[Lc18_拓扑排序] string+queue+map | 火星字典
链接: LCR 114. 火星词典
现有一种使用英语字母的外星文语言,这门语言的字母顺序与英语顺序不同。
给定一个字符串列表 words ,作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 。
请你根据该词典还原出此语言中已知的字母顺序,并 按字母递增顺序 排列。若不存在合法字母顺序,返回 "" 。若存在多种可能的合法字母顺序,返回其中 任意一种 顺序即可。
字符串 s 字典顺序小于 字符串 t 有两种情况:
- 在第一个不同字母处,如果
s中的字母在这门外星语言的字母顺序中位于t中字母之前,那么s的字典顺序小于t。 - 如果前面
min(s.length, t.length)字母都相同,那么s.length < t.length时,s的字典顺序也小于t。
示例 1:
输入:words = ["wrt","wrf","er","ett","rftt"]
输出:"wertf"示例 2:
输入:words = ["z","x"]
输出:"zx"示例 3:
输入:words = ["z","x","z"]
输出:""
解释:不存在合法字母顺序,因此返回 ""。题解
现有一种使用英语字母的外星文语言,但是这门语言的字母顺序与英语顺序不同。给定一个字符串列表 words
- 作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 (也就是说字符串是按照新语言的字母顺序已经进行排序了)。
- 请你根据该词典中的字符串还原出此语言中已知的字母顺序,并 按字母递增顺序 排列。
- 若不存在合法字母顺序,返回 “” 。若存在多种可能的合法字母顺序,返回其中 任意一种 顺序即可。
字符串 s 字典顺序小于 字符串 t 有两种情况:
- 在第一个不同字母处,如果 s 中的字母在这门外星语言的字母顺序中位于 t 中字母之前,那么 s 的字典顺序小于 t 。不用管后面是否还有其他字母。
- 如果前面 min(s.length, t.length) 字母都相同,那么 s.length < t.length 时,s 的字典顺序也小于 t 。
原理:
刚才我们是按照随意的顺序去比较搜集信息的,但是在计算机可不能这样,需要按照一定的顺序去比较搜集信息。
- 如何搜集信息
两层for循环
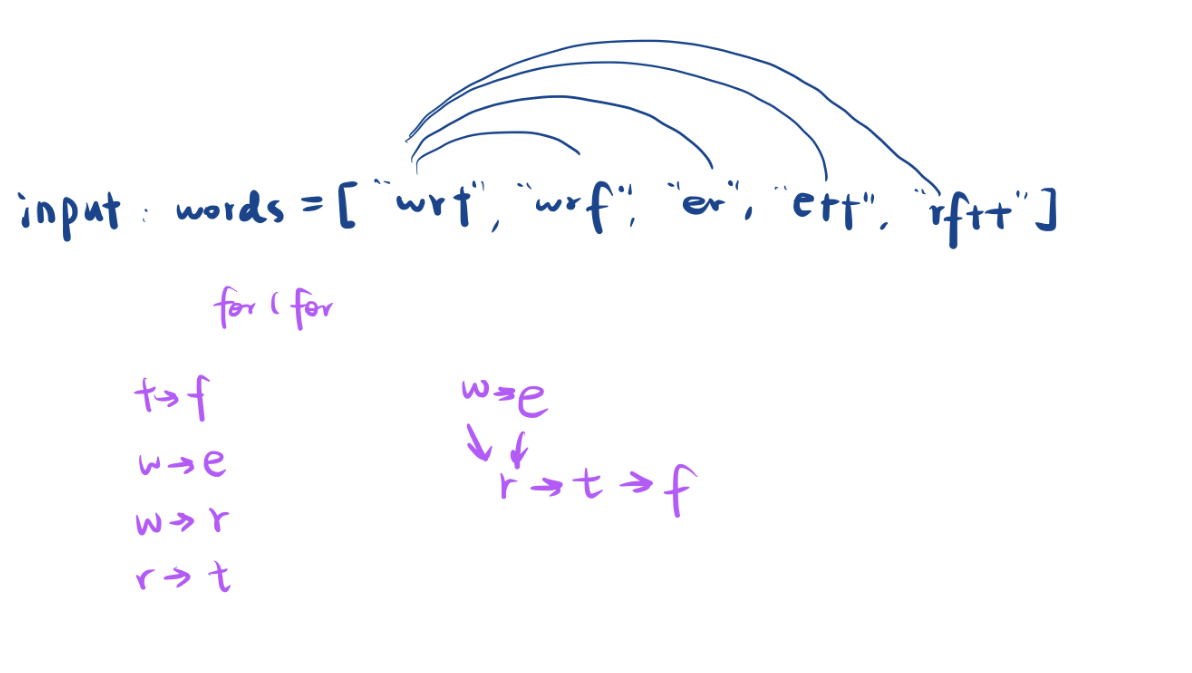
- 搜集的是两个字符串中第一个不相等字符的信息,就知道谁在前,谁在后。
- 如何统计这个信息呢?由 t 到 f 可以建立一条边。t在前 f在后,正好和有向图的含义是一样的。
- 同理经过多次,我们可以得到一个有向图,中间还包含去重重复信息
2. 如何还原出这些字符串中字母的顺序呢?
最开始可以找一个入度为0的字符加入队列,然后删除和它相连的边,重复上面操作直到图为空或者没有找到入度为0的字符为止。
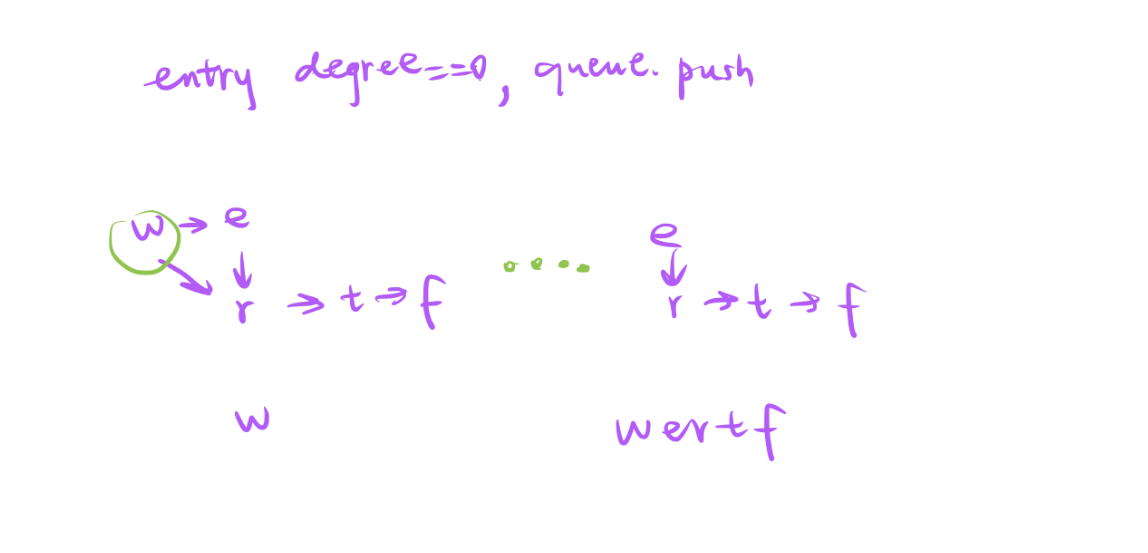
- 发现做一次拓扑排序即可。
拓扑排序
- 如何建图?
前面邻接表建图有两种做法
- vector<vector<>>
- unordered_map<>
这里顶点的值已经不在是int了,不太好对应了。因此还是选unordered_map<>建图。
- unordered_map<char,char[]>,char表示当前字符,char[]表示与这个字符相连的其他字符。
- 但是我们搜索的信息是会冗余的,比如wrt和er比较 w->e,wrt和ett比较 w->e,不能无脑全添加到数组里面。
- 所以我们可以判断下在数组中存过就不要在存了(count)
如何快速找呢?
- 可以把char数组继续搞一个hash表,因此终极建图就出来了。
- unordered_map<char,unordered_set> edges;
- char表示当前字符顶点,第二个hash表示这个顶点所连接的顶点。
统计入度信息
- 可以搞一个int数组统计每一个字符入度是多少,但是这里不推荐。
- 这道题并不是所有a-z字符都会出现,如果搞一个int[26],那有的字符出现过,有的压根没出现,那入度给0就会有问题,给-1也没有必要。
直接给一个unordered_map<char,int>,char表示当前字符,int表示当前字符的入度。
- 但是用hash表必须要先把hash表初始化一下。
- 初始化就是遍历字典中所有字符串每一个字符加入到hash,入度初始化为0。
- 如果不初始化,等会往队列中添加入度为0的字符的时候,一个也找不到。
- 原因就是 hash表只会存入度大于0的字符。
如何搜集信息
- 可以利用一个指针来搜集信息。判断当前两个字符串字符是否相等,不相等就右移动,当判断到第一个不相等的时候,就把这个信息丢到unordered_map<char,unordered_set> edges
- 同时更新一下入度。注意我们只是找第一个不同的字符,如果后面还有其他字符我们是不管的(break)
细节问题
- 我们刚刚所说的东西处理不了这样的字符串比较 “abc” 和 “ab”
- 前面相等字符串长的必定在后面,所以当发现有这些的字符串,就返回""
- 刚才拓扑排序解决不了这样的问题
- 因此特殊处理一下。可以在搜集信息的地方处理,当发现遍历到一个字符串的字符
- 上面字符还没有结束,但是下面的结束了,此时直接返回空就可以了。(!!!!这个地方 一定要注意判断一下/(ㄒoㄒ)/~~
class Solution {
public:
unordered_map<char,unordered_set<char>> edges;//建图
unordered_map<char,int> in;//入度
string alienOrder(vector<string>& words)
{
//初始化入度
for(string s:words)
{
for(char c:s)
in[c]=0;
}
//建图
for(int i=0;i<words.size();i++)
{
for(int j=i+1;j<words.size();j++)
{
if(!compare(words[i],words[j]))
return "";
}
}
string ret;
queue<char> q;
for(auto& [a,b]:in)
{
if(b==0)
{
q.push(a);
ret+=a;
}
}
while(q.size())
{
char c=q.front();
q.pop();
for(char s:edges[c])
{
if(--in[s]==0)
{
q.push(s);
ret+=s;
}
}
}
// !!!!!!!!!!检查是否有环
return ret.size() == in.size() ? ret : "";
}
bool compare(string s1,string s2)
{
int n=min(s1.size(),s2.size());
bool found=false;
for(int i=0;i<n;i++)
{
if(s1[i]!=s2[i])
{
//避免重复加边
if(!edges[s1[i]].count(s2[i]))
{
edges[s1[i]].insert(s2[i]);
in[s2[i]]++;
}
found=true;
break; //找到 第一个不同字符后 停止
}
}
// 处理前缀无效的情况(例如 ["abc", "ab"])
if (!found && s1.size() > s2.size())
return false;
return true;
}
};