Langchain+NebulaGraph结合大模型的KBQA源码分析
Langchian提供了与NebulaGraph交互的接口,下面我简单说明下如何使用,然后分析下langchain实现的源码。
from langchain_community.chains.graph_qa.nebulagraph import NebulaGraphQAChain
from langchain_community.graphs import NebulaGraph
from langchain_openai import ChatOpenAI
# 初始化
graph = NebulaGraph(
space="test", # nebulaGraph里的space
username="root", # 用户名
password="xxxx", # 密码
address="xxxx", # 地址
port=9669,
session_pool_size=30,
)
# 初始化llm
llm = ChatOpenAI(
api_key="sk-xxxxxxxxxxxxxxxxxx",
base_url="https://api.deepseek.com",
model="deepseek-chat",
)
chain = NebulaGraphQAChain.from_llm(
llm, graph=graph, verbose=True,allow_dangerous_requests=True
)
result = chain.run("介绍下印度塔塔集团")
print(result)
我的大模型选择的是deepseek,可以在https://platform.deepseek.com/购买
主要有两个类:
NebulaGraph:与nebula数据库的交互。
NebulaGraphQAChain: 数据库返回结果与大模型交互
NebulaGraph
我们先看下NebulaGraph类的函数
类的初始化函数就不做过多介绍了,其实就是定义了一个nebula数据库查询对象。
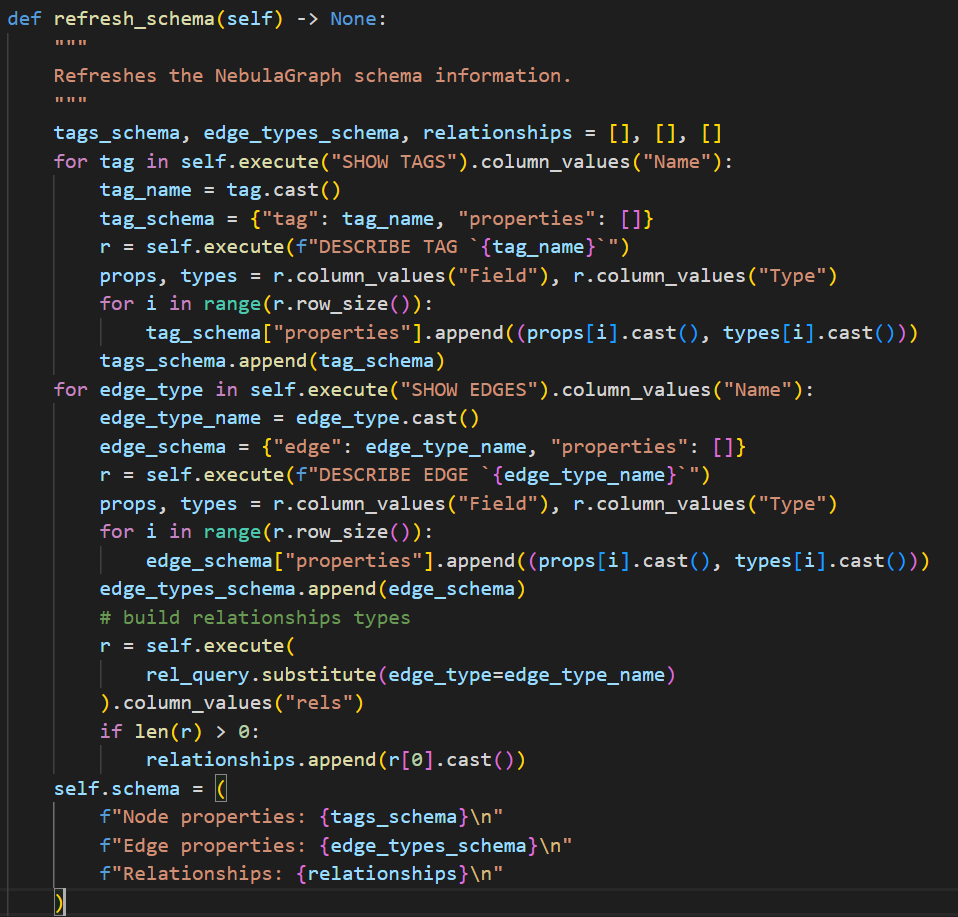
该类最主要的是实现了两个功能:1.得到schema。2.执行查询语句。下面简单介绍下这两个功能。
refresh_schema函数:用于得到nebula数据库的schema
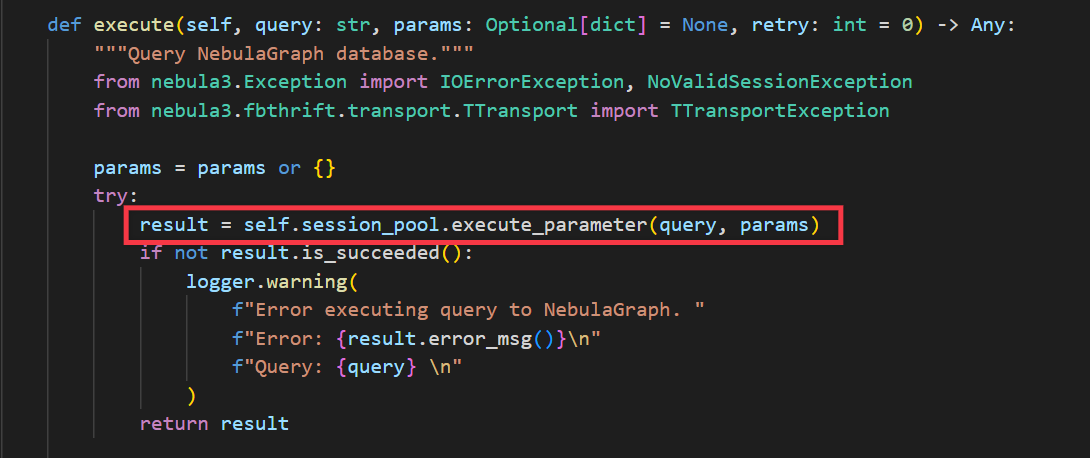
execute函数:用的是SessionPool的execute_parameter方法执行对应的nCQL命令。
NebulaGraphQAChain
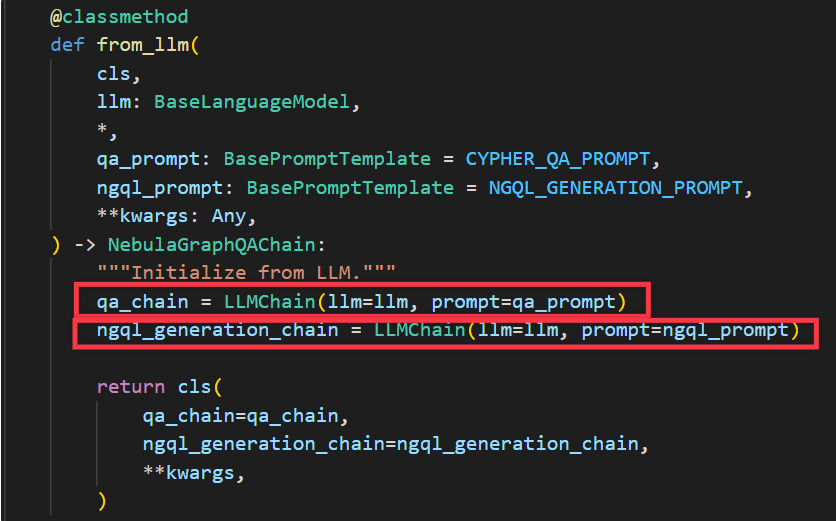
NebulaGraphQAChain为大模型问答的逻辑,先从from_llm函数入手逐步分析。
从from_llm函数可以看到主要有两个chain,qa_chain和ngql_generation_chain,涉及到两个Prompt。
qa_chain:用于将查询后的结果交给大模型生成最后的回答。
ngql_generation_chain:用于将用户的query生成对应的查询语句。
下面我们首先看下qa_prompt
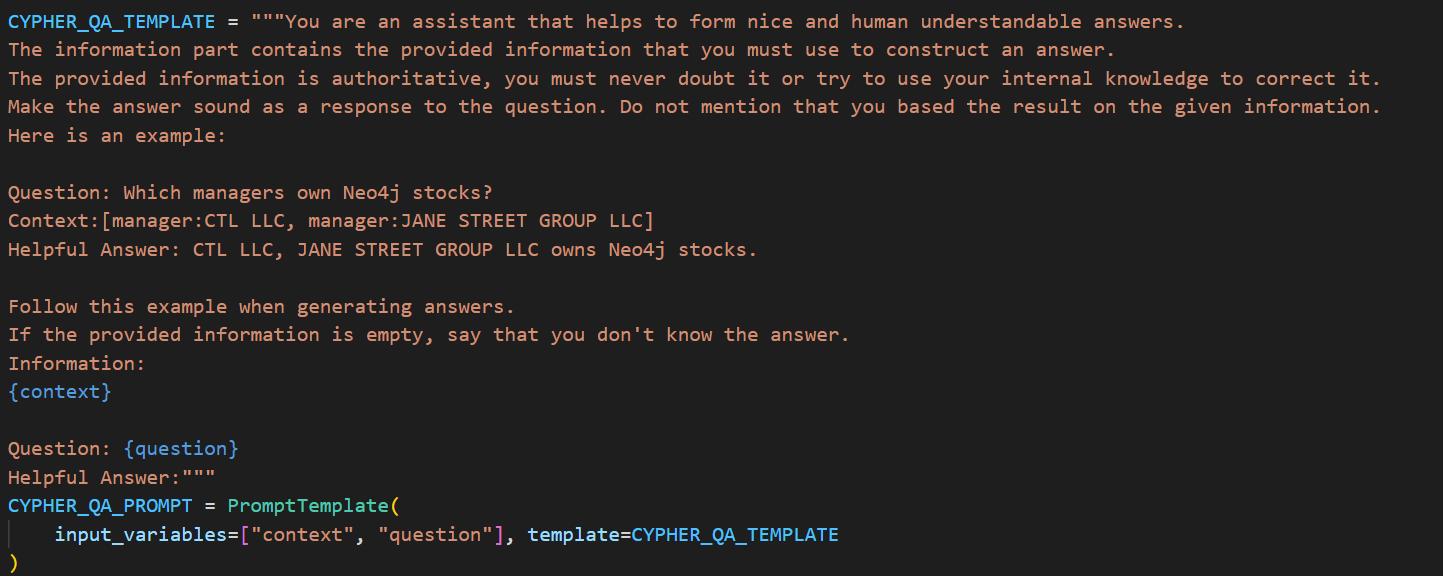
中文翻译如下:
"""你是一个生成友好且易于理解的回答的助手
信息使用规则:
1. 必须始终信任提供的上下文信息,该信息具有权威性
2. 切勿质疑或试图用自身知识修正提供的信息
3. 回答需直接回应问题,不得提及信息来源于给定上下文
示例演示:
问题:哪些管理者持有Neo4j股票?
上下文:[manager:CTL LLC, manager:JANE STREET GROUP LLC]
有帮助的回答:CTL LLC和JANE STREET GROUP LLC持有Neo4j股票。
执行规范:
- 严格遵循示例的应答格式
- 当上下文为空时,统一回复"根据现有信息无法回答该问题"
上下文信息:
{context}
待回答问题:
{question}
最终回答:"""
ngql_prompt的写法如下:
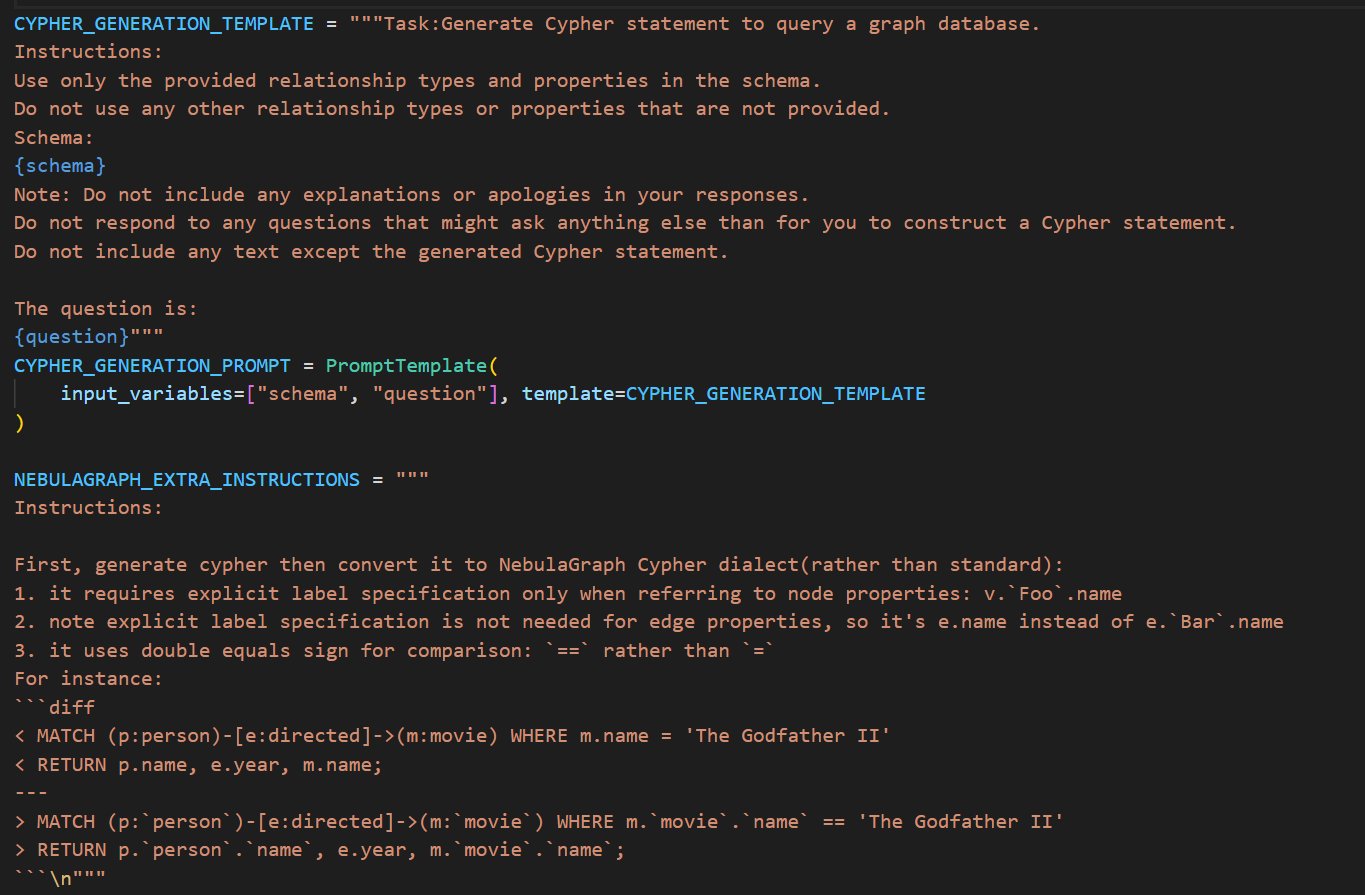
中文翻译如下:
"""任务:生成符合NebulaGraph方言的Cypher查询语句
指令:
首先生成标准Cypher语句,然后转换为NebulaGraph方言:
1. 节点属性访问需显式声明标签:v.`Foo`.name
2. 边属性无需标签声明:使用e.name而非e.`Bar`.name
3. 比较运算符使用双等号:`==` 代替 `=`
转换示例:
```diff
< MATCH (p:person)-[e:directed]->(m:movie) WHERE m.name = 'The Godfather II'
< RETURN p.name, e.year, m.name;
---
> MATCH (p:`person`)-[e:directed]->(m:`movie`) WHERE m.`movie`.`name` == 'The Godfather II'
> RETURN p.`person`.`name`, e.year, m.`movie`.`name`;
技术规范:
仅使用模式中定义的关系类型和属性
严禁使用未声明的关系类型或属性
模式:
{schema}
注意事项:
禁止包含解释性内容
仅响应Cypher语句生成请求
输出必须为纯净的Cypher语句
待处理问题:
{question}"""
先生成Cypher语句,然后转换为相应的nCQL语句。
下面看下整体的执行过程。
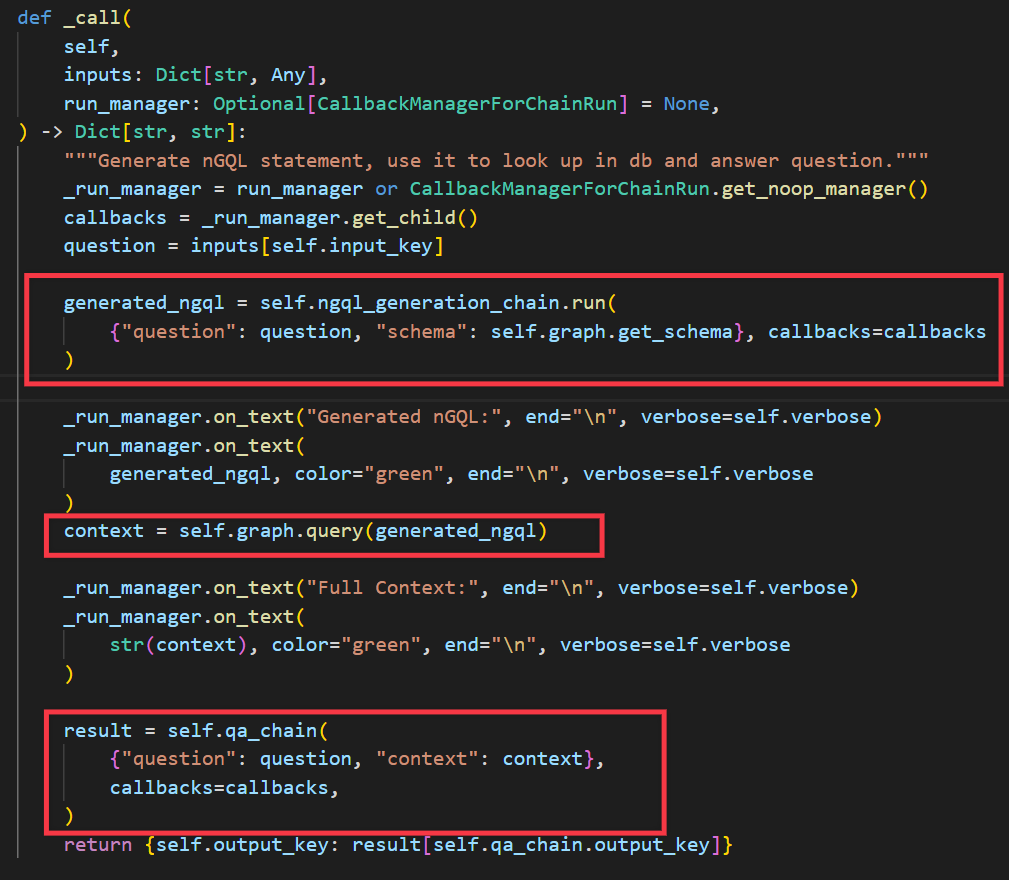
执行的时候先根据question和schema生成对应的查询语句generated_ngql,然后查询图谱得对应的查询结果context,最后大模型根据问题question和查询结果context得到最终回答result。
总结:
依赖大模型生成查询语句的能力,但是这个能力非常不稳定。KBQA一直是一个难点,现在主要有两种解决方法:
知识检索:根据问题从图数据库中定位最相关的实体、关系或三元组,以缩小搜索范围。
语义解析:本质上是将问题从无结构的自然语言转换为结构化的逻辑形式,然后可以将其转换为可执行的图数据库查询。
本文中Langchian用的就是语义解析的方式,考验模型的text2sql的能力,但是这个能力并不理想,最好的方法就是微调模型,比如neo4j的这个文章[2412.10064] Text2Cypher: Bridging Natural Language and Graph Databases。