3D版的VLA:从3D VLA、SpatialVLA到PointVLA——3D点云版的DexVLA,在动作专家中加入3D数据
前言
之前写这篇文章的时候,就想解读下3D VLA来着,但一直因为和团队并行开发具身项目,很多解读被各种延后
更是各种出差,比如从25年3月下旬至今,连续出差三轮,绕中国半圈,具身占八成
- 第一轮 珠三角,长沙出发,深圳 广州/佛山
- 第二轮 京津冀及山东,长沙出发,保定 北京 济南 青岛
- 第三轮 长三角,青岛出发,上海 南京 今天下午回到长沙
而出差过程中接到的多个具身订单中,有一个人形开发订单涉及要遥操,而3D版的VLA也是一种备选方案「详见此文《从宇树摇操avp_teleoperate到unitree_IL_lerobot:如何基于宇树人形进行二次开发》的开头」
故回到长沙后,便准备解读下3D VLA来了,但既然解读3D VLA了,那就干脆把相关3D版本的VLA一并解读下——特别是PointVLA 且我顺带建了一个PointVLA的复现落地群,欢迎私我一两句简介 以加入
如此,便有了本文
第一部分 3D VLA
第二部分 SpatialVLA
// 待更
第三部分 PointVLA: 将三维世界引入视觉-语言-动作模型
3.1 提出背景与相关工作
25年3.10日,来自1Midea Group、2Shanghai University、3East China Normal University等机构的研究者们提出了PointVLA
这个团队的节奏还挺快的,他们在过去半年多还先后发布了TinyVLA、Diffusion-VLA、DexVLA
| TinyVLA | 24年9月 | 1. Midea Group 2. East China Normal University 3. Shanghai University 4.Syracuse University 5. Beijing Innovation Center of Humanoid Robotics | Junjie Wen1,∗ , Yichen Zhu2,∗,† , Jinming Li3 , Minjie Zhu1 , Kun Wu4 , Zhiyuan Xu5 , Ning Liu2 , Ran Cheng2 , Chaomin Shen1,† , Yaxin Peng3 , Feifei Feng2 , and Jian Tang5 |
| Diffusion-VLA | 24年12月 | 1 East China Normal University, 2 Midea Group, 3 Shanghai University | Junjie Wen1,2,∗, Minjie Zhu1,2,∗, Yichen Zhu2,†,*, Zhibin Tang2, Jinming Li2,3, Zhongyi Zhou1,2,Chengmeng Li2,3, Xiaoyu Liu2,3, Yaxin Peng3, Chaomin Shen1, Feifei Feng2 |
| DexVLA | 25年2月 | 1 Midea Group 2 East China Normal University | Junjie Wen12∗ Yichen Zhu1∗† Jinming Li1 Zhibin Tang1 Chaomin Shen2, Feifei Feng1 |
| PointVLA | 25年3月 | 1 Midea Group 2 Shanghai University 3 East China Normal University | Chengmeng Li1,2,∗ Yichen Zhu1,∗,† Junjie Wen3 Yan Peng2 Yaxin Peng2,† Feifei Feng1 |
3.1.1 引言
如原论文中所说,机器人基础模型,特别是视觉-语言-动作(Vision-Language-Action,VLA)模型[4, 5, 25, 45, 46],在使机器人能够感知、理解和与物理世界交互方面展现了卓越的能力
- 这些模型利用预训练的视觉-语言模型(VLMs)[3, 8, 20, 30, 42] 作为处理视觉和语言信息的骨干,将其嵌入到一个共享的表示空间中,并随后将其转化为机器人动作
这个过程使机器人能够以有意义的方式与其环境交互 - VLA 模型的强大性能在很大程度上依赖于其训练数据的规模和质量。例如,Open-VLA[25] 使用4k 小时的开源数据集进行训练,而更先进的模型如π0 则利用10k 小时的专有数据,从而显著提升了性能
- 除了这些大规模的基础模型外,许多项目还通过物理机器人上的真实人类演示收集了大量数据集。例如,AgiBot-World[6] 发布了一个包含数百万条轨迹的大型数据集,展示了复杂的人形交互
然,大多数现有的机器人基础模型[4, 5, 21, 25, 46]都是基于二维视觉输入进行训练的[23, 35]。这构成了一个关键的局限性,因为人类感知和与世界互动是在三维空间中进行的。训练数据中缺乏全面的三维空间信息阻碍了机器人对其环境形成深刻理解的能力。可这,对于那些需要精确的空间感知、深度感知和物体操作的任务来说,这一点尤其关键
对此,他们提出了PointVLA,一种将点云集成到预训练的视觉-语言-动作模型中的新框架
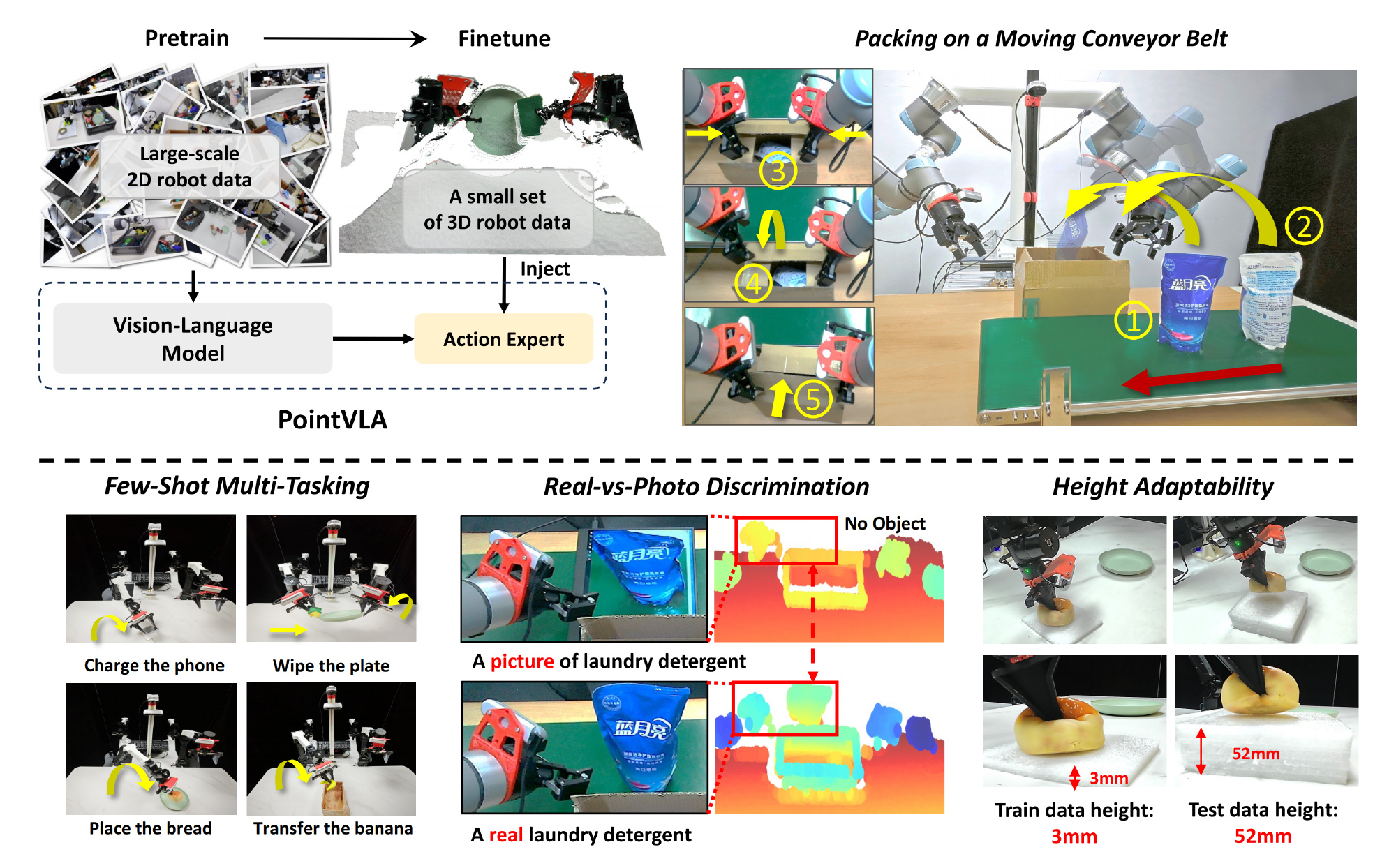
- 且考虑到新的3D机器人数据显著少于预训练的2D数据。在这种情况下,关键是不要破坏已建立的2D特征表示。故他们提出了一个3D模块化块,该块将点云信息直接注入到动作专家中
如此,通过保持视觉-语言骨干网络的完整性,确保了2D视觉-文本嵌入的保留——并仍然是可靠的信息来源 - 此外,他们力求将对动作专家特征空间的干扰降到最低。通过跳跃块分析,他们确定了测试时不太关键的层,即让动作专家中这些“用处较小”层的特征嵌入更适应新模态。在确定了这些较不重要的块后,他们通过加性方法注入提取的3D特征
3.1.2 相关工作
对于视觉-语言-动作模型
近年来的研究越来越多地关注于开发基于大规模机器人学习数据集训练的通用机器人策略[11,14,23,27,35]。视觉-语言-动作(VLA)模型已经成为训练此类策略的一种有前途的方法[4,9,12,13,24,33,36,40,45,46,48,54,55]。VLA扩展了视觉-语言模型(VLM)——这些模型通过基于互联网规模的大型图像和文本数据集进行预训练[1,8,20,28–30,42,53,58,59]——以实现机器人控制[44]
毕竟这种方法提供了几个关键优势:
- 利用大规模具有数十亿参数的视觉-语言模型骨干能够从大量的机器人数据集中进行有效学习
- 同时重用来自互联网规模数据的预训练权重增强了视觉-语言代理(VLAs)理解多样化语言指令以及对新颖物体和环境的泛化能力,使它们在实际机器人应用中具有高度适应性。机器人学习与三维模态
在三维场景中学习鲁棒的视觉运动策略[7,15–17,19,22,37,39,41,49–52]是机器人学习中的一个重要领域
- 现有方法如3DVLA[17]提出了综合框架,将多样化的三维任务(如泛化、视觉问答(VQA)、三维场景理解和机器人控制)整合到统一的视觉-语言-动作模型中
然而,3DVLA的一个局限性是其在机器人控制实验中依赖模拟,这导致了显著的模拟到真实的差距 - 其他研究,如3D扩散策略[51],表明使用外部三维输入(例如来自外部摄像机)可以提高模型对不同光照条件和对象属性的泛化能力
iDP3[50] 则进一步增强了三维视觉编码器并将其应用于人形机器人,在具有自我视角和外部摄像机视角的多样环境中实现了鲁棒性能 - 然而,丢弃现有的二维机器人数据或者完全用新增的三维视觉输入重新训练基础模型,将会耗费大量的计算资源
However, discarding existing 2D robot data or completely retraining the founda-tion model with added 3D visual input would be computa-tionally expensive and resource-intensive.
一个更实用的解决方案是开发一种方法,将三维视觉输入作为补充知识源集成到经过良好预训练的基础模型中,从而在不影响训练模型性能的情况下获得新模态的好处
3.1.3 预备知识:PointVLA相当于3D点云版的DexVLA
VLA的强大源于其底层的VLM,这是一个经过海量互联网数据训练的强大骨干网络。这种训练使得图像和文本表示能够在共享的嵌入空间中实现有效对齐
VLM作为模型的“头脑”,处理指令和当前视觉输入以理解任务状态。随后,一个“动作专家”模块将VLM的状态信息转化为机器人动作
而PointVLA构建于DexVLA [46]的基础上
- DexVLA采用了一个具有20亿参数的Qwen2-VL [2,43]视觉语言模型(VLM)作为其主干,以及一个具有10亿参数的ScaleDP [57](一种扩散策略变体)作为其动作专家
- DexVLA经历了三个训练阶段:
一个为期100小时的跨实体训练阶段(阶段1),随后是实体特定训练(阶段2),以及一个可选的针对复杂任务的任务特定训练(阶段3)
所有三个阶段都使用2D视觉输入。尽管这些VLA模型在多样化的操作任务中表现出色,但它们对2D视觉的依赖限制了它们在需要3D理解的任务中的表现,例如通过照片进行物体欺骗或在不同桌子高度之间的泛化
3.2 将点云注入到VLA中
3.2.1 3D点云注入器的整体架构
如之前所述,VLA模型通常在大规模二维机器人数据集上进行预训练。一个关键的观察是支撑他们方法的核心是现有2D预训练语料库与新兴3D机器人数据集之间数据规模的固有差异
- 具体而言,他们认为3D传感器数据(例如点云、深度图)的体量相比于2D视觉-语言数据集小了几个数量级,这是由于机器人研究历史上对2D感知的广泛关注所致。这种差异需要一种方法,既能保留从2D预训练中学习到的丰富视觉表示,又能有效整合稀疏的3D数据
- 一种解决这一挑战的简单策略是直接将3D视觉输入转换为3D视觉token,并将其融合到大型语言模型(LLM)中——这种方法已被许多3D VLM采用,例如LLaVA-3D [56]
然而,目前的视觉-语言模型在小规模3D数据集上微调时表现出有限的3D理解能力,这一局限性由两个因素加剧:
- 2D像素与3D几何结构之间的显著领域差异
- 以及与图像 - 文本和纯文本语料库的丰富相比,高质量的 3D 文本配对数据十分稀缺
为了解决这些问题,他们提出了一种范式,将3D点云数据视为补充的条件信号,而不是主要的输入模式。这种策略将3D处理与核心的2D视觉编码器分离,从而在保留预训练的2D表示完整性的同时,使模型能够利用几何线索
且通过设计,他们的方法减轻了对2D知识的灾难性遗忘,并降低了对有限3D数据过拟合的风险。点云注入器的模型架构
点云注入器的整体架构如下图图2(右)所示
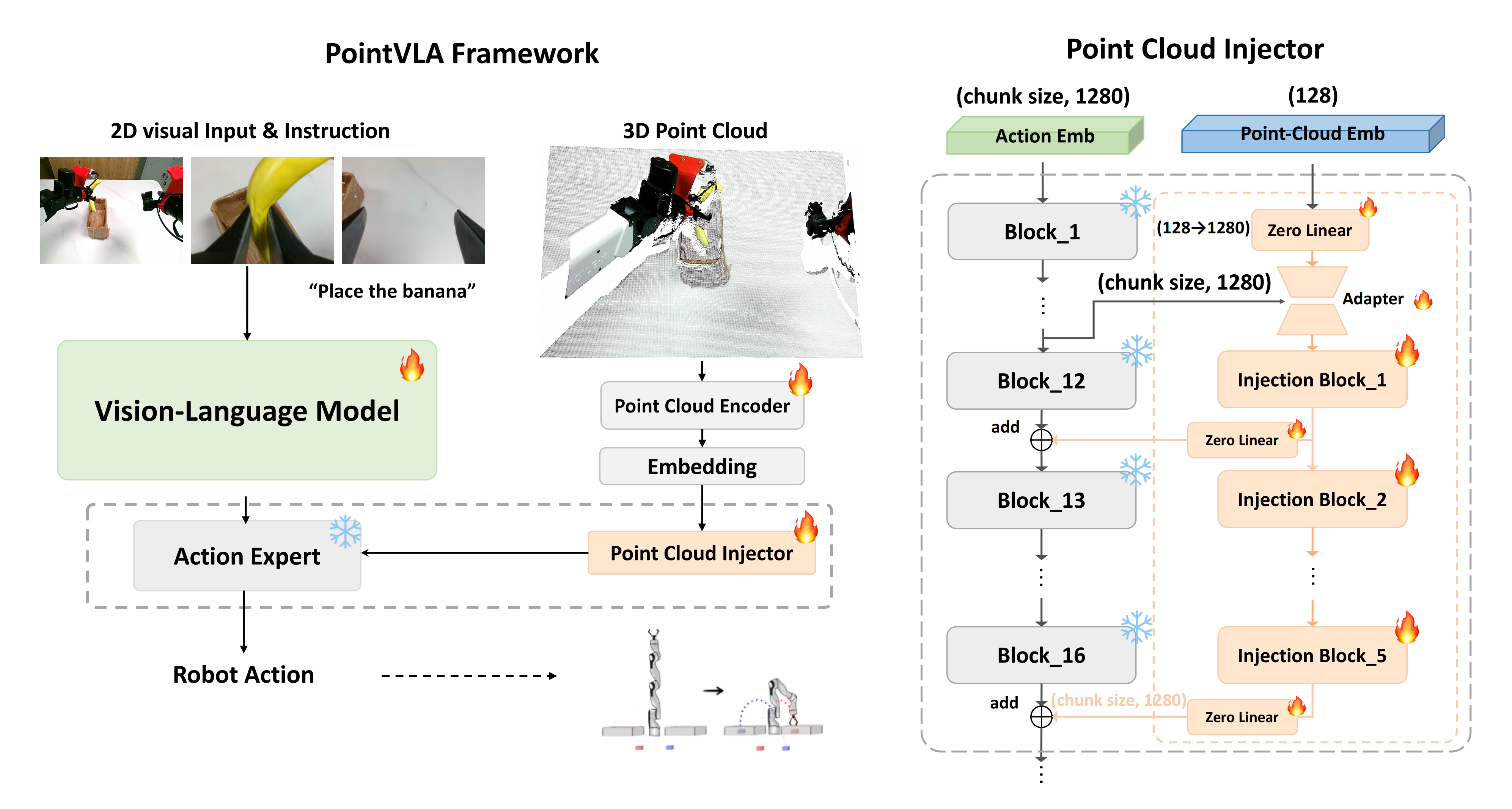
- 具体来说,对于传入的点云嵌入,他们首先将通道维度转换以匹配基础动作专家的通道维度。由于点云的动作嵌入可能较大——具体取决于块大小,他们设计了一个动作嵌入瓶颈来压缩动作专家的信息,同时使其与3D点云嵌入对齐
即Since the action embeddingfrom the point cloud can be large, depending on the chunksize, we design an action embedding bottleneck to compressthe information from the action expert while aligning it withthe 3D point cloud embedding. - 对于动作专家中的选定块,他们首先为每个块应用一个MLP层作为适配器,然后通过加法操作将点云嵌入注入到模型中
值得注意的是,他们会避免将3D特征注入到动作专家的每个块中,主要有两个原因
首先,由于所需的条件块,计算成本将高得无法接受
其次,注入不可避免地会改变受影响块的模型表示
鉴于此,他们的目标是尽量减少有限的 3D 视觉知识对源自 2D 视觉输入的预训练动作嵌入的干扰,故他们进行了分析以确定在推理过程中可以跳过的模块,同时又不影响性能
最后,他们仅将 3D 特征注入到这些不太关键的模块中
3.2.2 点云编码器
与DP3 [51] 和iDP3 [50] 中的观察一致,他们也发现预训练的3D视觉编码器会阻碍性能,通常会阻止在新环境中成功学习机器人行为
- 因此,他们采用了一种简化的分层卷积架构。上层卷积层提取低级特征,而下层卷积块学习高级场景表示。在层之间采用最大池化以逐渐减少点云密度
- 最后,再将特征进行拼接。从每个卷积块中提取的特征嵌入被整合为一个统一的嵌入,封装了多层次的三维表示知识。提取的点云特征嵌入被保留以供后续使用
总之,该架构与iDP3编码器相似。当然了,他们认为,采用更先进的点云编码器可能会进一步提高模型性能
3.2.3 在哪些块注入点云?跳过块分析
如前所述,将点云注入动作专家的每个模块并不理想,因为这会增加计算成本并扰乱从大量2D 基于视觉的机器人数据中学习到的原始动作表示
因此,他们分析了动作专家中哪些模块不太关键——即在推理过程中可以跳过而不影响性能的模块。这个方法在概念上与图像生成、视觉模型和大型语言模型中使用的技术一致[10,18, 26, 38]
- 具体来说,我们使用DexVLA [46] 中的折衬衫任务作为分析的案例研究。请注意,DexVLA 配备了一个包含10 亿参数的动作专家,具有32 个扩散transformer模块
评估遵循相同的指标:平均得分,这是一个长时任务的标准度量[4, 31, 46]——通过将任务分为多个步骤并根据步骤完成情况评估性能 - 他们首先每次跳过一个模块,并在下图中总结了他们的发现
实验表明,前11个模块对模型至关重要——跳过任何一个模块都会导致性能显著下降。特别是,当跳过11层之前的模块时夹具无法紧密闭合,使得模型难以完成任务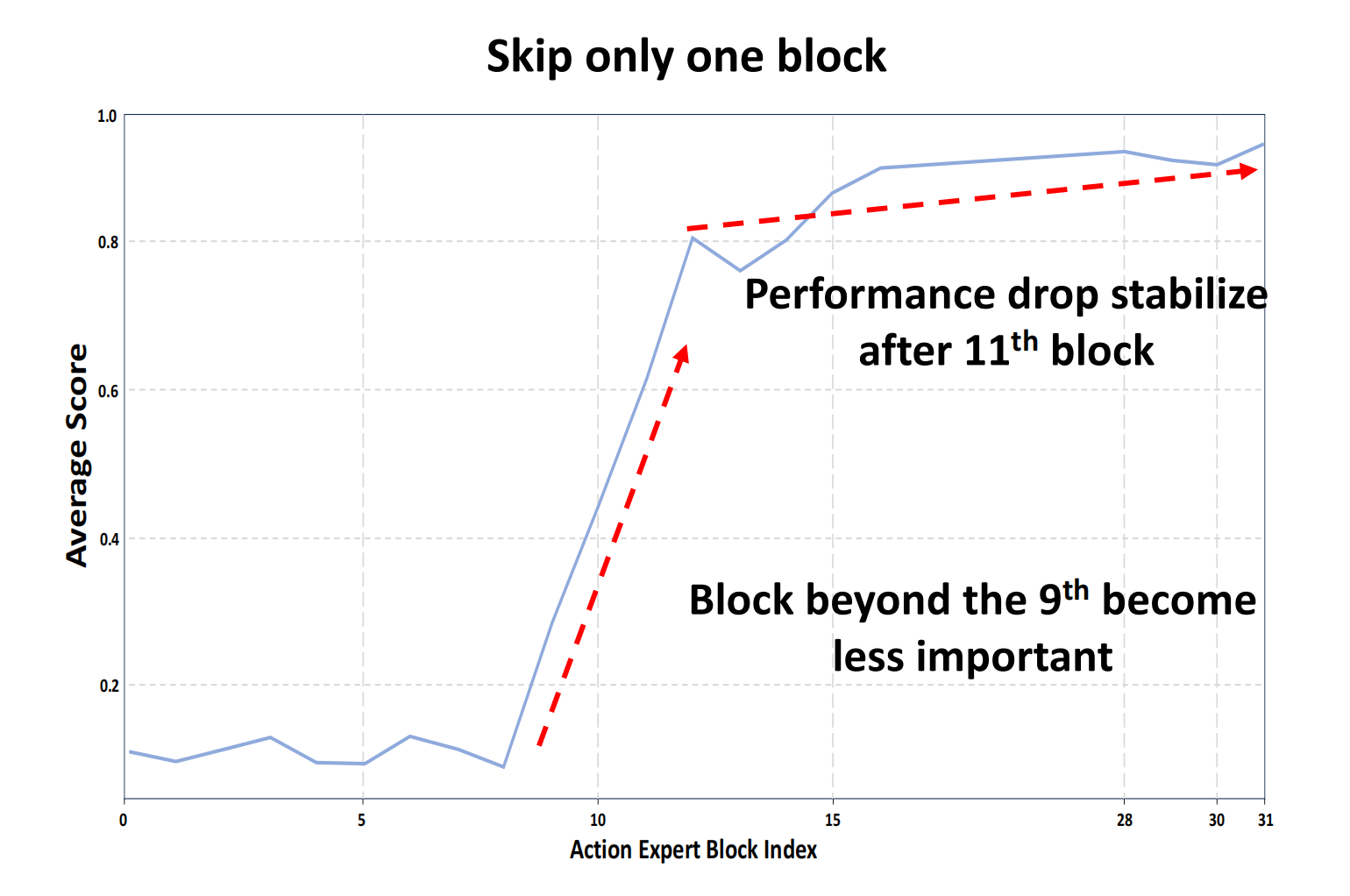
然而,从第11个模块开始,跳过单个模块是可以接受的,直到最后一个模块。这表明,经过训练后,第11到31模块对性能的贡献较少 - 为了进一步研究哪些模块适合点云注入,他们从第11模块开始进行了多模块跳过分析,如图3(右)所示
他们发现,在模型无法完成任务之前,可以跳过最多五个连续模块。这表明可以通过特定模块将3D表示选择性地注入到动作专家中,从而在不显著影响性能的情况下优化效率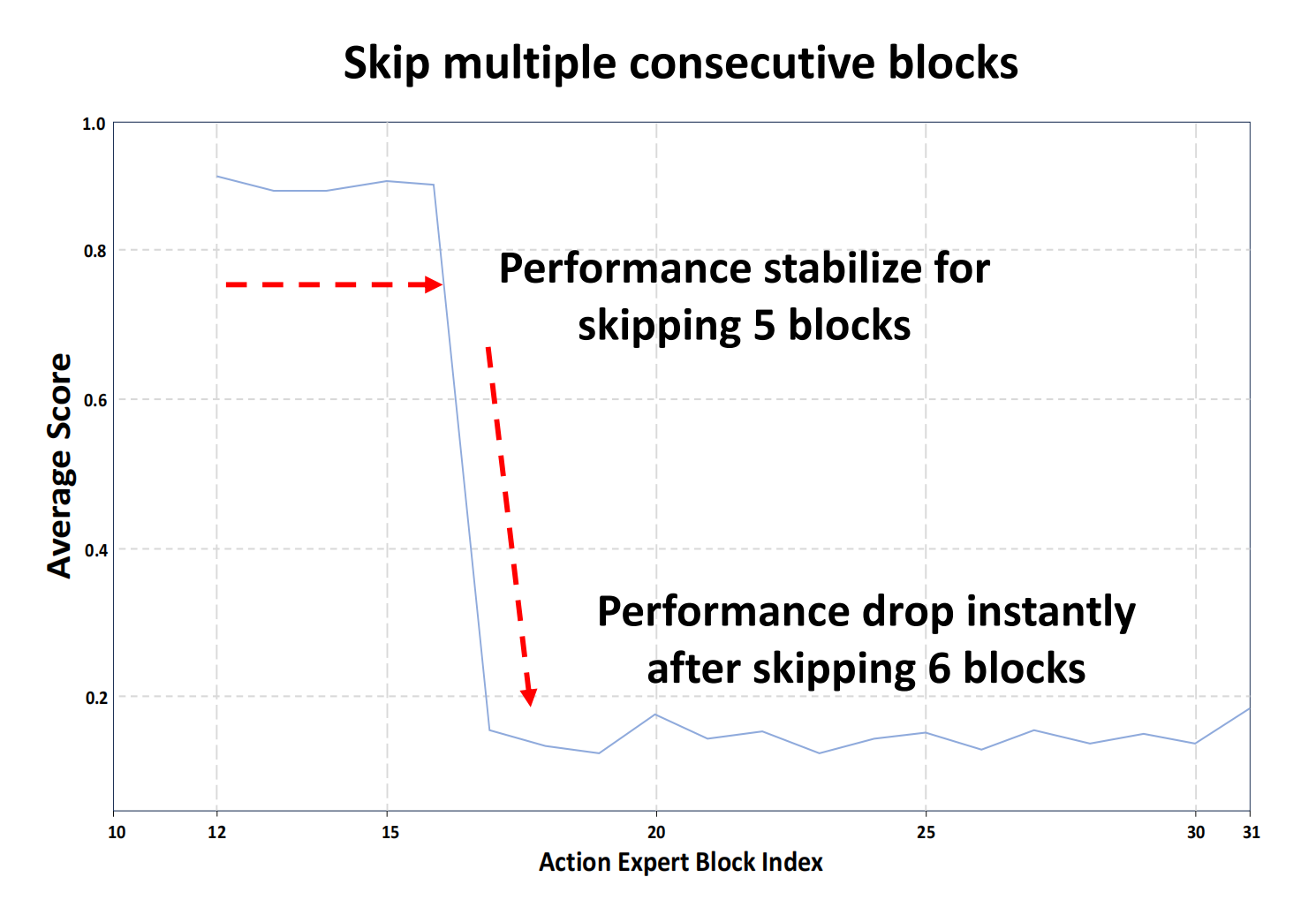
因此,当引入新数据时,他们将所有3D条件模块设置为可训练。且冻结原始动作专家中的所有模块,除了最后的层,这些层被调整以适应具体实施的输出
最终,他们仅训练了五个额外的注入模块,这些模块在推理过程中轻量且快速,使得他们的方法具有极高的成本效益
3.3 实验
3.3.1 实验设置
他们在两种实体上进行了真实机器人实验:
- 双臂 UR5e
两个 UR5e 机器人,每个配备一个 Robotiq 平行夹爪,和一个腕部安装的摄像头——数据以15Hz的频率采集。且使用RealSense D435i 摄像头作为腕部摄像头
另在两臂之间安装了一个俯视摄像头
相当于,此设置共有三个摄像头视角以及一个14维的配置和动作空间 - 双臂 AgileX
两个 6 自由度的 AgileX 机械臂,每个机械臂配备一个腕部摄像头——数据以30Hz 采集。我们使用 RealSense D435i 摄像头作为腕部摄像头
和一个基座摄像头——使用 RealSense L515 摄像头来收集点云数据
此配置具有 14 维的配置和动作空间,相当于总共由三个摄像头支持
之后,将 VLM 模型设置为可训练状态,因为模型需要学习新的语言指令
- 在这两个实验中,他们使用来自 DexVLA [46] 的第一阶段预训练权重,并对他们的模型进行微调。且使用与DexVLA 第二阶段训练相同的训练超参数,并使用最后一次检查点用于评估以避免选择性偏好
- 过程中,将所有任务的块大小设置为50
在他们的实验中,他们对比了包括扩散策略(DP)[9],3D扩散策略(DP3)[51],ScaleDP-1B [57],一种将扩散策略扩展到10亿参数的变体,Octo [34],OpenVLA[25],以及DexVLA [46]
请注意,由于PointVLA是基于DexVLA构建的,因此DexVLA可以被视为PointVLA在未结合3D点云数据情况下的消融版本
3.3.2 少样本多任务处理
如下图图5所示,他们设计了四个少样本任务:充电手机、擦盘子、放置面包、运输水果。物体被随机放置在一个小范围内,我们报告了每种方法的平均成功率
- 充电手机:机器人拾取一部智能手机并将其放置在无线充电器上。手机的尺寸测试了动作的精确性,而其脆弱性需要小心处理
- 擦盘子:机器人同时拾取一个海绵和一个盘子,用海绵擦拭盘子,评估双手操作技能
- 放置面包:机器人拾取一片面包并将其放置在一个盘子上。面包下面的一层薄泡沫用来测试高度泛化能力
- 运输水果:机器人拾取一个随机方向的香蕉并将其放置在一个位于中央的箱子里
由于作者旨在验证模型的少样本多任务能力,故他们为每个任务收集了20个示例,总计80个示例。物体的位置在一个小范围内随机化。这些任务评估了模型在不同场景中管理独立和协调机器人运动的能力。所有数据均以30Hz采集
从实验结果来看,他们宣称的他们的方法优于所有基线方法
- 且值得注意的是,扩散策略在大多数情况下都失败了,这可能是因为每个任务的样本量太小,导致动作表示空间变得纠缠——这一观察与先前文献中的发现一致[47]
- 此外,即使增加模型大小(ScaleDP-1B),也未能带来显著的改进
- 尽管数据有限,DexVLA 展现了强大的少样本学习能力;然而,其性能与 PointVLA 相当或稍逊
- PointVLA 中点云数据的整合实现了更高效的样本学习,突出了将三维信息整合到模型中的必要性。更重要的是,他们的结果证实了PointVLA的方法成功地保留了从二维预训练的VLA中学习的能力