文件操作和IO ——Java
初识文件
首先文件分为:
1.狭义的文件 – 保存在硬盘上的文件。
2.广义的文件 – 操作系统进行资源管理的一种机制。很多的软件/硬件资源,抽象成“文件”来进行表示。
(println => 控制台,scanner => 控制台的标准输入)
当前咋们主要谈的是 狭义的文件。
我们简单说说 硬盘 内存 cpu寄存器 分别在 存储空间 访问速度 成本 和持久化 上的不同点

其中硬盘分为 机械硬盘和 固态硬盘 ,固态硬盘(通常读写速度,1s几百GB)不管是速度还是价格都比机械硬盘(读写速度,1s几个MB)高上不少。
计算机中,目录套目录,构成了 树形结构(N叉树)

一台计算机中,能够保存的文件是很多的,那如何区分/识别唯一的一个文件呢? => 路径(定位到文件的一系列过程)
从树根开始,到最终的文件,中间都需要经历哪些目录,把这些目录记录下来,就够成“路径”。路径中一般使用 / (路径分隔符)来分割 路径中的多级目录。
在主流的操作系统中,都是使用 / 来分割的。但是 Windows 是例外。Windows / 和 \ 都支持(但是 Windows 默认使用 \)。
不过写代码的时候,涉及到路径,建议写成 / 。因为 写成 \ 早字符串中就需要转义的。

路径分为相对路径和绝对路径:
从树形结构的角度来看,树中的每个结点都可以被一条从根开始,一直到达的结点的路径所描述,而这种描述方式就被称为文件的绝对路径;除了可以从根开始进行路径的描述,我们可以从任意节点出发,进行路径的描述,而这种描述方式就被称为相对路径,相对于当前所在结点的一条路径。(相对路径需要明确一个“基准路径”)
例:



虽说谈到相对路径,要先明确基准路径。
但是如果在代码中写一个“相对路径”,那基准路径是谁呢??

在这里面中,基准路径是谁?不确定,这个取决于你程序允许的方式!
确认基准路径:
1.在 IDEA 中直接运行,基准路径就是项目的目录。

2.打一个 jar 包,单独运行 jar 包(后面说)
当前在哪个目录下执行运行命令(jar -jar jar包名),基准目录就是哪个目录。
3.如果是打成一个 war 包,放到 tomcat 中运行,此时基准目录就是tomcat的 bin 目录(未来再说)
文件的种类:
从开发的角度,把文件分为两类:
1.文本文件
2.二进制文件
(大前提,所有的文件都是二进制的(冯诺依曼大佬最初定下的规矩),但有一些文件是特殊的,二进制数据刚好能构成字符(不仅是ascii)== 二进制数据恰好都在码表上能够查到,并且翻译过来的字符能够构成有意义的信息。)
实际开发中判断某个文件是否是文本,有个简单粗暴的方法:
直接使用 记事本打开(记事本就是按照文本的方式来打开的,自动进行查码表,翻译),打开之后不是乱码,能看懂 ,就是文本文件,如果打开之后是乱码,看不懂,就是二进制文件。
Java中操作文件
Java标准库提供了一系列的类来操作文件:
- 文件系统操作(创建文件,删除文件,重命名,创建目录…)
- 文件内容操作(针对一个文件的内容进行读和写了)
文件系统操作:
Java 中通过 java.io.File 类来对⼀个⽂件(包括⽬录)进⾏抽象的描述。注意,有 File 对象,并不代表真实存在该⽂件。
我们来看看File 类常见的构造方法和方法:
构造方法:

常见方法:

代码示例:
案例1:


有个要注意的是,如果构造方法中传的路径是相对路径,那么getpath方法得到的就是相对路径,如果构造方法传的是绝对路径的话,那么getpath方法得到的就是绝对路径。
getCanonicalPath(会抛出异常)就是getAbsolutePath的简化版本,把路径中间的 . 或者 … 给干掉。
案例2:


creatNewFile方法会抛出异常:

那啥样的情况会出现异常呢?
1.硬盘满了
2.没有权限
3.硬盘坏了(cpu和 内存 非常抗造的,硬盘相比之下就脆弱很多,尤其是机械硬盘)
案例3:


观察deletOnExit方法;


deleteOnExit 是等进程结束后再删除文件。
进程退出时删除文件的使用场景:
在 word,ppt,excel 做一些大作业时,当你写了很多内容,突然,你的电脑没电了,然后文档也没保存。但是当你再次打开word,word提示你是否要恢复上次未保存的内容。
office 系列的产品,都会在你编辑文档的过程中,产生一个 隐藏的临时文件,这个临时文件就会同步实时保存你正在编辑的内容。
如果你的office 正常关闭了,此时这个临时文件就会自动删除(deleteOnExit),下次启动office,认为你上次是正常保存的,不会提示。
如果office异常关闭(突然断电),这个临时文件就任然存在,下次启动 office ,就可以从这个临时文件中,恢复你上次正在编辑的内容
(类似于这样的功能,服务器端也会涉及到,一些临时性的文件)
案例4:


list 只是列出当前目录里面的子元素,无法列出子目录中的内容(也就是孙子元素)。
list得到是文件名(String)(不推荐),listFiles得到的是 File 对象,包含更多的操作。(推荐)
案例5:



注:mkdir无法创建多级目录,只能创建一级。
但mkdirs()可以解决这个问题,可以创建多级目录。
案例6:


重命名还能起到“移动”的作用



从操作系统的角度来看,重命名和移动操作本质是一样的,这个移动操作通常速度极快(如果你的移动操作 跨硬盘 了(不是跨C盘D盘这种),此时就相当于 复制 + 删除,此时的速度就慢了),复杂度O(1)。
复制文件,复杂度就是O(n)。文件/目录里所有的数据,遍历,再写入写的文件/目录。
文件内容操作:
读写文件
Java 中针对文件内容的操作,主要是通过一组“流对象”来实现的
那是什么是“流”?

因此,计算机中针对读写文件,也是使用 流(Stream)词。流是操作系统层面的术语,和语言无关。各种编程语言操作文件,都叫流。
Java中提供了一组类,表示 流。有几十个,很多,这里就讲几个重要的。
针对上述几十个流,分为两个大类:
- 字节流:读写文件,以字节为单位,是针对二进制文件使用的。
InputStream 输入 从文件读数据
OutputStream 输出 往文件写数据 - 字符流:读写文件,以字符为单位,是针对文本文件使用的。
Reader 输入 从文件读数据
Writer 输出 往文件写数据
(字节 != 字符,一个字符可能是对应多个字节?? => 不确定,这个是取决于编码方式(字符集))
Java中的其他流对象,都是直接或间接继承这些类。
什么叫输入,什么叫输出:
根据数据的流向:
从硬盘 => CPU 输入
从CPU => 硬盘 输出
InputStream
InputStream 只是⼀个抽象类,要使⽤还需要具体的实现类。关于 InputStream 的实现类有很多,基本可以认为不同的输⼊设备都可以对应⼀个 InputStream 类,我们现在只关⼼从⽂件中读取,所以使⽤ FileInputStream。

FileInputStream的构造方法:

这里的创建对象操作,一旦成功,就相当于“打开文件”。类似C语言的 fopen。
毕竟,操作系统定义的流程,就是先打开,然后才能读写。认为 打开操作,就是根据文件路径,定位到对应的硬盘空间。

关闭文件操作。(非常重要)
类似内存一样,像C++,申请内存,释放内存(手动挡),对于Java,内存只要申请就行了,释放交给 GC 自动完成(自动档)。
但是文件资源不同于内存资源,虽然 GC 能够自动管理内存,但是不能自动管理文件,需要我们自己手动释放,如果不手动释放,就会引起“文件资源泄露”,类似于“内存泄漏”。
为了避免写代码的时候忘记写close方法,我们可以这样写代码:

但是,还有一个问题,上述代码有点繁琐,也就是有点“丑”。为了更进一步,我们可以用到 try with resources 语法来使代码更简洁一点。

只要出了 try 就会自动调用 close 方法。
当然,也不是所有类都能写到 try 的()内,这里要求这个类需要实现 Closable 接口。

约定好这个类一定有 close 方法,可以让 JVM 自动调用。
InputStream 的一些常用方法:

例子:


有的时候,这样写出的代码会报错,原因就是在该路径上没有此文件。

我们在demo文件中写个 “hello”,看看能打印出什么。

为什么呢?
因为read无参数版本,是按照字节读取的,一个一个字节取出来,分别打印的,每个字节的范围是 0 - 255 ,而 hello 是纯英文,根据 ASCII 码表,转换成10 进制。就是那5 个数字了。(十进制是正常的, 八进制是 0 开头,十六进制是 0x开头)

我们现在把demo文件换成“你好”,看看能打印出什么结果。

结果:

这是根据utf-8编码的,一个汉字是3个字节,所以“你好”就一个六个字节。

这样子看不吃来,我们把结果换成十六进制。(一个十六进制数字就是 4 bit ,两个 十六进制数字 就是 1个字节)

从上到下就是 ”你好“ 的十六进制编码。
接下来使用第二种read(byte[] b)方法
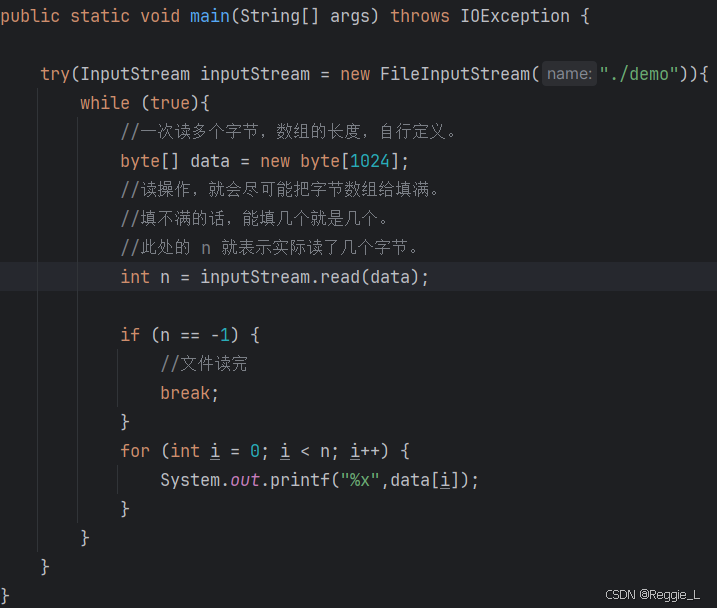
输出结果和上面是一样的

我们要提一下这一段代码:

这个代码是使用 参数作为方法的返回值,它在 C++中非常常见,但在Java中就比较少见了。它也被称为“输出型参数”。也就是刚创建的时候,我的数组是空的,n也为 0,但是通过read这个方法, data 和 n 上面就变成一些有意义的数据了。
有的时候也会使用参数来接受返回值,毕竟在Java中,如果参数是引用类型,方法内部修改对象内容,是能够影响到方法外部的。
其实,输出型参数,本质上还是语法上制约了我们的发挥。Java C++中,要求一个方法只能有一个返回值,如果希望返回多个数据(上述 read 就是希望同时返回 长度 和 数组内容)就只能通过参数来凑了,但同样的问题,在 Python ,GO是不存在的。都支持一个函数同时返回多个值。
OutputStream
OutputStream的一些常用方法:

注:
第一个write 的参数类型是 int 。为什么不是byte 呢?
因为 参数的取值范围是 0 - 255, 如果用 byte 类型, byte 的取值范围是 -128 -> 127,但是 Java中没有 unsigned 类型,byte类型就不能完全包含,所以就用int 了。
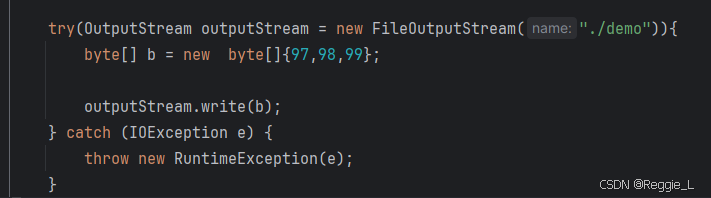
代码案例:


这中间关于 OutputStream 还有一个知识:
我们在上述代码,再多写几个 write,再看看 demo 文件内容会发生什么变化。


代码运行了两次,按照我们的期望来说,demo 文件中的内容应该是 abcabcdef ,但为什么只有 abcdef 呢?第一次的abc 去哪里了呢?
这是因为对于 OutputStream 来说,是会清除上次的文件内容的,打开文件的一瞬间,上次的文件就清空了。就像 C 语言中,按照写方式打开文件,也会有同样的特性,这是操作系统的行为,与语言无关。(而且对于 OutputStream 来说,默认情况下会尝试创建不存在的文件,也就是你给OutputStream 传的文件路径中,如果没有该文件没有创建,OutputStream 会自动创建该文件)
对于该问题,我们可以追加写的模式(也就是在传入一个参数true,默认情况是false),来避免内容被清空。



Reader(和 InputStream 一样,只不过适用的场景不同)
Reader 的常用方法:

代码案例:







注:

read 返回的相当于是一个 char,两个字节,所以上面的 “你”“好”分别是两个字节。但是这里就有一个问题了,砸门在前面使用字节流读取的时候,这里的“你”“好”都是 3 个字节。这里面是不是有什么问题呢?
其实,字符流和字节流的两个代码,都是对的,不矛盾的。字节流读到的是文件中原始的数据,在硬盘上保存文件的时候,就是 6 个字节,utf8 编码。字符流在读取的时候,就会根据文件的内容编码格式,进行解析,read()一次,就会读到3个字节(按照utf8解析的),返回的时候,针对3个字节进行转码了,拿着3个字节utf8的码表“你”汉字,read就把 “你”这个汉字在 Unicode 这个码表中再次查询了一次,得到Unicode的编码值,最终把 Unicode 的编码值返回到 char 变量中(两个字节)。
不过,这里会自动进行转码。转码也是有性能开销的,所以字节流比字符流快,确实也是毋庸置疑的。
Writer(和OutputStream一样)
Writer的常用方法:

代码案例(和OutputStream一样不清楚的可以参照OutputStream的案例):






当然,和OutputStream一样,每次调用Writer 都会清除上次的文件内容。如果想要保存上次文件内容,也是多传入一个参数 true。
小小的总结一下:
1.流对象的使用流程
先打开,再读写,最后关闭。
2.应该使用哪个流对象?
先区分文件是文本文件还是二进制文件,再区分读还是写。
看到这,顺便再提一个别的小知识点 = 缓冲区
缓冲区,通常就是一段内存空间,他是用来提高程序的效率。
通常如果直接读写硬盘,是比较低效的(硬盘速度慢),因此有的时候,就希望减少读写文件的次数。因此在进行 IO 操作的时候,就希望能够使用缓冲区,把要写的数据,先放到缓冲区里攒一波,再一起写,或者读的时候,也不是一个一个的读,一次读一批数据,到缓冲区中,再慢慢解析。
当前 IO 流对象,read 和 write 就属于直接读文件了。要想要提高效率:
1.写代码的时候,手动创建缓冲区(byte[]),手动减少 read write 次数。
2.使用标准库提供的“缓冲区流” BufferStream ,就是把 InputStream 之类的对象套上一层。(就是用起来比较麻烦)