教程:批量提取图片pdf固定位置文字然后保存为新的文件名,基于Python和阿里云的实现方案
一、项目背景
在实际工作和生活中,存在大量需要对图片或 PDF 进行批量处理的场景。例如,在档案管理中,工作人员可能会扫描大量文件,生成图片或 PDF 格式的档案资料。这些资料通常包含特定位置的关键信息,如文件编号、日期等。通过批量提取这些关键信息并将其作为文件名,可以方便后续的检索和管理。在金融行业,银行可能会收到大量客户的合同文件,这些文件以图片或 PDF 形式保存,通过提取合同编号等关键信息来重命名文件,能提高文件管理的效率。

二、界面设计
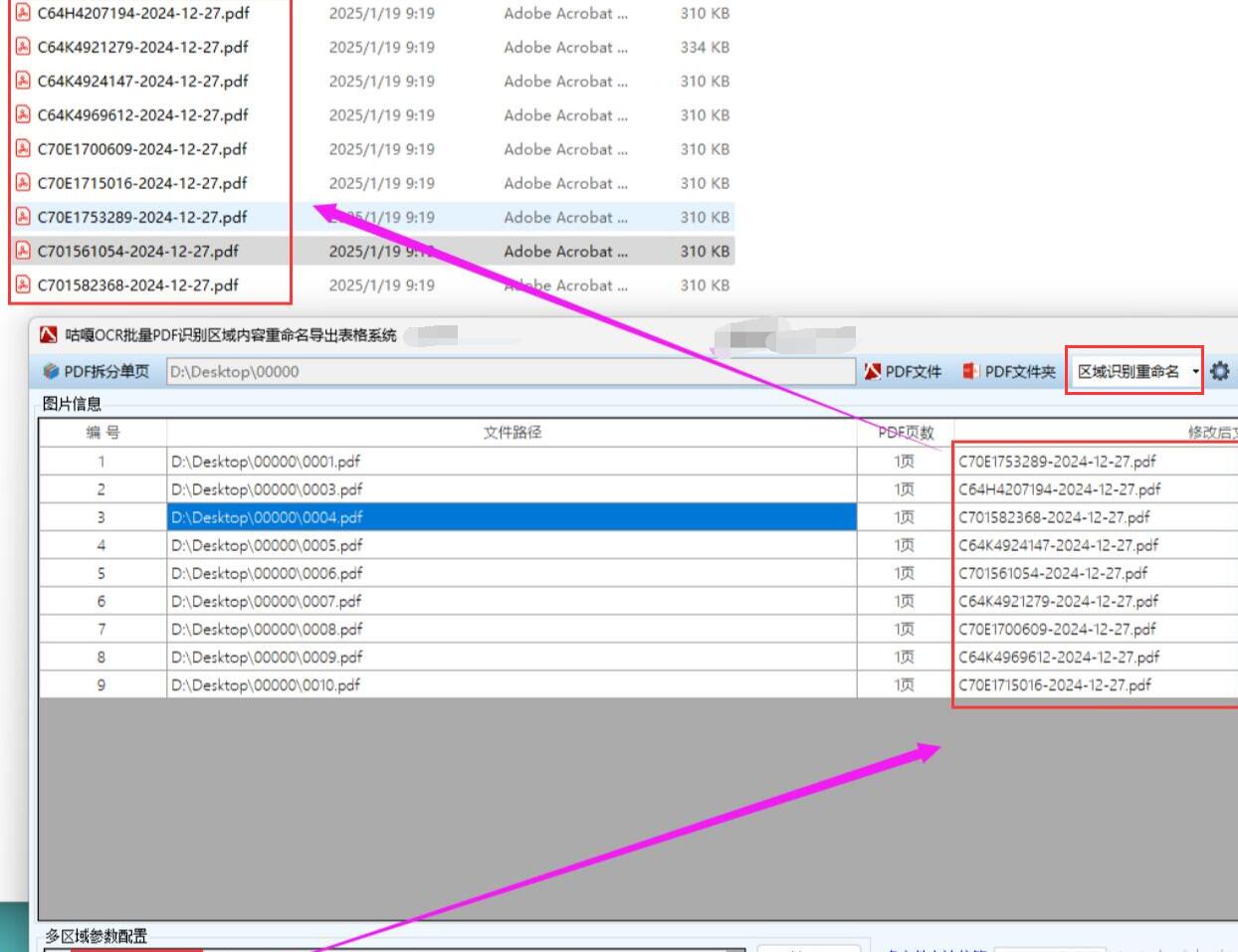
可以设计一个简单的图形用户界面(GUI),使用 Python 的 tkinter 库来实现。界面包含以下元素:
- 文件选择按钮:点击后弹出文件选择对话框,允许用户选择要处理的图片或 PDF 文件。
- 位置输入框:用于输入要提取文字的固定位置,格式可以是
x,y,width,height,表示矩形区域的左上角坐标和宽高。 - 阿里云配置输入框:输入阿里云 OCR 服务的 AccessKey ID 和 AccessKey Secret。
- 处理按钮:点击后开始对选择的文件进行处理。
- 进度条:显示处理进度。
- 日志文本框:显示处理过程中的日志信息,如成功提取的文字、重命名的文件名等。
三、详细代码步骤
1. 安装必要的库
需要安装 aliyun-python-sdk-core、aliyun-python-sdk-ocr、