训练进度和课程需求。
-
生成代理:基于分析结果生成课程序列,采用ε-greedy策略平衡探索与利用。
-
-
奖励生成模块:
-
分析代理:解析任务目标和可访问变量。
-
生成代理:生成代码形式的奖励函数,支持在线调整。
-
-
下游RL执行器:使用PPO算法,结合模型预测控制(MPC)生成控制指令。
3. 实验与结果
-
环境:CARLA模拟器,验证场景为匝道汇入和多车道超车。
-
基线对比:包括Vanilla PPO、AutoReward等,LearningFlow在成功率、泛化性、样本效率上均表现最优(表I)。
-
关键发现:
-
分析代理的重要性:消融实验显示,移除分析代理会导致奖励函数设计错误(图5)。

-
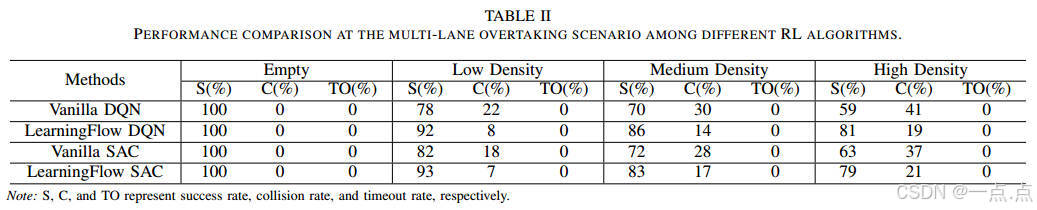
多RL算法适配性:支持PPO、DQN、SAC,验证框架的通用性(表II)。
-
实际驾驶演示:成功完成复杂交互任务(图6)。
-

4. 贡献与意义
-
技术贡献:
-
首个结合LLM与课程强化学习(CRL)的自动化策略学习框架。
-
提出多LLM代理协作机制(分析-生成-反射),提升生成内容的质量与稳定性。
-
-
实际价值:
-
减少对人工奖励设计的依赖,提升样本效率与策略性能。
-
在动态交通场景中展示优异的交互感知能力和泛化性。
-
5. 局限与未来方向
-
局限性:
-
对LLM生成结果的可靠性依赖较高,可能需人工干预纠错。
-
实时性挑战:LLM推理延迟可能影响实际部署。
-
-
未来工作:
-
引入扩散模型增强多模态决策能力。
-
优化LLM提示工程,提升生成效率与准确性。
-
总结
LearningFlow通过LLM与强化学习的深度融合,为自动驾驶策略学习提供了自动化、高效的解决方案。其多代理协作机制和闭环反馈设计显著提升了复杂场景下的策略性能,为未来智能驾驶系统的开发提供了新思路。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!