RNN模型与NLP应用——(6/9)Text Generation(文本自动生成)
声明:
本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。
材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用】
视频链接:RNN模型与NLP应用(6/9):Text Generation (自动文本生成)_哔哩哔哩_bilibili
一、学习目标
1.学习文本自动生成的基础原理
2.学会搭建文本自动生成模型
3.掌握代码实现文本自动生成模型
二、Text Generation
(1)Main Idea——文本生成原理
1.样例说明:
我们现在有一段话“the cayt sat on the ma”,那么问题是:下一个字母是什么?
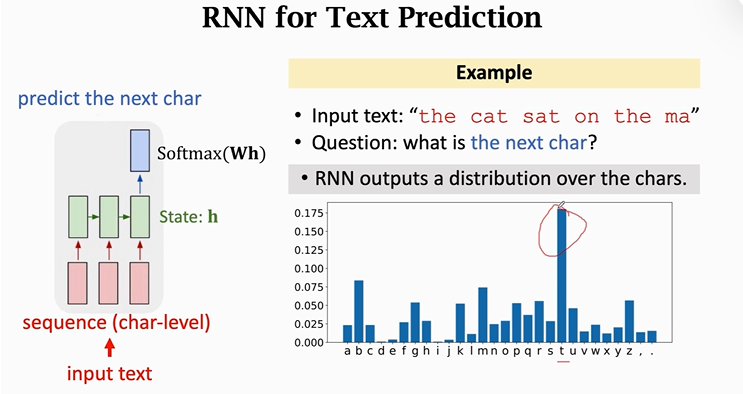
我们可以像上图一样
【首先】假设我们已经训练好了一个神经网络,将输入文本序列进行切分并处理成noe hot向量,再将向量输入给RNN模型,最后用输出的状态向量h与参数W相乘,用softmax分类器分类输出概率分布。
【next】假设这个神经网络已经训练好了,我们将“the cayt sat on the ma”输入给神经网络后,神经网络最上层的分类器就会输出这些个分类值
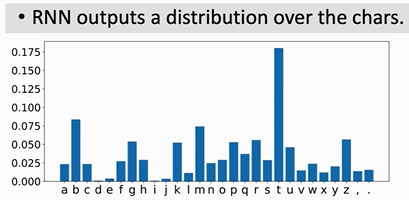
有了这些概率值,我们就可以预测下一个字母了。
【输出】有了概率值,我们可以选择输出最大概率的字母,也可以选择随随机输出。那么对于阳历文本“the cayt sat on the ma”来说,我们下一个可能会输出‘t’。
2.如何训练RNN

给定一个训练本文,设置好序列片段长度seg_len=40(如上图红色部分有40个字符的长度)和步长steride=3(意思是下一个片段会向右平移3个字符长度)。如下图:

红色部分作为神经网络的输入,蓝色字母作为标签(目标值),这些红色的输入文本和蓝色的标签将会被作为训练数据进行对神经网络的训练。
其实这就像是一个多分类问题,将设输出字母包括空格,标点符号在内一共有50个不同的字符,那么类别的数量就是50,输入一个片段,就会输出50个概率值。
训练出来的神经网络是什么样的,显然取决于你的训练文本。假如你用莎士比亚的文本作为训练文本,那么训练出来的神经网络的风格就偏向于莎士比亚风格。
(2)搭建文本生成神经网络
1.准备训练数据
随便拿一本书作为训练数据:
为了方便,我将字符串中所有字母都变为小写字母

设seg_len=60,每段片段长度为60,设置步长为3,将segment存入segments[ ]列表里,把下一个字符存入next_chars列表里,具体如下:

2.处理数据
把一个字符变成一个向量,那么一段序列片段就会变成一个矩阵。
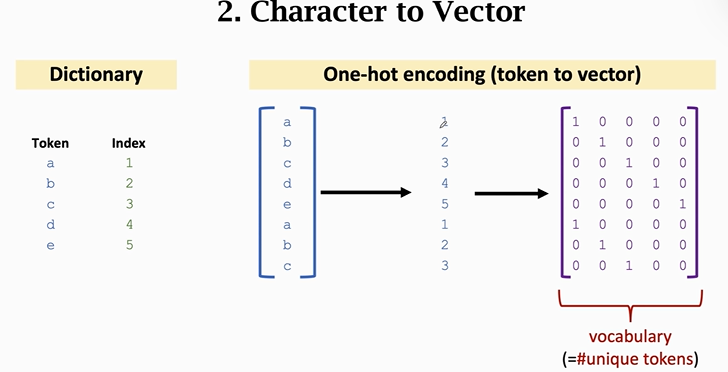
前几节课里得到one hot 向量后,还需要建立embedding层用一个低维词向量来表示一个词。
但本节内容中不需要用embedding层,原因如下:
前几节课我们将一句话分为多个单词,一个训练数据里常用的一个英文单词有10000多个,那么构成的one hot向量也就有10000维,如果不用embedding层处理的话,维度过高。
而这里我们是将一个片段分为多个字符,包括字母、标点、空格在内所有字符最多100维,因此构成的one hot向量最高也才100维。

v=57是指常用字符共57个,因此每个长度为60的片段就变成了一个60×57的矩阵,标签就变成了57×1的矩阵
3.搭建神经网络
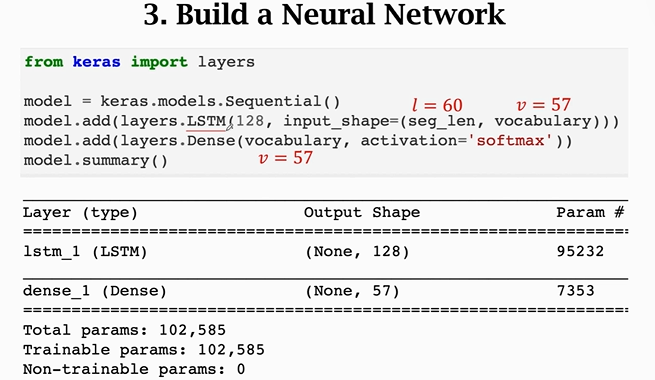
【注意】这里只能用单向LSTM,不能用双向LSTM,因为文本生成需要预测下一个字符,因此只能从前往后读取数据
4.编译拟合模型

x 对应一个60×57的矩阵,y对应标签即下一个字符
5.技术细节

x_input就是上文,pred的每一个元素都是一个概率值,每一个概率值代表着下一个字符的概率
那么有了概率值,我们该如何生成下一个字符呢?
【方法一】选取最大概率字符并输出

这种方法是确定性的,没有随机性,相当于一开始的输入就已经决定了后面的输出。所以这种方法不好
【方法二】从多项式分布中随机抽取

这种抽样过于随机,会发生很多语法错误或单词拼写错误
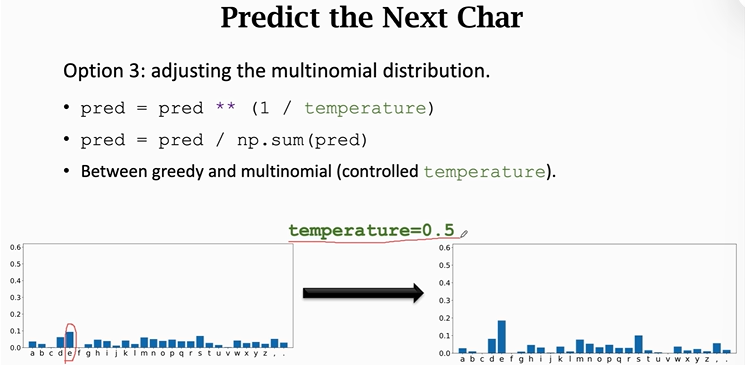
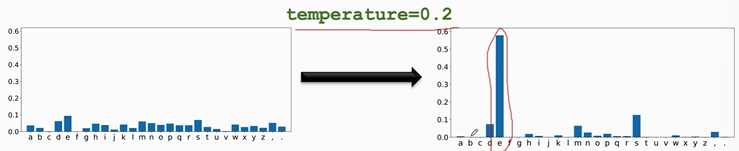
【方法三】temprature

temprature是一个介于0和1之间的数,先将概率值做幂变换,再进行归一化。做这种变换后大的概率值会更大,小的会更小。
例如:
三、文本为生成实例:


【注意】文本生成不是凭空生成,你需要喂给模型一个种子数据"Initial input (seed)"
四、总结

1.训练文本化成多个sigments片段
2.对字符做noe hot encoding(v是字典长度,l是序列长度)
3.建立和训练一个神经网络

1.提供种子数据
2.文本生成下一个字符
①把每一个segment做noe hot encoding
②神经网络输出一个概率分布
③根据概率值选择下一个字符
④把新生成的字符接到原文本后面,作为神经网络新的输入开始下一轮循环