文章目录
-
- 3.6 爬取当当网数据
-
- 3.6.1 创建项目
- 3.6.2 查找要爬取的数据对象
- 3.6.3 保存数据
3.6 爬取当当网数据
3.6.1 创建项目
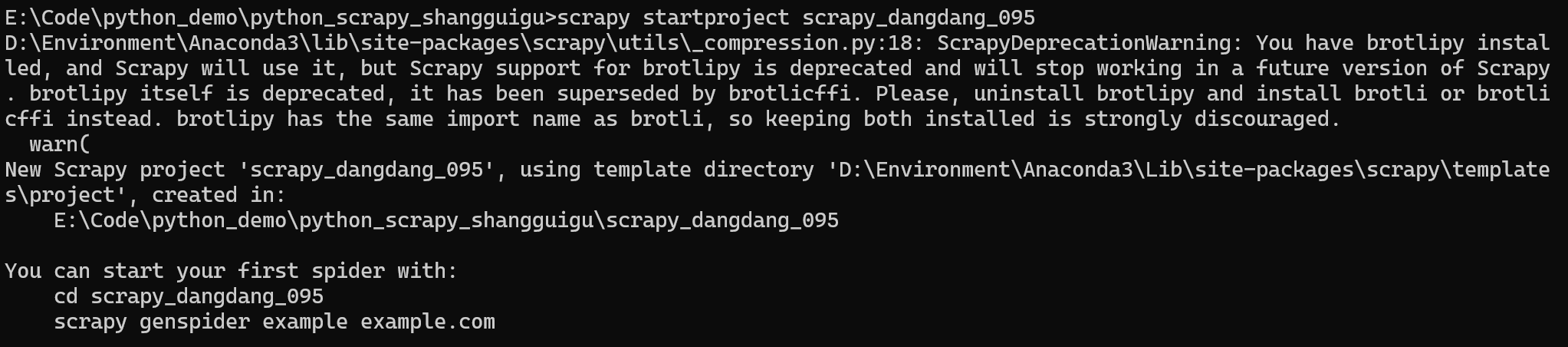
【1、创建项目】:
scrapy startproject scrapy_dangdang_095
【2、创建爬虫文件】
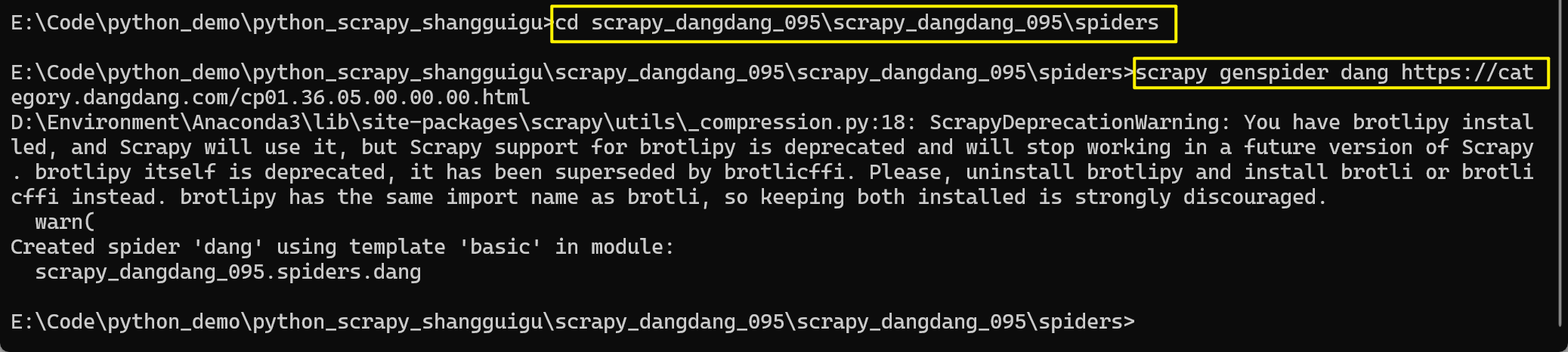
cd scrapy_dangdang_095\scrapy_dangdang_095\spiders
scrapy genspider dang https://category.dangdang.com/cp01.36.04.00.00.00.html