C++实现布隆过滤器
1.布隆过滤器概念
位图虽然能高效且节省存储数据,但是类型必须是整型,不能存储其它类型。布隆过滤器是由布隆提出的一中紧凑型,比较巧妙的概率型数据结构,特点是高效的插入和查询,可以得知什么是一定不存在或者可能存在的。它是用多个哈希函数,将一个数据映射到位图结构中。这种方式可以提升查询效率,且节省大量内存空间。
布隆过滤器的思想就是把key先映射成哈希整型值,在映射一个位,但只有一个位,出冲突率就会比较多,可以通过多个哈希函数映射多个位,降低冲突率。
布隆过滤器这里跟哈希表不一样,无法解决哈希冲突,因为布隆过滤器不存储这个值,只标记映射位。
2.布隆过滤器误判率
假设:
m:布隆过滤器的bit长度(数组总长度)
n:插入过滤器的元素个数
k:哈希函数的个数

重点是下图三个等式。

在布隆过滤器中,“哈希函数等条件”通常指的是以下假设和条件:
哈希函数的独立性:布隆过滤器使用多个哈希函数,这些哈希函数是相互独立的,即一个哈希函数的输出不会影响其他哈希函数的输出。
哈希函数的均匀性:每个哈希函数将输入元素映射到位数组中的每个位置的概率是相同的,即每个位被设置为1的概率是均匀分布的。
哈希函数的数量:布隆过滤器中使用了 k 个哈希函数,每个元素都会通过这 k 个哈希函数映射到位数组中。
位数组的长度:布隆过滤器的位数组长度为 m,即有 m 个位可供哈希函数映射。
插入的元素数量:布隆过滤器中插入了 n 个元素,每个元素都会通过 k 个哈希函数映射到位数组中。
代码实现
BitSet.h文件
#pragma once
#include<vector>
namespace bit
{
template<size_t N>
class bitset
{
public:
bitset()
{
_bs.resize(N / 32 + 1);
}
// x映射的位标记成1
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bs[i] |= (1 << j);
}
// x映射的位标记成0
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bs[i] &= (~(1 << j));
}
// x映射的位是1返回真
// x映射的位是0返回假
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bs[i] & (1 << j);
}
private:
std::vector<int> _bs;
};
template<size_t N>
class twobitset
{
public:
void set(size_t x)
{
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2) // 00->01
{
_bs2.set(x);
}
else if (!bit1 && bit2) // 01->10
{
_bs1.set(x);
_bs2.reset(x);
}
else if (bit1 && !bit2) // 10->11
{
_bs1.set(x);
_bs2.set(x);
}
}
// 返回0 出现0次数
// 返回1 出现1次数
// 返回2 出现2次数
// 返回3 出现2次及以上
int get_count(size_t x)
{
bool bit1 = _bs1.test(x);
bool bit2 = _bs2.test(x);
if (!bit1 && !bit2)
{
return 0;
}
else if (!bit1 && bit2)
{
return 1;
}
else if (bit1 && !bit2)
{
return 2;
}
else
{
return 3;
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
};
void test_twobitset()
{
bit::twobitset<100> tbs;
int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,6,7,9 };
for (auto e : a)
{
tbs.set(e);
}
for (size_t i = 0; i < 100; ++i)
{
//cout << i << "->" << tbs.get_count(i) << endl;
if (tbs.get_count(i) == 1 || tbs.get_count(i) == 2)
{
cout << i << endl;
}
}
}
void test_bitset1()
{
int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
int a2[] = { 5,3,5,99,6,99,33,66 };
bitset<100> bs1;
bitset<100> bs2;
for (auto e : a1)
{
bs1.set(e);
}
for (auto e : a2)
{
bs2.set(e);
}
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i) && bs2.test(i))
{
cout << i << endl;
}
}
}
BloomFilter.h文件
示例一是判断字符类型映射是否准确,以及不存在的字符对象是否能判断不存在。示例二是调整参数看误判率的变化。
#pragma once
#include<string>
#include"BitSet.h"
struct HashFuncBKDR
{
// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The CProgramming Language》
// 一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 31;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// 由Arash Partow发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// 由Daniel J. Bernstein教授发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
template<size_t N,
size_t X = 5,
class K = std::string,
class Hash1 = HashFuncBKDR,
class Hash2 = HashFuncAP,
class Hash3 = HashFuncDJB>
class BloomFilter
{
public:
void Set(const K& key)
{
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
//cout << hash1 <<" "<< hash2 <<" "<< hash3 << endl;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool Test(const K& key)
{
size_t hash1 = Hash1()(key) % M;
if (!_bs.test(hash1))
{
return false;
}
size_t hash2 = Hash2()(key) % M;
if (!_bs.test(hash2))
{
return false;
}
size_t hash3 = Hash3()(key) % M;
if (!_bs.test(hash3))
{
return false;
}
return true; // 可能存在误判
}
// 获取公式计算出的误判率
double getFalseProbability()
{
double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);
return p;
}
private:
static const size_t M = N * X;
bit::bitset<M> _bs;
};
void TestBloomFilter1()
{
BloomFilter<10> bf;
bf.Set("猪八戒");
bf.Set("孙悟空");
bf.Set("唐僧");
cout << bf.Test("猪八戒") << endl;
cout << bf.Test("孙悟空") << endl;
cout << bf.Test("唐僧") << endl;
cout << bf.Test("沙僧") << endl;
cout << bf.Test("猪八戒1") << endl;
cout << bf.Test("猪戒八") << endl;
}
void TestBloomFilter2()
{
srand(time(0));
const size_t N = 1000000;
BloomFilter<N> bf;
//BloomFilter<N, 3> bf;
//BloomFilter<N, 10> bf;
std::vector<std::string> v1;
//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
//std::string url = "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=ln2&fenlei=256&rsv_pq=0x8d9962630072789f&rsv_t=ceda1rulSdBxDLjBdX4484KaopD%2BzBFgV1uZn4271RV0PonRFJm0i5xAJ%2FDo&rqlang=en&rsv_enter=1&rsv_dl=ib&rsv_sug3=3&rsv_sug1=2&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=330&rsv_sug4=2535";
std::string url = "猪八戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是后缀不一样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}Test.cpp文件
#include<iostream>
#include<bitset>
using namespace std;
#include"BitSet.h"
//int main()
//{
// std::bitset<100> bs;
// cout << sizeof(bs) << endl;
//
// bs.set(32);
// bs.set(33);
//
// bs.reset(33);
// bs.set(34);
//
// cout << bs.test(31) << endl;
// cout << bs.test(32) << endl;
// cout << bs.test(33) << endl;
// cout << bs.test(34) << endl;
// cout << bs.test(35) << endl;
//
// std::bitset<-1>* ptr = new std::bitset<-1>();
// //bit::bitset<0xffffffff> bs2;
// //bit::bitset<UINT_MAX> bs2;
//
// return 0;
//}
#include"BloomFilter.h"
int main()
{
//test_bitset1();
//test_twobitset();
TestBloomFilter2();
}3.布隆过滤器删除问题
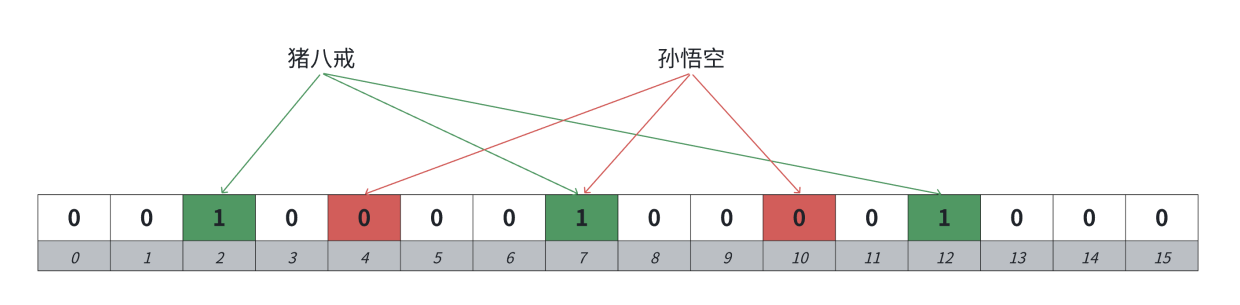
布隆过滤器默认是不支持删除的,比如“猪八戒”和“孙悟空”都映射到布隆过滤器中,它们映射的位有一个位是共同映射的(冲突的),如果把孙悟空删掉,再去查找“猪八戒“也会查找不到,就间接的把猪八戒删除了。
解决方案:用计数标记的方式,一个位置用多个标记位,记录映射这个位的计数值,删除时,仅仅减减计数,那么就可以某种程度支持删除。但是这个方案也有缺陷,如果说一个值不在布隆过滤器中,去删除它,减减映射位的计数,就会影响存在的值,就会导致一个确定存在的值,可能会变成不存在。另一种考虑计数支持删除,但是定期重建一下布隆过滤器。
4.布隆过滤器优缺点
布隆过滤器优点:效率高,节省空间,相比位图,可以适用于各种类型的标记过滤
缺点:存在误判,不好支持删除
5.布隆过滤器在实际应用
爬虫系统中URL去重
在爬虫系统中,为了避免重复爬取相同的URL,可以使用布隆过滤器去重。爬取到的URL可以通过布隆过滤器进行判断,已经存在的URL可以直接忽略,避免重复的网络请求和数据处理。