【Linux网络】以太网(数据链路层)
认识以太网
两台主机在同一个局域网下是可以进行通信的,因为每台主机都有自己的标识符.
太网是负责直接相连的两个设备之间的可靠数据传输,"以太网" 不是一种具体的网络, 而是一种技术标准; 既包含了数据链路层的内容, 也包含了一些物理层的内容.在局域网中,通过物理地址(MAC地址)识别设备,将数据封装成帧进行传输
以太网帧格式

MAC 地址是唯一的,每一台设备的网卡都有唯一的MAC地址号,是由48位二进制进行组成,通常前24位代表厂商代码,后24位由厂商进行自主分配
-
目的MAC地址(6字节):接收设备的物理地址,相当于目的主机的身份号。
-
源MAC地址(6字节):发送设备的物理地址,相当于发送方主机的身份证号,用于告诉接收方这条数据的来源也为了进行接收目的主机的确认和处理后的数据。
-
类型/长度(2字节):标明数据部分属于哪种协议(如IPv4、ARP)。
-
数据(46-1500字节):实际传输的信息。
-
帧校验序列(FCS)(4字节):用于检测传输中是否发生错误(如CRC校验)。
如何进行分离?
以太网帧的报头是采用定长的方式,一共是14个字节.
如何进行分用?
通过以太网帧头中的数据类型,数据链路层根据此字段决定将数据提交给哪个网络层协议处理
基于协议重谈是局域网进行数据转发的原理

数据包通过数据链路层的协议进行封装成数据帧,数据帧在局域网中进行传输时是可以被局域网中的所有主机进行查看到的(监听),当非目标主机进行识别数据帧发现目的MAC地址并不是自己后就会将监听的数据进行丢弃,只有当目的主机进行收到数据后会将数据进行获取.
抓包原理
这里说一下抓包工具的原理,抓包工具的原理依赖于将网卡设置为混杂模式(Promiscuous Mode)。默认情况下,网卡仅接收目标地址为本机MAC或广播/组播的数据帧,而混杂模式会解除这一限制,使网卡接收所有流经其物理接口的数据帧。
在集线器(Hub)网络中,混杂模式可捕获局域网内所有流量;但在交换机(Switch)网络中,由于交换机仅转发目标相关的流量,需结合ARP欺骗、端口镜像等技术才能实现类似效果。
抓包工具(如Wireshark)需通过内核接口(如libpcap)获取原始数据,并依赖管理员权限开启混杂模式
数据碰撞问题

由于在局域网中,任意两台主机进行通信,其他主机也是可以机型看到数据帧的,当同一时刻由不同的主机在局域网中进行发送数据,就会导致局域网中的数据发生碰撞,数据在物理层进行传输是通过二进制的形式,类似于物理中的波纹,一旦出现数据碰撞问题,就会导致数据无效.
进行思考,为什么要将数据进行分片(站在数据链路层)
一定程度进行减少数据碰撞
避免数据进行碰撞的策略
主机中是有碰撞检测和碰撞避免的算法的
通过交换机进行"隔绝"

交换机进行识别局部新碰撞,对碰撞的数据不进行转发,左侧已经发生数据碰撞了,直接进行"隔绝",m1->m6进行发送数据也不在进行转发,防止左侧的碰撞影响右侧的正常通信.
ARP协议

同一个局域网下的主机(主机和主机,主机和路由器,路由器和路由器)之间我们是是默认他们之间可以进行正常的通信的,但是我们现在知道了在同一局域网下进行通信必须知道对方发MAC地址,这是如何进行得知对方的MAC地址的呢?这就涉及ARP协议。
ARP数据报的格式
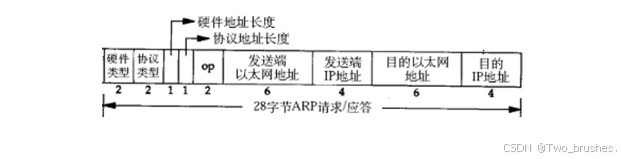
协议的原理

以一号路由器和九号主机进行通信为例
数据到达目标网络,只知道对应目标主机的IP地址,并不知道MAC地址,要想进行通信,首先要先进行ARP申请,将数据包进行封装上ARP报文,由于不知道目的主机的IP地址,目的MAC地址字段填写为全0或者空代表不知道目的主机的MAC地址,然后交给MAC帧,由MAC帧进行封装上以太网帧报头,将以太网目的MAC地址继续进行填写成FFFFFF代表不知道目的主机的MAC地址,然后把数据发送到局域网上,由于目的主机的MAC地址是FFFFFF,所有主机都可以进行获取这个以太网帧,获取数据后进行通过MAC帧进行解包,然后分析报文中的OP,先看是请求还是应答,然后通过对比目的IP和自己的IP是否一致,如果不一致将数据进行丢弃;如果一致,进行应答,这次应答是知道对方的IP地址和MAC地址的,通过应答将自己的MAC地址进行通知对方,这就是ARC协议的原理.
整体进行理解网络通信的流程
应用层:
应用程序通过
socket()创建套接字,并(服务器端)调用bind()绑定端口。TCP 需要
connect()进行 三次握手 建立连接,而 UDP 直接发送数据。传输层:
TCP:数据拆分为多个 TCP 段,加上 TCP 头部(包括序号、校验和等),然后传给网络层。
UDP:数据加上 UDP 头部(源端口、目标端口、长度等),传给网络层。
网络层(IP):
添加 IP 头(源 IP、目的 IP)。
检查数据长度,若超过 MTU,则进行 IP 分片。
通过 路由表 查找下一跳,发送给路由器。
链路层(以太网/无线):
先查找 ARP 缓存,获取目的 IP 对应的 MAC 地址。
如果没有,则发送 ARP 请求获取 MAC 地址。
组装 以太网帧(源 MAC、目标 MAC、数据)。
通过交换机/无线 AP 传输数据,最终到达目的 MAC 地址的主机。
目标主机接收数据:
网卡检查 MAC 地址匹配后,将数据交给 网络层。
网络层检查 IP 地址匹配后,将数据交给 传输层(TCP/UDP)。
传输层根据端口号交给 应用层 处理(如 HTTP 服务器解析请求)。
ARP欺骗
为什么会存在ARP欺骗
ARP是被缓存的,将一些主机的IP和MAC地址进行缓存到ARP缓存表中,并且缓存表是会进行动态更新的,ARP在进行收到应答时,会以最新的为主.

ARP欺骗的原理
ARP欺骗的基本原理是通过伪造ARP响应(即伪装成目标设备的响应)来修改局域网中设备的ARP缓存表。具体来说,ARP是用来将IP地址映射到MAC地址的协议,在局域网内设备之间进行通信时,发送方会查找目标IP地址对应的MAC地址。如果ARP缓存表中没有该映射,设备会广播一个ARP请求,询问网络中谁拥有该IP地址,并希望获得其MAC地址。正常情况下,目标设备会回应其MAC地址。
而在ARP欺骗中,攻击者伪造一个ARP响应,宣称自己的MAC地址对应目标IP地址(或者伪造目标设备的MAC地址对应自己的IP)。这样,目标设备就会将攻击者的MAC地址映射到错误的IP地址,造成数据流向攻击者,而不是正确的目的地。
重新看待OSI七层模型
表示层--协议的定制,序列化和反序列化


DNS协议
网络协议栈中只有IP,我们通过访问网站都是用的域名,便于互联网的商业化而DNS协议就是用于域名转化成IP地址.
早期实现的原理:配置文件进行建立关系
DNS协议的基本工作原理:
-
查询过程: 当你在浏览器中输入一个网址时,计算机会首先查询本地的DNS缓存,看看是否已有该域名对应的IP地址。如果没有,它会向配置的DNS服务器发起查询请求。
-
递归查询: 如果本地DNS服务器没有该信息,它会向更高层级的DNS服务器发起递归查询,直到找到权威DNS服务器并返回域名对应的IP地址。
-
权威DNS服务器: 每个域名都有一个或多个权威DNS服务器,负责存储并提供该域名的实际解析记录。当递归查询最终到达权威DNS服务器时,它会提供正确的IP地址。
-
缓存机制: 为了加快解析过程,DNS服务器会缓存域名和IP地址的映射关系。缓存数据有时效性,称为TTL(Time To Live)。TTL过期后,DNS服务器会重新查询。
域名解析服务器是多叉树的结构,先进行问自己最近的服务器,本质kv映射
底层是UDP
根域名服务器(AI)
开始回答并不是回答问题的本身,而是组织进行框架条理
纯应用层,忽略OS为我们做的
非常好的体系,非常好表达能力
热爱生活保持乐观
ICMP协议
ICMP协议的功能

网络出现问题了,网络排查故障的功能
一些常用的命令
ping命令

- 此处 ping 的是域名, 而不是url! 一个域名可以通过DNS解析成IP地址.
- ping命令不光能验证网络的连通性, 同时也会统计响应时间和TTL(IP包中的Time To Live, 生存周期).
- ping命令会先发送一个 ICMP Echo Request给对端; 对端接收到之后, 会返回一个ICMP Echo Reply;
注意:
ping命令基于ICMP, 是在网络层. 而端口号, 是传输层的内容. 在ICMP中根本就不关注端口号这样的信息
traceroute命令
是一个网络诊断工具,用于显示数据包从源主机到目标主机的传输路径。它可以帮助分析数据在互联网上的路由情况,通常用于排查网络延迟或路由问题。
语法
traceroute [options] <destination>

---------------------------------------------------------------------------------------
NAT技术
NAT IP转换技术


NAT IP 技术原理
源IP不断进行替换的技术称为NAT IP转换技术.
NAPT技术
当局域网下的 私有 IP 设备 访问公网时,数据包经过 NAT 设备(如路由器),其源IP地址不断进行替换成路由器的LAN口IP,最后被替换为公网IP,然后发送到公网服务器。服务器在处理完请求后,将数据返回到该公网 IP 地址。但此时,服务器 只能看到 NAT 设备的公网 IP,而无法直接识别原始的私有 IP 地址,因此返回的数据仅能到达路由器,而路由器需要知道如何将数据包正确分发回 具体的内网设备。
然而,每台主机都运行着 TCP/IP 协议栈,而多个进程或线程可能同时访问同一个服务器,如果 NAT 仅仅进行 IP 地址转换,那么所有访问公网的请求都会显示相同的公网 IP,导致 返回数据无法区分不同的内网主机或进程。这时,NAPT 技术(也称 PAT,端口地址转换) 通过在 NAT 映射表中 记录端口号,使得路由器在收到服务器返回的数据时,能够根据 端口号 找到具体的内网 IP 和进程端口号,并将数据正确返回给对应的主机和进程。
NAPT的技术原理
唯一的四元组 源IP+源端口号 目的IP+目的IP端口号
转化表中进行维护的就是唯一四元组。

-
出站连接:当内网主机向外部网络发送数据包时,NAPT 路由器会记录数据包的源 IP 地址和端口号,然后将这些信息转换为公共 IP 地址和一个新的、唯一的端口号。转换后的映射关系会存储在转换表中。
-
入站数据:当外部服务器回复数据时,数据包会携带目的公共 IP 地址和目标端口号。NAPT 路由器通过查找转换表,确定原始的内网 IP 地址和端口号,将数据正确地转发到相应的内网主机。
代理服务器
反向代理服务器

反向代理服务器时在客户端和公司服务器之间的服务器,代理用户进行请求,通过很多算法进行分摊流量使得服务器集群中的服务器尽可能的负载均衡,防止客户端进行访问公司服务器主机集群时,用户全部进行访问的是这个服务器主机集群中的某一部分,造成服务器主机集群的忙先不均问题,严重甚至某个服务器主机压力过大,导致整个服务器集群崩溃的问题。
正向代理服务器

正向代理服务器时在客户端和公司服务器之间的服务器,代理客户端进行访问资源,由于网络限制或隐私保护,客户端无法直接访问目标服务器,因此请求会先发送给正向代理服务器。正向代理服务器代表客户端访问目标服务器,并获取数据。正向代理服务器将数据返回给客户端,让客户端以为自己直接访问了目标服务器,并且正向代理服务器代理用户进行访问服务器中的资源然后将资源进行返回,这个资源在正向服务器中进行缓存,当其他的客户端进行访问相同的资源时,直接进行访问正向服务器中的资源,不需要再进行访问目标服务器中的资源,提高访问效率,减少目标服务器中的压力。