P2P网站怎么建设苏州网站建设 网络推广公司
部署Kimi-VL-A3B-Instruct视频推理
契机
⚙ 最近国内AI公司月之暗面推出了Kimi-VL开源视觉模型。模型参数16.4B,但是推理时候激活参数2.8B。看了huggingface主页的Full comparison,在多项Benchmark的时候都展示出了不俗的实力。由于业务中使用了qwen-vl-2.5-7B,所以测试下Kimi-VL-A3B-Instruct是否在更小的部署资源中拥有更好的表现。
moonshotai/Kimi-VL-A3B-Instruct · Hugging Face
安装
conda create --name Kimi-VL python=3.11.0
conda activate Kimi-VL
git clone https://github.com/MoonshotAI/Kimi-VL.git
pip install -r requirements.txt
#额外安装视频推理所需依赖
pip install opencv-python
#flash-attn的安装会访问github,如果网络没有魔法,建议尝试其他办法
pip install -U flash-attn --use-pep517 --no-build-isolation#模型下载
moonshotai/Kimi-VL-A3B-Instruct#运行期间用以下命令查看显卡资源,按照0.5s刷新一次
nvidia-smi -l 0.5
图片推理测试
代码
from tracemalloc import start
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
import timemodel_path = "moonshotai/Kimi-VL-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16,device_map="auto",trust_remote_code=True,attn_implementation="flash_attention_2"
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)while True:time.sleep(1)start = time.time()image_path = "Kimi-VL/figures/demo1.png"image = Image.open(image_path)messages = [{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "20字描述图片"}]}]text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")inputs = processor(images=image, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)generated_ids = model.generate(**inputs, max_new_tokens=512)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]response = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]print(response)print(time.time() - start)
输入输出

多次输出如下:
城市天际线,高楼林立,交通繁忙,夕阳余晖。
1.8491706848144531
城市天际线,高楼林立,交通繁忙,夕阳余晖。
1.2099909782409668
城市天际线,高楼林立,交通繁忙,夕阳余晖。
1.1886250972747803
城市天际线,高楼林立,交通繁忙,夕阳余晖。
1.1849017143249512
城市天际线,高楼林立,交通繁忙,夕阳余晖。
1.1930198669433594
资源占用
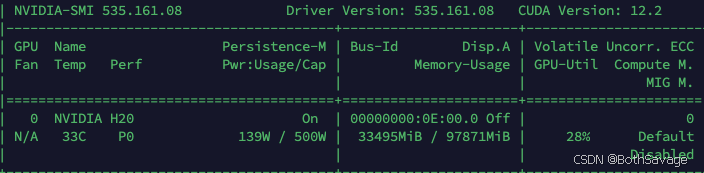
视频推理测试
代码
import time
import cv2
import argparse
import torch
import os
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor# Function to extract frames from video, save them, and return paths
def extract_frames(video_path, save_dir, target_fps=1, max_frames=1):"""Extracts up to max_frames from a video file at target FPS, saves them, and returns their paths."""frame_paths = []# Create save directory if it doesn't existos.makedirs(save_dir, exist_ok=True)try:cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"Error: Could not open video file: {video_path}")return frame_pathsvideo_fps = cap.get(cv2.CAP_PROP_FPS)if video_fps <= 0:print(f"Warning: Could not get video FPS for {video_path}. Assuming 30 FPS.")video_fps = 30frame_interval = max(1, int(round(video_fps / target_fps)))frame_count = 0saved_frame_count = 0while cap.isOpened() and saved_frame_count < max_frames:ret, frame = cap.read()if not ret:breakif frame_count % frame_interval == 0:# Convert BGR (OpenCV) to RGB (PIL)frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)img = Image.fromarray(frame_rgb)# Save frame to diskframe_filename = f"frame_{saved_frame_count:04d}.png"frame_filepath = os.path.join(save_dir, frame_filename)try:img.save(frame_filepath)frame_paths.append(frame_filepath)saved_frame_count += 1except Exception as save_e:print(f"Error saving frame {frame_filepath}: {save_e}")# Optionally continue to next frame or breakframe_count += 1cap.release()print(f"Extracted and saved {len(frame_paths)} frames to {save_dir} from {video_path} at ~{target_fps} FPS.")except Exception as e:print(f"An error occurred during frame extraction: {e}")if 'cap' in locals() and cap.isOpened():cap.release()return frame_paths# --- Argument Parsing ---
# parser = argparse.ArgumentParser(description="Describe video frame(s) using Kimi-VL model.")
# parser.add_argument("video_path", help="Path to the input video file.")
# parser.add_argument("--max_frames", type=int, default=1, help="Maximum number of frames to extract and process.")
# parser.add_argument("--save_dir", default="./test-frames", help="Directory to save extracted frames.")
# parser.add_argument("--prompt", default="Describe this video", help="Text prompt for the model.")
# parser.add_argument("--target_fps", type=float, default=1.0, help="Target frames per second for extraction.")
# args = parser.parse_args()# --- Frame Extraction & Saving ---
# extracted_frame_paths = extract_frames(args.video_path, args.save_dir, target_fps=args.target_fps, max_frames=args.max_frames)
extracted_frame_paths = extract_frames("test.mp4", "./test_kimi_frames", target_fps=4, max_frames=40)if not extracted_frame_paths:print("No frames were extracted or saved. Exiting.")exit()# --- Model Loading ---
model_path = "moonshotai/Kimi-VL-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16,device_map="auto",trust_remote_code=True,attn_implementation="flash_attention_2"
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)# --- Prepare Input for Model ---
# Load images from the saved paths
loaded_images = []
for frame_path in extracted_frame_paths:if os.path.exists(frame_path):loaded_images.append(Image.open(frame_path))else:print(f"Warning: Saved frame path not found: {frame_path}")print(f'Loaded {len(loaded_images)} images for processing.')# Construct the messages list
content = []
for frame_path in extracted_frame_paths:content.append({"type": "image", "image": frame_path})
# content.append({"type": "text", "text": args.prompt})
content.append({"type": "text", "text": '描述视频'})messages = [{"role": "user", "content": content}
]print('Messages:')
print(messages)# Process text and image paths
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")# --- Model Generation ---
while True:time.sleep(1)try:start =time.time()# Use the loaded images in the processor callinputs = processor(images=loaded_images[0] if len(loaded_images) == 1 else loaded_images, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)generated_ids = model.generate(**inputs, max_new_tokens=512)generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]response = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]print("--- Model Response ---")print(response)print(time.time()-start)except Exception as e:print(f"An error occurred during model generation: {e}")
输入输出
7s视频,每秒4帧
Extracted and saved 26 frames to ./test_kimi_frames from test.mp4 at ~4 FPS--- Model Response ---
视频开始时展示了一片宁静的海洋和蓝天,海面上波光粼粼,天空中散布着几朵白云。随后,一个世界地图的图像逐渐浮现,地图上标注了不同国家的边界。地图上方有一行日文文字,解释了蓝色代表墨卡托投影法,红色代表实际大小。地图下方有一个按钮,显示为“Show Mercator Size”,暗示可以通过点击按钮来切换地图的显示方式。整个画面给人一种宁静而开阔的感觉,仿佛置身于大海之中,同时通过地图的对比,引发对地理和地图投影的思考。
13.988295316696167
--- Model Response ---
视频开始时展示了一片宁静的海洋和蓝天,海面上波光粼粼,天空中散布着几朵白云。随后,一个世界地图的图像逐渐浮现,地图上标注了不同国家的边界。地图上方有一行日文文字,解释了蓝色代表墨卡托投影法,红色代表实际大小。地图下方有一个按钮,显示为“Show Mercator Size”,暗示可以通过点击按钮来切换地图的显示方式。整个画面给人一种宁静而开阔的感觉,仿佛置身于大海之中,同时通过地图的对比,引发对地理和地图投影的思考。
13.980722665786743
--- Model Response ---
视频开始时展示了一片宁静的海洋和蓝天,海面上波光粼粼,天空中散布着几朵白云。随后,一个世界地图的图像逐渐浮现,地图上标注了不同国家的边界。地图上方有一行日文文字,解释了蓝色代表墨卡托投影法,红色代表实际大小。地图下方有一个按钮,显示为“Show Mercator Size”,暗示可以通过点击按钮来切换地图的显示方式。整个画面给人一种宁静而开阔的感觉,仿佛置身于大海之中,同时通过地图的对比,引发对地理和地图投影的思考。
13.964439153671265
--- Model Response ---
视频开始时展示了一片宁静的海洋和蓝天,海面上波光粼粼,天空中散布着几朵白云。随后,一个世界地图的图像逐渐浮现,地图上标注了不同国家的边界。地图上方有一行日文文字,解释了蓝色代表墨卡托投影法,红色代表实际大小。地图下方有一个按钮,显示为“Show Mercator Size”,暗示可以通过点击按钮来切换地图的显示方式。整个画面给人一种宁静而开阔的感觉,仿佛置身于大海之中,同时通过地图的对比,引发对地理和地图投影的思考。
13.99526834487915资源占用

总结
- 这个显存占用也不低啊
- 纯记录
写到最后
