电商用户购物行为分析:基于K-Means聚类与分类验证的完整流程
随着电商行业的快速发展,用户行为分析成为企业优化营销策略、提升用户体验的重要手段。通过分析用户的购物行为数据,企业可以挖掘出用户群体的消费特征和行为模式,从而制定更加精准的营销策略。本文将详细介绍一个基于Python实现的电商用户购物行为分析系统,涵盖数据预处理、K-Means聚类、分类验证和结果可视化等模块。
系统架构与模块设计
该系统由四个主要模块组成:
-
数据预处理模块:负责加载、清洗和特征提取。
-
K-Means聚类模块:用于用户行为数据的聚类分析。
-
分类验证模块:验证聚类结果的质量。
-
结果可视化模块:将分析结果以图表形式展示。
以下将详细描述每个模块的设计与实现。
数据预处理模块
功能与实现
数据预处理是整个分析流程的基础,其主要功能包括:
-
数据加载:从CSV文件中加载用户行为数据。
-
数据清洗:处理缺失值、异常值和重复值。
-
特征提取:提取用户行为的关键特征,如浏览次数、购买频率等。
-
特征标准化:对特征进行归一化或标准化处理。
-
特征降维:通过PCA等方法降低特征维度(可选)。
class DataPreprocessor:
def __init__(self, data_file):
self.data_file = data_file
self.data = Nonedef load_data(self):
try:
self.data = pd.read_csv(self.data_file)
print(f"数据加载成功,数据维度: {self.data.shape}")
return self.data
except Exception as e:
print(f"数据加载失败: {e}")
return Nonedef clean_data(self):
# 处理缺失值
self.data = self.data.dropna()
# 处理重复值
self.data = self.data.drop_duplicates()
print(f"数据清洗完成,清洗后数据维度: {self.data.shape}")
return self.datadef extract_features(self):
# 提取用户行为特征
user_features = self.data.groupby('user_id').agg({
'page_views': 'sum',
'purchase_amount': 'sum',
'visit_duration': 'mean',
'purchase_frequency': 'count'
}).reset_index()
print("特征提取完成")
return user_featuresdef normalize_features(self, method='z-score'):
# 特征标准化
scaler = StandardScaler()
normalized_features = pd.DataFrame(scaler.fit_transform(user_features),
columns=user_features.columns)
normalized_features['user_id'] = user_features['user_id']
print("特征标准化完成")
return normalized_features
K-Means聚类模块
功能与实现
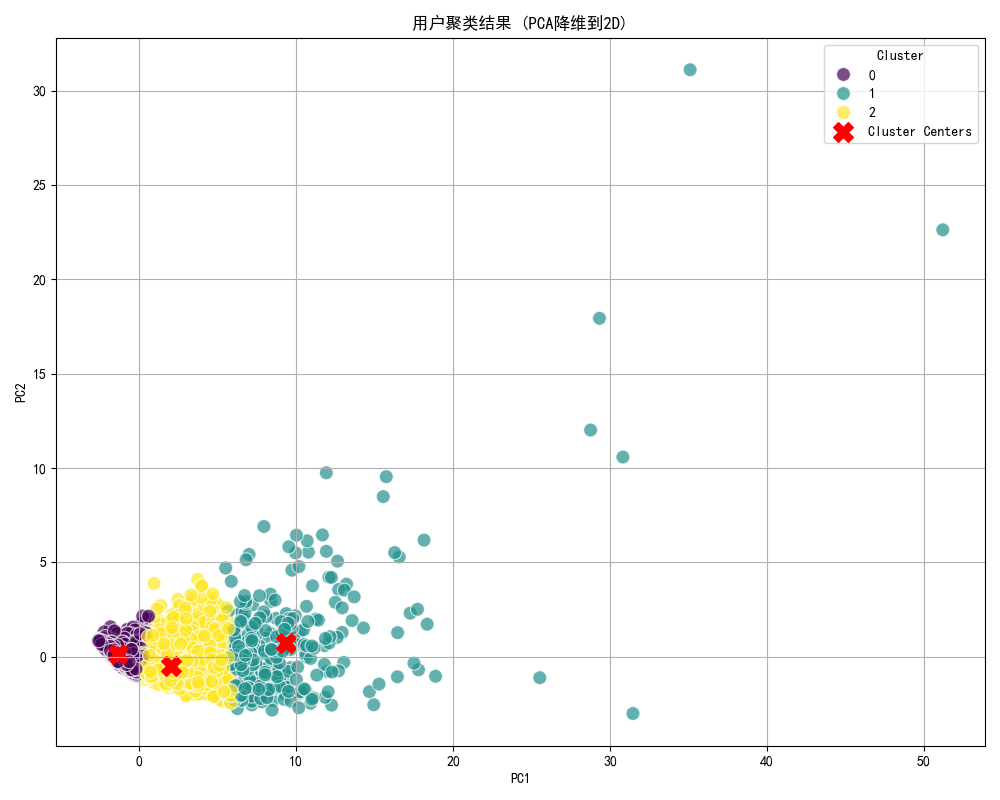
K-Means聚类模块用于将用户划分为不同的群体,主要功能包括:
-
最优K值选择:通过肘部法则和轮廓系数确定最优聚类数。
-
聚类执行:使用K-Means算法对用户行为数据进行聚类。
-
聚类结果可视化:通过2D/3D散点图展示聚类结果。
-
聚类结果分析:计算每个簇的特征统计量。
代码实现
class KMeansClusterer:
def __init__(self, features_data):
self.features_data = features_data
self.kmeans_model = None
self.cluster_labels = None
self.optimal_k = Nonedef find_optimal_k(self, k_range=(2, 10)):
# 使用肘部法则和轮廓系数确定最优K值