Elasticsearch 8.18 中提供了原生连接 (Native Joins)
作者:来自 Elastic Costin Leau
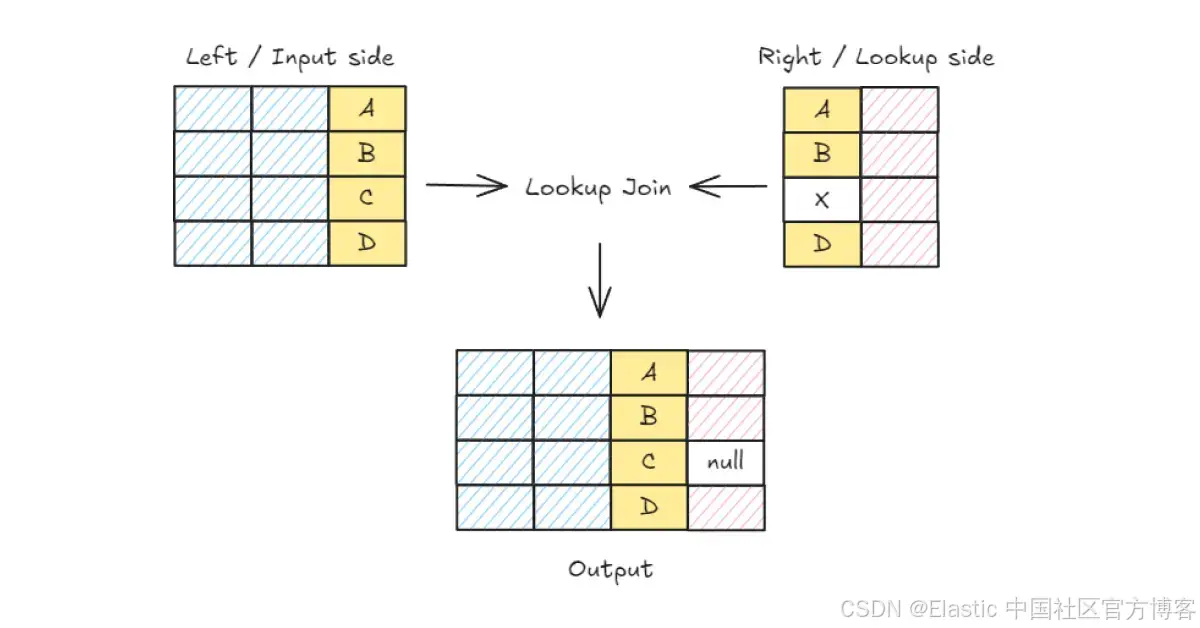
探索 LOOKUP JOIN,这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令。
很高兴宣布 LOOKUP JOIN —— 这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令,旨在执行左 joins 以进行数据增强。通过 ES|QL,用户可以根据定义如何在 Elasticsearch 中本地配对文档的标准,将来自一个索引的文档与来自另一个索引的文档查询和组合。这种方法通过在查询时动态关联跨多个索引的文档,从而减少了重复数据,提高了数据管理效率。
例如,以下查询将来自一个索引的员工数据与另一个索引中对应的部门信息连接,使用共享的字段键名称:
FROM employees
| LOOKUP JOIN departments ON dep_id正如其名称所示,LOOKUP JOIN 在查询时执行一个补充的或左(外部)连接,连接任何常规索引(employees 索引)—— 左侧和任何查找索引(departments 索引)—— 右侧。左侧的所有行将与右侧的相应行(如果有的话)一起返回。
查找侧的索引模式必须设置为 lookup。这意味着底层索引只能有一个分片。当前的解决方案解决了连接一侧的基数挑战,以及像 Elasticsearch 这样的分布式系统所遇到的问题,这些问题将在下一节中详细说明。
除了使用 lookup 索引模式外,对源数据或使用的命令没有限制。此外,无需进行数据准备。
连接可以在过滤之前或之后执行:
// associate employees hired in the last year in departments in US and sort by department name
FROM employees
| WHERE hire_date > now() - 1 year
| LOOKUP JOIN departments ON dep_id
| WHERE dep_location == "US"
| KEEP last_name, dep_name, dep_location
| SORT dep_name与聚合混合使用:
// count employees per country
FROM employees
| STATS c = COUNT(*) BY country_code
| LOOKUP JOIN countries ON country_code
| KEEP c, country_name
| SORT country_name或与另一个 join 结合使用:
// find the error messages in the last hour alongside their source host name and error description
FROM logs
| WHERE message_type :"error"
| LOOKUP JOIN message_types ON err_code
| LOOKUP JOIN host_to_ips ON src_ip
| WHERE log_date > now() - 1 hour
| KEEP log_date, log_type, err_description, host_name执行 Lookup Join
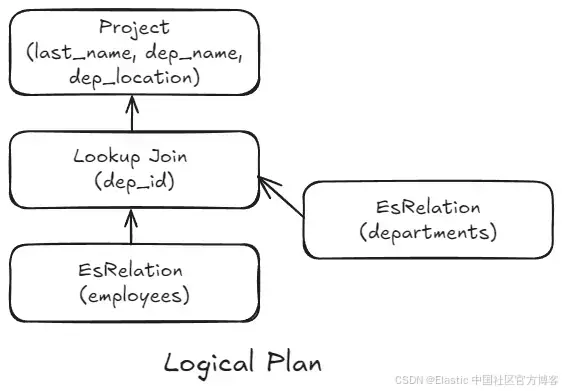
让我们通过查看一个不包含其他命令(如 filter)的基本查询来说明运行时会发生什么。这将使我们能够专注于执行阶段,而不是规划阶段。
FROM employees
| LOOKUP JOIN departments ON dep_id
| KEEP last_name, dep_name, dep_location逻辑计划(logical plan)是一个表示数据流和必要转换的树状结构,是上述查询翻译后的结果。这个逻辑计划以查询的语义为核心。
为了确保高效扩展,标准的 Elasticsearch 索引会被分成多个分片,并分布在整个集群中。在 join 场景中,如果左侧 (L) 和右侧 (R) 都进行分片,将会产生 L*R 个分区。为了尽量减少数据移动的需求,lookup join 要求右侧(提供增强数据的一方)只有一个分片,类似于 enrich 索引,其副本数量由索引设置决定(默认是 1)。
这减少了执行 join 所需的节点数量,从而缩小了问题空间。因此,LR 变为 L1,也就是 L。
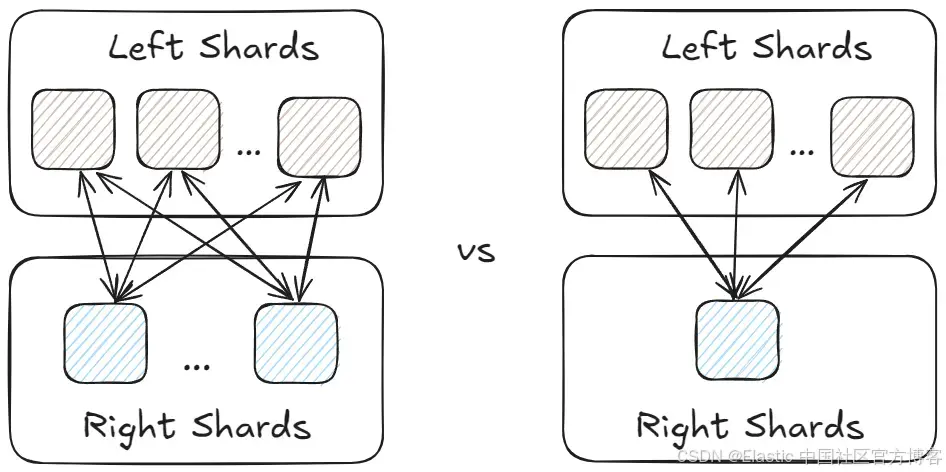
因此,协调节点只需将计划分发到左侧的数据节点,在本地使用 lookup(右侧)索引执行 hash join,通过右侧构建底层哈希映射,而左侧则用于批量 “探测” 匹配的键。
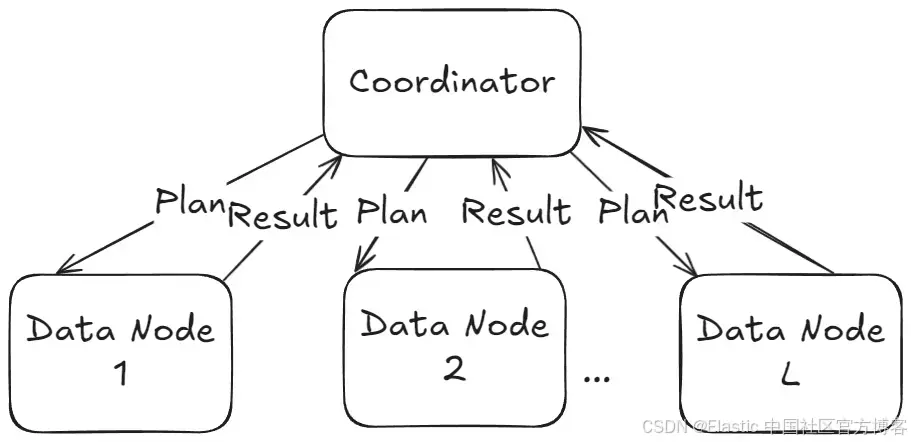
生成的分布式物理计划(physical plan),专注于查询的分布式执行,结构如下:
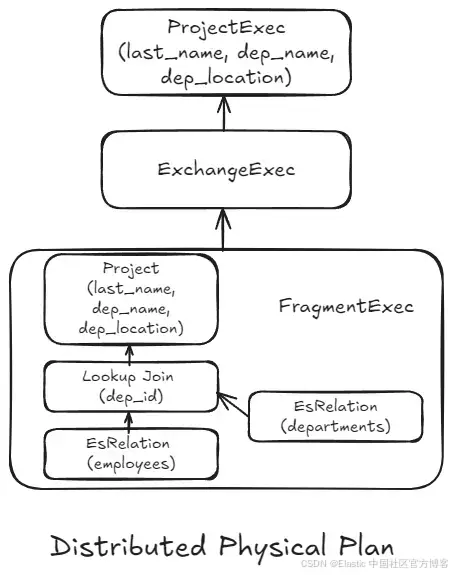
该计划由两个主要部分或子计划组成:一个是在协调节点上执行的物理计划(通常是接收并负责完成查询的节点),另一个是计划片段,在数据节点(存储数据的节点)上执行。由于协调节点本身不包含数据,它会将一个计划片段发送到相关的数据节点进行本地执行。执行结果随后会返回给协调节点,由其计算最终结果。
两个实体之间的通信通过 Exchange 块在计划中表示。对于这个查询来说,协调节点的工作量不大,因为大部分处理都发生在数据节点上。
该片段封装了逻辑子计划,从而可以根据每个分片数据的具体特性进行优化(例如缺失字段、本地的最小值和最大值)。这种本地重新规划还有助于在节点间或节点与协调节点之间的代码存在差异(例如在集群升级期间)时进行管理。
本地物理计划(local physical plan)大致如下:
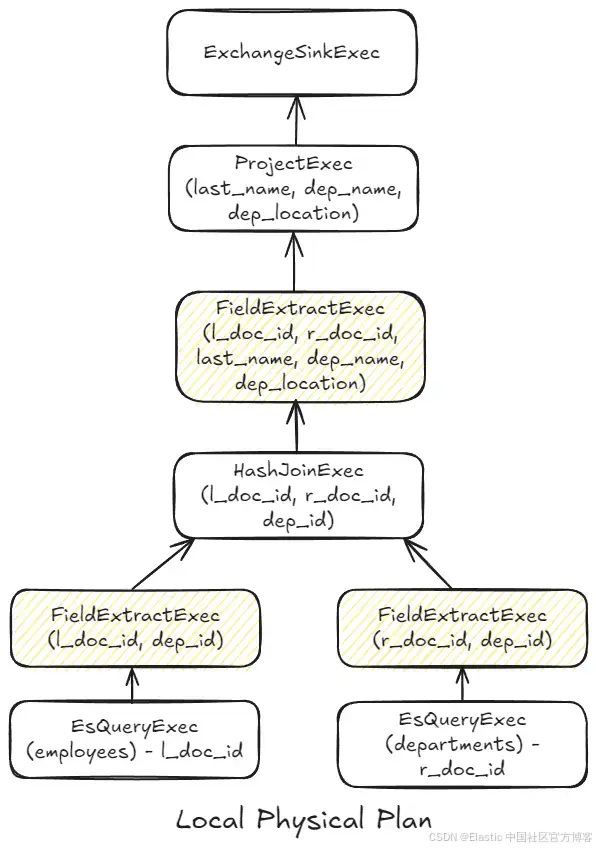
该计划旨在通过高效的数据提取方式减少 I/O。树底部的两个节点作为根节点,为上层节点提供数据。每个节点输出对底层 Elasticsearch 文档(doc_id)的引用。这种设计是有意为之,用于尽可能延迟加载列(字段)或文档,直到通过指定的提取节点(图中为黄色)进行处理。在这个特定的计划中,加载操作发生在执行每一侧 hash join 之前,以及最终 project 操作之前,此时仅使用 join 后的结果数据将其输出到节点之外。
未来工作
限定符 - Qualifiers
目前,lookup join 的语法要求两个表中的键名称相同(类似于某些 SQL 方言中的 JOIN USING)。这个限制可以通过 RENAME 或 EVAL 来解决:
FROM employees_new
| RENAME dep AS dep_id // align the names of the group key
| LOOKUP JOIN departments ON dep_id这是一个不必要的不便,我们正在通过引入(源)限定符在不久的将来解决这个问题。
之前的查询可以重写为(语法正在开发中):
FROM employees_new e
| LOOKUP JOIN departments ON e.dep == departments.dep_id请注意,join key 被替换为一个等式比较,其中每一侧都使用字段名称限定符,限定符可以是隐式的(departments)或显式的(e)。
更多连接类型和性能
我们目前正在改进 lookup join 算法,以更好地利用数据拓扑,专注于利用 Lucene 中的底层搜索结构和统计信息进行数据跳过的优化。
从长远来看,我们计划支持更多的连接类型,如内连接(或交集,结合两侧具有相同字段的文档)和全外连接(或并集,即使没有共同键,也结合两侧的文档)。
反馈
Elasticsearch 对原生 JOIN 支持的道路漫长,追溯到 0.90 版本。早期的尝试包括 nested 和 _parent 字段类型,后者最终在 2.0 版本中被重写,在 5.0 版本中被弃用,并在 6.0 版本中由 join 字段替代。
更近期的功能,如 Transforms(7.3)和 Enrich 数据摄取管道(7.5)也旨在解决类似连接的用例。在更广泛的 Elasticsearch 生态系统中,Logstash 和 Apache Spark(通过 ES-Hadoop 连接器)提供了替代解决方案。Elasticsearch SQL,自 6.3.0 版本推出以来,也值得一提,因为其语法相似:虽然它支持广泛的 SQL 功能,但原生 JOIN 支持一直没有实现。
所有这些解决方案都有效并继续得到支持。然而,我们认为,ES|QL 由于其查询语言和执行引擎,显著简化了用户体验!
ESQL Lookup join 目前处于技术预览阶段,在 Elasticsearch 8.18 和 Elastic Cloud 中免费提供 —— 试试看,并告诉我们它对你有何帮助!
Elasticsearch 拥有众多新功能,帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本,开始免费云试用,或立即在本地机器上试用 Elastic。
原文:Native joins available in Elasticsearch 8.18 - Elasticsearch Labs