Hive数据倾斜 常见解决办法
Hive数据倾斜 常见解决办法

数据倾斜是指在数据处理中,数据分布不均匀,大部分数据集中在少数几个 “键”(key)上的现象。
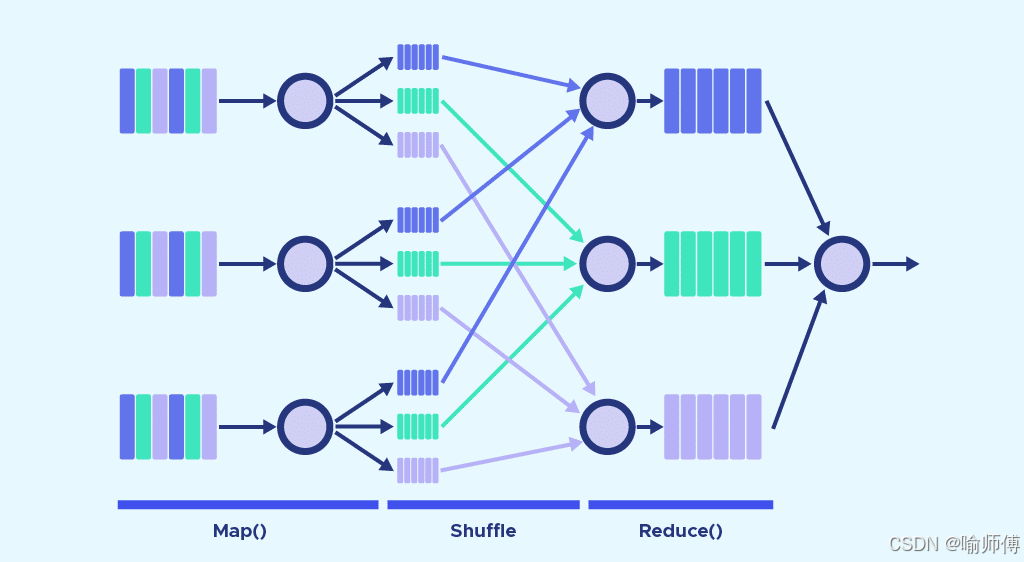
数据倾斜这个问题,在MapReduce编程模型中十分常见,根本原因就是大量相同的key被分配到一个reduce里 🎯,造成一个reduce任务处理不过来,但是其他的reduce任务没有数据可以处理 😫。
很多同学在回答Hive数据倾斜问题时,往往只是简单地罗列"使用map join"、“增加reduce数”、"设置hive.groupby.skewindata=true"等通用方法 📝,而没有结合具体业务场景和数据特征进行分析 🔍,这种做法是没有意义的,也难以真正解决问题 。
在解决Hive数据倾斜问题时,不是简单地罗列通用方法 🚫,而是针对不同业务场景下的具体问题进行分析和解决 💡。
博主总结了一些常见场景下的数据倾斜的解决办法,根据不同的场景,选择不同的方法即可🎈🎈🎈。
1. 数据类型不一致导致
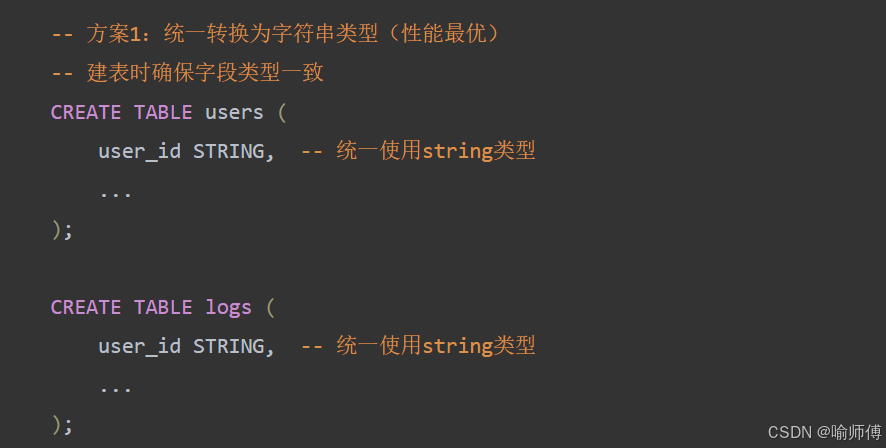
当两个表进行JOIN操作时,如果关联字段的数据类型不一致(例如一个表是int类型,另一个表是string类型),Hive会无法使用Map Join优化,导致数据倾斜和性能下降。
- 用户表users中的user_id字段为int类型
- 日志表logs中的user_id字段为string类型
- 直接JOIN会导致Hive执行Reduce Join,效率低下
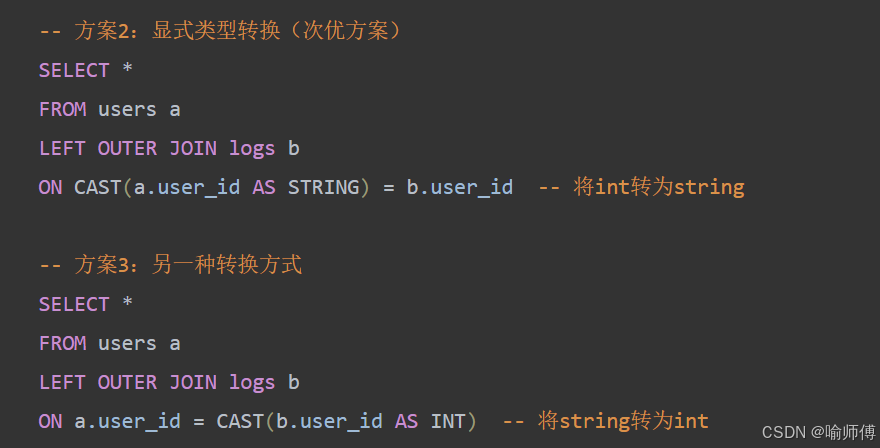
-
但是 类型转换会带来额外的计算开销,应尽量避免
-
最佳方案是在ETL过程中统一字段类型
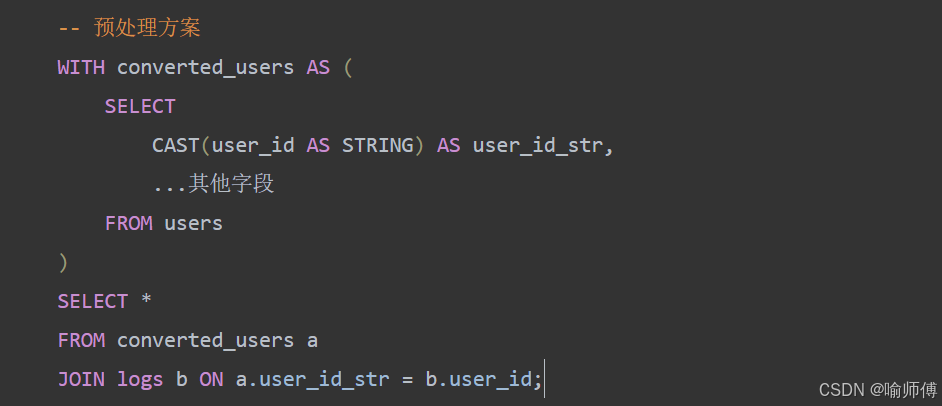
Tips: 对于大表JOIN,建议先对其中一张表进行预处理:
2. NULL值导致
当数据中存在大量NULL值时,这些NULL值会被分配到同一个Reducer处理,导致严重的数据倾斜问题。
处理数据倾斜时,理解业务含义比技术方案更重要!🔍 先判断NULL是"需要过滤的异常"还是"必须保留的有效值"。
场景一:NULL是异常值 ❌
Demo:
- 用户ID出现NULL(本不该为空)
- 员工姓名出现NULL(关键字段缺失)
- 银行卡号NULL(业务上不允许)
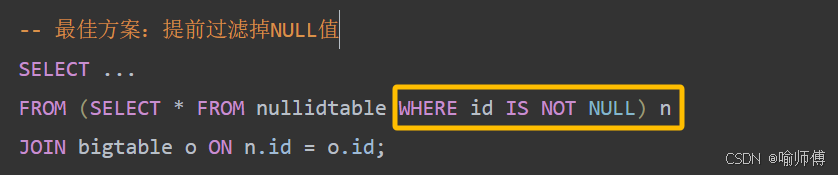
场景二:NULL是有效值 ✔️
Demo:
- 业务上允许的NULL值(如未填写选项)
- 需要保留在结果中的NULL记录

RAND()函数为NULL值生成随机数 🌈- 使NULL记录均匀分布到不同Reducer
- 保持查询结果不变(因为NULL本来就不会匹配任何有效ID)
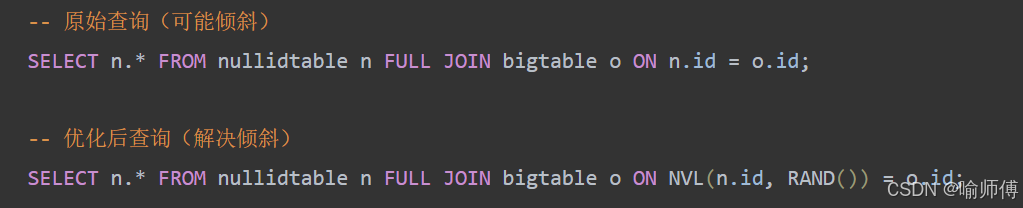
- 原本
n.id = o.id时,NULL永远不会等于任何值(包括其他NULL) - 使用
NVL(n.id, RAND())后:- 对有效ID保持原匹配逻辑 🔄
- 对NULL值生成随机数,使其均匀分布
- 最终结果集保持不变(因为NULL本来就不会匹配)
具体来说,我们可以根据具体业务数据的分布,去预处理或者调整随机数的范围:
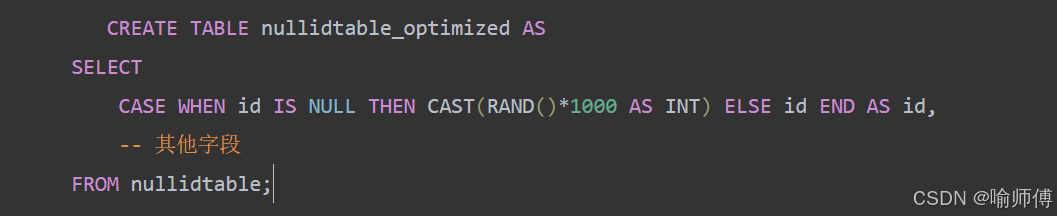
预处理阶段处理NULL:
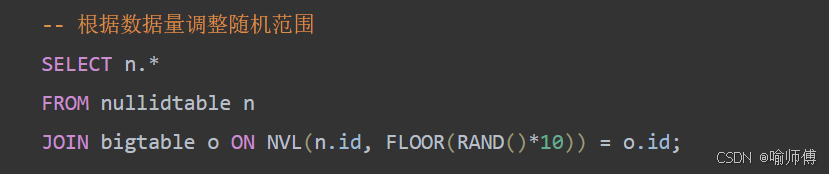
动态调整随机范围:
监控倾斜情况:

3. 单表GROUP BY导致
当执行GROUP BY操作时,如果某些Key的数据量远大于其他Key,会导致数据倾斜——少量Reducer需要处理绝大部分数据,而其他Reducer空闲。
1. 参数优化(推荐方案)
优势:自动处理倾斜,无需修改业务SQL
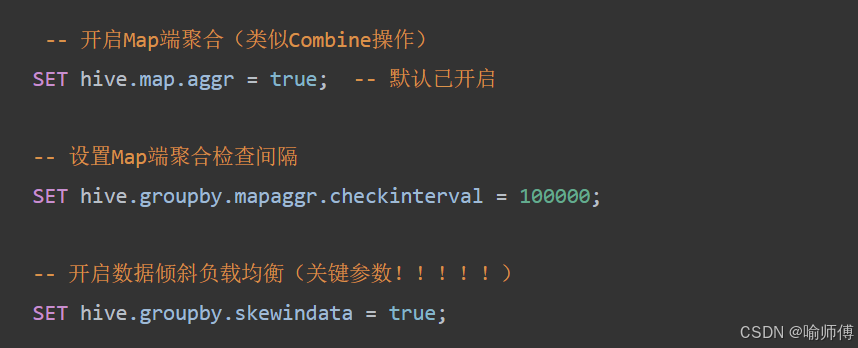
工作原理:
- 第一阶段MRJob:Map输出随机分布到Reduce,执行部分聚合
- 第二阶段MRJob:按GroupBy Key重新分发,完成最终聚合
2. 增加Reducer数量法
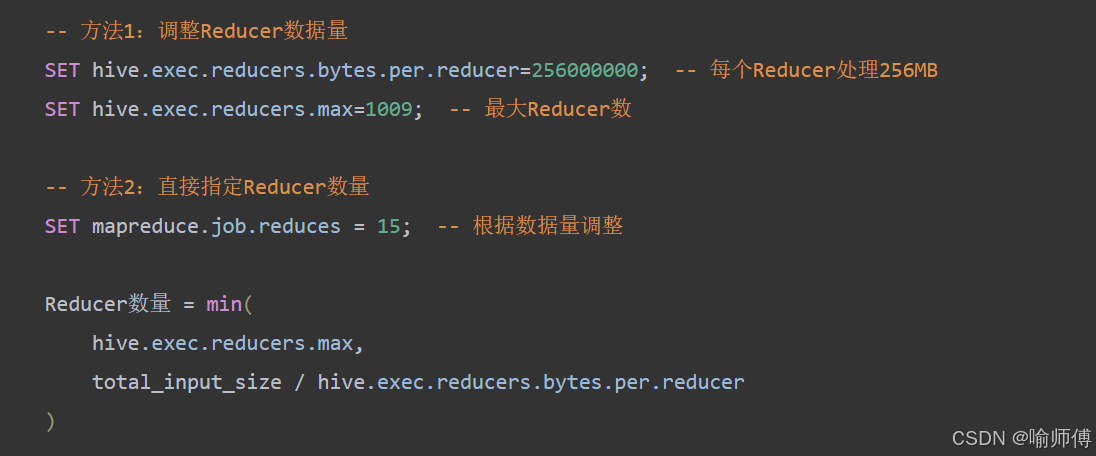
3. 两阶段聚合法(手动实现)

| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 参数优化 | 简单聚合场景 | 自动处理,无需改SQL | 产生两个MRJob |
| 增加Reducer | 多倾斜Key场景 | 实现简单 | 资源消耗大 |
| 两阶段聚合 | 复杂聚合场景 | 精准控制 | 需要修改SQL |
- 优先使用
hive.groupby.skewindata=true - 对于超大数据集,结合使用参数优化和增加Reducer
- 定期分析Key分布:
SELECT key, COUNT(*) FROM table GROUP BY key ORDER BY 2 DESC LIMIT 10; - 在ETL阶段对高频Key进行预处理
4. 多表JOIN导致
一、参数优化法(推荐优先尝试)
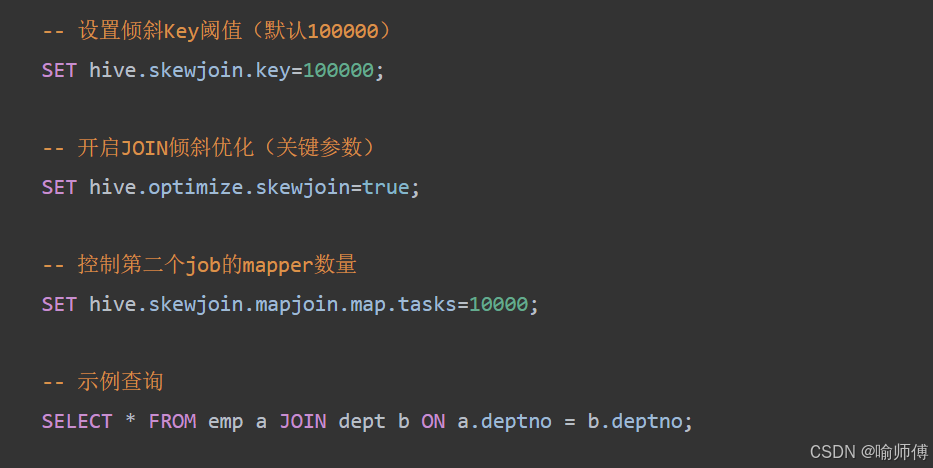
工作原理:
参数优化法通过Hive内置的倾斜检测和自动优化机制处理数据倾斜:
-
倾斜检测:当某个Join Key的记录数超过hive.skewjoin.key阈值时,识别为倾斜Key
-
数据分流:将倾斜Key对应的数据临时写入HDFS文件
-
两阶段处理:
- 第一阶段:正常处理非倾斜数据
- 第二阶段:使用MapJoin专门处理倾斜Key数据
-
结果合并:合并两个阶段的处理结果

二、大小表JOIN优化方案
1. MapJoin强制转换(最佳方案)
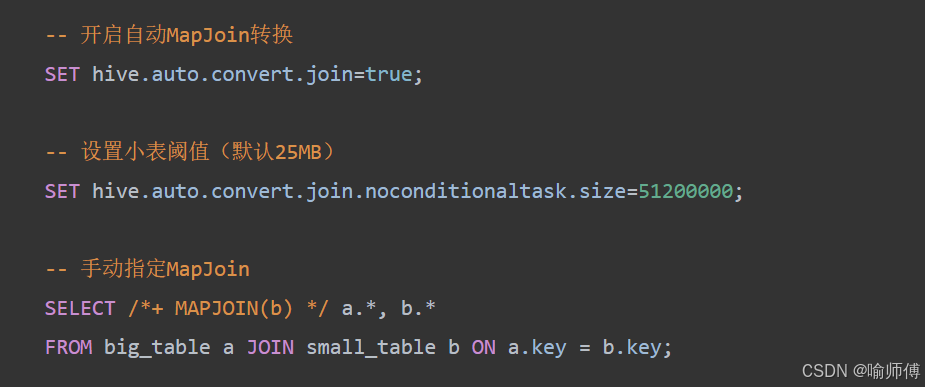
mapjoin工作原理:
- 小表加载:将小表完全加载到内存中构建哈希表
- 大表扫描:逐行扫描大表数据
- 内存匹配:直接在内存中完成Join操作
- 无Reduce阶段:完全在Map阶段完成,避免数据倾斜
2. 大表打散+小表扩容
数据分片:将大表的倾斜Key通过随机后缀打散到N个分片
数据扩容:将小表复制N份,每份添加对应分片后缀
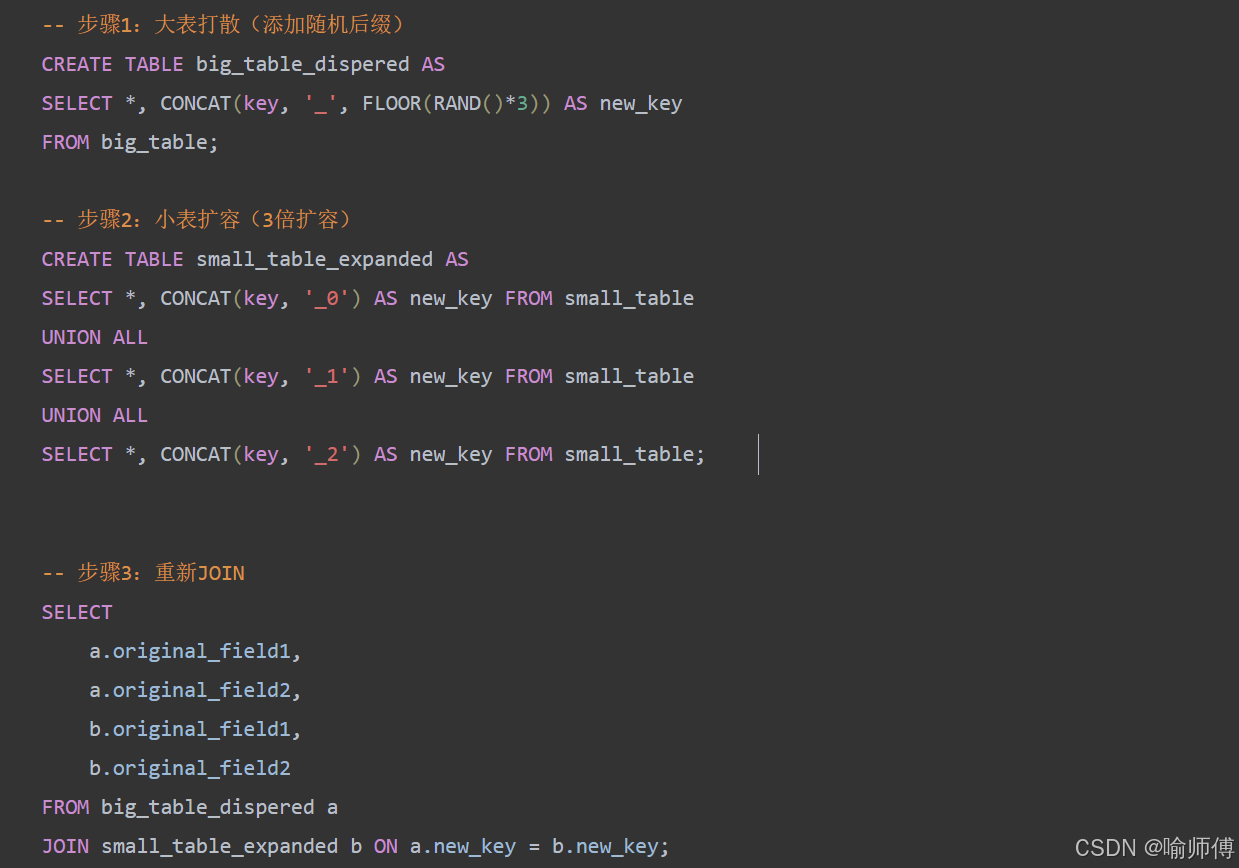
三、大表JOIN大表解决方案
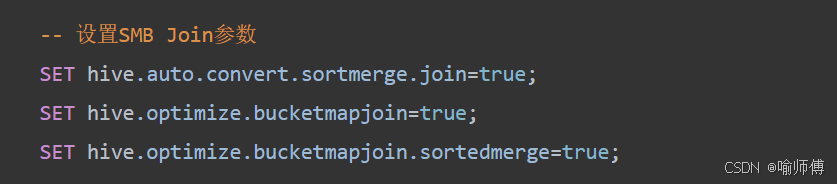
SMB Join(Sort-Merge-Bucket Join)
假如有两个大表,如何join速度快,就是创建两个分桶表表,把大表的数据导入进去,然后让分桶表和分桶表进行join,速度会快,当然在执行之前,需要开启smb join的设置。
hive 的三种join
1、ReduceJoin 也叫 Common Join、Shuffle Join
2. MapJoin
3. Sort Merge Bucket Join(分桶表Join)
普通JOIN:
表A数据 → Shuffle → Reduce处理
表B数据 → Shuffle ↗
(需要全网传输数据)
SMB Join:
表A桶1 ↔ 表B桶1(直接比较)
表A桶2 ↔ 表B桶2
...
(无需网络传输)
- 预分配均衡:通过哈希分桶,相同Key的数据被均匀分布到多个桶
- 并行处理:每个桶对(如A桶1和B桶1)可以独立处理
- 避免Shuffle:不需要像Reduce Join那样全网传输数据
想象你有两个超大仓库(表A和表B),每个仓库都有几百万个包裹(数据行),现在需要找出两个仓库中收件人相同的包裹进行配对。
普通做法(Reduce Join):
- 把所有包裹倒出来混在一起
- 让一群工人(Reducers)各自负责某些收件人名的包裹
- 每个工人需要从混乱的包裹堆里找出自己负责的部分
SMB Join做法:
-
预先分拣(分桶):
- 两个仓库都安装了相同的自动分拣机(分桶函数)
- 按照收件人姓名把包裹分配到固定编号的货架(桶)上
- 比如"张三"的包裹总是到1号货架,"李四"总是到2号货架
-
预先排序(Sort):
- 每个货架上的包裹按收件人姓名排好序
-
高效配对(Merge):
- 现在只需要将两个仓库的1号货架对比,2号货架对比…
- 因为已经排好序,可以像翻书一样快速配对
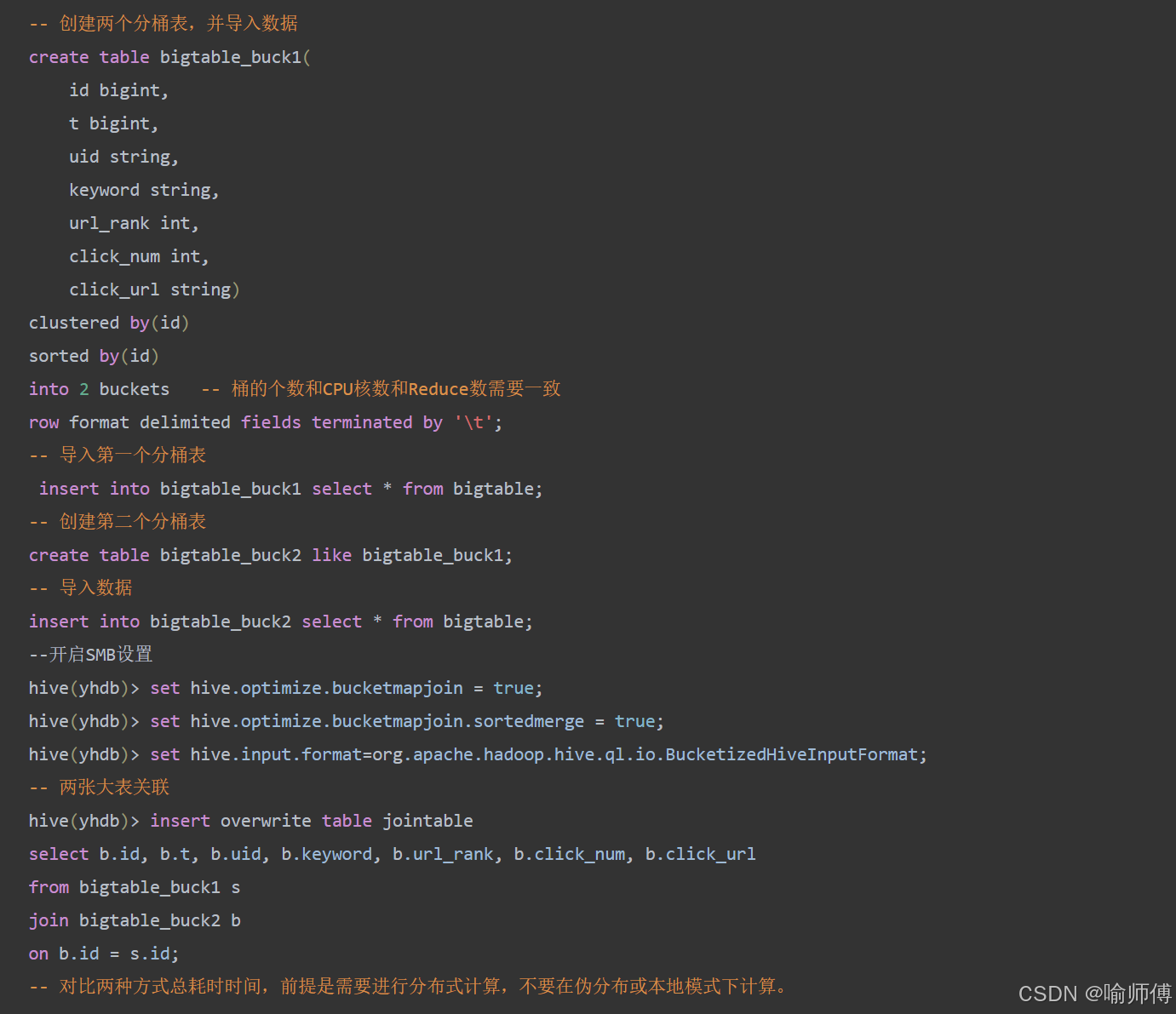
- 分桶(Bucketing)
CREATE TABLE table_bucketed (id INT,name STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;
- 哈希分配:对JOIN字段(如id)计算哈希值,模运算后确定桶编号
- 物理隔离:不同桶的数据存储在不同文件中
- 一致性:相同id的记录在两个表中会被分到相同编号的桶
- 排序(Sorting)
CREATE TABLE table_bucketed_sorted (id INT,name STRING
)
CLUSTERED BY (id) SORTED BY (id) INTO 4 BUCKETS;
- 每个桶内数据按JOIN字段排序
- 使JOIN操作可以使用归并排序算法(类似合并两个有序数组)
- Join执行过程
桶映射:表A的桶1只与表B的桶1JOIN,桶2对桶2…
通过这种"分而治之"的策略,SMB Join能极大提升大表JOIN的性能,特别是在分布式环境下效果更为显著。
- 适用两个超大表(TB级别)的JOIN、JOIN字段值分布相对均匀
- 可以预先进行分桶和排序操作