Yolo系列之Yolo v1概述及网络结构理解
Yolo v1概述及网络结构理解
目录
- Yolo v1概述及网络结构理解
- Yolo v1概述
- 概念
- 核心思想
- 评价指标
- MAP
- IOU
- mAP50
- mAP50 - 95
- 优缺点
- 网络框架
- 核心网络框架
- 边界框
- 关键设计思想
- 损失函数
Yolo v1概述
概念
YOLOv1(You Only Look Once Version 1)是 YOLO 系列的第一个版本,由 Joseph Redmon 等人在 2016 年提出。YOLOv1 的核心思想是将目标检测问题转化为一个回归问题,通过单次前向传播即可预测图像中的目标边界框和类别概率。YOLOv1 是目标检测领域的一个重要里程碑,它通过将目标检测问题转化为回归问题,实现了实时检测。虽然 YOLOv1 有一些缺点,但它的思想在后继版本中得到了改进和优化。
核心思想
将目标检测问题转化为一个回归问题,通过单次前向传播即可完成检测。
具体步骤如下:
- 图像划分:
- 将输入图像划分为 S×S的网格(如 7×7)。
- 每个网格负责预测 B 个边界框(Bounding Box)和这些边界框的置信度(Confidence Score)。
- 边界框预测:每个边界框包含以下信息:
- 边界框的中心坐标 (x,y)。
- 边界框的宽度和高度 (w,h)。
- 边界框的置信度(表示该框包含目标的概率)。
- 类别预测:
- 每个网格还会预测 C 个类别的概率(C 是类别数量)。
- 最终的类别概率是边界框置信度与类别概率的乘积。
- 非极大值抑制(NMS):使用 NMS 去除冗余的边界框,保留最有可能的检测结果,如下0.98>0.83>0.75,选框为0.98的。

评价指标
MAP
在目标检测任务中,MAP(Mean Average Precision,平均精度均值)是评估模型性能的核心指标之一。YOLO(You Only Look Once)系列模型也使用 mAP 来评估检测效果,它综合考虑了模型的精度(Precision) 和召回率(Recall),并通过计算不同置信度阈值下的平均精度(AP)来评估模型性能。
- 精度(Precision):预测为正样本的样本中,实际为正样本的比例。
Precision=True Positives (TP)/(True Positives (TP)+False Positives (FP)) - 召回率(Recall):实际为正样本的样本中,被正确预测为正样本的比例。
Recall= True Positives (TP)/(True Positives (TP)+False Negatives (FN))
IOU
在目标检测任务中,IoU(Intersection over Union,交并比) 是评估预测边界框(Bounding Box)与真实边界框之间重叠程度的核心指标。YOLO(You Only Look Once)系列算法在训练和评估中广泛使用 IoU 来计算定位精度、匹配预测框与真实框,以及作为非极大值抑制(NMS)的依据。
- 取值范围:0(无重叠)到 1(完全重合)。
- 阈值选择:通常认为 IoU ≥ 0.5 时预测框是“正确”的(但可根据任务调整,如更严格的任务可能要求 IoU ≥ 0.7)。

mAP50
mAP50:表示当 IoU 阈值为 0.5 时模型的平均精度。即只考虑预测框与真实框的重叠部分达到 50%及以上的情况,计算所有类别的 AP(Average Precision)的平均值,AP 衡量的是随着不同置信度阈值的召回率变化,精度是如何变化的。mAP50 是一个固定的评估标准,仅关注IoU 为 0.5 这一特定阈值下的模型性能。
mAP50 - 95
mAP50 - 95:衡量的是模型在 IoU 阈值从 0.5 到 0.95 范围内的平均精度。计算的是所有类别的 AP 的平均值,其中AP 是在 IoU 阈值从 0.5 到 0.95 的每个 0.05 步长上计算的。mAP50- 95 考虑了更广泛的 IoU 范围,能够评估模型在不同重叠程度下的性能,提供了更全面的模型性能评估,是一个更严格的评估指标,其值通常比 mAP50 要低。
优缺点
- 优点
- 速度快:YOLOv1 可以实现实时检测(45 FPS),远快于当时的两阶段检测方法(如 R-CNN)。
- 全局推理:YOLOv1 在处理图像时,会同时考虑整个图像的上下文信息,而不是像滑动窗口方法那样只关注局部区域。
- 端到端训练:YOLOv1 是一个端到端的模型,可以直接从输入图像到输出检测结果进行训练。
- 缺点
- 对小目标检测效果较差:由于每个网格只能预测固定数量的边界框,YOLOv1 在处理小目标或密集目标时效果较差。
- 定位精度较低:与两阶段检测方法相比,YOLOv1 的定位精度较低。
- 对长宽比异常的目标检测效果较差:YOLOv1 的边界框预测机制对长宽比异常的目标(如非常宽或非常高的目标)效果较差。
网络框架
核心网络框架
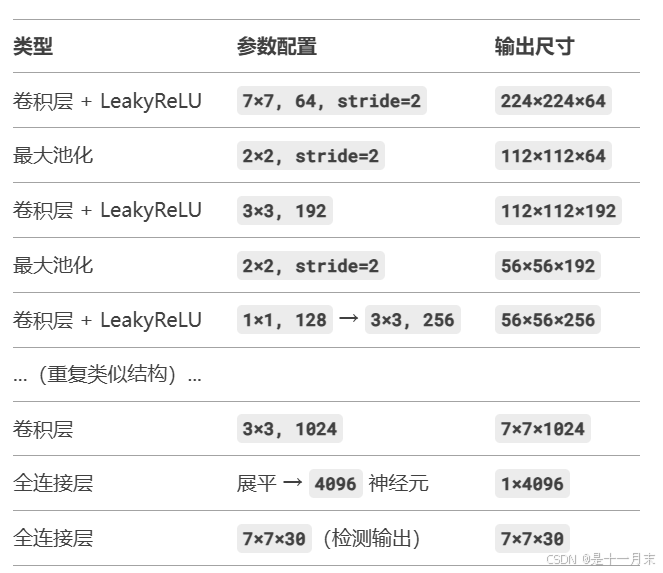
YOLOv1 使用一个端到端的卷积神经网络(CNN),结构类似于 GoogLeNet 的简化版,包含 24 个卷积层 和 2 个全连接层。整体分为特征提取器和检测头两部分
-
特征提取器(Backbone)
- 由 24 个卷积层组成,用于提取图像特征。
- 使用 1×1 和 3×3 卷积核,部分层后接 2×2 最大池化
- 最终输出 7×7×1024 的特征图。
-
检测头(Detection Head)
- 2 个全连接层:将特征图展平后通过全连接层输出预测结果。
- 最终输出张量形状:7×7×30(对应网格预测结果)。
边界框
YOLOv1 直接通过全连接层回归边界框的坐标和尺寸,其核心设计如下:
- 网格划分:将输入图像划分为 S×S 的网格(默认 S=7)。
- 每个网格预测:
- 2 个边界框(Bounding Box):每个框预测 (x, y, w, h, confidence)。
- (x, y):边界框中心相对于当前网格的偏移量(范围 0~1)。
- (w, h):边界框的宽高相对于整个图像的比例(范围 0~1)。
- confidence:框的置信度(包含目标且位置准确的概率)。
- 20 个类别概率(针对 VOC 数据集的 20 类分类任务)总计输出:每个网格预测 2×5 + 20 = 30 个值,最终输出张量为 7×7×30。
关键设计思想
- 单阶段检测(One-Stage)
- 将检测任务转化为回归问题,直接输出边界框和类别。
- 相比两阶段方法(如 R-CNN),速度更快(45 FPS)。
- 网格化预测
- 每个网格负责预测中心点落在该区域的目标。
- 限制:每个网格最多预测 2 个框,对小目标和密集目标效果较差。
- 损失函数设计
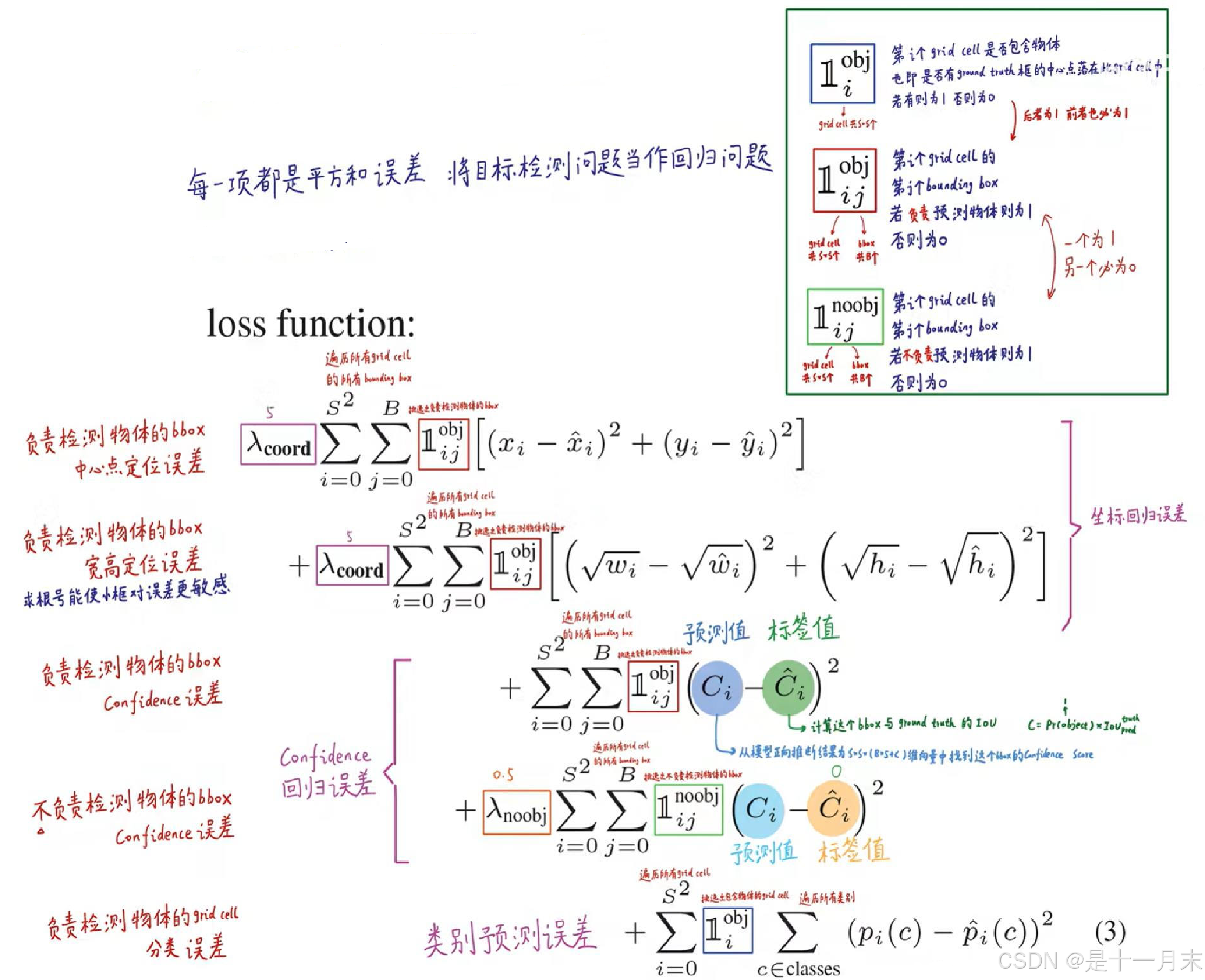
YOLOv1 的损失函数包含三部分 :- 边界框坐标损失(MSE)
- 边界框置信度损失(含正负样本权重)
- 类别概率损失(交叉熵)
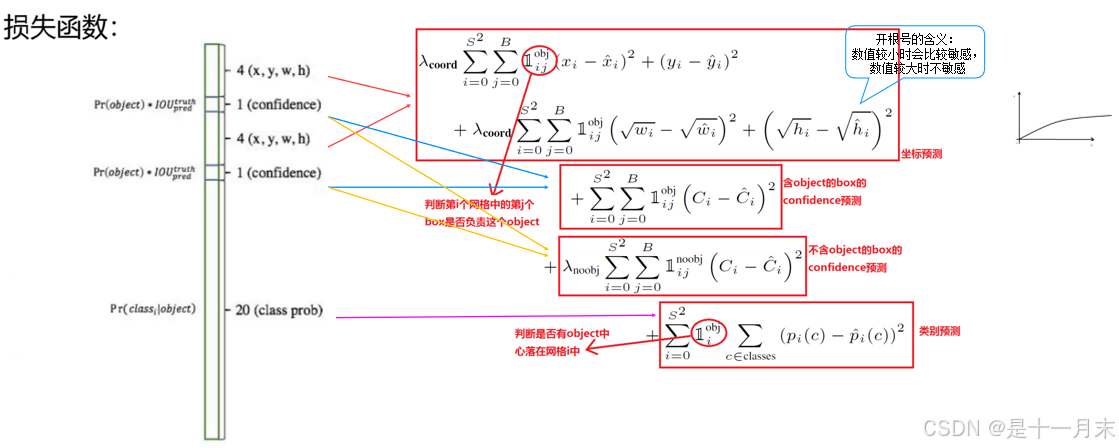
损失函数
YOLO-V1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么Y0L0的损失就包括三部分:位置误差,confidence误差,分类误差。损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。