【HDFS入门】数据存储原理全解,从分块到复制的完整流程剖析
目录
1 HDFS架构概览
2 文件分块机制
2.1 为什么需要分块?
2.2 块大小配置
3 数据写入流程
4 数据复制机制
4.1 副本放置策略
4.2 复制流程
5 数据读取流程
6 一致性模型
7 容错机制
7.1 数据节点故障处理
7.2 校验和验证
8 总结
在大数据时代,Hadoop分布式文件系统(HDFS)作为Hadoop生态系统的存储基石,其高效可靠的数据存储机制为海量数据处理提供了坚实基础。本文将深入剖析HDFS的数据存储原理,从文件分块到数据复制的完整流程,以全面理解HDFS的核心工作机制。
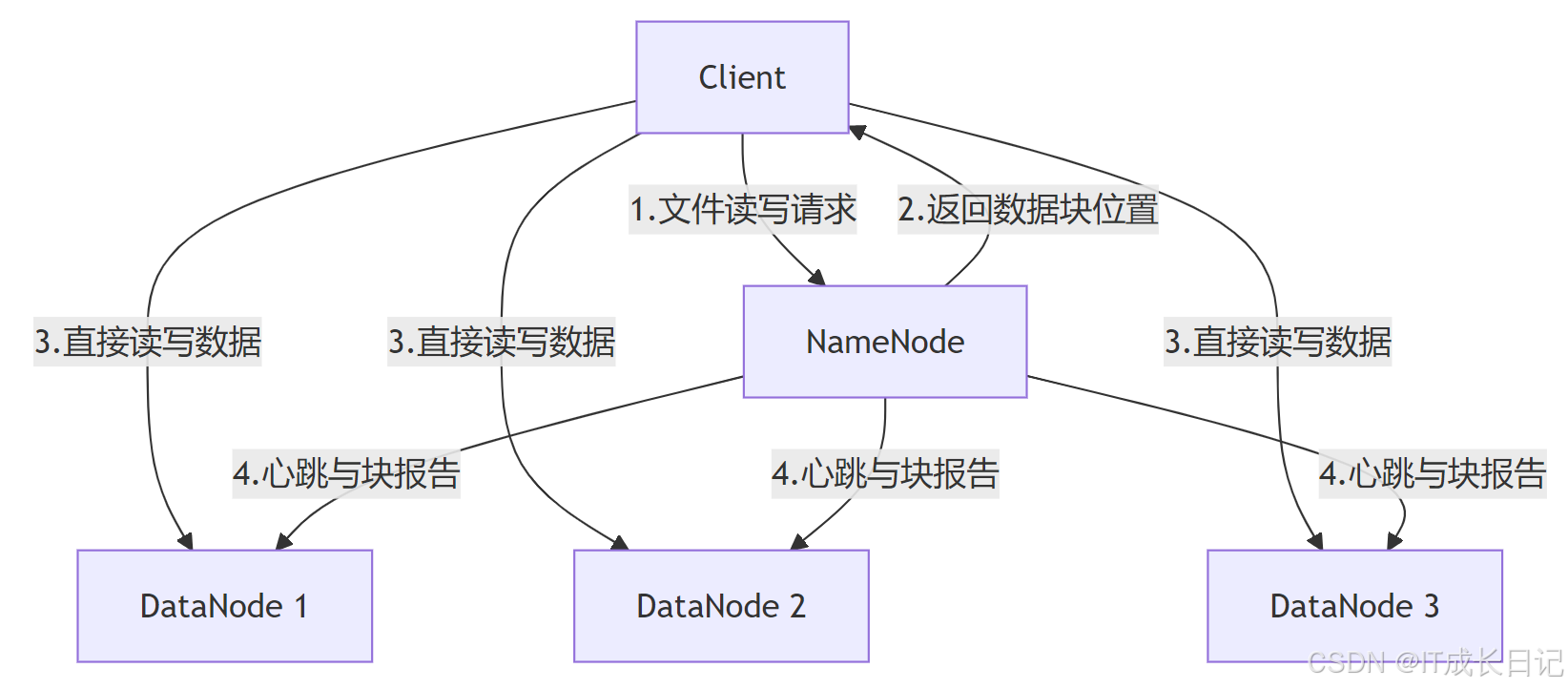
1 HDFS架构概览
HDFS采用主从(Master/Slave)架构设计,主要由以下两个核心组件构成:
- NameNode:主服务器,负责管理文件系统的命名空间和客户端对文件的访问
- DataNode:集群中的工作节点,负责存储实际的数据块
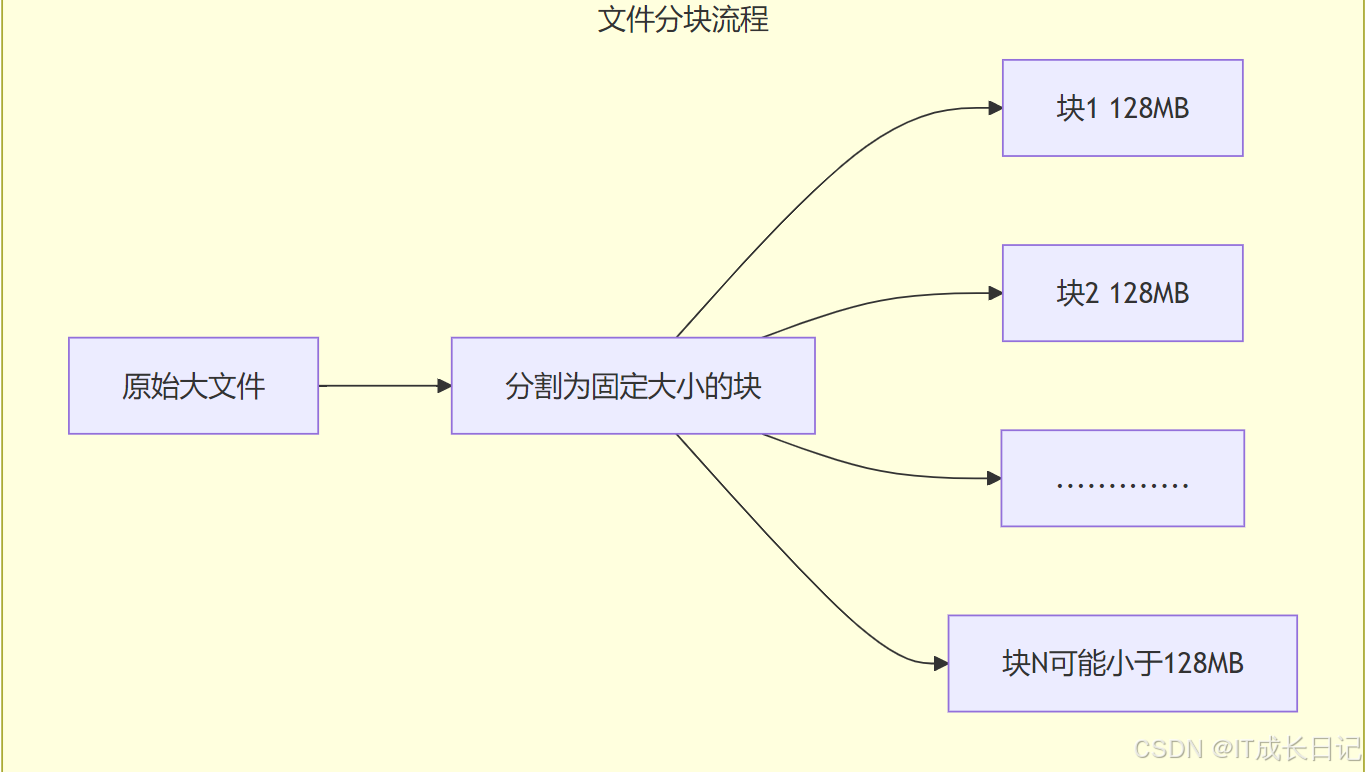
2 文件分块机制
2.1 为什么需要分块?
HDFS设计用于存储超大文件,典型文件大小从GB到TB级别。将大文件分割成固定大小的块(Block)带来以下优势:
- 简化存储子系统设计
- 便于容错和故障恢复
- 优化大规模数据处理
2.2 块大小配置
HDFS默认块大小为128MB(可配置),远大于传统文件系统的块大小(通常4KB),这种设计减少了寻址开销,适合大数据场景。
3 数据写入流程
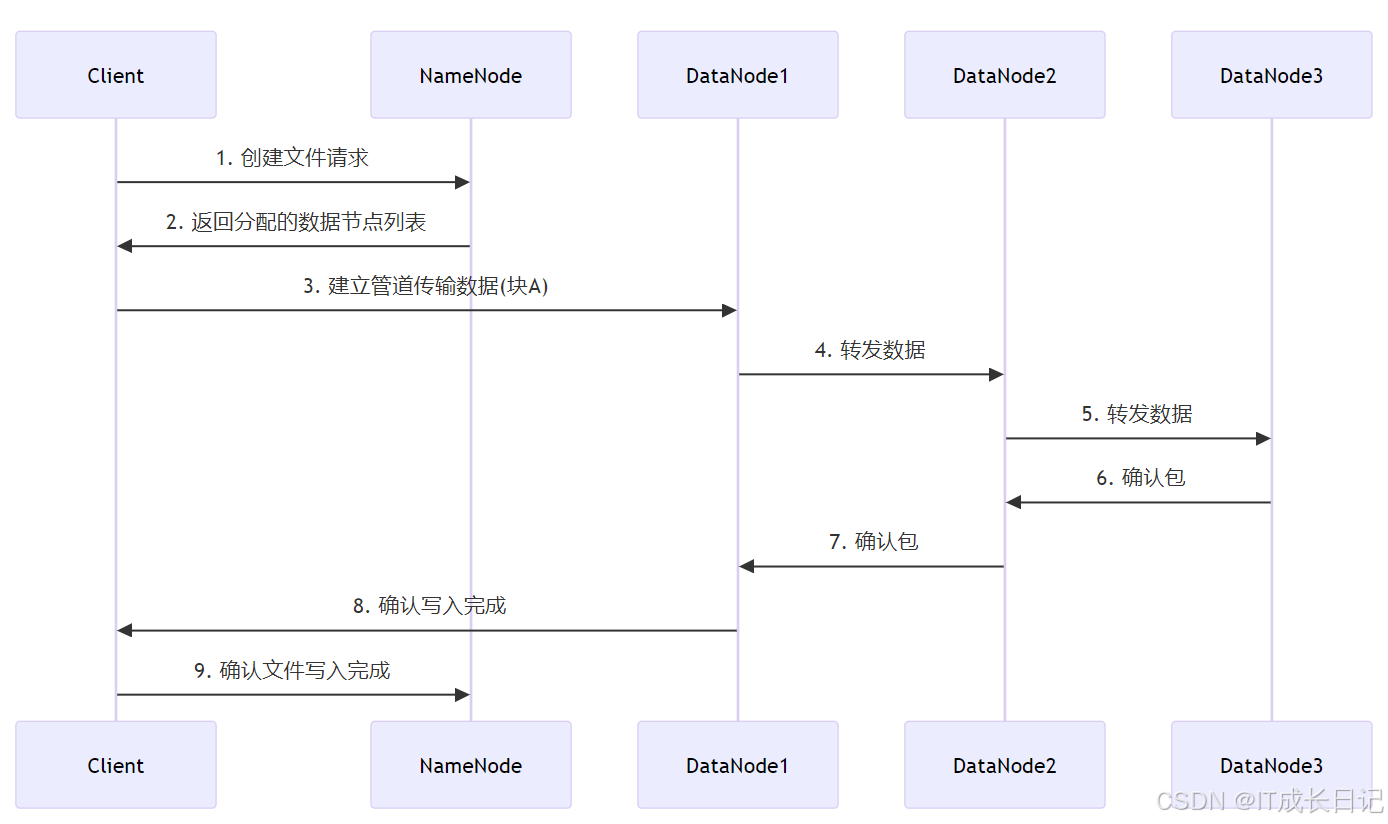
- 客户端向NameNode发起创建文件请求
- NameNode验证权限后,在命名空间中创建文件条目,并返回适合写入的数据节点列表
- 客户端与第一个DataNode建立连接开始传输数据
- 数据沿管道(pipeline)顺序传输到所有副本节点
- 确认信息沿管道反向传回客户端
- 完成所有块写入后,客户端通知NameNode完成文件写入
4 数据复制机制
4.1 副本放置策略
HDFS采用智能的副本放置策略来平衡可靠性与性能:
- 第一个副本:优先写入客户端所在的节点(若客户端在集群外,则随机选择)
- 第二个副本:放置在不同机架的节点上
- 第三个副本:放置在与第二个副本相同机架的不同节点上
4.2 复制流程
当检测到副本数量不足时,HDFS会自动触发复制过程:

5 数据读取流程
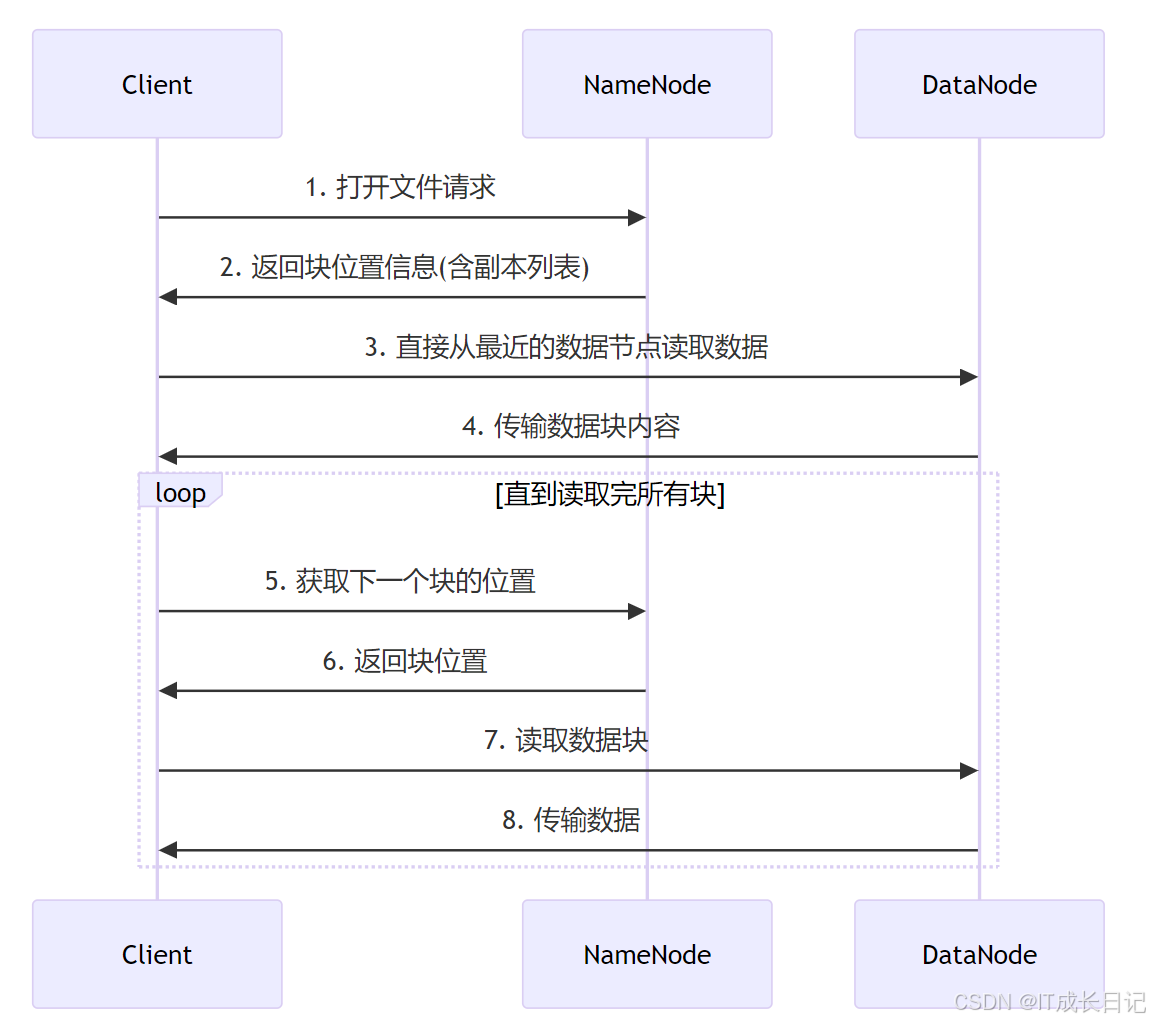
- 客户端向NameNode请求文件块位置信息
- NameNode返回包含该文件所有块位置(按与客户端网络拓扑距离排序)
- 客户端直接从最近的DataNode读取数据
- 读取完成后关闭流
6 一致性模型
HDFS采用"一次写入多次读取"(Write-Once-Read-Many)模型:
- 文件一旦创建、写入并关闭后就不能修改
- 支持追加写入(需要显式配置)
- 正在写入的文件对其他客户端不可见,直到关闭

7 容错机制
7.1 数据节点故障处理
- 心跳检测:DataNode定期(默认3秒)向NameNode发送心跳
- 块报告:DataNode定期发送其存储的块列表
- 故障判定:NameNode若10分钟未收到心跳,则判定节点失效
- 副本复制:NameNode触发副本不足块的复制

7.2 校验和验证
HDFS使用校验和(Checksum)确保数据完整性:
- 默认每512字节数据生成一个32位校验和
- 读取时验证校验和
- 发现损坏时从其他副本读取并修复
8 总结
HDFS通过分块存储、智能复制和机架感知等机制,实现了高吞吐量、高可靠性的海量数据存储。理解这些核心原理对于优化Hadoop集群性能、解决存储相关问题至关重要。