物体检测算法:R-CNN,SSD,YOLO
这,只是一段简短的介绍
目标检测
下面简单讲解目标检测里面使用的常用算法。
区域卷积神经网络
R-CNN
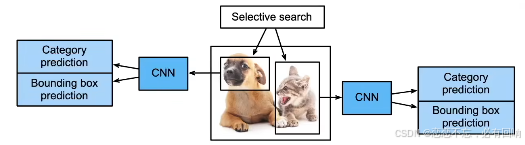
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
但是上述选择有个问题,就是锚框每次选到的大小不一样,这样如何使得这些锚框最后变成一个 batch?下面介绍 RoI Pooling
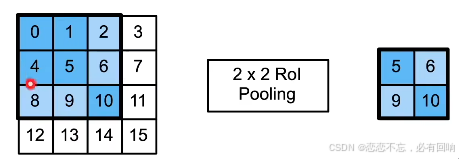
兴趣区域(RoI)池化层
- 给定一个锚框,均匀分割成 n × m n×m n×m 块,输出每块里的最大值
- 不管锚框多大,总是输出 n m nm nm 个值
- 可能切的不是很均匀,这样就需要取整
- 让每个锚框都可以变成自己想要的形状
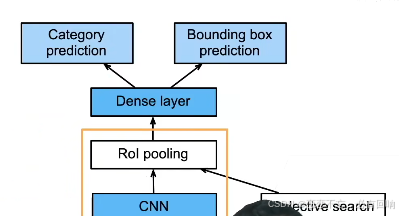
Fast RCNN
- 使用 CNN 对图片抽取特征
- 使用 RoI 池化层对每个锚框生成固定长度特征
Faster R-CNN
- 使用一个区域提议网络来替代启发式搜索来获得更好的锚框
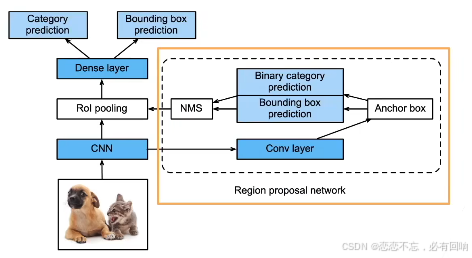
用一个神经网络来替代之前的选择性搜索的算法。
Mask R-CNN
- 如果有像素级别的标号,使用FCN来利用这些信息
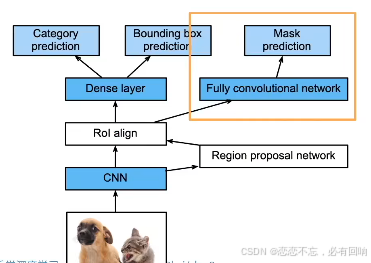
总结
- R-CNN 是最早、也是最有名的一类基于锚框和 CNN 的目标检测算法
- Fast/Faster R-CNN 持续提升性能
- Faster R-CNN 和 MaskR-CNN 是在最求高精度场景下的常用算法
单发多框检测(SSD)
生成锚框
- 对每个像素,生成多个以它为中心的锚框
- 给定
n
n
n 个大小
s
1
,
…
,
s
n
s_1, \ldots, s_n
s1,…,sn 和
m
m
m 个高宽比,那么生成
n
+
m
−
1
n + m - 1
n+m−1 个锚框,其大小和高宽比分别为:
- ( s 1 , r 1 ) , ( s 2 , r 1 ) , … , ( s n , r 1 ) , ( s 1 , r 2 ) , … , ( s 1 , r m ) (s_1, r_1), (s_2, r_1), \ldots, (s_n, r_1), (s_1, r_2), \ldots, (s_1, r_m) (s1,r1),(s2,r1),…,(sn,r1),(s1,r2),…,(s1,rm)
SSD模型
- 一个基础网络来抽取特征,然后多个卷积层块来减半高宽
- 在每段都生成锚框
- 底部段来拟合小物体,顶部段来拟合大物体
- 对每个锚框预测类别和边缘框
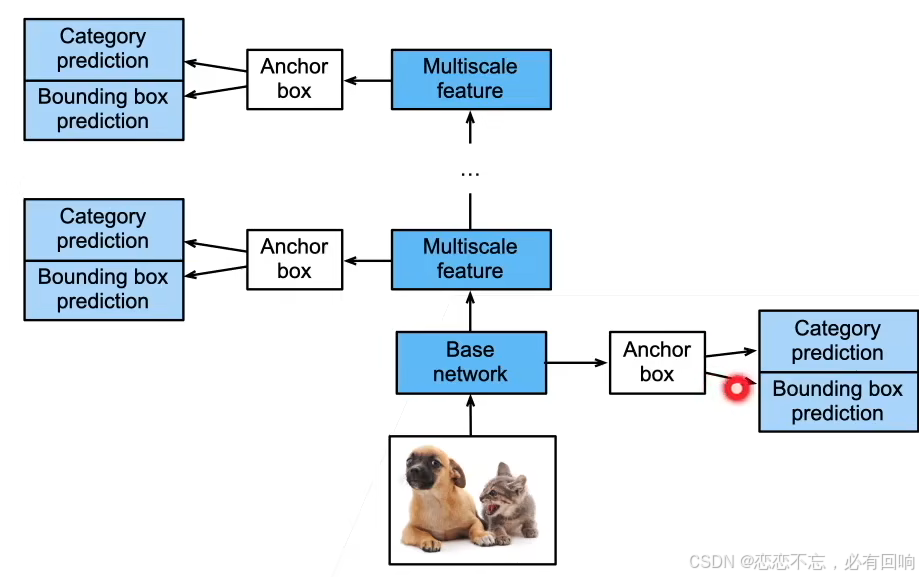
总结
- SSD通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框
- 在多个段的输出上进行多尺度的检测
YOLO(你只看一次)
- SSD 中锚框大量重叠,因此浪费了很多计算
- YOLO 将图片均匀分成 S × S S×S S×S 个锚框
- 每个锚框预测 B B B 个边缘框
- 后续版本 (V2,V3,V4…) 有持续改进
QA 思考
Q1:测试数据增强做平均,是结果做平均还是概率做平均?还是看实际情况选择?
A1:概率做平均,也就是基本上会在 softmax 上面做平均。
Q2:RoI 会不会把图片压变形?这样的话对预测有影响吗?
A2:RoI 操作本身并不直接导致图像压变形。RoI操作通常用于从图像中提取感兴趣的特定区域,以便进一步处理或分析。然而,在处理过程中如果RoI的提取或者后续处理(如resize到固定大小)不注意保持原始的比例,可能会导致所提取区域的图像被拉伸或压缩,从而出现变形的情况。
这种变形是否会影响预测结果取决于具体情况。对于大部分物体而言,由于其宽高比在一定范围内变化不大,因此即使发生轻微变形也可能不会对最终的预测结果造成显著影响。但对于一些对形状特别敏感的任务或对象(例如长颈鹿这类具有明显比例特征的对象),图像的变形可能会干扰模型的判断能力,进而影响预测准确性。
为了避免这种情况,可以在设计算法时采取措施来保证RoI操作后图像的比例不变,比如通过适当的填充或是采用能够适应不同比例输入的网络结构等方法。这样可以最大限度地减少因图像变形带来的不利影响。
Q3:锚框的位置怎么在训练过程中越来越接近目标框?
A3:在训练过程中,锚框的位置通过最小化定位损失逐渐接近目标框,利用梯度下降算法根据损失函数的反馈调整锚框的坐标偏移量,同时结合分类损失确保锚框正确分类,随着迭代优化,锚框不仅位置逼近目标框,其大小和形状也逐步调整以匹配目标框的实际尺寸,从而实现精准的目标检测。