具身推理器:协同视觉搜索、推理和行动,实现具身交互任务
25年3月来自浙大、中科院软件所、中科院大学、阿里达摩院、南京软件所、南邮和河海大学的论文“Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks”。
深度思维模型的最新进展,已在数学和编码任务上展现出卓越的推理能力。然而,它们在需要通过图像动作交错轨迹与环境持续交互的具身域中的有效性仍未得到充分探索。本文提出了具身推理器,该模型将 o1 式推理扩展到交互式具身搜索任务。与主要依赖逻辑推理的数学推理不同,具身场景需要空间理解、时间推理和基于交互历史的持续自我反思。为了应对这些挑战,合成 9.3k 条连贯的观察-思维-动作轨迹,其中包含 64k 个交互式图像和 90k 个不同的思维过程(分析、空间推理、反思、规划和验证)。开发一个三阶段训练流程,通过模仿学习、通过拒绝采样进行自我探索以及通过反射调优进行自我纠正来逐步增强模型的能力。评估表明,其模型明显优于那些先进的视觉推理模型,例如,它比 OpenAI o1、o3-mini 和 Claude-3.7 分别高出 9%、24% 和 13%。分析表明,该模型表现出更少的重复搜索和逻辑不一致,在复杂的长期任务中尤其具有优势。在现实环境测试也显示出优势,同时表现出更少的重复搜索和逻辑不一致的情况。
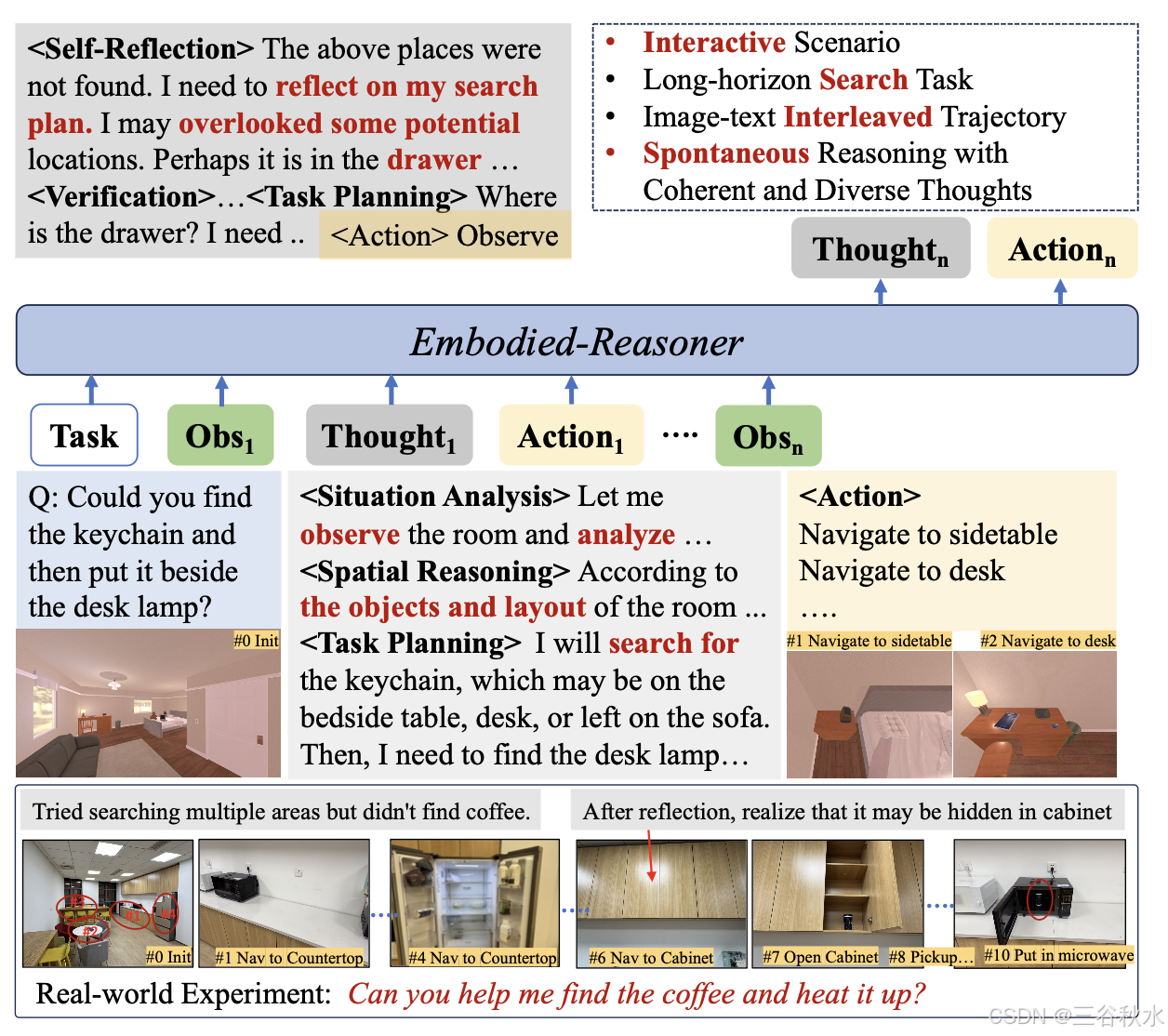
如图所示一个具身交互任务:在未知房间中寻找物体。然后本文提出 Embodied-Reasoner,它具有自发推理和交互能力。在每次行动之前,它会产生不同的想法,例如自我反思或空间推理,形成图文交织的轨迹。它表现出一致的推理和高效的搜索行为,而 OpenAI o3-mini 经常表现出重复搜索和逻辑不一致,失败率较高。
深度思考模型(例如 OpenAI o1 [30]、Gemini 2.0 Flash Thinking [10]、DeepSeek R1 [14] 和 Qwen-QwQ [39])的最新进展,已在需要大量思考的领域中展现出卓越的推理能力。这些模型通过大规模强化学习 (RL)[14, 38] 进行训练,或在精细的思维轨迹上进行后期训练[27, 64],在得出解决方案之前表现出类似人类的思维模式和自我反思。它们的成功已在需要深思熟虑的推理领域取得重大进展,特别是在大学水平的数学 [13, 27] 和编码任务 [18, 62] 方面。
尽管取得这些进展,但仍出现一个关键问题:o1 式推理范式是否可以扩展到这些专门领域之外,以解决需要具身智能的更复杂挑战?具体来说,这些推理能力能否有效地应用于需要长期规划和深思熟虑交互式环境中的具身任务?由于以下几个基本挑战,这种扩展并非易事:
挑战 1:扩展多模态交互。与大多数仅限于单轮对话的问答任务相比,具身模型在长期任务中以交互方式运行。这意味着它们必须不断与环境交互,收集实时反馈(大多数以视觉模态出现),然后相应地采取合理的行动(文本模态)。在这种情况下,模型需要处理冗长且图像动作交错的上下文,并产生连贯、上下文一致的推理。然而,这对许多当前的多模态模型和视觉推理模型来说仍然是一个挑战 [12, 15, 15, 34, 55, 55]。即使是像 OpenAI o3-mini [31] 这样的高级推理模型,在这些具身交互任务中也经常无法表现出稳健的推理能力,从而导致重复或不一致的行为。
挑战 2:多样化的推理方式。与主要依赖专业知识和逻辑推理的数学任务不同,具身场景需要日常生活中存在的更广泛的能力。如图所示,在寻找隐藏在未知房间中的物体时,模型必须利用常识知识来推断潜在的搜索区域(例如,步骤 1、3),理解物体的空间关系以在步骤 1、5 中规划有效的探索路径,并使用时间推理来回忆以前尝试中的相关线索(步骤 9)同时反思以前的失败。这些多方面的推理要求对多模态模型提出了挑战。

本文提出 Embodied-Reasoner,这是一种将深度思考能力扩展到具身交互任务的新方法。
为了开发具身场景的 o1 式推理模型,首先设计一个需要高级规划和推理而不是低级运动控制的具身任务,即寻找隐藏物体。接下来,在模拟器中设计一个数据引擎来合成交互式推理语料库:任务指令和相应的关键动作序列。每个动作都会产生视觉观察,形成交互轨迹。最后,为每个动作生成多个思维,例如上下文分析、任务规划、空间推理、反思和验证,从而创建具有“观察-思考-行动”上下文的交互式推理语料库。
如上图所示,该模型需要空间推理能力来理解厨房的布局和物体关系,根据常识推断潜在位置(冰箱、餐桌),系统地搜索未探索的区域,并通过实时观察调整规划,同时避免重复搜索。
数据引擎利用 LLM 自动生成任务指令。然而,与以前的指令合成 [36, 47] 不同,具身任务指令必须满足场景的约束,即避免引用当前场景中不存在的目标或涉及非法操作,例如,如果场景中不包含沙发或沙发无法移动,“请将沙发移到角落”是无效的。因此,首先为每个任务设计多个任务模板,利用 GPT-4o 的编码功能自动选择满足任务约束的目标,并将指令多样化为不同的风格和复杂度。
该引擎会自动注释合成指令的关键动作序列,并通过附加搜索过程生成各种动作序列。
关联图(Affiliation Graph)。首先,如图所示,使用模拟器的元数据构建关联图。在图中,每个节点代表一个目标,边表示两个目标之间的关联关系,例如,抽屉中的钥匙链被描绘为以“包含”关系连接到父节点(抽屉)的叶子(钥匙链)。
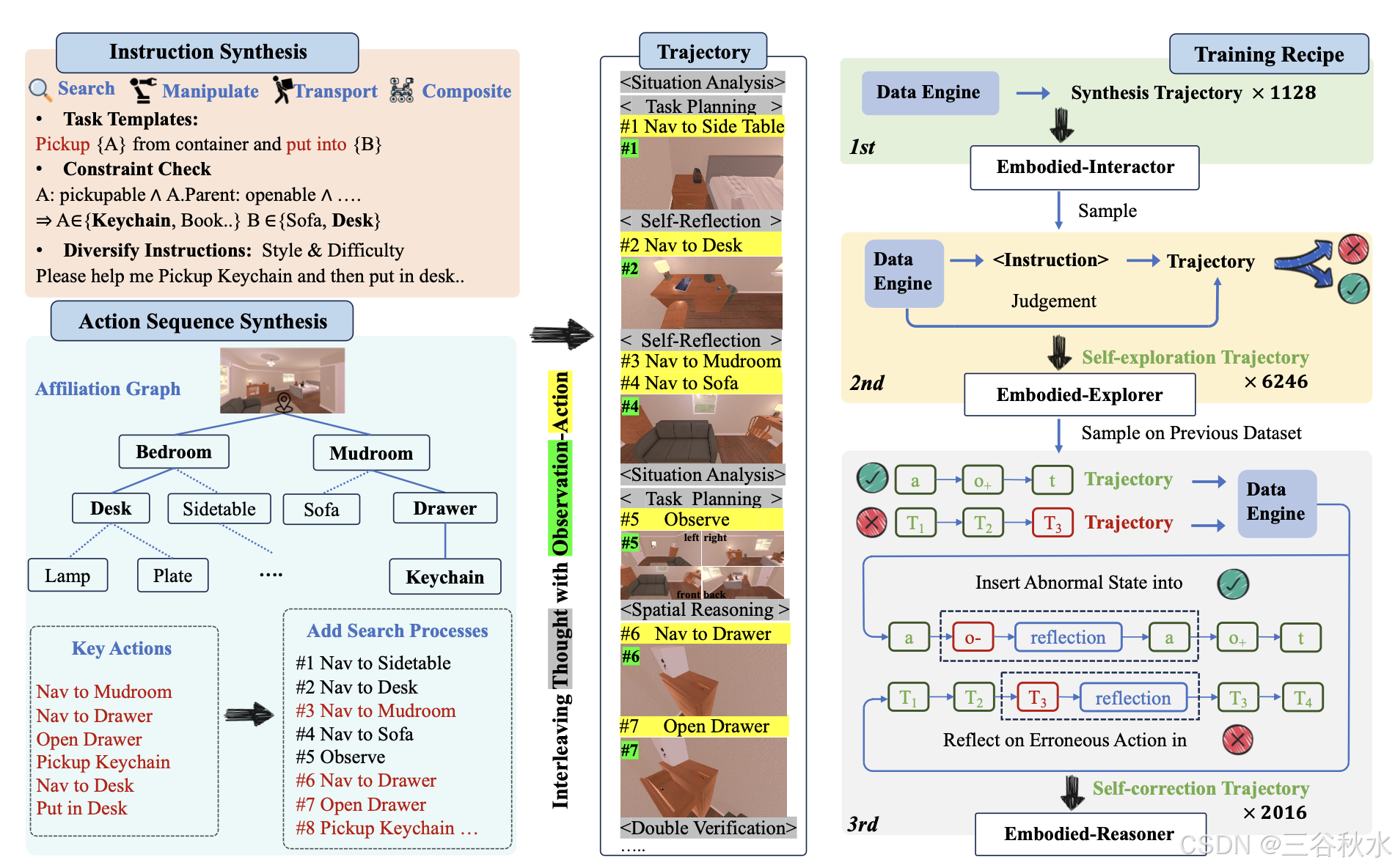
关键动作序列。然后,利用构建的关联图和合成的指令模板来推导完成任务所需的最小动作序列(关键动作)。例如,“拿起钥匙链并将其放在桌子上”,从叶节点(钥匙链)开始,向上追溯到其父节点(抽屉)和祖节点(门厅)。GPT-4o 生成相应的动作序列:A1:导航到门厅,A2:导航到抽屉,A3:打开抽屉,A4:拿起……所有关键动作对于完成任务都是必不可少的。
添加其他搜索过程。除了关键动作序列之外,其引擎还通过插入其他搜索过程来合成探索路径。例如,如上图所示,引擎首先插入三个搜索动作:导航到边桌(sidetable)、桌子和沙发。在找不到钥匙串后,它会插入一个观察动作,直到最终在抽屉中找到钥匙串。这些额外的搜索动作使轨迹更加真实合理,展示机器人如何逐渐探索陌生的环境,直到成功找到目标。
在运行合成的动作(a_1,a_2,…,a_n)之后,得到一条交互轨迹:o_1,a_1,o_2,a_2,…,o_n,a_n,其中o_i 表示第一人称视角图像。然后,为每个动作生成多个深度思考的想法(t_i),创建一个交错的上下文:观察-思考-动作。
多样化的思维模式。首先,定义五种思维模式来模拟人类在不同情境下的认知活动:上下文分析、任务规划、空间推理、自我反思和双重验证。用简洁的提示来描述每个模式,指导GPT-4o合成相应的思维过程。
从观察-行动中得出思维。对于每一次交互,指示 GPT-4o 选择一种或多种思维模式,然后根据交互上下文生成详细的想法。这些想法被插入到观察和行动之间(o_n,a_n→o_n,t1_n,t2_n,…t^k_n,a_n)。具体来说,用之前的交互轨迹(o_1,t_1,a_1,…,o_n)和即将采取的行动(a_n)提示 GPT-4o,并生成一个合理的思考过程(t_n)。它应该考虑最新的观察(o_n)并为下一步动作(a_n)提供合理的理由,同时也要与之前的想法(t_1:n-1)保持逻辑一致。
为了激励推理能力,设计三个训练阶段,即模仿学习、拒绝采样的调整和反思调整,将通用 VLM 引导到具有深度思考能力的具身交互模型中。
多轮对话格式。考虑到交互轨迹遵循交错的图像文本格式(观察-思维-动作),将它们组织为多轮对话语料库。在每一轮中,观察的图像和模拟器的反馈作为用户输入,而思维和动作作为辅助输出。在训练期间,只计算思维和动作 token 的损失。
在第一阶段,使用数据引擎生成一小组指令轨迹,大多数包含有限的搜索过程或仅由关键动作(观察-思考-关键动作)组成。Qwen2-VL-7B-Instruct 在该数据集上进行微调,并学会理解交错的图像-文本上下文、输出推理和动作tokens。
经过调整后,开发 Embodied-Interactor,它能够在具身场景中进行交互。然而,大多数合成轨迹仅包含完成任务的关键动作,没有搜索过程或观察环境。在大多数情况下,Embodied-Interactor 表现出有限的搜索能力,即它不知道如何处理无法直接找到目标并需要进一步搜索的情况。例如,当它打开冰箱找鸡蛋但冰箱是空的时,它可能会回答:“鸡蛋不存在”而不是搜索其他位置。
自我探索轨迹。DeepSeek-R1 表明,通过对大规模自我探索数据进行拒绝采样和奖励引导的强化学习,可以获得高级推理能力。受此启发,用 Embodied-Interactor 对大量自生成轨迹进行采样,以供进一步训练。具体而言,如上图所示,使用数据引擎合成新任务指令及其关键操作,然后使用 Embodied-Interactor 在高温设置下对每条指令采样多条轨迹。最后,选择高质量的轨迹。
数据引擎作为奖励模型。使用数据引擎作为过程监督奖励模型 (PRM) 来评估这些采样的轨迹。保留 6,246 条成功轨迹,其中大多数在多次搜索尝试后完成任务。对所有收集的轨迹执行第二阶段指令调整,开发 Embodied-Explorer。它表现出自适应的规划和搜索行为。例如,当无法直接找到目标对象时,它会制定一个涉及多个具有不同优先级潜在区域的详细搜索规划。
Embodied-Explorer 偶尔会产生不合理的动作,尤其是在出现幻觉等长期任务中。此外,机器人经常会遇到暂时的硬件故障。这需要模型对不合理行为进行自我反思,识别异常状态并及时纠正。如上图所示,使用 Embodied-Explorer 对之前任务的大量轨迹进行采样。1)对于失败的轨迹,定位第一个错误动作并构建自我纠正轨迹。2)对于成功的轨迹,插入异常状态来模拟硬件故障。
将异常状态插入成功轨迹。模拟两种机器人异常:导航异常,机器人导航到与命令不一致的位置(例如,动作:“导航到冰箱”,但实际导航到了桌子);操作异常,机械臂暂时无法执行交互命令。对于成功的轨迹 {…, a, o_+, t…},在动作 (a) 后插入异常状态 (o_−),然后针对该异常生成自我反思想法 (t_r)。最后,重试相同的动作:{…, a, o_−, t_r, a, o_+ …}。
反思失败轨迹中的不合理行为。使用合成的关键动作,识别每个失败轨迹 (Traj_−) 中的第一个错误动作。然后,针对错误动作生成自我反思的思维 (t_r) 并补充剩余的正确轨迹 (Traj_+t:n),创建一个修正轨迹:{Traj_-1:t, t_r^t, Traj_-t:n}。在合成的自我修正轨迹上微调模型。对于损失计算,屏蔽掉错误的部分轨迹(Traj_e1:t)并仅计算反思 token(t_rt)和正确轨迹(Traj_ct:n)的损失。
如表所示,为三个训练阶段(即 ⟨Scene, Inst, Traj⟩)合成 9,390 条独特的任务指令及其“观察-思考-动作”轨迹。在第一阶段,数据引擎合成 1,128 对指令-轨迹。在第二阶段,通过拒绝采样保留 6,246 条探索性轨迹。在第三阶段,数据引擎合成 2,016 条自我修正轨迹。
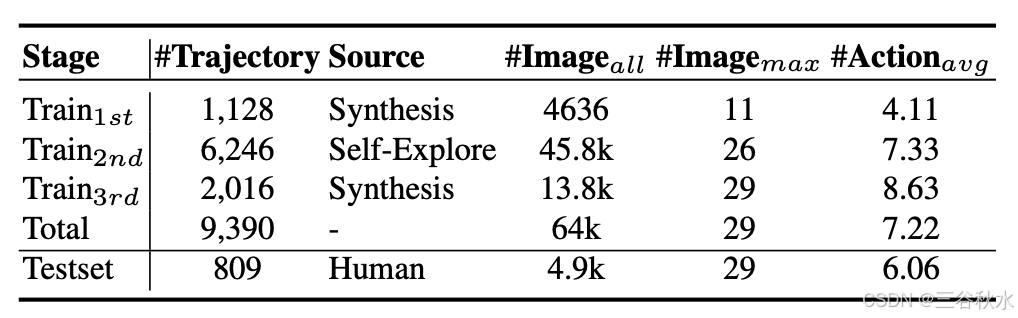
数据集涵盖 107 个不同的室内场景,例如厨房和客厅,并涵盖了 2,100 个交互式目标(例如鸡蛋、笔记本电脑)和 2,600 个容器(例如冰箱、抽屉)。所有轨迹均包含 64K 个来自交互的第一人称视角图像和 8M 个思维 tokens。
思维模式分布。统计五种思维模式在所有轨迹中出现的频率。如图所示,任务规划和空间推理出现的频率最高,分别为 36.6K 和 26.4K。这意味着每条轨迹包含大约四个规划和三个推理。此外,自我反思通常发生在搜索失败后,每条轨迹大约两次。这些不同的想法激励模型的推理能力。
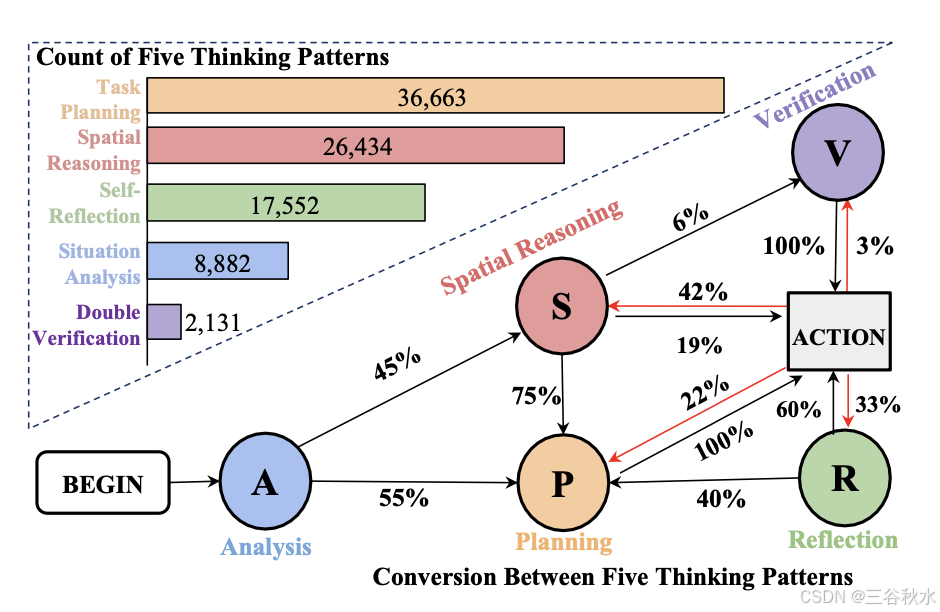
思维模式之间的转换。如图所示计算了五种思维模式之间的转换概率。它们之间的关系是灵活的,取决于情况。它通常从任务规划开始,然后是任务规划(55%)和空间推理(45%)。在导航未知区域时,它经常依赖于空间推理(动作→S:42%)。如果搜索失败,它会转向自我反思(Action→R:33%),一旦(子)任务完成,它有时可能会进行双重验证(Action→V:3%,S→V:6%)。这种多样化的结构使模型能够学习自发思考和灵活的适应性。
在 12 个新场景中培养 809 个测试用例,这些场景与训练场景不同。手动设计指令并注释相应的关键动作和最终状态:⟨指令、关键动作、最终状态⟩。值得注意的是,测试集包含 25 个精心设计的超长视界任务,每个任务涉及四个子任务和 14-27 个关键动作。
为了评估推理模型的泛化能力,设计一个关于物体搜索的真实世界实验,涵盖三个场景的 30 个任务:6 个厨房任务、12 个浴室任务和 12 个卧室任务。在测试期间,人类操作员手持相机捕捉实时视觉输入。该模型分析每个图像并生成操作命令,操作员执行该操作。
如图说明一个例子:“你能帮我找到咖啡并加热吗?” 模型在两次探索(步骤 1、2)后排除台面和餐桌,最终在橱柜中找到咖啡(#7)并将其放入微波炉加热(#11)。然而, OpenAI o3-mini 未能制定合理的规划,先前往微波炉而不是寻找咖啡。此外,它经常忘记搜索并表现出重复搜索,这与之前的分析一致。
