ICCV2021 | 重新思考并改进视觉 Transformer 的相对位置编码
Rethinking and Improving Relative Position Encoding for Vision Transformer
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 方法-Method
- 先前的相对位置编码方法-Previous Relative Position Encoding Methods
- 提出的相对位置编码方法-Proposed Relative Position Encoding Methods
- 实验-Experiments
- 相关工作-Related Work
- 结论与评述-Conclusions and Remarks

论文链接
GitHub链接
本文 “Rethinking and Improving Relative Position Encoding for Vision Transformer” 聚焦于视觉 Transformer 中的相对位置编码(RPE),回顾了现有方法并分析其优缺点,提出了四种专为 2D 图像设计的 iRPE 方法,包括偏置和上下文两种模式及不同的 2D 相对位置计算方式,还给出了高效实现。实验表明 iRPE 方法能有效提升 DeiT 和 DETR 性能,且分析得出 RPE 在不同任务中的特性等结论。
摘要-Abstract
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT [21] and DETR [1] obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding.
相对位置编码(RPE)对于Transformer捕捉输入token的序列顺序至关重要。其在自然语言处理中的普遍有效性已得到证实。然而,在计算机视觉领域,它的效果尚未得到充分研究,甚至存在争议,例如,相对位置编码是否能与绝对位置编码发挥同样的作用?为了阐明这一点,我们首先回顾现有的相对位置编码方法,并分析它们在视觉Transformer中的优缺点。然后,我们提出了专门针对二维图像的新型相对位置编码方法,称为图像相对位置编码(iRPE)。我们的方法考虑了方向相对距离建模,以及自注意力机制中查询与相对位置嵌入之间的相互作用。所提出的iRPE方法简单且轻量,可轻松插入Transformer模块中。实验表明,仅凭借这些编码方法,DeiT和DETR在ImageNet和COCO数据集上,相较于其原始版本,分别获得了高达1.5%(top-1准确率)和1.3%(平均精度均值,mAP)的稳定提升,且无需调整学习率和权重衰减等额外超参数。我们的消融实验和分析也得出了一些有趣的发现,其中部分结果与以往认知相悖。
引言-Introduction
这部分主要阐述了Transformer在计算机视觉领域的重要性,引出位置编码的关键作用,进而聚焦相对位置编码(RPE)在计算机视觉中的研究现状及问题,最终说明研究工作的主要内容和贡献,具体如下:
- Transformer与位置编码:Transformer因在捕捉长距离依赖方面的出色表现,在计算机视觉领域备受关注。但其核心的自注意力机制无法捕捉输入token的顺序,因此位置编码对Transformer至关重要。位置编码主要有绝对位置编码和相对位置编码两种方式。
- RPE在计算机视觉中的争议:RPE在自然语言处理中已被证明有效,但在计算机视觉中的效果尚不明确。不同研究得出了相互矛盾的结论,有的研究发现相对位置编码相比绝对位置编码没有增益,有的则认为相对位置编码能带来明显提升,还有研究称相对位置编码无法与绝对位置编码相媲美。
- 研究动机与问题:现有关于RPE在视觉Transformer中有效性的研究结论不一致,且原始RPE是针对1D词序列提出的,对于2D图像或视频序列,将其直接从1D扩展到2D是否合适,以及方向信息在视觉任务中是否重要,这些问题都有待研究。
- 研究内容与贡献:重新思考和改进视觉Transformer中RPE的使用,提出专门针对2D图像的iRPE方法。具体贡献包括分析RPE的关键因素,为新方法设计提供指导;引入高效实现方式,降低计算成本;提出四种iRPE方法,实验证明其能有效提升DeiT和DETR模型性能;解答了之前关于RPE的争议性问题。
相关工作-Related Work
这部分内容主要介绍了Transformer中自注意力机制和位置编码的相关背景知识,为后文理解相对位置编码及改进方法做铺垫,具体如下:
- 自注意力机制:自注意力是Transformer的核心组件,它将输入序列中的查询与一组键值对映射为输出。对于输入序列 x = ( x 1 , . . . , x n ) x=(x_{1}, ..., x_{n}) x=(x1,...,xn),自注意力计算输出序列 z = ( z 1 , . . . , z n ) z=(z_{1}, ..., z_{n}) z=(z1,...,zn),其中每个输出元素 z i z_{i} zi 是输入元素的加权和,权重系数 α i j \alpha_{ij} αij 通过对 e i j e_{ij} eij 进行softmax计算得到,而 e i j e_{ij} eij 使用缩放点积注意力计算。多头自注意力(MHSA)则是并行运行多次自注意力,将多个头的输出拼接并线性变换到期望维度。
- 位置编码
- 绝对位置编码:由于Transformer没有循环和卷积结构,为让模型利用序列顺序信息,需注入位置信息。原始自注意力采用绝对位置编码,将绝对位置编码 p = ( p 1 , . . . , p n ) p=(p_{1}, ..., p_{n}) p=(p1,...,pn) 加到输入toekn嵌入 x x x 上,即 x i = x i + p i x_{i}=x_{i}+p_{i} xi=xi+pi,绝对位置编码有正弦余弦函数固定编码和可学习编码等方式。
- 相对位置编码:除绝对位置外,相对位置编码考虑输入元素间的成对关系。这种编码方式将输入元素 x i x_{i} xi 和 x j x_{j} xj 之间的相对位置编码为向量 p i j V p_{ij}^{V} pijV、 p i j Q p_{ij}^{Q} pijQ、 p i j K p_{ij}^{K} pijK,并嵌入到自注意力模块中,重新构建了计算输出 z i z_{i} zi 和 e i j e_{ij} eij 的公式,且相对位置编码在不同注意力头之间可以共享或不共享。
方法-Method
先前的相对位置编码方法-Previous Relative Position Encoding Methods
该部分回顾并分析了以往的相对位置编码方法,主要包括Shaw’s RPE、Transformer-XL的RPE、Huang’s RPE、SASA的RPE和Axial-Deeplab的RPE,具体内容如下:
- Shaw’s RPE:Shaw等人将输入token建模为有向完全连接图,用可学习向量 p i j p_{ij} pij 表示任意两个位置 i i i 和 j j j 之间的相对位置。考虑到精确相对位置信息在一定距离外作用不大,引入clip函数减少参数数量。在计算 z i z_{i} zi 和 e i j e_{ij} eij 时,将相对位置编码融入其中, p V p^{V} pV 和 p K p^{K} pK 是相对位置编码在值和键上的可训练权重, k k k 为最大相对距离。
- Transformer-XL的RPE:Dai等人在查询中引入额外的偏差项,使用正弦函数形式进行相对位置编码。通过公式 e i j e_{ij} eij 的计算,利用正弦编码向量 s s s 提供相对位置的先验信息, W R W^{R} WR 为可训练矩阵,将 s i − j s_{i - j} si−j 投影为基于位置的键向量。
- Huang’s RPE:Huang等人提出的方法同时考虑查询、键和相对位置之间的相互作用。在计算 e i j e_{ij} eij 的公式中, p i j p_{ij} pij 为查询和键共享的相对位置编码,通过这种方式对相对位置进行编码。
- SASA的RPE:上述三种方法主要针对语言建模中的1D词序列,Ramachandran等人提出适用于2D图像的编码方法。将2D相对编码分解为水平和垂直方向,分别用1D编码进行建模,在计算 e i j e_{ij} eij 时,对键进行相对位置编码,通过连接水平和垂直方向的编码形成最终的相对编码,可减少可学习参数数量和计算成本,但该编码仅应用于键。
- Axial-Deeplab的RPE:Wang等人引入位置敏感方法,在自注意力中添加依赖于查询、键和值(qkv)的位置偏差,应用于轴向注意力,沿高度轴和宽度轴顺序传播信息。不过,当相对距离大于阈值时,编码设为零。研究发现长距离相对位置信息有用,若结合分段函数,该方法在建模长距离依赖时可进一步提升效率。
提出的相对位置编码方法-Proposed Relative Position Encoding Methods
该部分主要提出了针对视觉Transformer的新型相对位置编码方法(iRPE),涵盖引入新编码模式、设计新映射函数和计算方法,以及给出高效实现方案等内容,具体如下:
- Bias模式和Contextual模式:以往的相对位置编码方法都依赖于输入嵌入,这引发了编码是否能独立于输入的疑问。为研究该问题,引入了bias模式和contextual模式。bias模式独立于输入嵌入,而contextual模式考虑与查询、键或值的交互。统一公式为 e i j = ( x i W Q ) ( x j W K ) T + b i j d z e_{ij}=\frac{(x_{i}W^{Q})(x_{j}W^{K})^{T}+b_{ij}}{\sqrt{d_{z}}} eij=dz(xiWQ)(xjWK)T+bij。在bias模式中, b i j = r i j b_{ij}=r_{ij} bij=rij, r i j r_{ij} rij是可学习的标量;在contextual模式中, b i j = ( x i W Q ) r i j T b_{ij}=(x_{i}W^{Q})r_{ij}^{T} bij=(xiWQ)rijT , r i j r_{ij} rij是可训练向量,且有多种变体,还可应用于值嵌入。
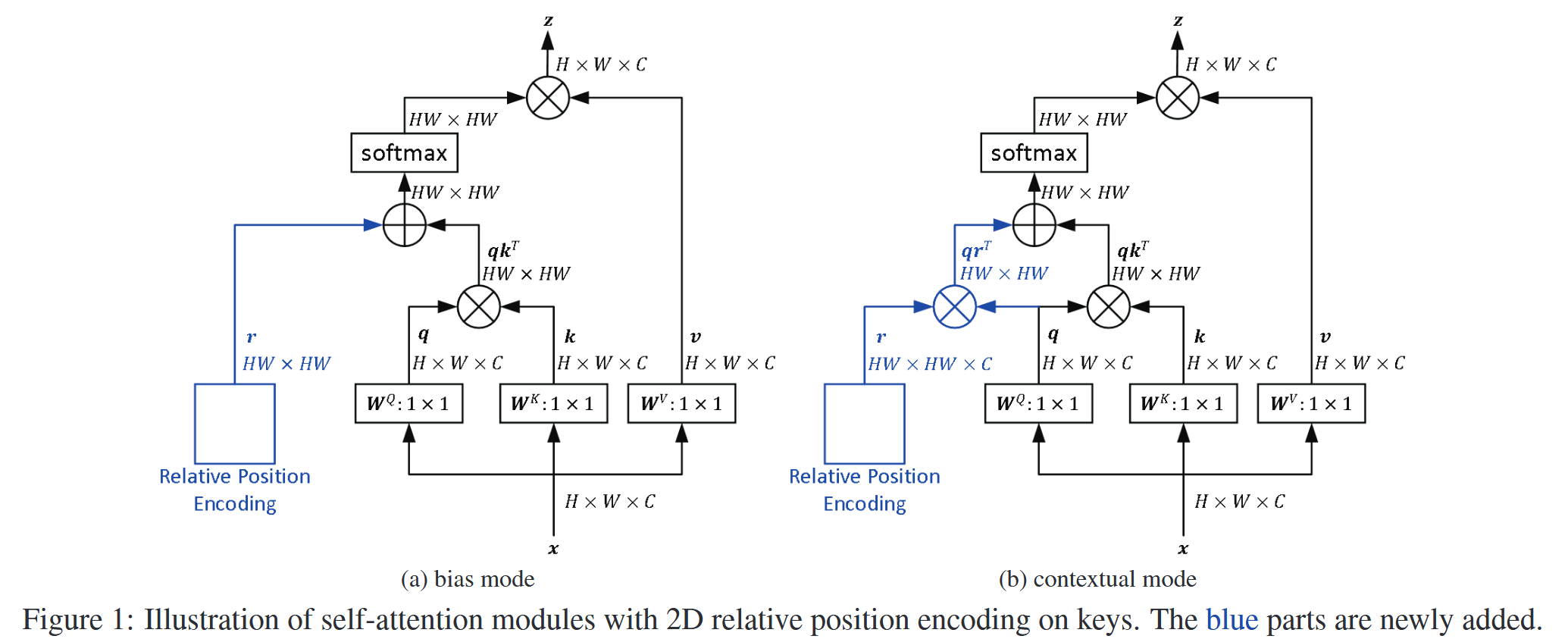
图1:在键上使用二维相对位置编码的自注意力模块示意图。蓝色部分是新添加的。 - 分段索引函数:为降低计算成本和参数数量,引入分段函数 g ( x ) g(x) g(x),它将相对距离映射为有限集中的整数,进而索引相对位置权重 r i j r_{ij} rij。与传统clip函数不同, g ( x ) g(x) g(x)基于相对距离分配注意力,更适用于高分辨率图像或需要长距离特征依赖的任务。函数公式为:
g ( x ) = { [ x ] , ∣ x ∣ ≤ α s i g n ( x ) × m i n ( β , [ α + ln ( ∣ x ∣ / α ) ln ( γ / α ) ( β − α ) ] ) , ∣ x ∣ > α g(x)=\begin{cases} [x],& \vert x\vert\leq\alpha\\ sign(x)\times min(\beta,\left[\alpha+\frac{\ln(\vert x\vert/\alpha)}{\ln(\gamma/\alpha)}(\beta - \alpha)\right]),& \vert x\vert>\alpha \end{cases} g(x)={[x],sign(x)×min(β,[α+ln(γ/α)ln(∣x∣/α)(β−α)]),∣x∣≤α∣x∣>α
其中, [ ⋅ ] [·] [⋅] 为取整运算, s i g n ( x ) sign(x) sign(x) 确定符号, α \alpha α 决定分段点, β \beta β 控制输出范围, γ \gamma γ 调整对数部分的曲率。
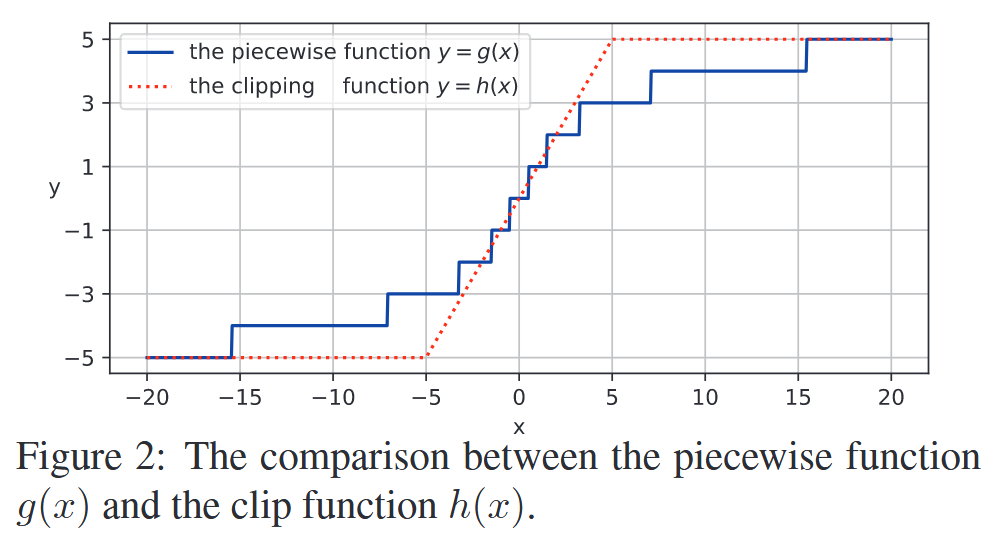
图2:分段函数 g ( x ) g(x) g(x)与clip函数 h ( x ) h(x) h(x)的对比。 - 2D相对位置计算:
- Euclidean方法:计算图像平面上两点的欧氏距离,并映射为相应编码,是无向的。公式为 r i j = p I ( i , j ) r_{ij}=p_{I(i,j)} rij=pI(i,j), I ( i , j ) = g ( ( x ~ i − x ~ j ) 2 + ( y ~ i − y ~ j ) 2 ) I(i,j)=g(\sqrt{(\tilde{x}_{i}-\tilde{x}_{j})^{2}+(\tilde{y}_{i}-\tilde{y}_{j})^{2}}) I(i,j)=g((x~i−x~j)2+(y~i−y~j)2) , p I ( i , j ) p_{I(i,j)} pI(i,j)根据模式是可学习标量或向量,桶数量为 2 β + 1 2\beta + 1 2β+1。
- Quantization方法:针对Euclidean方法中相近邻居可能映射到相同索引的问题,对欧氏距离进行量化,使不同实数映射到不同整数,同样是无向的,修改后的索引计算为 I ( i , j ) = g ( q u a n t ( ( x ~ i − x ~ j ) 2 + ( y ~ i − y ~ j ) 2 ) ) I(i,j)=g(quant(\sqrt{(\tilde{x}_{i}-\tilde{x}_{j})^{2}+(\tilde{y}_{i}-\tilde{y}_{j})^{2}})) I(i,j)=g(quant((x~i−x~j)2+(y~i−y~j)2))。
- Cross方法:考虑像素位置方向的重要性,提出有向的Cross方法。该方法分别在水平和垂直方向计算编码,然后汇总。公式为 r i j = p I x ‾ ( i , j ) x ‾ + p I y ‾ ( i , j ) y ‾ r_{ij}=p_{I^{\overline{x}}(i,j)}^{\overline{x}}+p_{I^{\overline{y}}(i,j)}^{\overline{y}} rij=pIx(i,j)x+pIy(i,j)y , I x ~ ( i , j ) = g ( x ~ i − x ~ j ) I^{\tilde{x}}(i,j)=g(\tilde{x}_{i}-\tilde{x}_{j}) Ix~(i,j)=g(x~i−x~j) , I y ~ ( i , j ) = g ( y ~ i − y ~ j ) I^{\tilde{y}}(i,j)=g(\tilde{y}_{i}-\tilde{y}_{j}) Iy~(i,j)=g(y~i−y~j) ,桶数量为 2 × ( 2 β + 1 ) 2\times(2\beta + 1) 2×(2β+1)。
- Product方法:为提高效率并融入更多方向信息,设计Product方法。该方法通过组合2D索引得到编码,公式为 r i j = p I x ‾ ( i , j ) , I y ‾ ( i , j ) r_{ij}=p_{I^{\overline{x}}(i,j),I^{\overline{y}}(i,j)} rij=pIx(i,j),Iy(i,j) ,桶数量为 ( 2 β + 1 ) 2 (2\beta + 1)^{2} (2β+1)2。
- 高效实现:对于contextual模式下的方法,存在公共项 ( x i W ) p I ( i , j ) T (x_{i}W)p_{I(i,j)}^{T} (xiW)pI(i,j)T ,原计算方式时间复杂度为 O ( n 2 d ) O(n^{2}d) O(n2d)。利用 I ( i , j ) I(i,j) I(i,j) 的多对一性质,提出高效实现方式,先以 O ( n k d ) O(nkd) O(nkd) 的时间复杂度预计算所有 z i , t = ( x i W ) p t T z_{i,t}=(x_{i}W)p_{t}^{T} zi,t=(xiW)ptT ,再通过 y i , j = z i , I ( i , j ) y_{i,j}=z_{i,I(i,j)} yi,j=zi,I(i,j) 分配,使计算成本降至 O ( n k d ) O(nkd) O(nkd)。
实验-Experiments
该部分通过多种实验,对相对位置编码进行深入探究,涵盖实施细节、各因素分析、与其他方法对比以及可视化研究,以验证iRPE方法的有效性,具体内容如下:
- 实施细节:大多实验以DeiT为基线模型,在所有自注意力层添加相对位置编码,通常仅在键上添加。设置分段函数 g ( x ) g(x) g(x) 的参数 α : β : γ = 1 : 2 : 8 \alpha:\beta:\gamma = 1:2:8 α:β:γ=1:2:8,并依 β \beta β 调整桶数量,用额外桶存储分类token的相对位置编码。采用与DeiT相同的训练设置,包括优化器、学习率调度、数据增强等,用8个NVIDIA Tesla V100 GPU从零训练模型300个epoch。
- 相对位置编码分析
- 有向与无向对比:实验表明,有向方法(Cross和Product)在视觉Transformer中的表现优于无向方法(Euclidean和Quantization),这凸显了方向信息对处理高度结构化且语义相关的图像像素的重要性。
- Bias与Contextual对比:Contextual模式性能更优,因其编码会随输入特征变化,而Bias模式编码固定不变。
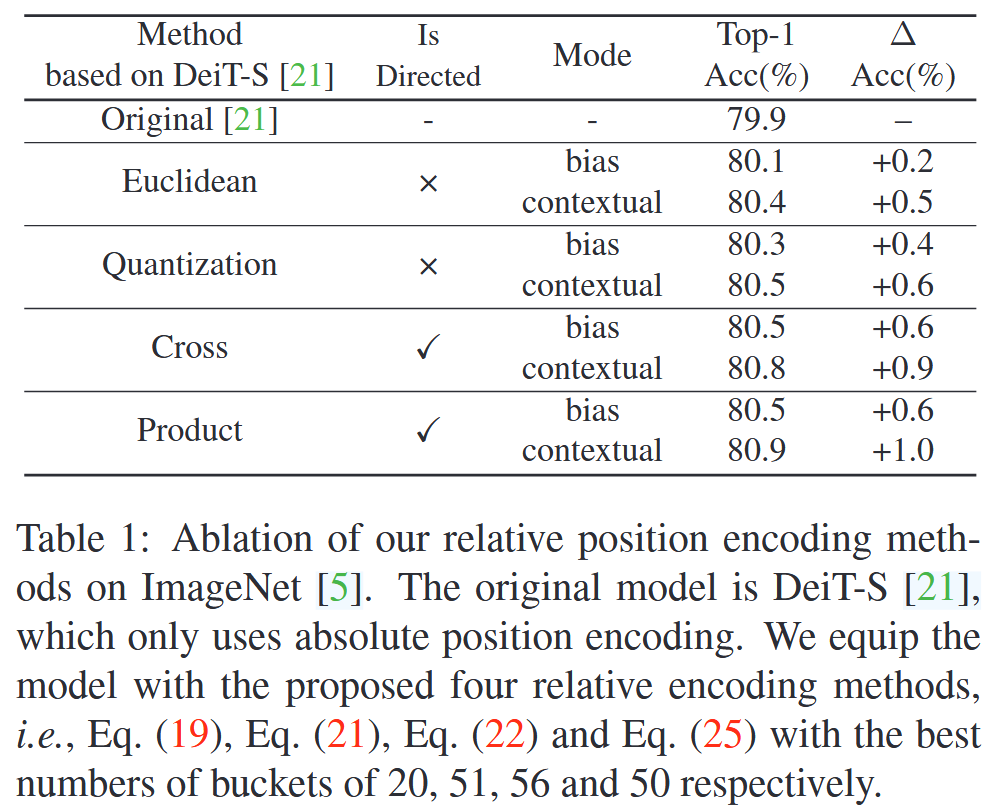
表1:在ImageNet数据集上对我们提出的相对位置编码方法的消融实验。原始模型是DeiT-S,该模型仅使用绝对位置编码。我们为该模型配备了所提出的四种相对编码方法,即公式(19)、公式(21)、公式(22)和公式(25),其最佳桶数分别为20、51、56和50。 - 共享与非共享对比:在Bias模式下,跨注意力头共享编码会导致精度大幅下降;在Contextual模式中,两种方案性能差异不明显,为节省参数,最终采用共享方案。
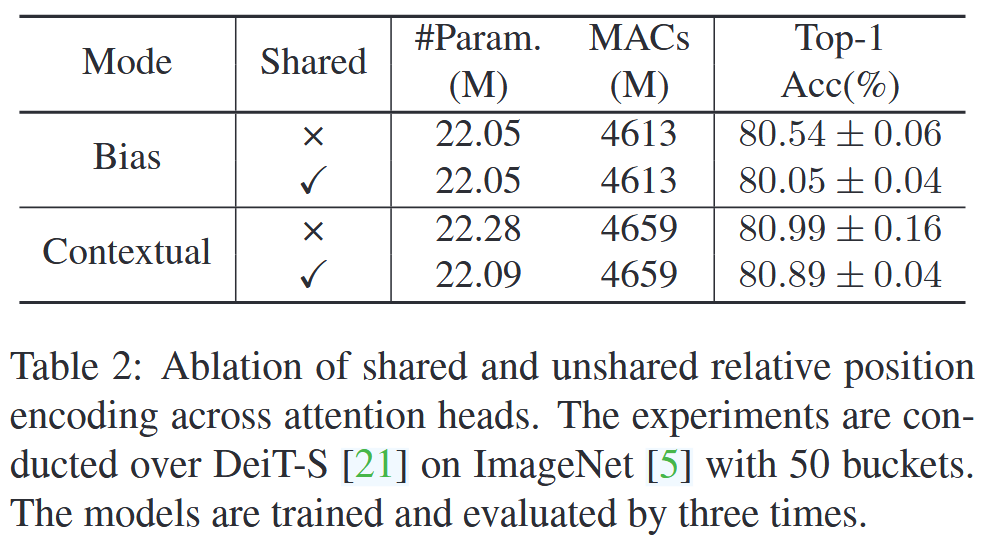
表2:注意力头间相对位置编码共享与非共享的消融实验。实验在ImageNet数据集上基于DeiT-S模型进行,设置桶数为50。模型经过三次训练和评估。 - 分段函数与Clip函数对比:在图像分类任务中,两者性能差异微小;但在目标检测任务里,分段函数更优。因为目标检测输入分辨率高、序列长,分段函数能依据相对距离分配不同注意力,而Clip函数在相对距离大于阈值时会赋予相同编码。
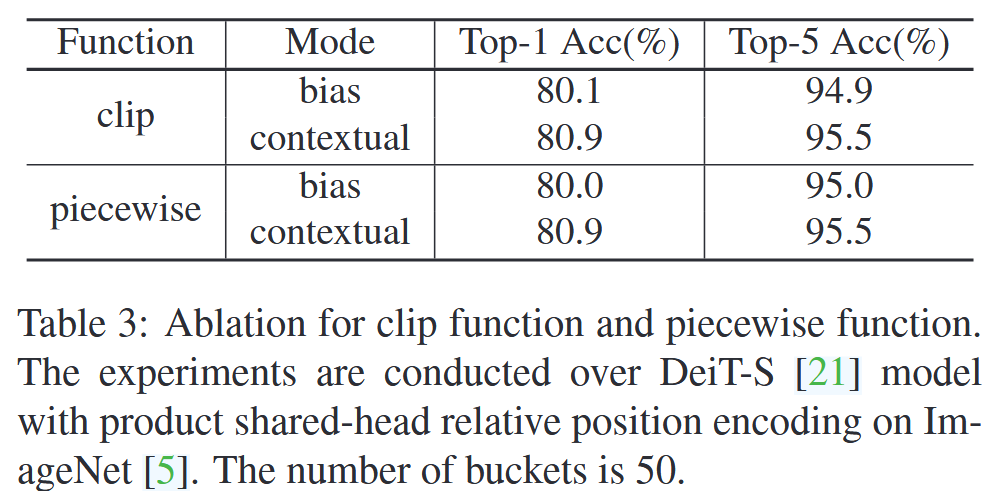
表3:Clip函数和分段函数的消融实验。实验在搭载乘积共享头相对位置编码的DeiT-S模型上进行,数据集为ImageNet,桶的数量为50。 - 桶数量影响:研究发现,对于DeiT-S的14×14特征图,桶数量为50时,能在计算成本和精度间取得较好平衡,超过该数量后,精度提升不再显著。
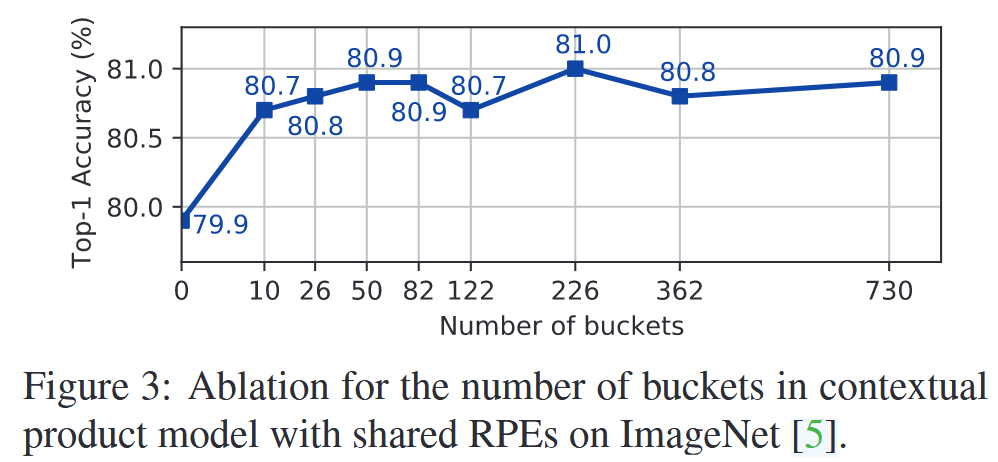
图3:在ImageNet数据集上,具有共享相对位置编码(RPE)的上下文乘积模型中,针对桶数量的消融实验。 - 组件分析:去除DeiT-S原有的绝对位置编码会使Top-1准确率下降;仅使用相对位置编码的模型表现优于仅用绝对位置编码的模型;添加相对位置编码后,绝对位置编码对提升性能无明显作用;相对位置编码作用于查询或键时比作用于值带来的性能提升更大;同时在查询、键和值上应用相对位置编码可进一步提高模型性能 。
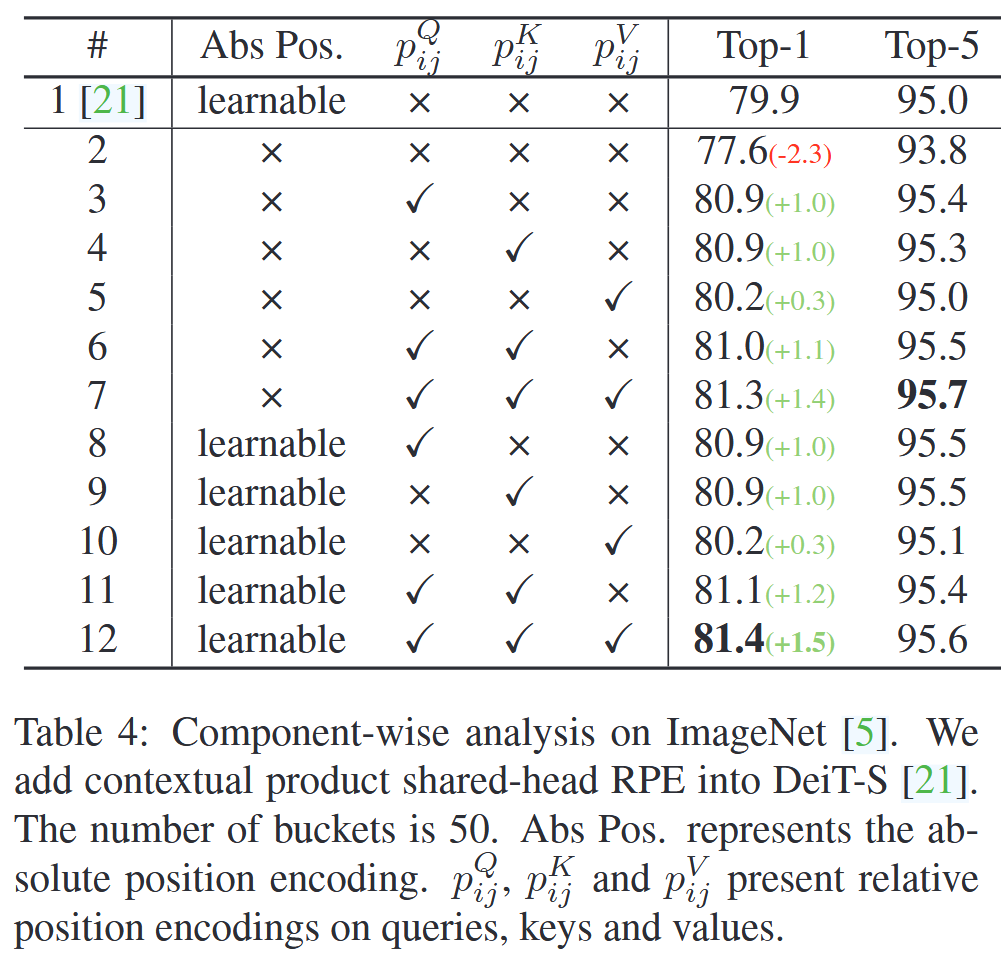
表4:在ImageNet数据集上的组件分析。我们在DeiT-S模型中加入了上下文乘积共享头相对位置编码(RPE)。桶的数量为50。“Abs Pos.”表示绝对位置编码。 p i j Q p_{ij}^{Q} pijQ、 p i j K p_{ij}^{K} pijK 和 p i j V p_{ij}^{V} pijV 分别表示查询、键和值上的相对位置编码。 - 复杂度分析:采用高效实现的iRPE方法,相比仅含绝对位置编码的DeiT-S基线模型,额外计算成本最多1%。
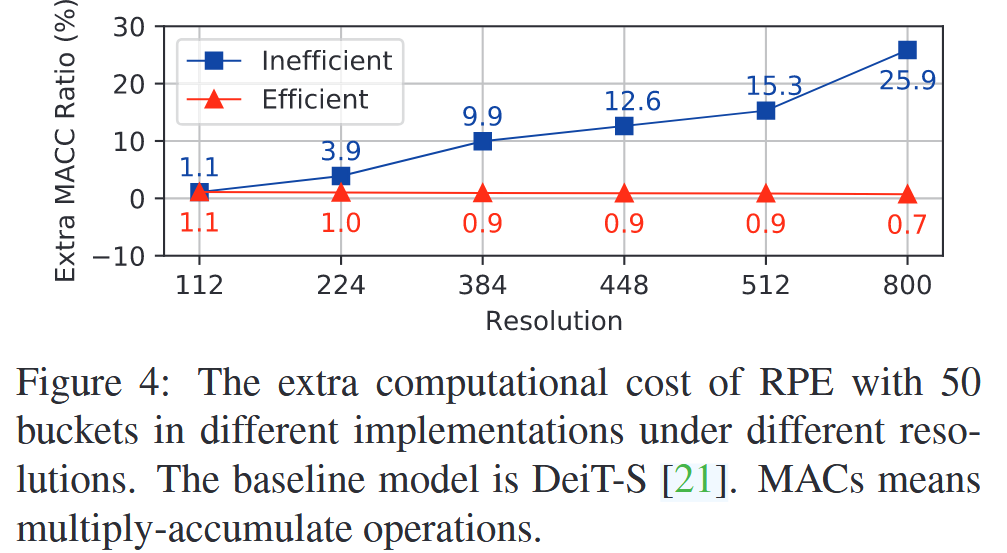
图4:在不同分辨率下,采用50个桶的相对位置编码(RPE)在不同实现方式下的额外计算成本。基线模型为DeiT-S。MACs表示乘累加运算。
- 图像分类对比实验:将iRPE方法与其他先进方法对比,以DeiT为基线,采用含50个桶的Contextual Product共享头方法。结果显示,iRPE方法在所有DeiT模型上均有性能提升,如DeiT-Ti/S/B模型的Top-1准确率分别提高1.5%、1.0%、0.6%。在查询和值上都添加iRPE,模型性能还能进一步提升,且iRPE方法在参数数量和计算量方面更具优势。
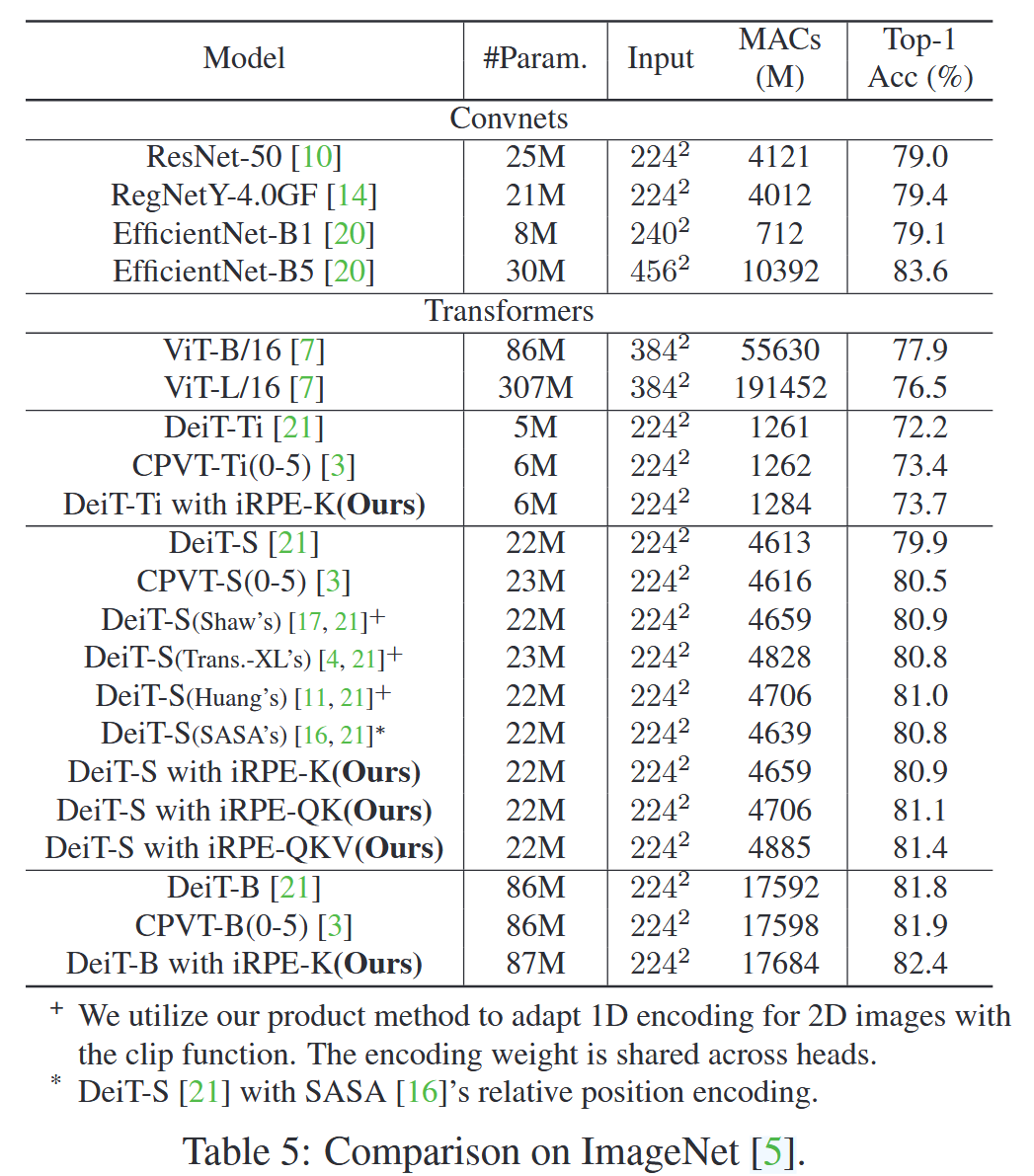
表5:在ImageNet数据集上的对比。 - 目标检测对比实验:以基于Transformer的检测模型DETR为基线,在COCO 2017检测数据集上验证iRPE方法的通用性。除在编码器的所有自注意力模块中注入RPE外,其他训练和验证设置不变。实验结果表明,iRPE方法使DETR在150和300个训练epoch下,平均精度均值(mAP)分别提升1.3和1.7。同时,研究发现位置编码对DETR至关重要,且绝对位置嵌入在该模型中优于相对位置嵌入,这与图像分类任务中的结论相反,推测是因为DETR需要绝对位置编码的先验信息来定位物体。
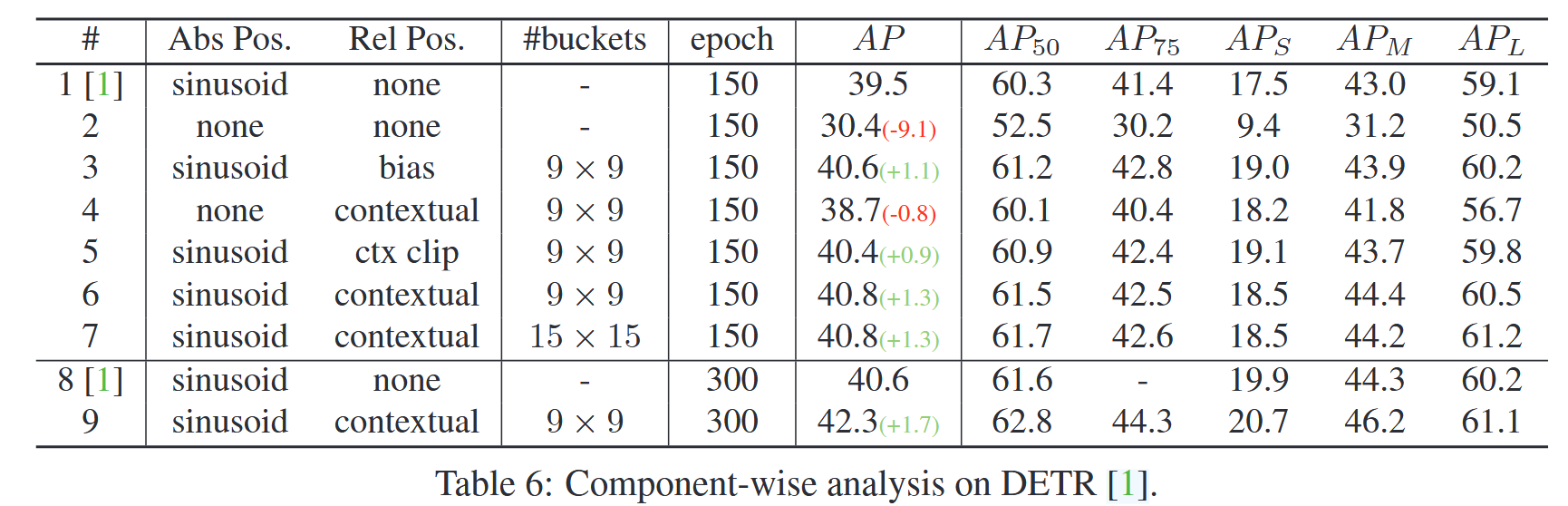
表6:基于DETR的组件分析。 - 可视化分析:通过可视化RPE添加到注意力中的额外权重 b i j b_{ij} bij 发现,在Transformer的浅层(如block 0),RPE使patch更关注相邻patch;但在深层(如block 10),这种现象消失。这表明RPE为Transformer注入了类似卷积的归纳偏差,增强了模型捕捉局部模式的能力,不过经过多层传递后,模型已能捕捉足够的局部信息。
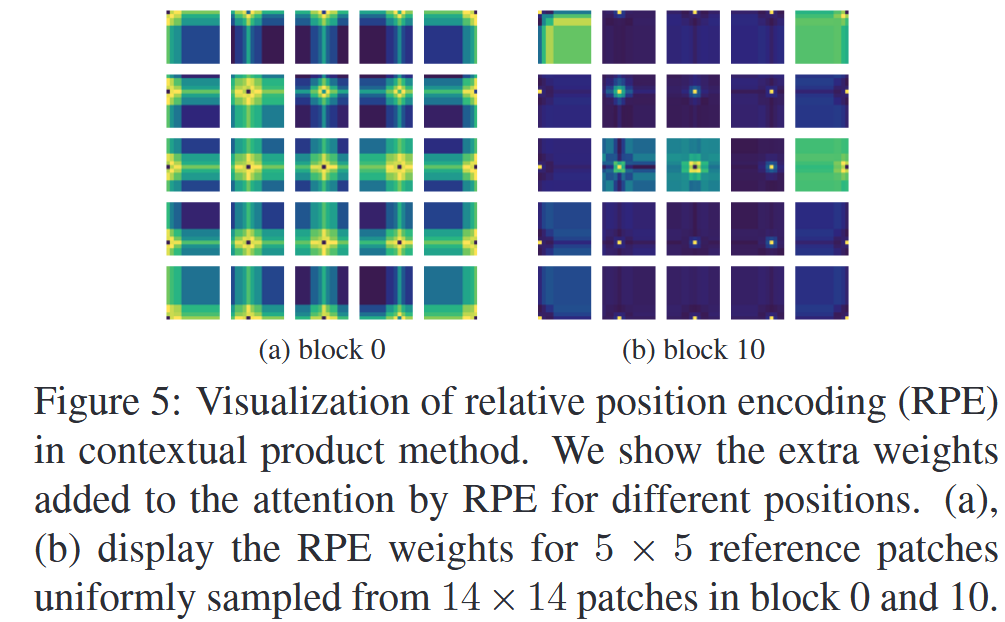
图5:上下文乘积法中相对位置编码(RPE)的可视化。我们展示了RPE为不同位置的注意力添加的额外权重。(a)和(b)展示了从第0块和第10块的14×14个patch中均匀采样的5×5参考patch的RPE权重。
相关工作-Related Work
该部分主要介绍了与本文研究相关的工作,包括Transformer在计算机视觉中的应用以及相对位置编码的发展,具体内容如下:
- Transformer:最初由Vaswani等人提出用于自然语言处理,近年来在计算机视觉领域得到广泛应用。在图像分类和目标检测任务中,本文选用DeiT和DETR作为基线模型。在ViT和DeiT中,图像被分割成固定大小的patch,其嵌入特征加上绝对位置编码后输入标准Transformer编码器,还会添加一个可训练的分类token用于分类。而DETR则先使用CNN骨干网络进行特征提取,将输出的下采样特征图展平后输入Transformer,由其输出边界框,同时在编码器和解码器中添加可学习或正弦的绝对位置编码。
- 相对位置编码:最早由Shaw等人提出,他们将相对位置编码添加到键和值中。随后,Dai等人提出带有正弦矩阵先验和更多可学习参数的相对位置编码;Huang等人提出了几种1D编码变体。相对位置编码在自然语言处理中的有效性已得到验证。在2D视觉任务方面,也有一些研究应用了相对位置编码,如Ramachandran等人提出分别计算并连接每个维度的编码,Chu等人提出在编码器之间插入位置编码生成器。然而,相对位置编码在视觉Transformer中的效果仍不明确,这正是本文研究和探讨的重点。
结论与评述-Conclusions and Remarks
这部分总结了研究成果,讨论相对位置编码(RPE)在视觉Transformer中的应用,分析不同因素对其效果的影响,得出关键结论并提出未来研究方向。
- 研究成果总结:回顾现有RPE方法,提出四种适用于视觉Transformer的iRPE方法。大量实验表明,iRPE方法能在分类和检测任务中显著提升模型性能,且增加的复杂度可忽略不计,还能方便地嵌入视觉模型的自注意力模块。
- RPE应用分析与结论
- 注意力头间共享RPE:RPE可在不同注意力头间共享以节省参数,在contextual模式下,共享和非共享RPE的性能相当。
- RPE与绝对位置编码的应用差异:在图像分类任务中,RPE可替代绝对位置编码;但在目标检测任务中,绝对位置编码对预测物体位置必不可少,不能被RPE替代。
- 考虑位置方向性的重要性:RPE应考虑位置方向性,这对结构化的2D图像至关重要,有助于模型更好地捕捉图像特征。
- RPE对浅层注意力的影响:RPE能使Transformer的浅层更关注局部patch,为模型注入类似卷积的归纳偏差,提升捕捉局部模式的能力。
- 未来研究方向:计划将iRPE方法拓展到其他基于注意力的模型和场景,如语义分割等需要高分辨率输入的任务,以及点云分类等非像素输入的任务,进一步探索其应用潜力。