c++--------- stack queue
目录
目录
目录
一、stack queue的介绍和使用
1.1 stack queue的介绍
1.2 stack queue的使用
1.3 相关题目
最小栈
栈的压入、弹出序列
二、模拟实现
三、容器适配器
1、什么是适配器
2、STL标准库中stack和queue的底层结构
3、deque的简单介绍
(1)vector和list对比
(2)deque的原理介绍
(3)deque的缺点
(4)为什么选择deque
(5)deque如何如何实现[]的随机访问
四、priority_queue
1、priority_queue的介绍
2、priority _queue的使用
3、priority_queue的模拟实现
五、仿函数
一、stack queue的介绍和使用
1.1 stack queue的介绍
https://cplusplus.com/reference/stack/stack/?kw=stack![]() https://cplusplus.com/reference/stack/stack/?kw=stack
https://cplusplus.com/reference/stack/stack/?kw=stack
https://cplusplus.com/reference/queue/queue/![]() https://cplusplus.com/reference/queue/queue/
https://cplusplus.com/reference/queue/queue/

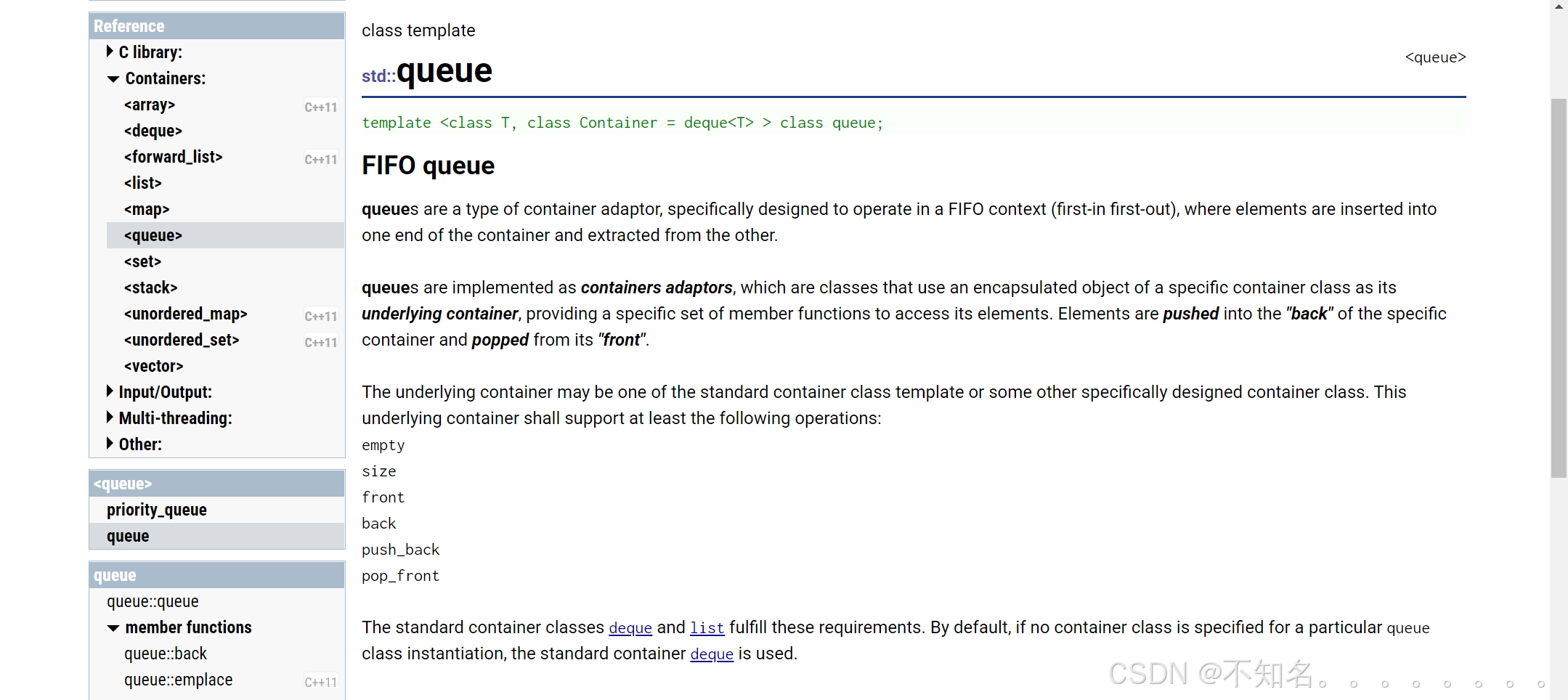
我们可以观察到stack queue和vector、string、list都不同的是的模板中有一个适配器
1.2 stack queue的使用
stack:
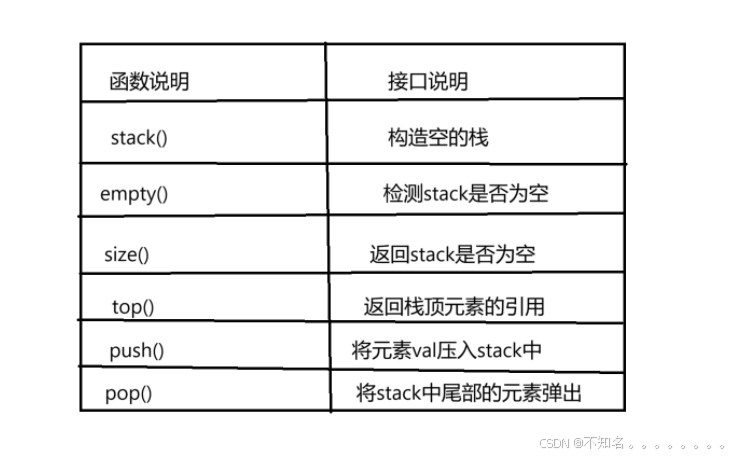
queue:

举例
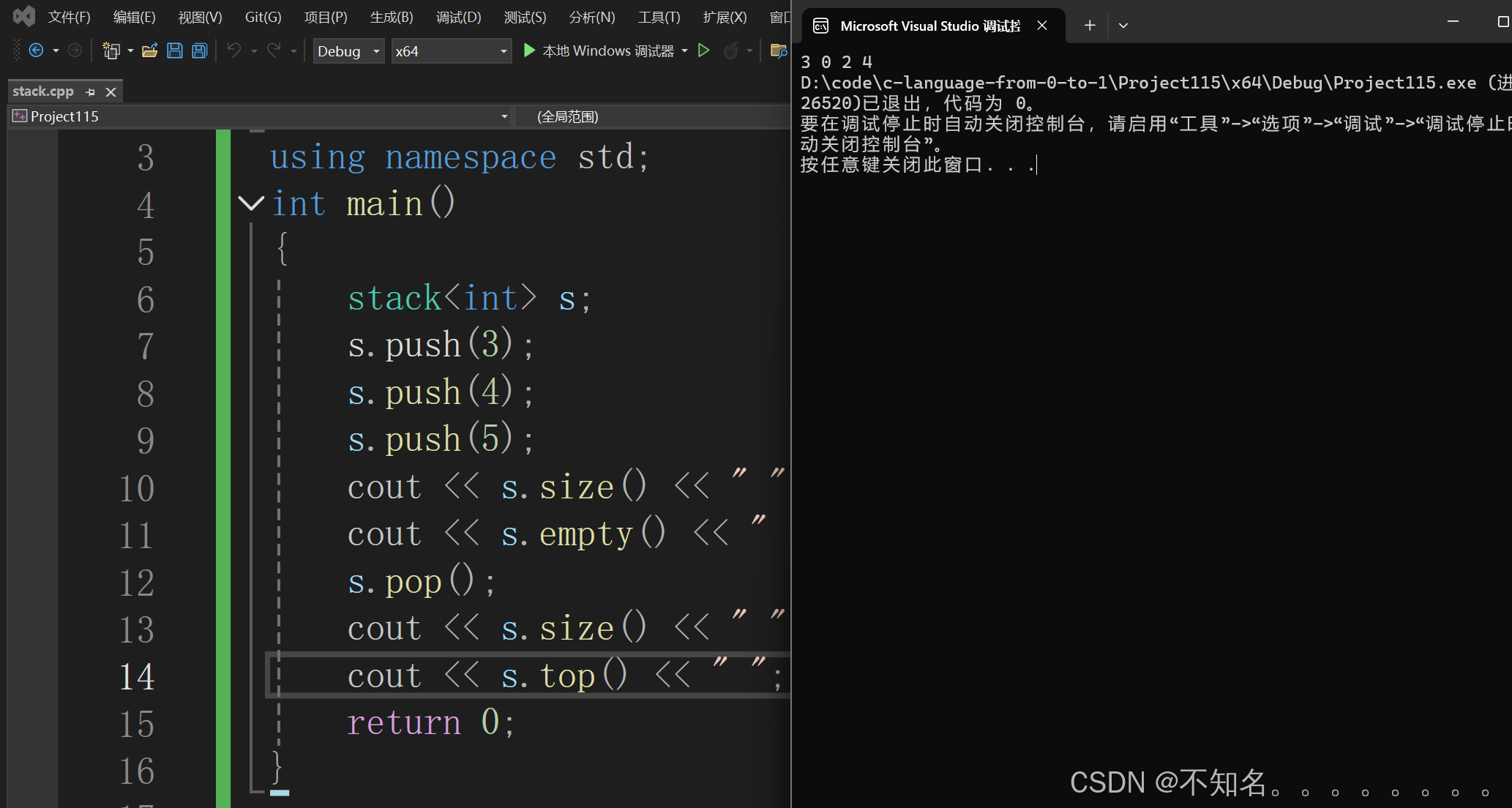
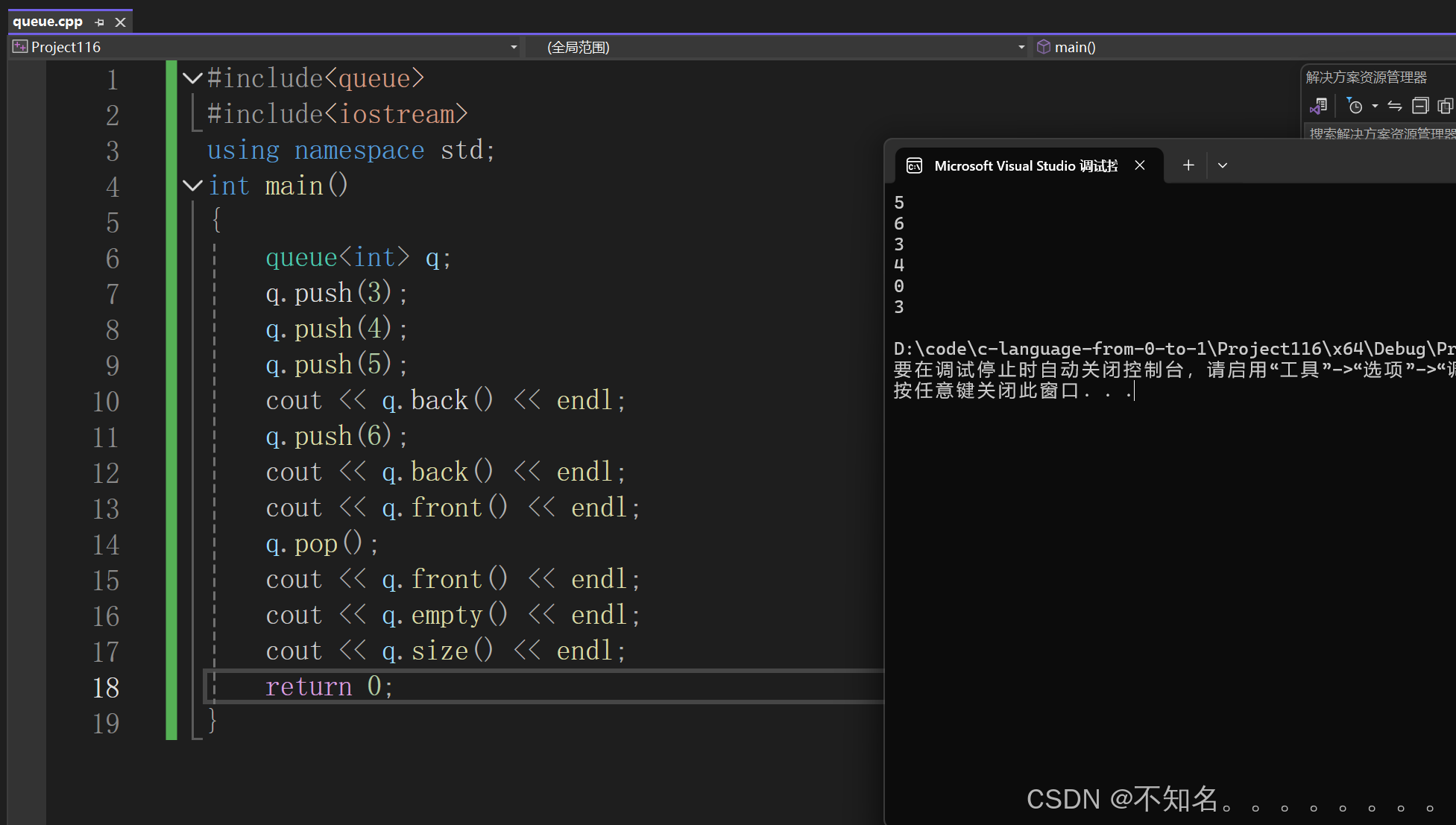
1.3 相关题目
最小栈
https://leetcode.cn/problems/min-stack/description/
解题思路:这道题可以使用双栈来实现,一个栈存储数据,一个存储最小值,但我们push的时候存储数据的栈正常push,另一个第一次push,下一次如果push的数据小于或者等于栈顶的元素就push,反之不push,但我们pop的时候 存储数据的栈正常pop,另一个如果存储数据pop之前的栈顶数据等于当前栈的栈顶数据就pop。top就是存储数据栈的栈顶元素,最小数据就是另一个栈的栈顶数据
代码实现
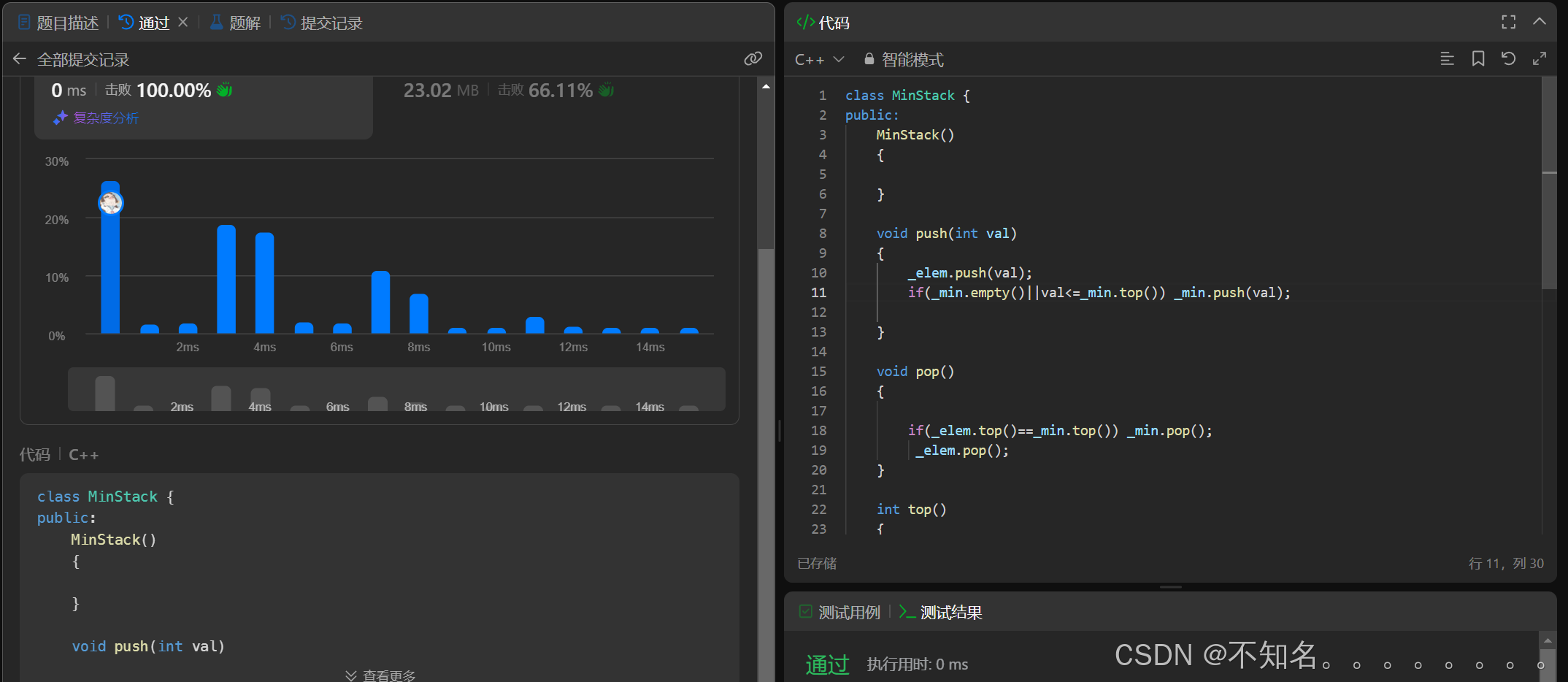
class MinStack {
public:
MinStack()
{
}
void push(int val)
{
_elem.push(val);
if(_min.empty()||val<=_min.top()) _min.push(val);
}
void pop()
{
if(_elem.top()==_min.top()) _min.pop();
_elem.pop();
}
int top()
{
return _elem.top();
}
int getMin()
{
return _min.top();
}
private:
std::stack<int> _elem;
std::stack<int> _min;
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(val);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->getMin();
*/栈的压入、弹出序列
https://www.nowcoder.com/practice/d77d11405cc7470d82554cb392585106?tpId=13&&tqId=11174&rp=1&ru=/activity/oj&qru=/ta/coding-interviews/question-ranking 
解题思路:
模拟压栈 , 我们设立两个变量input 和output 分别来标记pushV和popV所在的位置,在建立一个栈s,当他为空的时候或者他栈顶元素不等于pop[output]我们就让他压入pushV[input],并让input++,如果input已经input<popV.size我们就返回false ,当他不为空栈顶元素等于pop[output],就是让他pop,并让output++;
bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {
if (pushV.size() != popV.size()) {
return false;
}
stack<int> s;
int output = 0;
int input = 0;
while (output < popV.size()) {
while (s.empty() || s.top() != popV[output]) {
if (input < pushV.size())
s.push(pushV[input++]);
else
return false;
}
s.pop();
output++;
}
return true;
}
};
二、模拟实现
从栈的接口我们可以看出来,栈实际是一种特殊的vector,因此使用vector完全可以模拟是实现stack
代码:
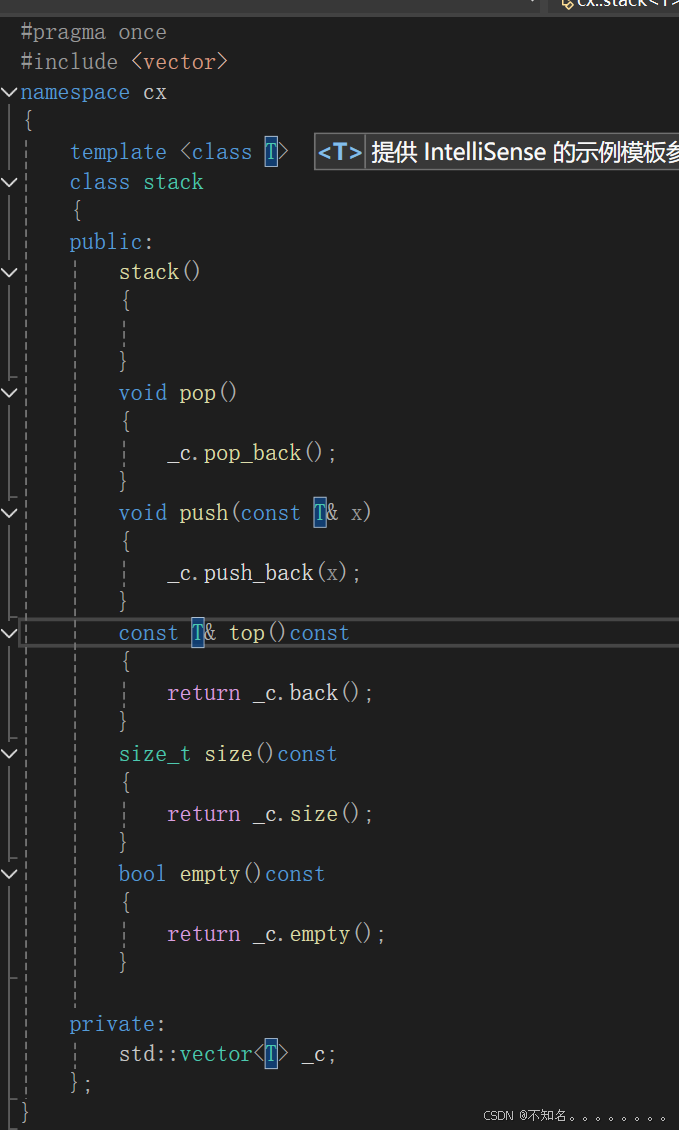
#pragma once
#include <vector>
namespace cx
{
template <class T>
class stack
{
public:
stack()
{
}
void pop()
{
_c.pop_back();
}
void push(const T& x)
{
_c.push_back(x);
}
const T& top()const
{
return _c.back();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
std::vector<T> _c;
};
}但其实用list封装也是可以的
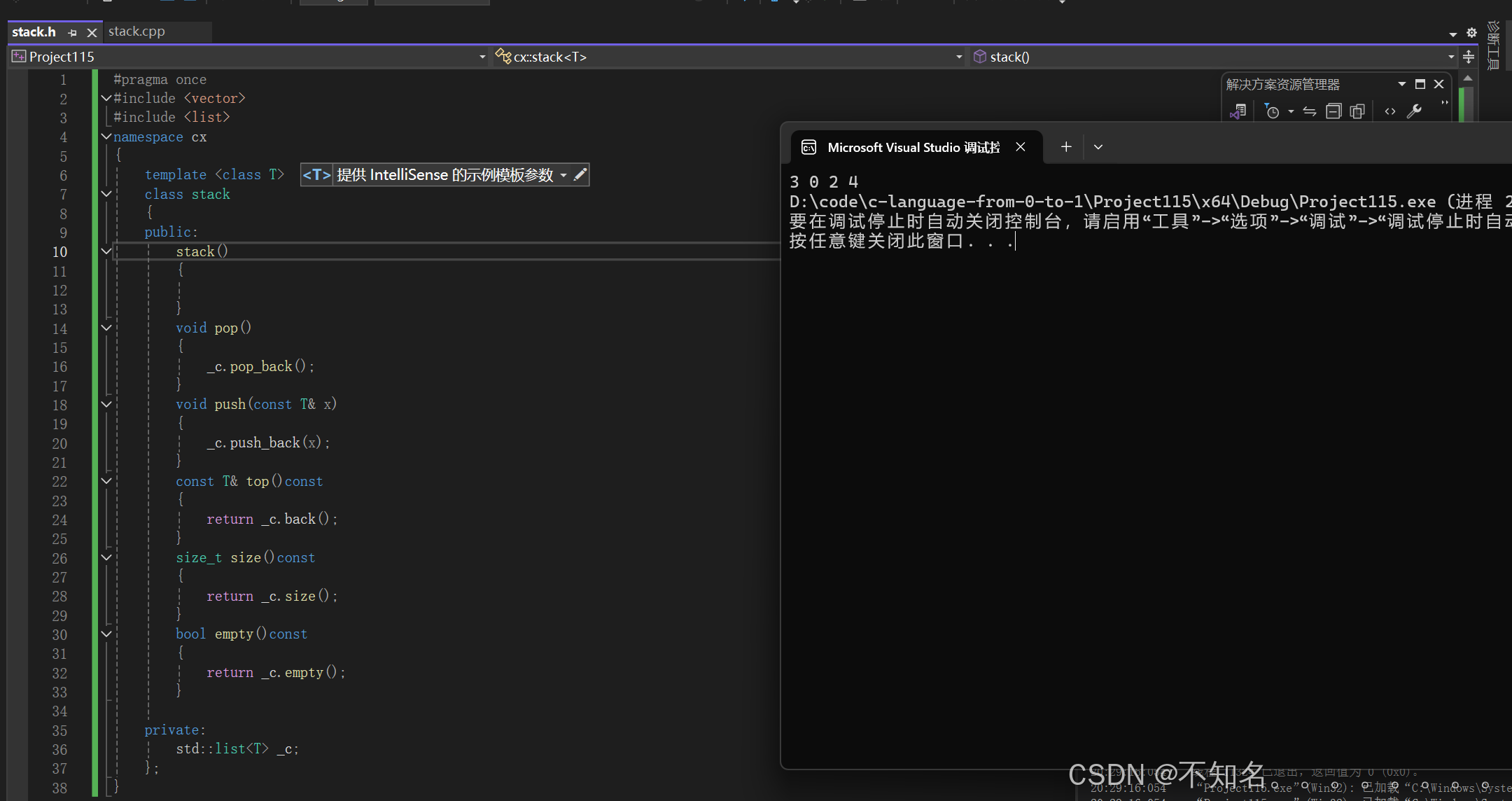
所以我们的源码中引入了一个模板容器适配器
三、容器适配器
1、什么是适配器
适配器是一种设计(设计模式是一套被反复使用堆的、多数人知晓的、经过分类编目、代码设计经验的总结),该模式是将一个类的接口转化成客户希望的另一个接口
2、STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和queue只是对其他容器接口进行了包装,STL中stack和queue默认使用deque
例如
模拟实现:
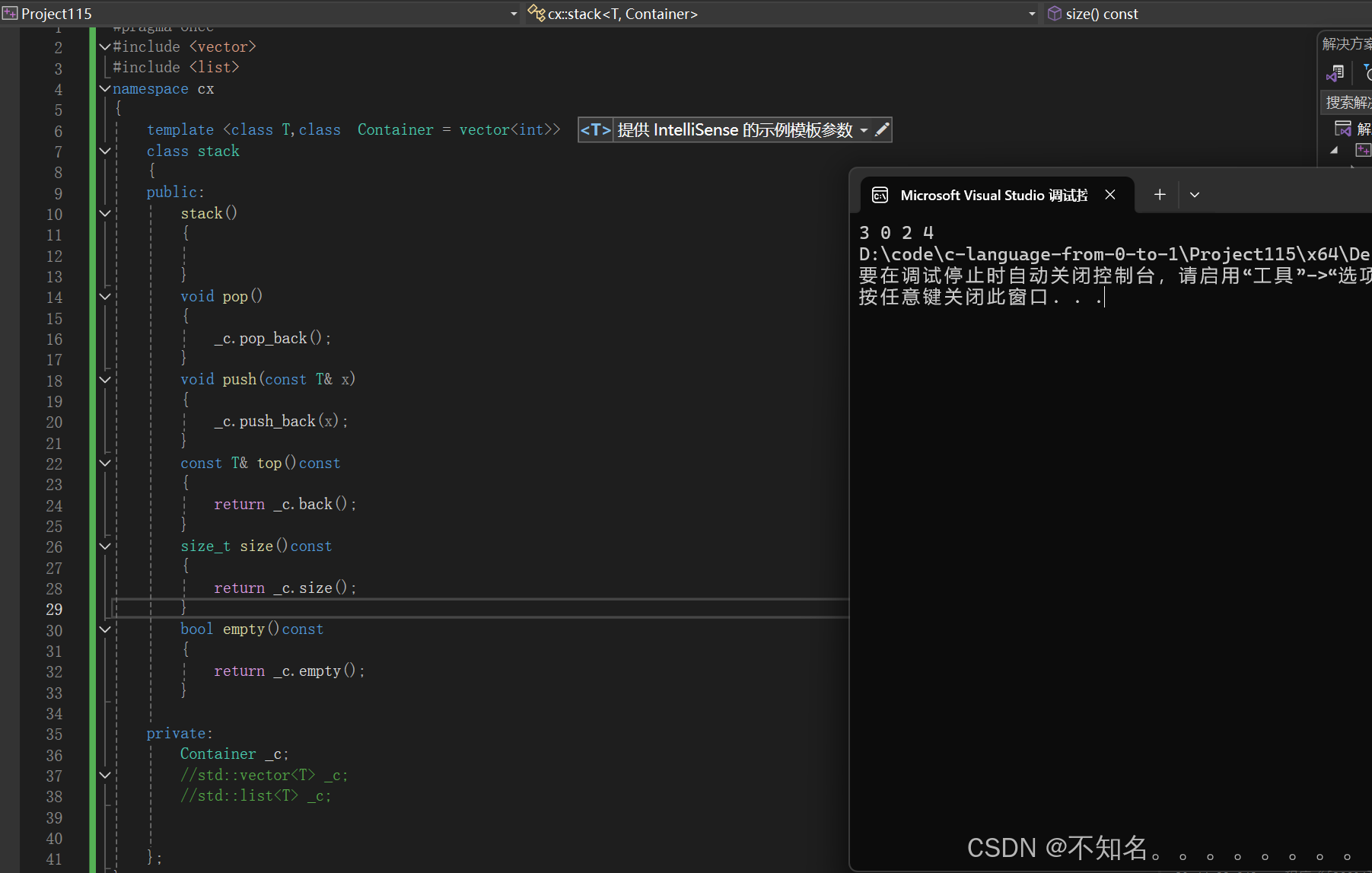
#include <vector>
#include <list>
namespace cx
{
template <class T,class Container = vector<int>>
class stack
{
public:
stack()
{
}
void pop()
{
_c.pop_back();
}
void push(const T& x)
{
_c.push_back(x);
}
const T& top()const
{
return _c.back();
}
size_t size()const
{
return _c.size();
}
bool empty()const
{
return _c.empty();
}
private:
Container _c;
//std::vector<T> _c;
//std::list<T> _c;
};
}3、deque的简单介绍
(1)vector和list对比
vector
优点:下标的随机访问
缺点:中间或者头部插入删除效率低/扩容有一定的消耗,可能存在一定的空间的浪费
list
优点:高效的在任意位置插入删除
缺点:不支持小标随机访问/按需申请释放空间
tip:我们可以看到vector和list几乎是互补的,你的优点是我的缺点,所以有人希望有一种结构可以将二者的优点结合在一起所以deque应运而生(但值得注意的是deque是一个缝合怪,他将二者的优点缝合的不过完全)
(2)deque的原理介绍
deque(双端队列):是一种双开口的连续空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),和vector比较,头插的效率高,不需要搬移元素;和list比较,可以小标随机访问。deque并不是真正连续的空间,而是由一段段的空间拼接而成的,deque类似于一个动态二维数组,其底层如下
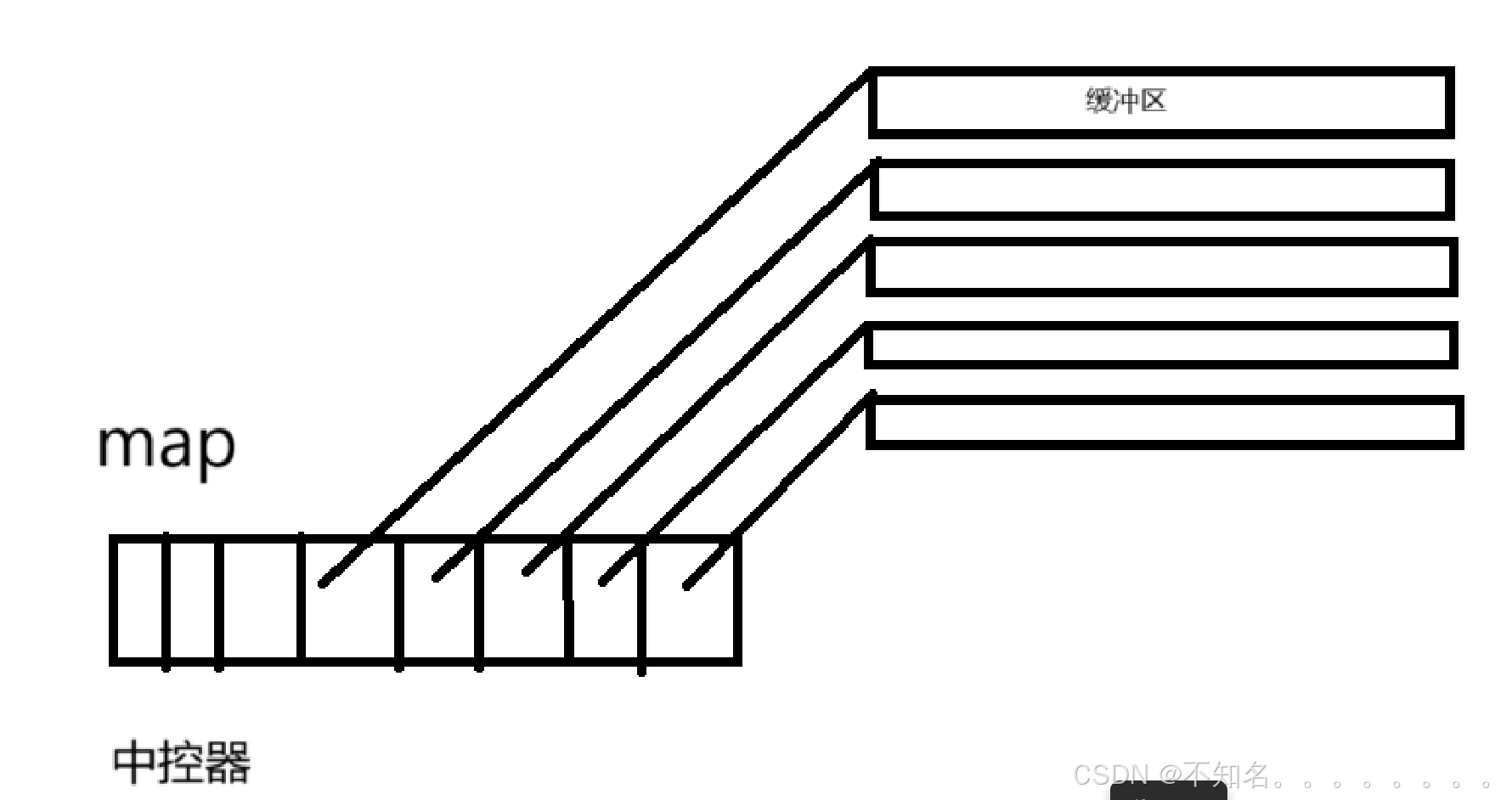
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续” 以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器实际就比较复杂
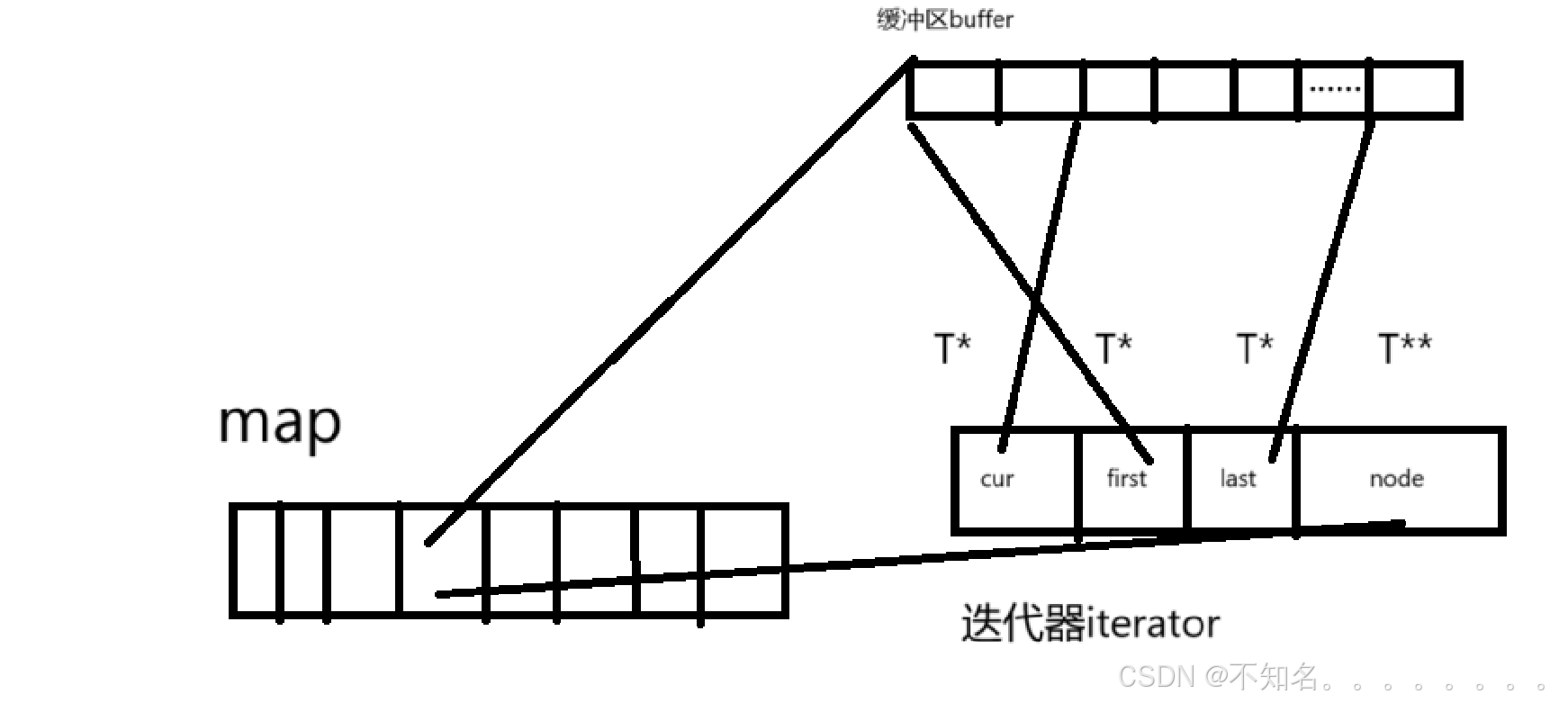
那deque是如何借助其迭代器维护其假象连续的结构呢
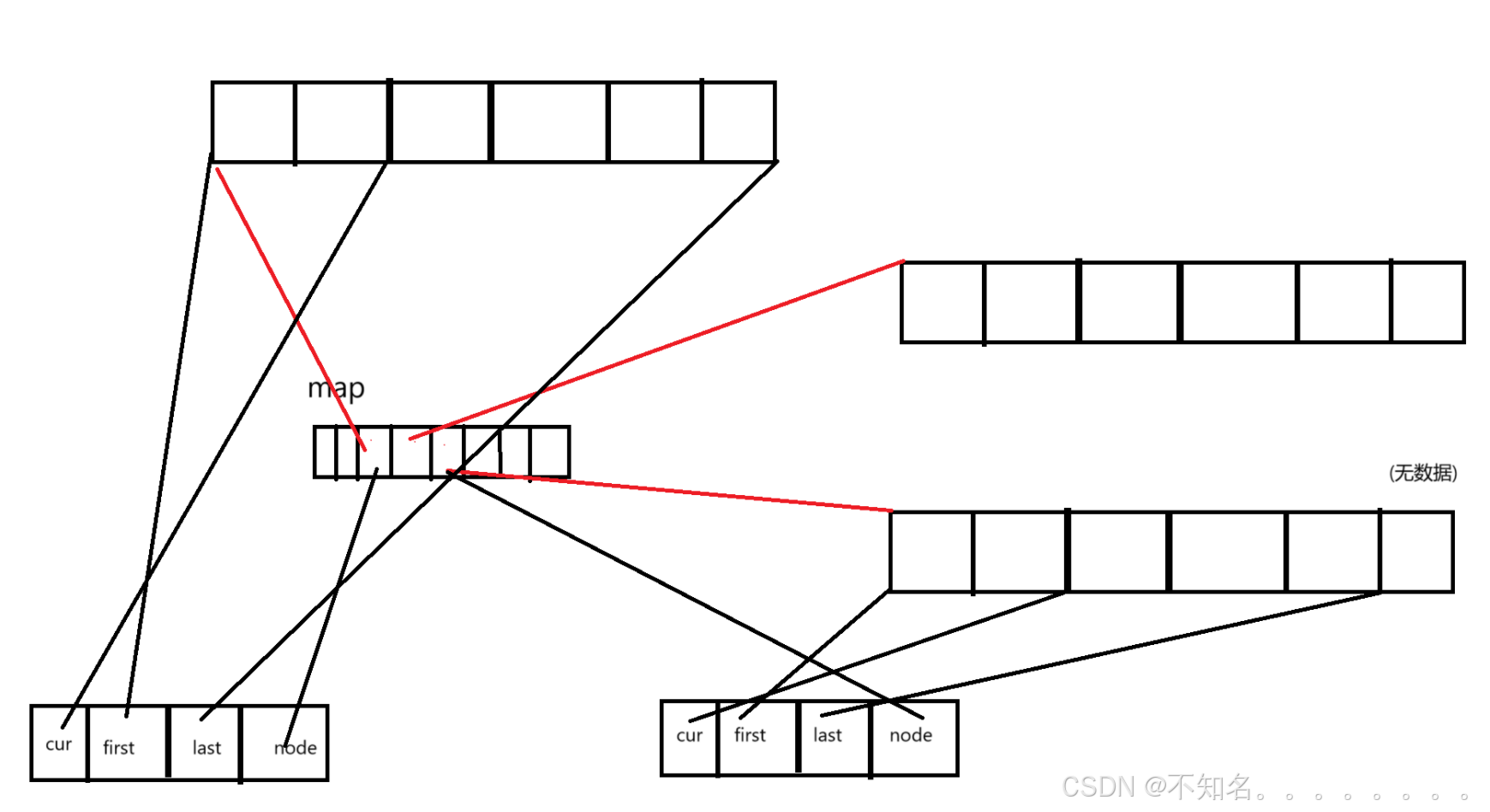
start(iterator) end(iterator)
我们比较迭代器的时候一般比较的是cur中,迭代器的++等操作也是控制cur的
当我们尾插的时候如果end的last位置还有空间就可以直接插入last的位置,再让last++,如果没有位置 ,我们需要再开一段数组然后将值插入再数组的第一个位子,将该数组的地址给map数组中然后再让end的node指向map中新开数组的地址。
当我们头插的时候我们需要新开一段数组,然后再将数据插入在数组的最后一个位置(如果不这样就不符合++迭代器,到迭代器到下一个数据的逻辑)在将数组地址传给map中start前面的位置
(3)deque的缺点
与vector比较,deque的优势是:头插和删除的时候,不需要搬移元素 ,效率特别高,而且在扩容的时候,也不需要搬移大量的元素,因此其效率是比vector高的
与list相比,其底层是连续的空间,空间利用率比较高,必须要额外存储字段
但是:deque是不适合遍历的,因为在遍历的时候,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能要经常遍历,因此在实际中,需要线性结构的时,大多数会优先考虑vector和list,deque的应用并不多,而目前能看到的是一个应用就是,STL用其作为stack和queue的底层数据结构
(4)为什么选择deque
stack和queue不需要遍历(因此二者并没有迭代器),只需要在固定的一端或者两端进行操作/
在stack元素增长时,deque比vector的效率高(扩容的时候不需要搬移大量的数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高
(5)deque如何如何实现[]的随机访问
deque会进行运算符重载,将[]的值先/8得到在哪一个数组,在%8得到在数组的哪一个(如果 第一个数组没有满的话,需要加上第一个字母当前的位置,表示从他开始遍历的)
四、priority_queue
1、priority_queue的介绍
https://cplusplus.com/reference/queue/priority_queue/
(1)优先级队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元 素中最大的。
(2)以上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于 顶部的元素)
(3)优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue 提供一组特定的成员函数来访问其元素。元素从特定容器的尾部弹出,其称为优先队列的顶 部。
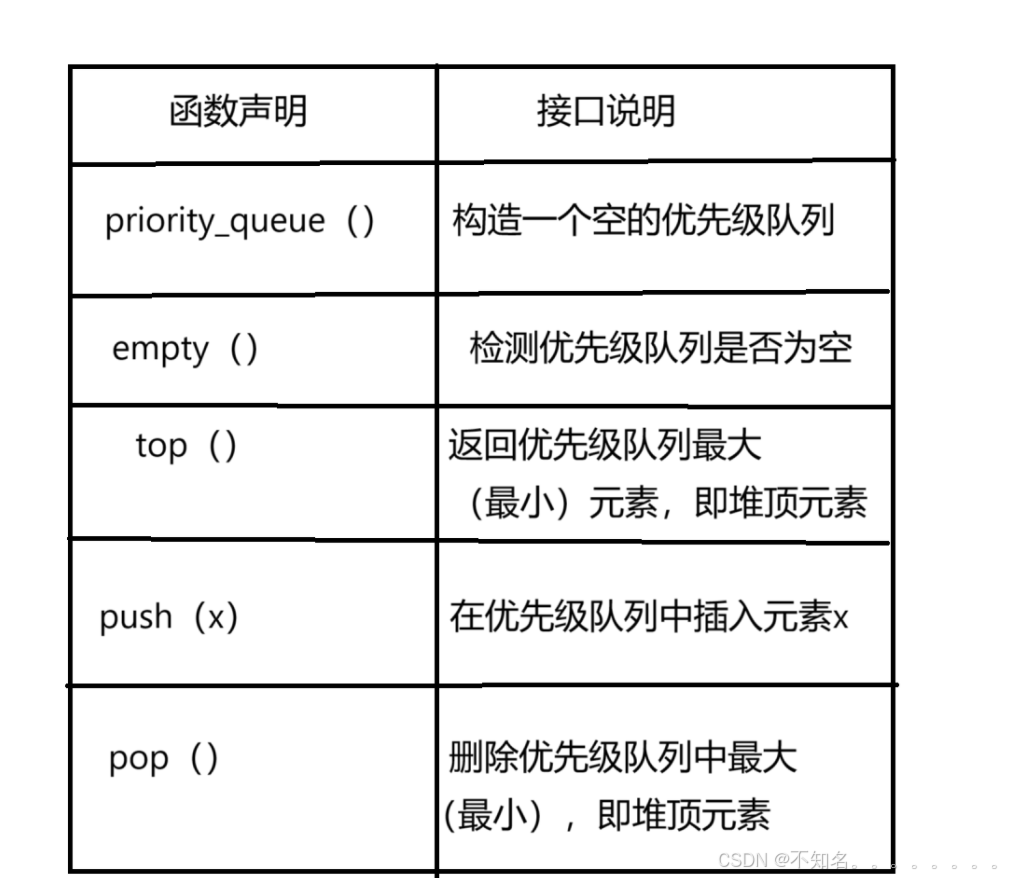
(4)底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过 随机访问迭代器访问,并支持以下操作:

(5)标准容器类vector和deque满足这些需求。默认情况下,如果没有特定的priority_queue类实 例化指定容器类,则使用vector
(6)需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用 算法函数make_heap、push_heap和pop_heap来自动完成此操作
2、priority _queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上有使用了堆算法将vector中的元素构成堆的结构,因此priority-queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。默认情况下它是大堆
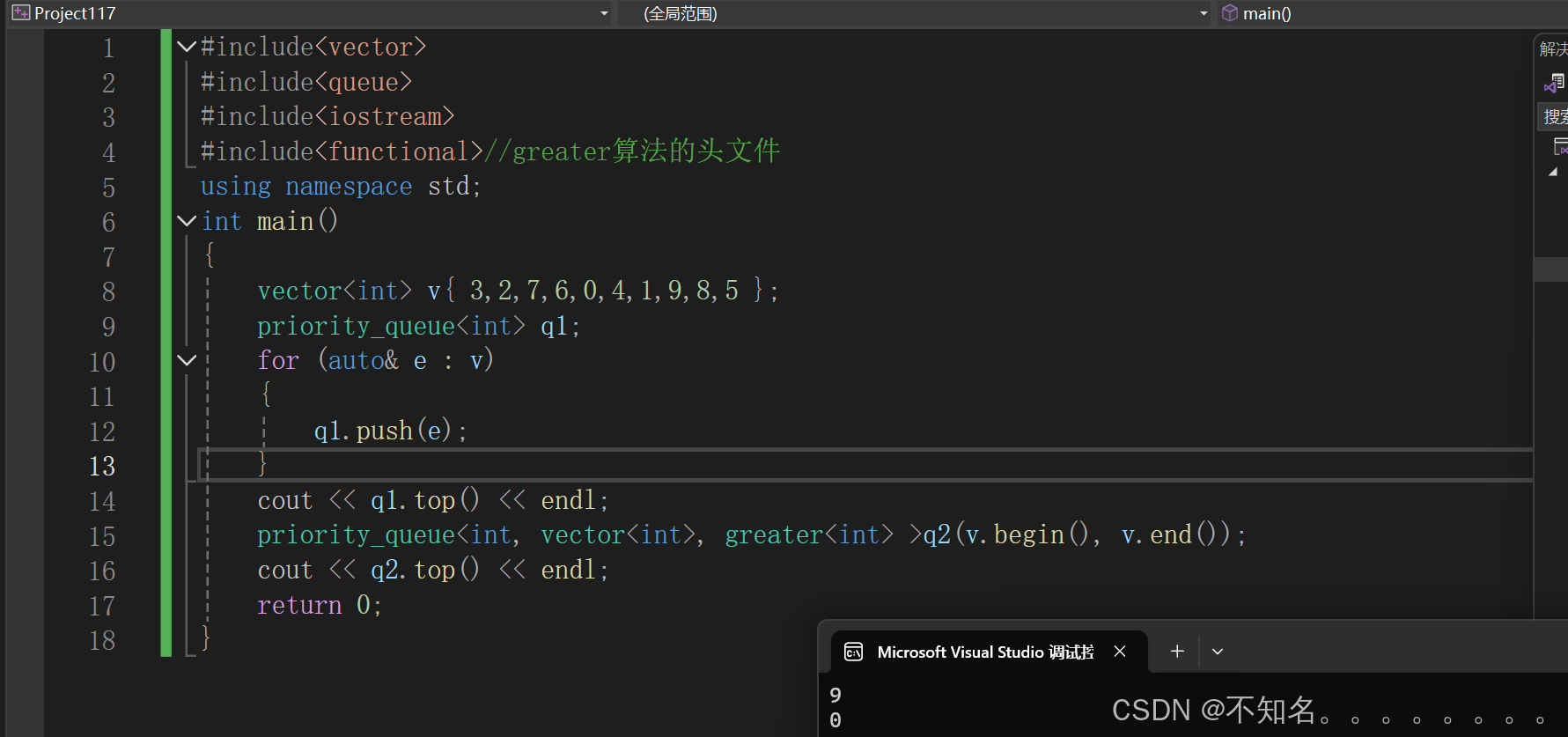
3、priority_queue的模拟实现
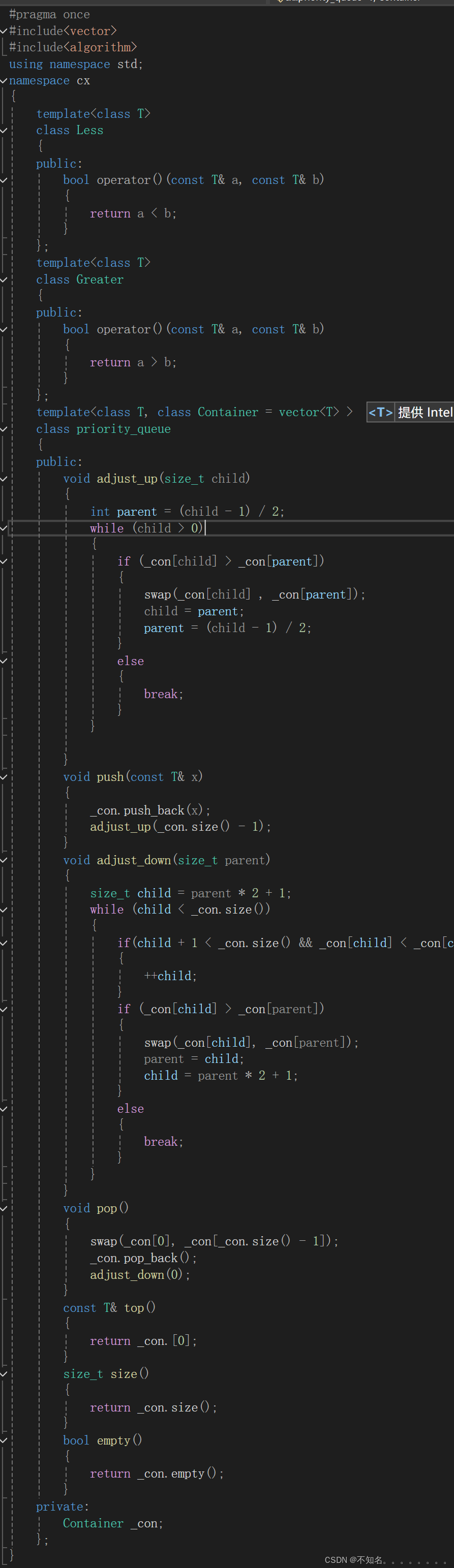
#pragma once
#include<vector>
#include<algorithm>
using namespace std;
namespace cx
{
template<class T>
class Less
{
public:
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& a, const T& b)
{
return a > b;
}
};
template<class T, class Container = vector<T> >
class priority_queue
{
public:
void adjust_up(size_t child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (_con[child] > _con[parent])
{
swap(_con[child] , _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size() - 1);
}
void adjust_down(size_t parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if(child + 1 < _con.size() && _con[child] < _con[child + 1])
{
++child;
}
if (_con[child] > _con[parent])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
const T& top()
{
return _con.[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}五、仿函数

我们观察到源码中有一个仿函数,原因是我们默认priority_queue是大堆,如果我们希望实现一个小堆,观察到代码高度相似,只是比较的逻辑不一样,如果我们为此再写一个代码是浪费的,所以我们使用一个模板当我们需要不同的比较逻辑的就传哪一个类,仿函数就是一个重载了()的一个类,因为在C语言中我们实现调用不同的逻辑是用的函数指针,所以我们叫他仿函数
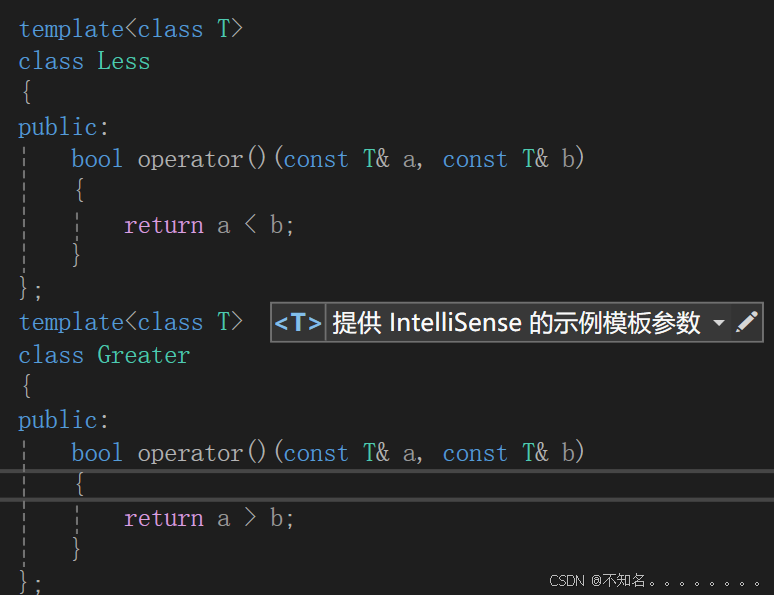
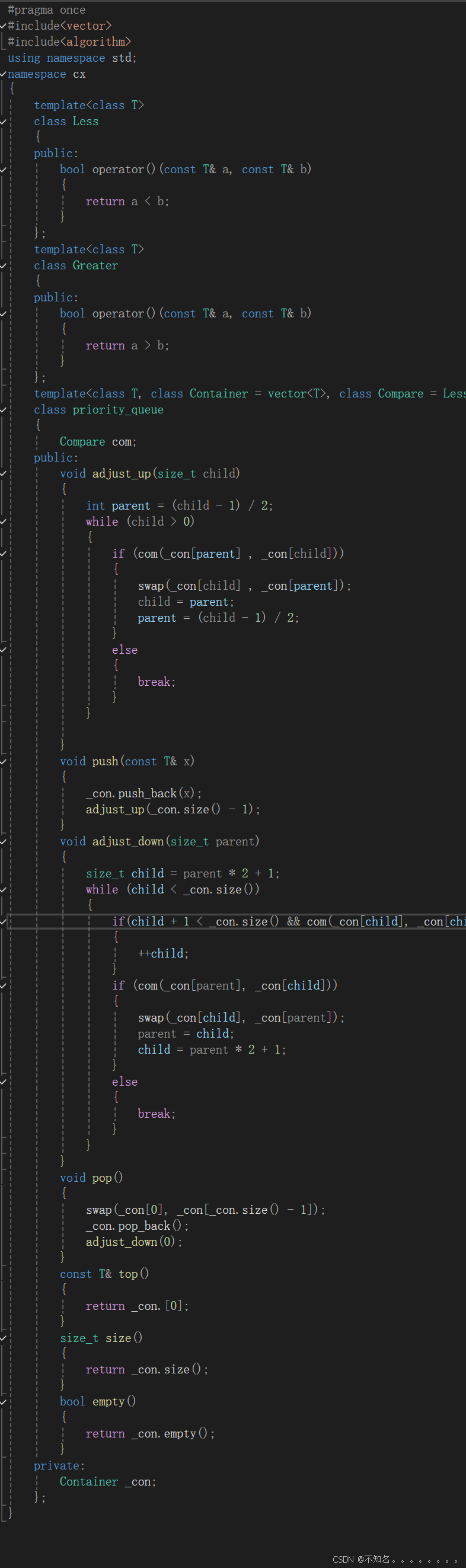
#pragma once
#include<vector>
#include<algorithm>
using namespace std;
namespace cx
{
template<class T>
class Less
{
public:
bool operator()(const T& a, const T& b)
{
return a < b;
}
};
template<class T>
class Greater
{
public:
bool operator()(const T& a, const T& b)
{
return a > b;
}
};
template<class T, class Container = vector<T>, class Compare = Less<T>>
class priority_queue
{
Compare com;
public:
void adjust_up(size_t child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent] , _con[child]))
{
swap(_con[child] , _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size() - 1);
}
void adjust_down(size_t parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if(child + 1 < _con.size() && com(_con[child], _con[child+1]))
{
++child;
}
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
const T& top()
{
return _con.[0];
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
}