Memory Bank 不够用?Cline 全新 CRCT:省 token,依赖关系自行追踪
大家好!我是“非架构”。
你是否也经历过这样的崩溃瞬间:维护一个庞大的祖传代码库,想修改一个看似简单的功能,却发现它牵一发而动全身?或者,每次向 AI 代码助手(比如 Cline)描述完需求,它刚开始干活就好像“失忆”了,完全忘了项目的整体结构和之前的讨论?
没错,AI 代码编辑器在小型项目和原型开发中是效率神器,但在面对大型、复杂、依赖关系错综复杂的“代码巨兽”时,常常显得力不从心。这不仅拖慢了开发速度,更让我们对 AI 的实际应用效果打了折扣。
不过别担心,曙光已现!继 Cline 推出 Memory Bank 尝试管理人力可维护的上下文后,一个更专注于解决大型项目依赖追踪和任务分解难题的开源框架——Cline Recursive Chain-of-Thought System (CRCT) 诞生了!
今天,就让我们一起深入探索这个“项目导航仪”,看看 CRCT 如何帮助我们告别在大代码库中“大海捞针”的困境,提升开发效能!
(💡 提示:文章较长,可以直接跳到文末的 “一图胜千言” 查看核心总结!)
一、大型项目 + AI 代码编辑器 = “水土不服”?痛点速览
为什么 AI 助手在小项目里如鱼得水,到了大项目就频频“翻车”?主要痛点有:
- 上下文“容量焦虑”:AI 的“记忆”(上下文窗口)有限,塞不下整个大项目,导致理解片面,频繁丢失关键信息。
- 依赖关系“迷魂阵”:项目一大,文件、模块间的调用关系就像一团乱麻,AI 很难理清全局,修改时心惊胆战。
- 复杂任务“难以下手”:想让 AI 搞定一个涉及多模块的大任务?它往往不知道该从何开始,如何分解,如何协调。
- 性能“龟速”响应:分析海量代码和复杂依赖,需要大量计算,AI 反应慢,等待时间让人抓狂。
这些问题,严重影响了 AI 在大型复杂项目中的实用价值。
二、现有方案“隔靴搔痒”?Memory Bank 与 CRCT 的分野
为了解决这些问题,业界做了不少尝试:智能补全、Bug 检测、文档生成…… Cline 推出的 Memory Bank 也是重要一步。
Memory Bank 像是一个结构化的项目备忘录 (通常是 memory-bank/ 目录下的 Markdown 文件)。开发者可以记录项目目标、架构、技术选型等高层上下文,让 AI 在新会话中能“回忆”起项目概况。
但是! Memory Bank 主要依赖人工维护,并且侧重于宏观信息的记录。对于代码内部深层次、细粒度的依赖关系和复杂任务的自动分解执行,它的帮助相对有限。
这时,CRCT 闪亮登场!
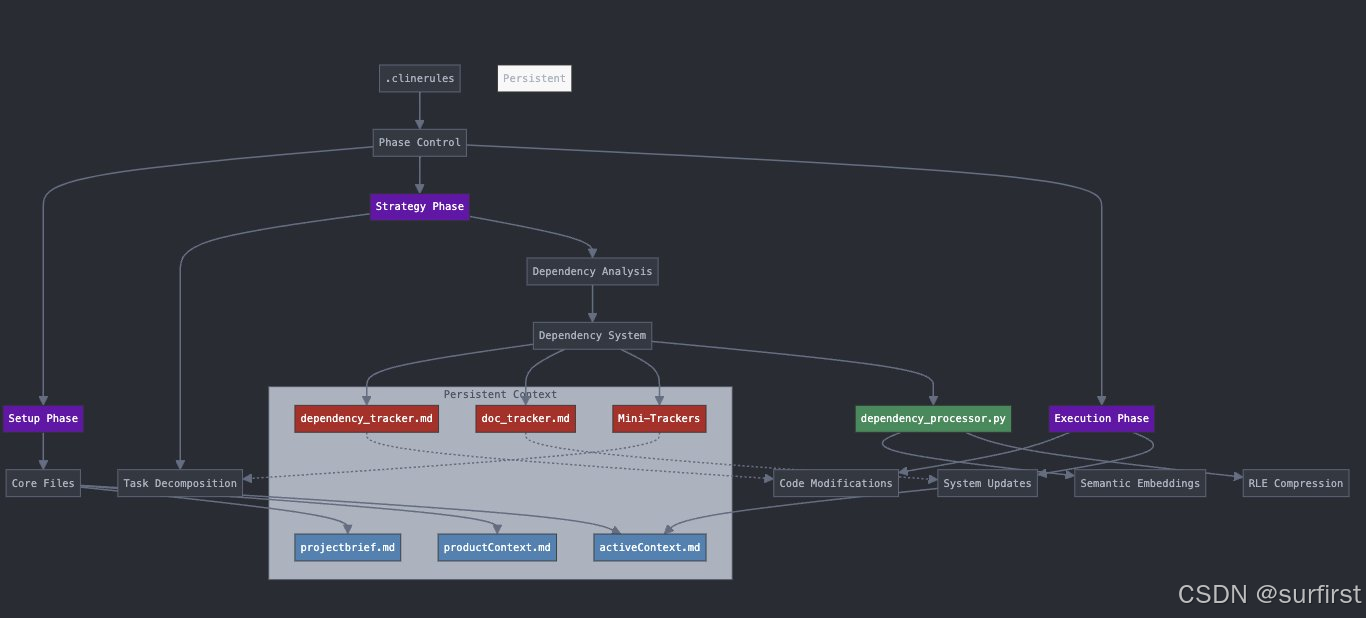
如果说 Memory Bank 是项目的“备忘录”,那么 CRCT 更像是一个底层的、自动化的“工程框架”或“导航系统”。它不只是“记忆”,更要“理解”和“执行”。
CRCT vs. Memory Bank 核心区别:
| 特性 | Cline Memory Bank (备忘录) | CRCT (工程框架/导航仪) |
|---|---|---|
| 核心目标 | 跨会话高层上下文保存 & 文档化 | 精细化依赖追踪 & 复杂任务分解 & 状态持久化 |
| 主要机制 | 结构化 Markdown 文件 (人工维护为主) | 递归 CoT, 文件系统状态, 自动化依赖系统, 缓存, MUP 协议 |
| 依赖管理 | 记录技术选型等宏观信息 | 核心优势:精细追踪 (KeyInfo, 分层聚合), 高效 (RLE压缩) |
| 任务处理 | 辅助规划,记录进度 | 核心优势:递归分解复杂任务,隔离上下文 |
| 性能优化 | 无 | 核心优势:缓存, 最小上下文加载 (显著提速) |
| 自动化程度 | 较低 (依赖提示更新) | 较高 (协议驱动更新) |
| 最擅长解决 | AI 跨会话“失忆”问题,项目概况传递 | 大型项目中依赖复杂难追踪、任务难分解执行的问题 |
简单说: Memory Bank 帮你告诉 AI “我们正在建什么,大概怎么建”,而 CRCT 帮你让 AI “弄清楚各个零件怎么连接,复杂任务怎么一步步拆解完成”。
三、CRCT 的“黑科技”:拆解大型项目的秘密武器
CRCT 听起来很酷,但它具体是怎么做到的呢?别被技术名词吓到,我们来逐一拆解它的“核武器”:
🚀 武器一:递归分解 (Recursive Decomposition)
-
做什么? 把一个复杂的大任务,像剥洋葱一样,一层层自动分解成更小、更简单的子任务。
-
怎么做? 每个子任务都有自己的“工作空间”(文件目录),包含独立的上下文、指令和输出,互不干扰。
-
好处? 化整为零,降低复杂度,让 AI 能聚焦处理当前的小任务,避免信息过载。
-
*(想象一下:这里可以放一个树状图,展示一个大任务被分解成多个小任务的过程)
🔗 武器二:模块化依赖追踪系统 (Modular Dependency Tracking)
- 做什么? 精准、高效地搞清楚代码中“谁依赖谁”。这是 CRCT 的“杀手锏”!
- 核心技术:
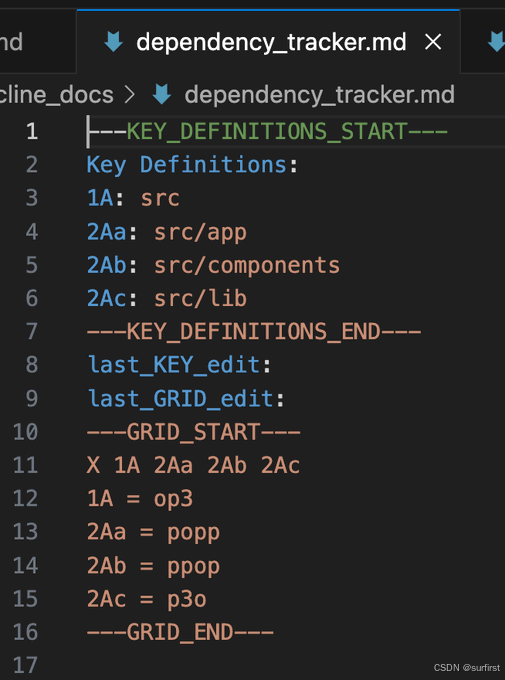
- Contextual Keys (KeyInfo):可以理解为给代码模块、函数起**“外号”或“速记码”**。用这个短小的 KeyInfo 来代表,比用冗长的完整文件路径或函数签名更高效。
- 分层依赖聚合 (Hierarchical Dependency Aggregation):就像看地图,你可以选择只看省/市级别的依赖关系,而不用一开始就陷入具体的街道门牌号(具体文件/函数)。需要时再深入细节。
- RLE 压缩:一种压缩技术,好比把“AAAAA”记作“5个A”,大大减少存储依赖信息所需的空间。
- 结果? 据说效率比传统方式提升约 90%!还提供了命令 (
show-dependencies,visualize-dependencies) 让你轻松查看和管理依赖。
💾 武器三:持久化状态 (Persistent State) + MUP
- 做什么? 让 AI 的“记忆”和工作状态能永久保存下来,而不是对话结束就消失。
- 怎么做? 利用 VS Code 的文件系统(比如
cline_docs/目录)存储上下文、指令、依赖关系等。通过强制更新协议 (MUP),确保 AI 在执行任务时,这些状态信息能被自动、准确地更新。 - 好处? 解决了 AI 的“失忆”问题,工作可以随时中断和恢复。
⚡ 武器四:性能优化 (Caching & Minimal Context Loading)
- 做什么? 让 CRCT 在处理大型项目时也能保持高速响应。
- 怎么做?
- 缓存系统:把计算过的依赖关系等结果存起来,下次再用就快了。效果惊人,某些任务能从 11 分钟缩短到 30 秒!
- 最小上下文加载:只加载当前任务绝对必要的代码和信息,避免一开始就读入大量无关内容。
- 好处? 大幅提升 AI 处理大型项目的效率和开发体验。
还有……
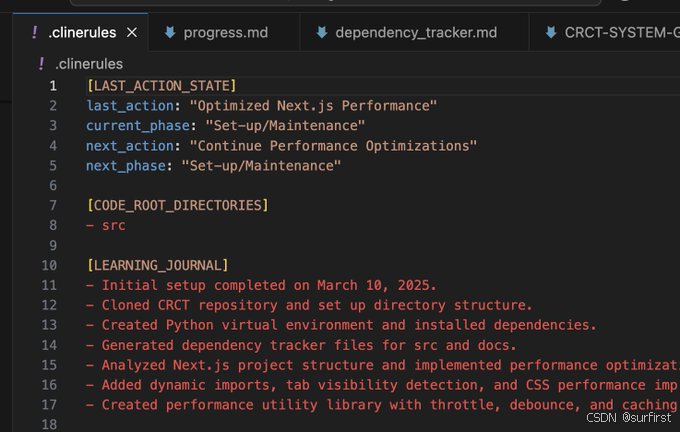
- 阶段化工作流:通过
.clinerules控制 AI 按“设置/维护”、“策略”、“执行”等阶段有序工作。 - 链式思考 (CoT):保留 AI 的思考过程,让操作更透明。
- 可配置性:可以自定义忽略文件、配置硬件加速 (cpu, cuda, mps) 等。
工作原理一句话总结: CRCT 通过递归分解任务,利用高效的依赖系统和持久化状态理解项目,仅加载必要上下文,并通过缓存加速,让 AI 能条理清晰、高效地处理大型复杂项目。
四、实战场景:CRCT 如何发光发热?
理论说了这么多,我们来看个实际场景:
场景: 开发者小明需要重构项目 CoreUtils 模块里的一个核心函数 processData(),这个函数被项目里几十个其他模块间接或直接调用。
- 没有 CRCT / Memory Bank: 小明头大了!他得手动搜索所有调用点,或者依赖 IDE 不一定完全准确的查找。他让 Cline 帮忙分析影响,但 Cline বারবার因为上下文不足而遗漏关键依赖,或者给出错误的建议。小明改得心惊胆战,生怕弄崩哪里。
- 只有 Memory Bank: 小明可以把
CoreUtils的重要性写进 Memory Bank,让 Cline 知道这是核心模块。但这对于梳理processData()具体被谁、在哪里、怎么调用的细粒度依赖关系,帮助有限。Cline 分析影响时依然可能受上下文限制。 - 有了 CRCT:
- 小明让 Cline 使用 CRCT 的
show-dependencies for CoreUtils.processData或visualize-dependencies命令,快速获得一张清晰的依赖图。 - 他决定开始重构。CRCT 自动将“重构 processData”这个大任务,递归分解为“分析依赖”、“修改 A 模块调用”、“修改 B 模块调用”、“更新单元测试”等子任务。
- 对于每个子任务,CRCT 只加载最小相关上下文 (比如
processData函数本身和 A 模块的相关代码),让 Cline 能专注处理。 - 小明在 Cline 的辅助下逐一完成子任务。每完成一步,CRCT 通过 MUP 协议自动更新持久化状态和依赖信息。
- 整个过程条理清晰,上下文准确,依赖明确,小明终于可以安心地完成这次大型重构了!
- 小明让 Cline 使用 CRCT 的
看到差别了吗?CRCT 真正深入到了代码的“毛细血管”层面进行管理和导航。
五、上手体验:三步让 CRCT 在 Cline 中为你所用
心动了吗?想试试 CRCT?上手其实很简单:
- 克隆仓库 & 安装依赖:
git clone https://github.com/RPG-fan/Cline-Recursive-Chain-of-Thought-System-CRCT-.git cd Cline-Recursive-Chain-of-Thought-System-CRCT- pip install -r requirements.txt # (如果需要运行 Python 脚本工具) - 配置 Cline:
- 将 CRCT 仓库里
cline_docs/prompts/core_prompt(put this in Custom Instructions).md的内容,复制到 Cline 扩展设置的 “Custom Instructions” 区域,或者项目根目录下的.clinerules文件里。这是给 Cline 下达的“最高指示”,告诉它如何运用 CRCT 框架。 - (建议:可以截图展示 VS Code 中 Cline 设置 Custom Instructions 的位置)
- 将 CRCT 仓库里
- 启动 & 使用:
- 在 Cline 输入框输入
Start.,CRCT 就会开始工作,引导你完成初始化。 - 对于现有项目,将 CRCT 的文件结构(如
cline_docs/,cline_utils/)复制到项目里,然后可以用类似Perform initial setup and populate dependency trackers.的提示让 CRCT 分析你的代码。 - 之后,你就可以在对话中自然地使用
show dependencies,add dependency,visualize dependencies等指令(让 AI 理解你的意图即可)。
- 在 Cline 输入框输入
别被初始设置吓到,一旦配置好,CRCT 就能在后台默默地让你的 Cline 变得更强大!
六、温馨提示 (Points to Note)
- 学习曲线: CRCT 引入了一些新概念和工作流,可能需要一点时间来熟悉和适应。
- 开源演进中: CRCT 是一个活跃的开源项目(目前 v7.5),这意味着它在不断改进,但也可能遇到一些小问题。这同时也是参与贡献的好机会!
七、总结:拥抱 CRCT,告别大型项目开发焦虑!
CRCT 的出现,为使用 Cline 等 AI 代码助手应对大型、复杂项目带来了革命性的解决方案。它通过:
- ✅ 递归分解 简化复杂性
- ✅ 精准依赖追踪 告别“依赖地狱”
- ✅ 持久化状态 解决“失忆”问题
- ✅ 高效性能优化 提升开发体验
让你能够更自信、更高效地在大型代码库中穿梭、修改和创造。
如果你正被大型项目的维护或开发所困扰,强烈建议你去 CRCT 的 GitHub 仓库 了解更多信息,并在你的项目中尝试一下!
互动时间:
看完 CRCT 的介绍,你觉得它最吸引你的功能是哪个?或者,你在大型项目中遇到过哪些用 AI 难以解决的痛点?欢迎在评论区分享你的看法! 👇
🎁 一图胜千言 (核心总结)
- CRCT 是什么? 一个为 Cline 设计的开源框架,像“项目导航仪”,专门解决 AI 处理大型、复杂代码库的难题。
- 解决什么问题? AI 在大项目中的上下文丢失、依赖追踪困难、任务分解混乱、性能低下等痛点。
- 和 Memory Bank 的区别? Memory Bank 像“备忘录”(高层上下文,人工维护为主),CRCT 像“工程框架”(精细依赖/任务,自动化程度高)。
- 核心优势? 递归分解任务 + 精准高效的依赖追踪 + 持久化状态 + 缓存提速。
- 最大价值? 让你能用 Cline 更高效、更安全地开发和维护大型软件项目。