【速写】prune与activate
序言
昨天逼亦童跑了5K,30分25秒,3K时刚好18分钟,本想把他逼进30分钟,还是太勉强了,不过半个多月就能练到这个水平,也不赖了。
明天要去芜湖参加xxp的婚礼,实话说我还是很乐意去一趟的,xxp之前因为跟邻座因为抖腿的问题闹矛盾还动了手,搬到了我旁边,我其实无所谓,总有性格不合的人,不过跟他也一起讨论了很多问题,一段时间后也觉得xxp还是很温文儒雅的,并没有什么不好,只是年后他还没来郭实验室,确是许久不见。
最近一直在思考的一个问题,权重参数与隐层输出的解释问题。发现模型会出现一些明显不该出现的偏好,比如随机生成表格中人物的年龄,就算0~9不是均匀分布,但至少12345这几个数字出现的概率应该不会太小,但实际情况是几乎95%以上的概率第一个年龄的十位数都会是生成2,从第3个往后就不足1%了。这其实也包括人物的姓氏甚至性别:
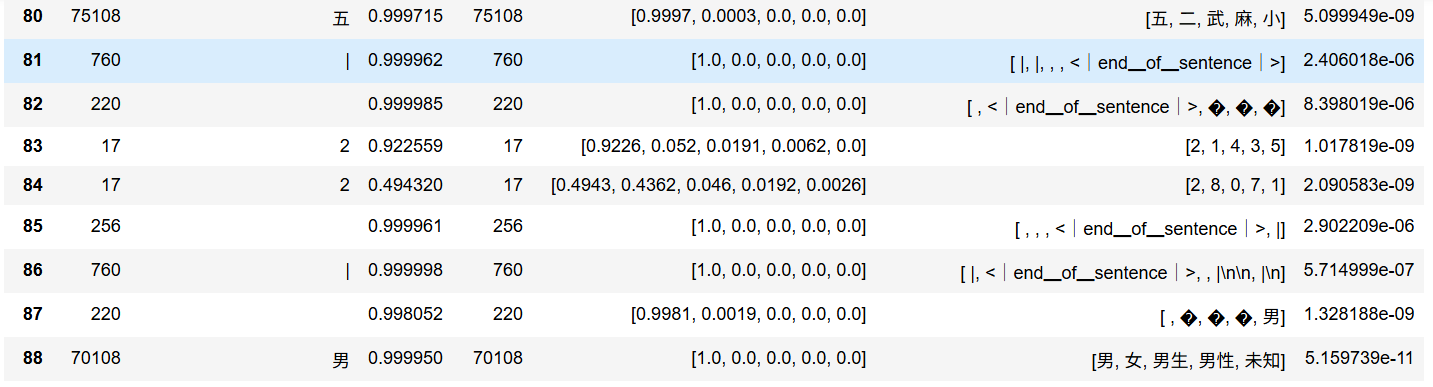
当然这个事情并不好说,人类其实可能也有偏好,只是个体的偏好不是那么好量化而已。
晚饭后,偶然想到激活与剪枝,LoRA本身实际上是一种boost,都是在拟合误差——输出的误差,这和soft prompt是完全不同,soft prompt是拟合参数的误差(不太准确,还是扩充参数准确一些),但是明显现在LoRA更主流,其实也不一定是效果更好,感觉只是更易用,热插拔。
假想模型是一棵庞大的决策树,我觉得这很形象,从根输入到叶输出,传统boost只是在叶子层面调节,LoRA则可能会在树的每一层都会调节。这样就像一根竹节虫玩具,只是扭头可能尾巴就会发散的很厉害,蝴蝶效应;只扭尾巴又很费力;还是要在身体上一节一节的扭,这样才稳定且每次都不用扭太多。
这是合理的,但同时也说明了隐层输出是重要的,ICLR的BEST PAPER的方法也说明了这一点,应该编辑的是隐层输出而非权重参数。
联想到跟亦童之前讨论得出过一个结论,不管是NLP还是CV,使用LoRA时,似乎v_proj的rank会明显比q_proj或者k_proj小,这个问题之后可能会再深入分析一下,想要找到一个理论上的证明,现在只是实证了一下,对每个LoRA块进行SVD分解,然后探究奇异值的分布,v_proj的奇异值分布明显更加尖锐,
比如下面是一个rank=64的LoRA微调后某一层QKV三个LoRA块的奇异值分布情况,其余层是类似的:
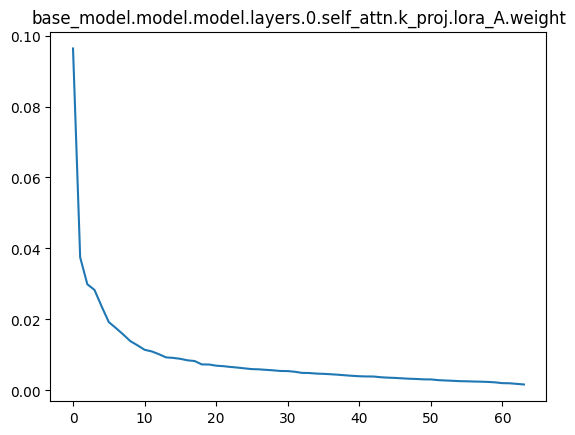
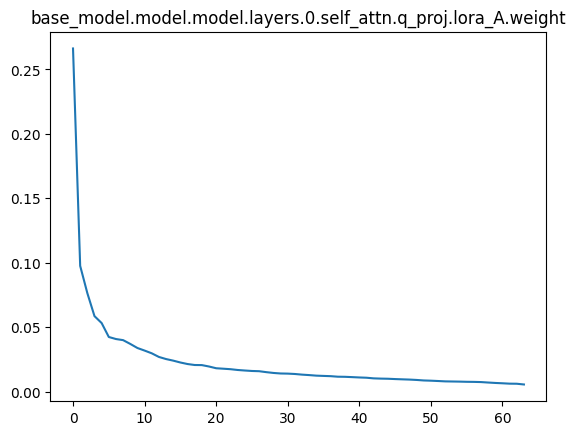
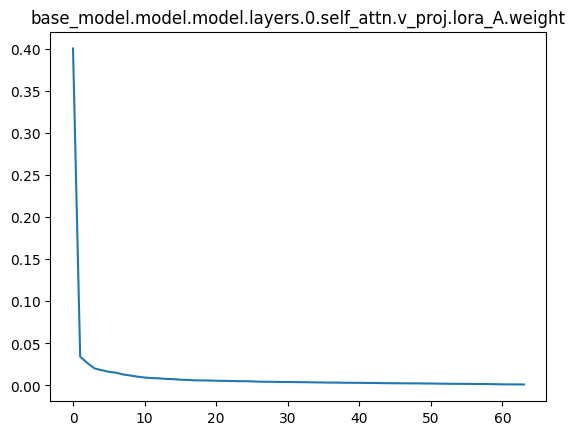
v_proj会明显荐椎很多,其实就是秩不满,没必要达到64,推论就是V其实没必要调,Q和K更值得调。
这个现象的原因不得而知,之后再详细探讨。
还是想回到剪枝与激活的问题上,前者相当于在剪去连接神经元的突触,后者则是直接剪去神经元。
目前剪枝还是非常直观的根据权重的绝对值来剪,也可以随机剪,也就是dropout。而激活,之前的ReLU会直接切掉负输出,其实也是一种变相的剪枝对不对?不过现在还是GeLU会用得更多了,因为负数端保留了一个很小得值,前向传播的计算量变大了,反而没了这种“剪枝”的意味。
其实,prune和activate何尝不是另一种影射。
文章目录
- 序言
- 关于torch.nn.utils.prune中的剪枝方法
- **1. 基础剪枝方法**
- **(1) 随机剪枝 (`RandomUnstructured`)**
- **(2) 幅度剪枝 (`L1Unstructured`)**
- **2. 结构化剪枝**
- **(1) 通道剪枝 (`LnStructured`)**
- **(2) 随机结构化剪枝 (`RandomStructured`)**
- **3. 自定义剪枝**
- **4. 全局剪枝 (`global_unstructured`)**
- **关键注意事项**
- **示例代码(完整流程)**
- 关于GeLU与ReLU激活的思考
- **1. ReLU vs. GeLU:行为对比**
- **2. 为什么GeLU更受青睐?**
- **(1) 平滑性改善训练动态**
- **(2) 近似生物学合理性**
- **(3) 在Transformer中的表现**
- **(4) 数值稳定性**
- **3. ReLU的剩余优势**
- **4. 为什么“增加复杂度”反而有效?**
- **5. 其他类似激活函数的趋势**
关于torch.nn.utils.prune中的剪枝方法
torch.nn.utils.prune 是 PyTorch 提供的模型剪枝工具模块,它包含多种预定义的剪枝方法,用于通过移除神经网络中的冗余权重来减少模型大小和计算量。以下是该模块中常见的剪枝方法及其特点:
1. 基础剪枝方法
(1) 随机剪枝 (RandomUnstructured)
- 作用:随机移除无结构化的权重(不考虑权重的位置)。
- 适用场景:全连接层、卷积层等任意参数矩阵。
- 示例:
prune.random_unstructured(module, name='weight', amount=0.3) # 剪枝30%权重
(2) 幅度剪枝 (L1Unstructured)
- 作用:按权重的 L1 幅度(绝对值)排序,移除最小的权重。
- 原理:认为绝对值小的权重对模型贡献较小。
- 示例:
prune.l1_unstructured(module, name='weight', amount=0.5) # 剪枝50%权重
2. 结构化剪枝
(1) 通道剪枝 (LnStructured)
- 作用:按通道(如卷积核的整个通道)剪枝,移除整个通道。
- 参数:
n指定范数类型(如 L1/L2),dim指定剪枝维度。 - 示例(剪枝卷积层的输出通道):
prune.ln_structured(module, name='weight', amount=0.2, n=2, dim=0) # L2范数剪枝20%通道
(2) 随机结构化剪枝 (RandomStructured)
- 作用:随机移除整个通道或滤波器。
- 示例:
prune.random_structured(module, name='weight', amount=0.3, dim=0)
3. 自定义剪枝
通过 prune.BasePruningMethod 可实现自定义剪枝策略。需重写 compute_mask 方法定义剪枝逻辑。
4. 全局剪枝 (global_unstructured)
- 作用:跨多个层全局剪枝,按统一标准(如权重大小)对所有参数剪枝。
- 优势:避免局部剪枝导致某些层过度稀疏。
- 示例:
parameters_to_prune = [(module1, 'weight'), (module2, 'weight')] prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.4)
关键注意事项
- 掩码机制:剪枝后,原始权重被存储为
weight_orig,并通过掩码weight_mask屏蔽被剪枝的权重。 - 永久化剪枝:使用
prune.remove永久删除掩码并应用剪枝:prune.remove(module, 'weight') - 序列化问题:剪枝后的模型需通过
state_dict保存掩码,加载时需重新应用剪枝。
示例代码(完整流程)
import torch.nn.utils.prune as prune# 定义模型
model = torch.nn.Linear(100, 10)# 应用L1剪枝(剪枝30%权重)
prune.l1_unstructured(model, name='weight', amount=0.3)# 检查剪枝后的权重(被剪枝部分为0)
print(model.weight)# 永久化剪枝
prune.remove(model, 'weight')
通过灵活组合这些方法,可以实现模型压缩、加速推理或研究网络鲁棒性。更多细节可参考 PyTorch官方文档。
关于GeLU与ReLU激活的思考
其实激活函数也可以视为一种剪枝对不对,只是常规剪枝剪的是模型的参数,而激活本身是剪的隐层的输出,比如ReLU会剔除掉负数的输出值,使得能够加速推理或者训练。那么为什么现在多用GeLU而不是用ReLU作为激活呢,GeLU在负数端会保留很小的输出,这样不是凭空增加了复杂度吗?
确实,从某种角度看,激活函数(如ReLU)可以被视为一种对隐层输出的“动态剪枝”,而传统的参数剪枝(如权重剪枝)是对模型参数的静态剪枝。两者的核心目标都是通过稀疏化来提升模型的效率或泛化能力。但为什么现代模型(如Transformer)更倾向于使用GeLU而非ReLU?这需要从数学性质、训练动态和实际效果等多方面分析。
1. ReLU vs. GeLU:行为对比
| 特性 | ReLU | GeLU |
|---|---|---|
| 数学形式 | max(0, x) | x * Φ(x)(Φ为标准正态CDF) |
| 负数端处理 | 完全截断(硬稀疏化) | 平滑衰减(软稀疏化) |
| 梯度行为 | 负数梯度为0,正数梯度为1 | 所有位置梯度连续非零 |
| 稀疏性 | 强(显式稀疏) | 弱(隐式稀疏) |
2. 为什么GeLU更受青睐?
(1) 平滑性改善训练动态
- ReLU的缺陷:在负数端梯度归零,导致“死神经元”(Dead ReLU Problem),尤其是初始化不佳或学习率过高时,部分神经元可能永远无法激活。
- GeLU的优势:负数端保留微小梯度(梯度接近但不为0),缓解神经元死亡问题,使训练更稳定。
(2) 近似生物学合理性
- GeLU的表达式(
x * Φ(x))可以理解为对神经元的“随机门控”效果(类似Dropout的思想),模拟了生物神经元的随机激活特性,理论上更具表达能力。
(3) 在Transformer中的表现
- 实验验证:在BERT、GPT等模型中,GeLU相比ReLU通常能带来更高的精度(如1-2%的提升)。这可能与Transformer的深层结构和自注意力机制有关:
- 自注意力层的输出分布更复杂,ReLU的硬截断可能丢失有用信息。
- GeLU的平滑性有助于梯度在多层的传播。
(4) 数值稳定性
- GeLU的连续性避免了ReLU在
x=0处的不可导问题(虽然实际中ReLU的次梯度仍可工作),这对某些理论分析更友好。
3. ReLU的剩余优势
尽管GeLU更流行,ReLU仍在以下场景有竞争力:
- 计算效率:ReLU的简单性在边缘设备上仍有速度优势。
- 显式稀疏性:当需要严格的输出稀疏性时(如某些压缩场景),ReLU更直接。
- 浅层网络:在参数量较小的模型中,ReLU的表现可能与GeLU相当。
4. 为什么“增加复杂度”反而有效?
GeLU在负数端保留微小值看似增加了计算负担,但实际收益来自:
- 梯度信号保留:避免训练时的信息损失,尤其对深层网络至关重要。
- 模型容量:微小的负数端响应可能携带对下游任务有用的信息(如区分“轻微负面”和“强烈负面”特征)。
- 现代硬件优化:虽然GeLU计算比ReLU复杂,但GPU/TPU对这类激活函数有专门优化,实际耗时差距不大。
5. 其他类似激活函数的趋势
类似GeLU的平滑激活函数(如Swish、Mish)也表现出优于ReLU的效果,进一步验证了:
- 硬稀疏化(如ReLU)并非最优:适度的平滑性和梯度保留能提升深层网络的训练效果。
- 动态稀疏比静态稀疏更灵活:GeLU的“软剪枝”允许模型根据输入动态调整稀疏模式,而参数剪枝是静态的。
总结:
- ReLU:像“硬剪枝”,高效但可能导致信息损失和训练不稳定。
- GeLU:像“软剪枝”,通过保留微小信号改善训练动态和模型表现,尤其在深层网络中优势明显。
- 选择依据:模型深度、硬件条件、任务需求(如是否需要严格稀疏性)是关键因素。当计算资源允许时,GeLU通常是更优解。