快速在 Windows 平台上高效安装flash_attn库
快速在 Windows 平台上高效安装flash_attn库
flash_attn全称是FlashAttention, 它是一个为加速注意力机制(Attention Mechanism)设计的库,能够显著提升深度学习模型的性能。很多AI项目都会使用到这个框架,普通PC在window平台安装过程需要非常漫长的时间,很多涉及flash_attn的项目都使用linux系统,本文将总结自己在 Windows 平台安装 FlashAttention方法。
1. 安装 FlashAttention
1.1 准备工作
在开始之前,请确保你的系统满足以下要求:
- 操作系统:Windows 10 。
- Python 版本:3.10(支持更高的版本)。
- CUDA 工具包: CUDA 工具包12.6。
- PyTorch: PyTorch 2.x 版本。
1.2 安装flash_attn库
安装flash_attn库具体步骤:
1.2.1 下载编译源码制造轮子
如果是正常安装会从编译源码开始,在window平台会花费非常长的时间,
pip install flash_attn
编译代码过程如下图:
编译成功如下图:

本人配置是I5-1140的cpu,16G内存,3060显卡,安装过程包含编译源码大概从晚上8点开始到第二天的3点多完成,花费了8小时左右,太费时了推荐使用编译好的whl包直接安装。
编译包已上传csdn,下载:https://download.csdn.net/download/qyhua/90559018
Python 3.10 和 Windows x64 系统,选择 flash_attn-2.7.4.post1-cp310-cp310-win_amd64.whl。
1.2.2 使用轮子执行安装命令
打开命令行工具并执行以下命令进行安装:
pip install flash_attn-2.7.4.post1-cp310-cp310-win_amd64.whl
下载flash_attn-2.7.4.post1-cp310-cp310-win_amd64.whl: https://download.csdn.net/download/qyhua/90559018
1.2.3 安装完成测试
使用 flash_attn_func 进行标准的 Q、K、V 输入的注意力计算。
# import flash_attn
# print(flash_attn.__file__)
import torch
from flash_attn.flash_attn_interface import flash_attn_func
# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 创建随机输入张量 (batch_size=2, seq_len=8, num_heads=4, head_dim=64)
q = torch.randn(2, 8, 4, 64, device=device).half() # Query 转换为 FP16
k = torch.randn(2, 8, 4, 64, device=device).half() # Key 转换为 FP16
v = torch.randn(2, 8, 4, 64, device=device).half() # Value 转换为 FP16
# 执行注意力计算
output = flash_attn_func(q, k, v)
print("Output shape:", output.shape)
print("Flash Attention test passed!")
测试结果如下图:
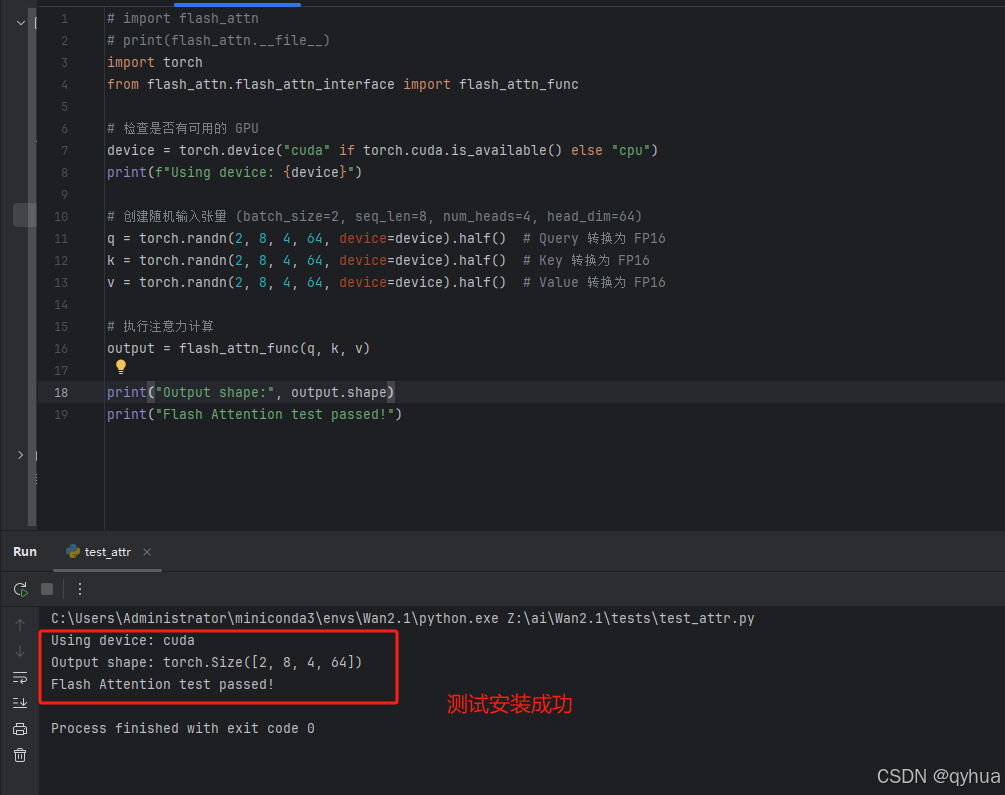
验证安装成功。
通过上述步骤,你应该能够在 Windows 平台上顺利安装并使用 FlashAttention。如果还有其他问题或需要进一步的帮助,请随时留言!