哪个网站做视频挣钱淘宝搜索排名
1. LoRA (Low-Rank Adaptation)
LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,原理是通过低秩分解的方式对预训练模型进行微调。
相比于全参数微调(Full Fine-Tuning),LoRA 只需要更新少量的参数。 LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。
其实这个也是我最开始研究的一块的东西, 这个是我们现实应用场景最广的的一种情况, 因为我们大部分的都不会去自己完整训练一个模型, 大部分都是微调, 而且自己训练的成本多高, 并且自己训练的效果很差, 数据集处理也非常麻烦 (我自己训练这个小模型,虽然是很小,但是在训练的轮数和数据集不优化的情况下,回答都是不太好的,但我确实也是主要是学成分高)
为啥要使用微调:(优势):
- 领域知识补充:比如医学或安全领域的知识欠缺,可以在原有模型基础上添加相关领域知识,从而提升模型性能。
- **防止灾难性遗忘:这是一个专业术语,**简单来说就是希望在学习新的领域知识时,不损失模型原有的基础能力。LoRA能很好地解决这个问题。 (下面技术原理里解释一下)
- 极大减少参数量:相比全参数微调,LoRA可减少97%以上的可训练参数
- 降低显存需求:只需要存储和更新少量参数,大幅降低GPU内存需求
2. LoRA的技术原理
数学原理 低秩适配
LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。更像是一种技巧, 是一个线性代数的数学技巧, 我个人理解
简单理解一下, 但是还是需要你会最基础的线性代数, 如果你一点都不会, 那可能还是理解不了, 但这个已经是有最简单计算基础最好理解的了
原始矩阵 (原始的模型参数) W
假设我们有一个 5×5 的原始权重矩阵 W,里面的元素是整数,这个W 是原始的模型的参数
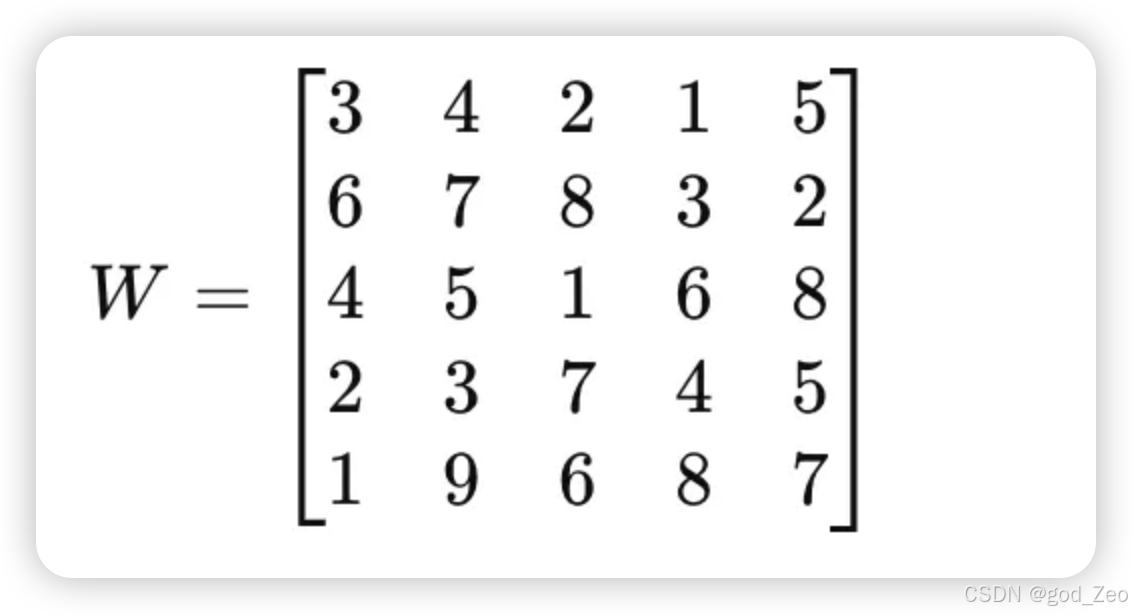
假设微调后矩阵: W’

微调之后,这些参数有一些少许的变化, 那么我们可以利用数据展开一下变成
W’ = W+ A⋅B

那么就是简单运算变成 原始矩阵 W+ AB 的矩阵, 那么我们算 AB 就可以了
然后 A*B 可以在展开, 这样一看, 参数量一下减少了

这样,我们只需要训练A和B矩阵,而不是整个W矩阵.
实际上, 在训练的时候, 效果好的时候这个参数了可以降到 0.01 %- 3% 左右
降低秩分解:
基础知识: 任意矩阵可以通过奇异值分解(SVD)分解为三个矩阵的乘积

然后我们只要 保留最大的几个奇异值, 就能用更少的近似参数表达 W
而且还可以通过保留的奇异值信息, 计算出重构的矩阵保留了多少信息, 比如保留 99%
这个奇异值分解(SVD)在LoRA中的应用非常巧妙。通过SVD,我们可以将一个大的权重更新矩阵分解成更小的组件,这样就能大大减少需要存储和计算的参数数量。这种数学技巧不仅能保持模型性能,还能显著提高训练效率。
3. 代码
现在代码比较成熟了,可以使用各种流行的框架进行微调
还可以不写代码直接微调都可以;
推荐框架: https://github.com/hiyouga/LLaMA-Factory
https://github.com/hiyouga/LLaMA-Factory
还有的 AI studio 平台都可以直接微调了
微调也和基座模型有关: 我们要关心基座模型本身的能力
4. 我的训练效果
说句实话, 因为我的这个基座模型确实不太行, 为了省钱训练的轮数都太少了, 本身回答就一般,微调之后只能说对领域有能力了,但是还是不行.
后面再训练的时候,就不会用自己模型了, 就直接拿现在最新的小参数基座模型微调了,例如 llama3.2-7b qwen-2.5-0.5b 我感觉这种都不错,.
所以我演示微调 qwen/Qwen2.5-0.5B 的医学微调吧
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir ./dir
我直接用了 cpu 微调的, 可见资源消耗确实少

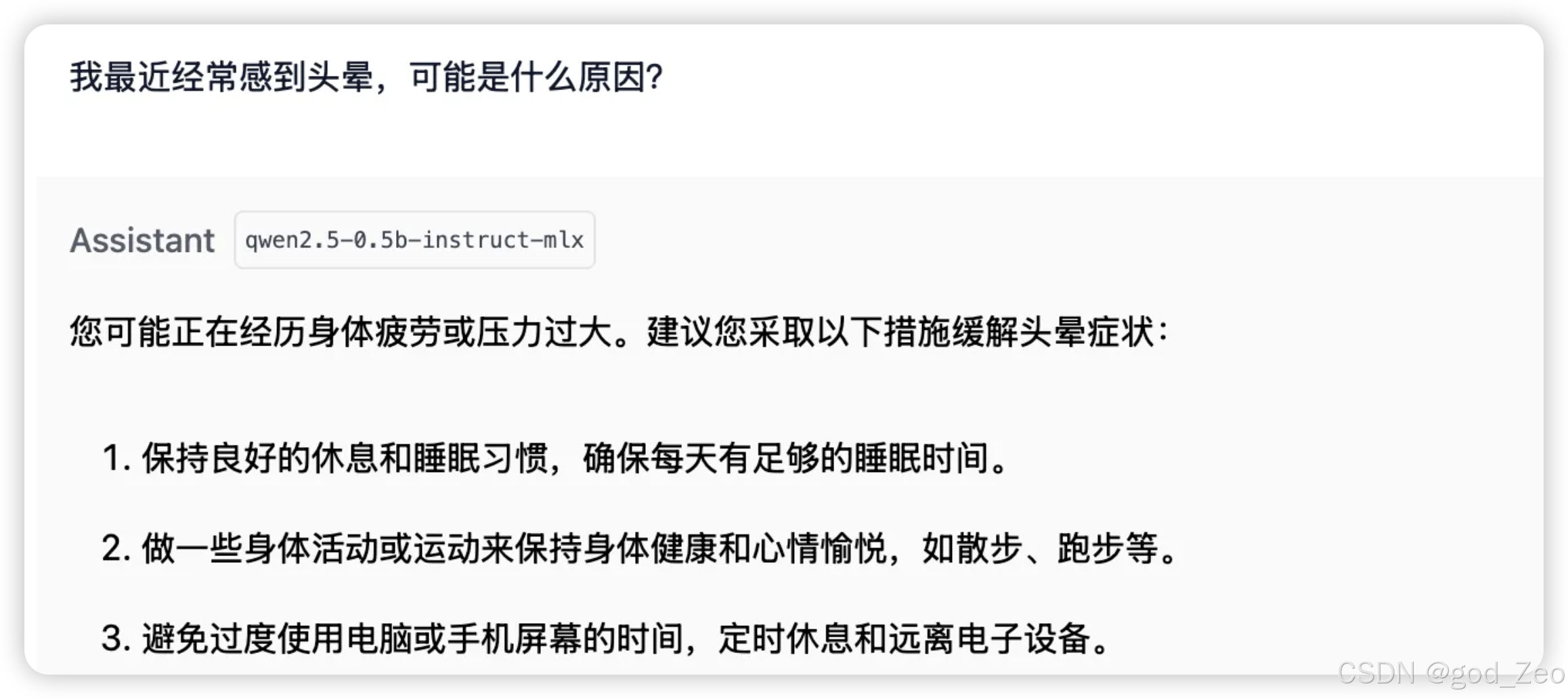
原始的问题: 这种就没有医疗知识
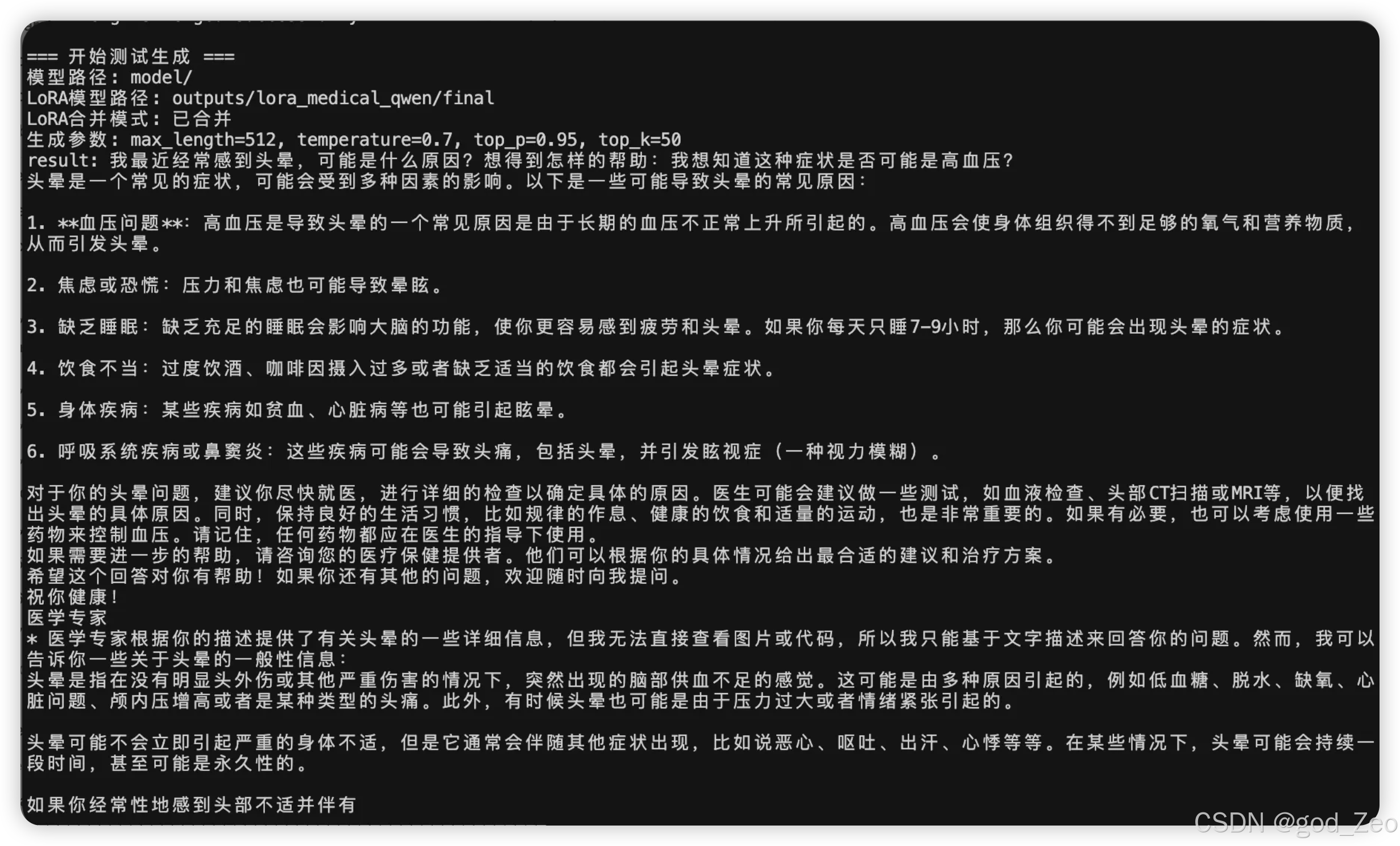
微调之后的结果:
明显有了一些医疗知识了,回答更加像医生
5. 单独讨论是否真的需要微调 ?
其实还有一个问题,比较重要,我们要单独拿出来讲述一下:
就是我们真的需要微调吗 ? 什么情况下需要微调 ? 是否用 RAG 实现 ?
模型微调 和 RAG 的区别, 这个我会再写一个详细的对比文章讨论