大模型的第一天学习-LM studio的安装和本地大模型搭建
大模型的第一天学习-LM studio的安装和本地大模型搭建
- 一、下载安装,加载模型
- 二、使用本地服务器
- 三、模型参数的学习
- 四、一些必要的知识
一、下载安装,加载模型
- 直接在官网下载lm studio
- 将下载模型加载进来。可以通过hugging face下载模型,也可以直接拷贝。或者直接搜索“发现”
二、使用本地服务器
因为我对python和post链接熟悉一点,就打算使用python去链接lm studio来使用大模型,来实现本地化。
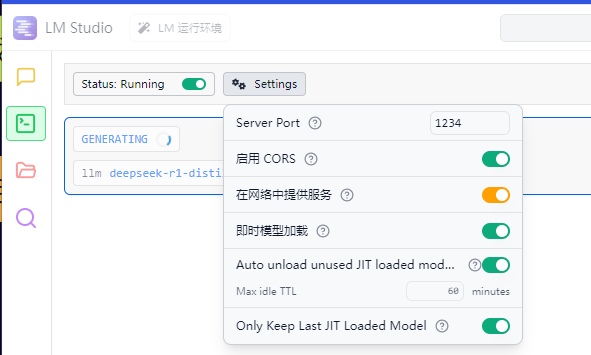
- 在“开发者”启动允许本地链接,并得到端口数据
- 在cmd钟输入ipconfig,得到ipv4地址
- 得到链接地址:http://localhost:1234/v1/chat/completions
下面是代码,要填入正确的ipv4和端口。( “top_k”: 10,“temperature”:0.9,。。。“max_tokens”: 30000,这些连七八糟的模型参数现在可以不加,不影响使用,以后慢慢来。。。)
import requests
url = "http://1.1.1.11:1234/v1/chat/completions"
data = {"model":"deepseek-r1-distill-llama-8b","messages": [{"role": "system", "content": "你是一个专业的助手。"},{"role": "user", "content": f"""
对于email信息,可以按以下分类方法进行分类:类型:<会议通知><信息知会><待办事宜><问询>紧急程度:<紧急><优先><普通>
分级方法:
如果包括手机等个人信息,为4级,否则为1级。
以下是两份email,请进行分类分级:
张三:
昨天下午,2378号项目出现现场故障,针对此问题,我们将于今天下午两点在3号会议室开会讨论请按时参加。有关项目的信息,可以与李四联系,联系电话13912345678。
"""}]
}try:# 发送 POST 请求(无数据)response = requests.post(url,json=data)# 打印响应状态码和内容print("Status Code:", response.status_code)print("Response Body:", response.text)except requests.exceptions.ConnectionError as e:print("连接失败,请确认:")print("- 目标服务器是否运行中")print("- 端口是否正确")print("- IP 地址是否正确")
三、模型参数的学习
- top_k (候选单词的个数)只有排名前k的词会被考虑
- top_p (概率)从模型的概率分布中抽样时,只会考虑累积概率达到top_p的那些词
- temperature 控制生成文本的随机性
- max_tokens 设置生成文本的最大长度
- frequency_penalty 正值减少高频词的出现
- presence_penalty 正值会惩罚重复出现的话题,鼓励探索新的主题
四、一些必要的知识
自回归生成:大语言模型是通过重复生成token序列(sequence)中的下一个token来运作的。每次模型想要生成另一个token时,会重新阅读整个token序列并预测接下来应该出现的token。