基于Qwen2.5-7B-Instruct进行LoRA微调推理全流程探索
文章目录
- 一、环境准备
- 二、模型下载
- 三、LoRA微调
- 1.构建训练集
- 2.微调
- 四、合并微调结果推理
- 1.不合并LoRA
- 2.合并LoRA微调结果推理
- API(ms-swift)
一、环境准备
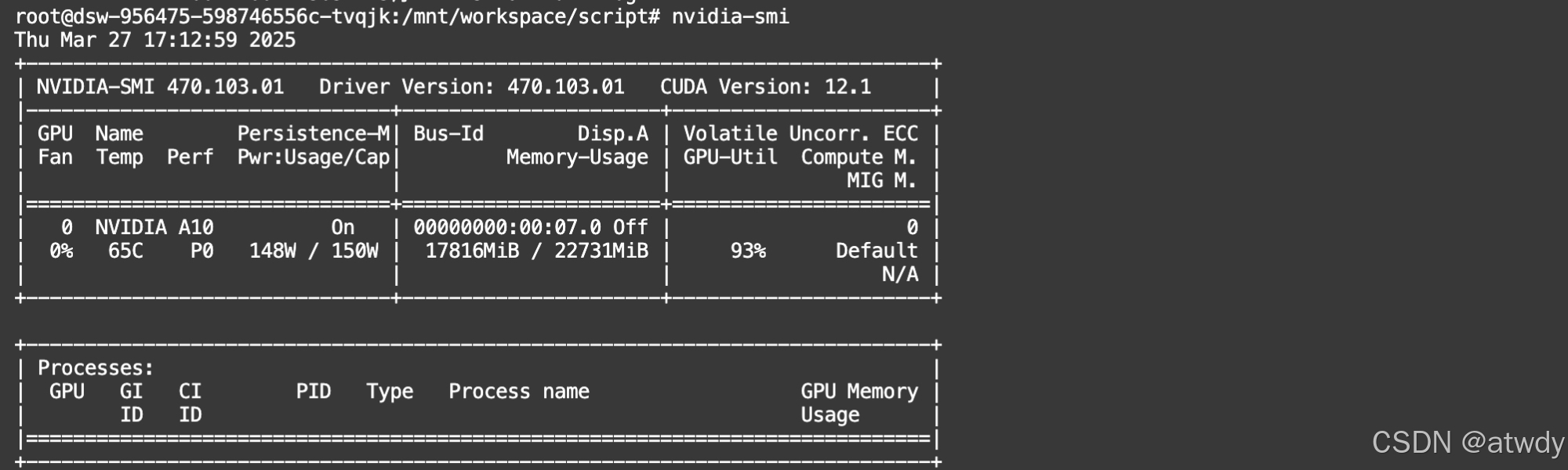
本次测试环境为modelscope社区提供的免费额度环境,A10单卡环境:
二、模型下载
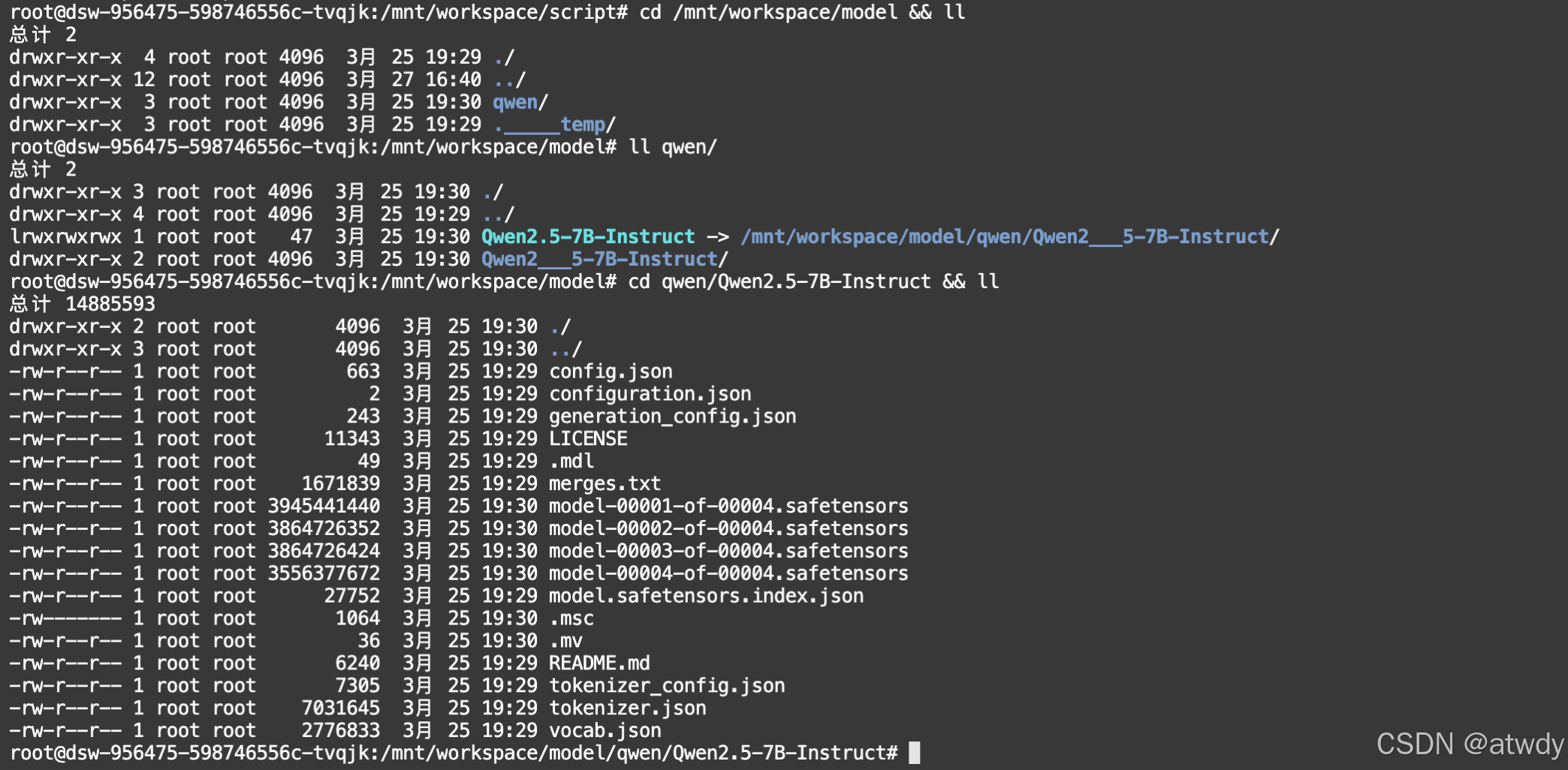
本次测试目的为跑通模型部署,微调及推理全流程,首先下载模型到本地,参考https://github.com/datawhalechina/self-llm/blob/master/models/Qwen2.5/05-Qwen2.5-7B-Instruct%20Lora%20%E5%BE%AE%E8%B0%83.md#%E6%A8%A1%E5%9E%8B%E4%B8%8B%E8%BD%BD,几行代码就可以下载:
from modelscope import snapshot_download
# 第一个参数指定需要下载的模型,第二个参数指定下载到本地的位置
model_dir = snapshot_download('qwen/Qwen2.5-7B-Instruct', cache_dir='/mnt/workspace/model', revision='master')
下载完成后的基座模型:
三、LoRA微调
使用ms-swift,通过lora方式微调下载的基座模型,产出微调的权重文件。
ms-swift是一个针对大模型微调的高层封装框架,旨在简化训练流程、统一接口并集成多种微调技术,如 LoRA、QLoRA、Prefix Tuning等。通过ms-swift实现LoRA微调,仅需配置参数,无需关心底层实现。
1.构建训练集
参考https://swift.readthedocs.io/zh-cn/latest/Customization/%E8%87%AA%E5%AE%9A%E4%B9%89%E6%95%B0%E6%8D%AE%E9%9B%86.html,本次使用的是下面格式:

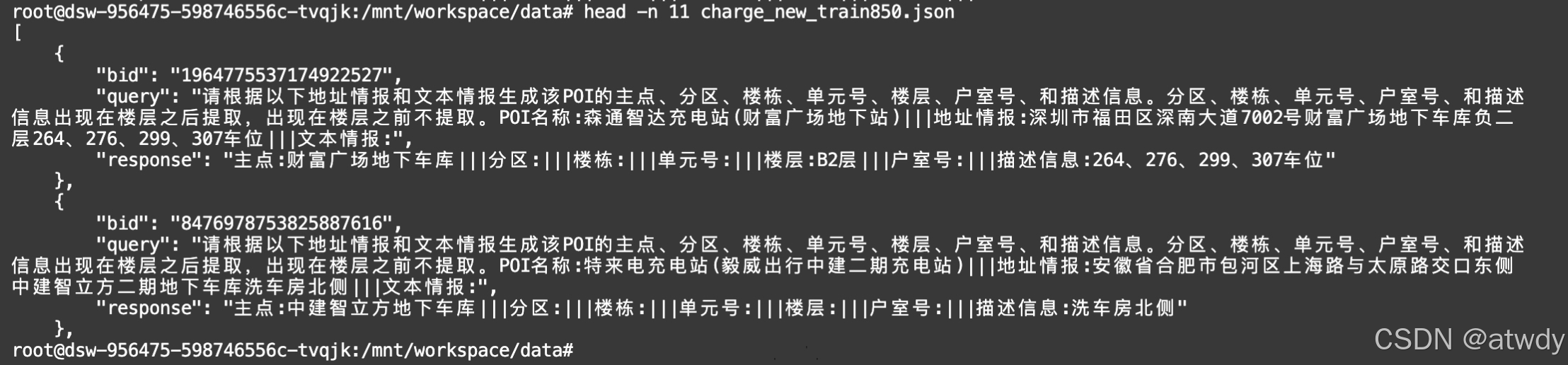
850条训练数据,每个训练数据组成一个json对象,其中必须包含query和response,可以有其他额外字段,只要不和内置的一些字段名如system、history等相同就不会影响训练。所有的json对象用一个json数组包含。
2.微调
具体微调参数代表的含义可以参考https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html,本次测试的swift环境是3.x。微调脚本:
#!/bin/bash
prompt_dir=/mnt/workspace/data/charge_new_train850.json
output_dir=/mnt/workspace/output/charge_new_train850.qwen2.5_7b
model_dir=/mnt/workspace/model/qwen/Qwen2.5-7B-Instruct
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model $model_dir \
--model_type qwen2_5 \
--dataset $prompt_dir \
--output_dir $output_dir \
--num_train_epochs 3 \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout 0.05 \
--weight_decay 0.1 \
--learning_rate 1e-4 \
--gradient_checkpointing true \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16
训练完成后在output文件夹下会生成指定名称charge_new_train850.qwen2.5_7b的文件夹,文件夹里的内容结构:
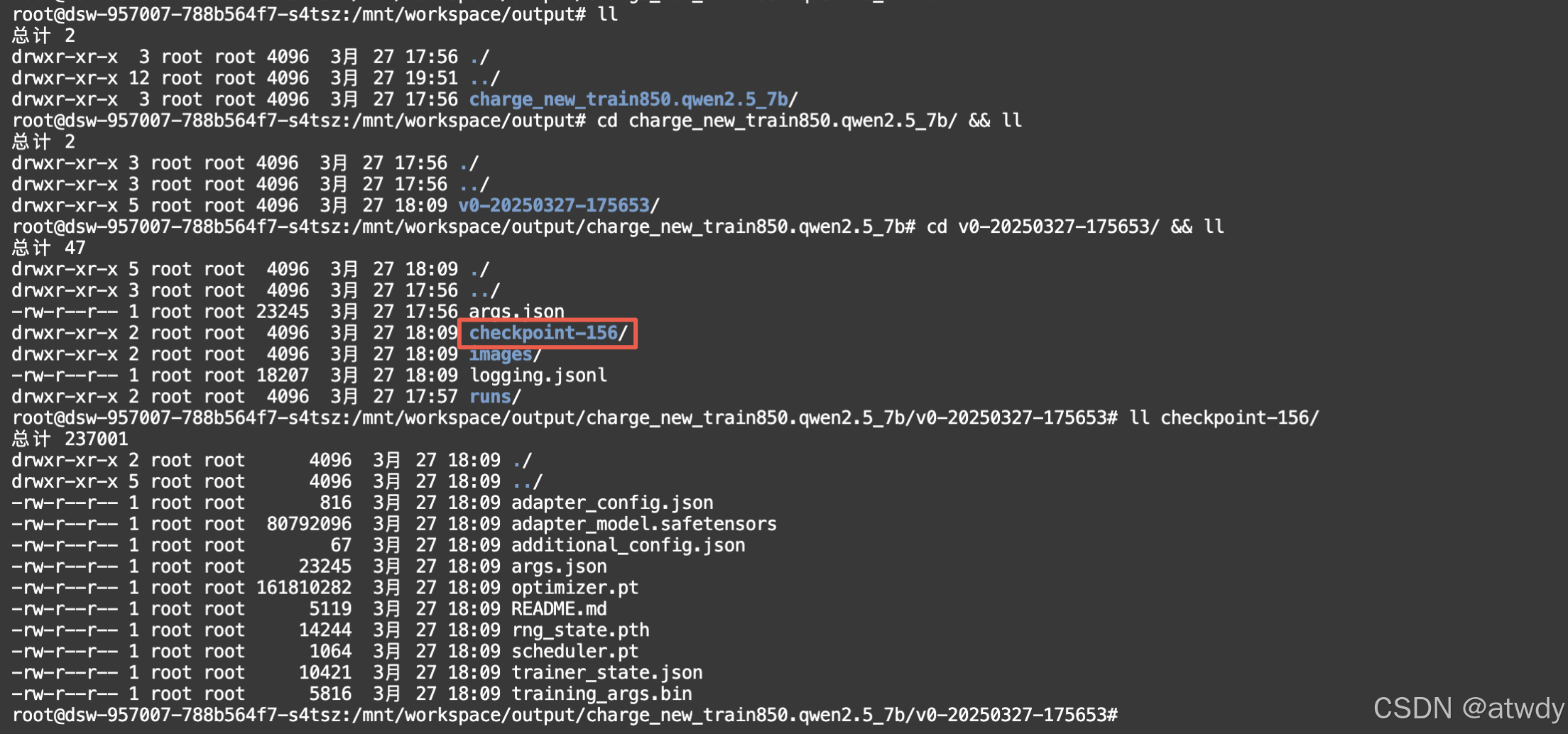
圈起来的就是最终的微调结果,在推理时加载改结果就可以了。
四、合并微调结果推理
1.不合并LoRA
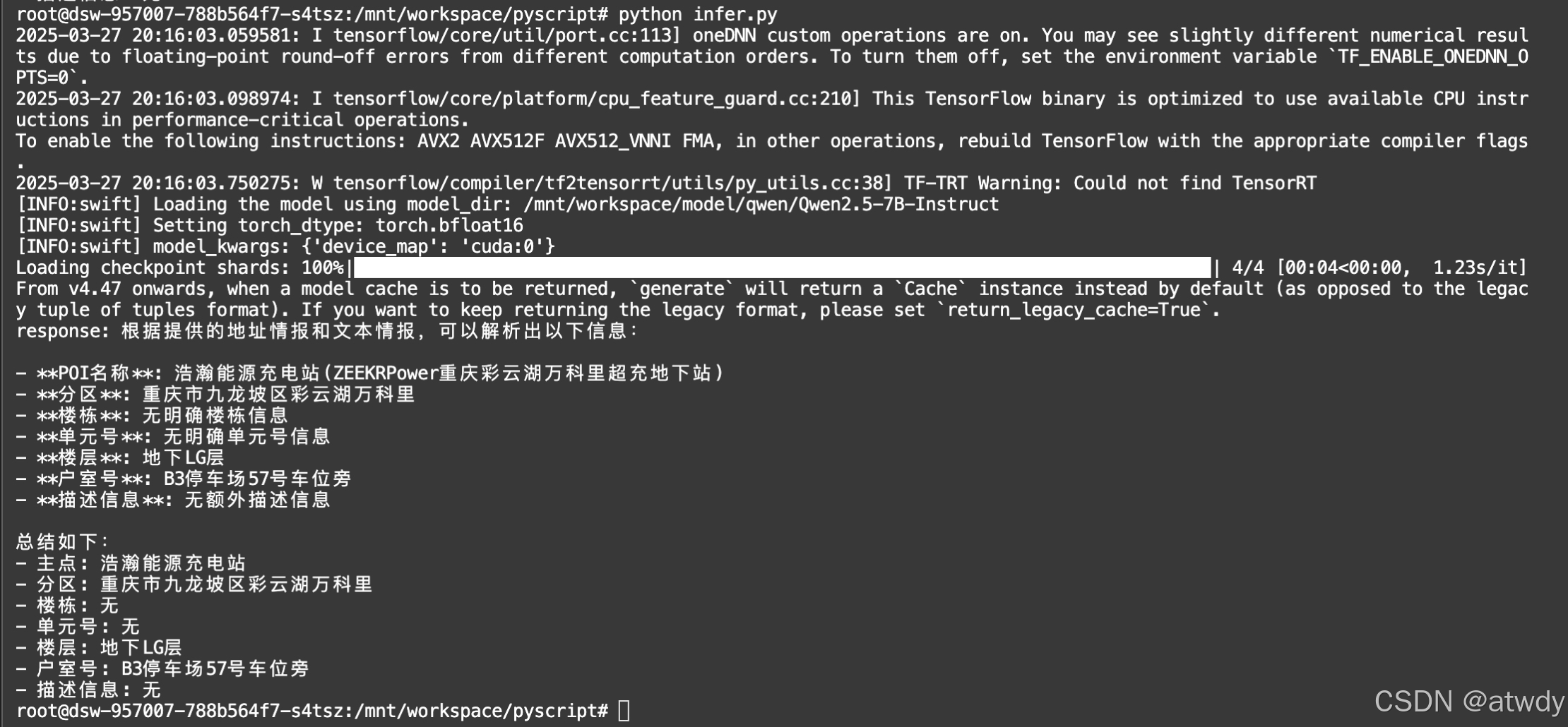
使用下载的基座模型,先测试一下推理效果作为合并LoRA后推理效果的对照,参考https://swift.readthedocs.io/zh-cn/latest/Instruction/%E6%8E%A8%E7%90%86%E5%92%8C%E9%83%A8%E7%BD%B2.html#id2:
import os
from swift.llm import PtEngine, RequestConfig, InferRequest
query = """
请根据以下地址情报和文本情报生成该POI的主点、分区、楼栋、单元号、楼层、户室号、和描述信息。分区、楼栋、单元号、户室号、和描述信息出现在楼层之后提取,出现在楼层之前不提取。
POI名称:浩瀚能源充电站(ZEEKRPower重庆彩云湖万科里超充地下站)|||地址情报:重庆市九龙坡区彩云湖万科里地下LG层B3停车场57号车位旁|||文本情报:
"""
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 本地模型地址
model = '/mnt/workspace/model/qwen/Qwen2.5-7B-Instruct'
# 加载推理引擎 & 设置批推理最多1条
engine = PtEngine(model, max_batch_size=1)
request_config = RequestConfig(max_tokens=512, temperature=0)
# 推理
infer_requests = [InferRequest(messages=[{'role': 'user', 'content': query}])]
response = engine.infer(infer_requests, request_config) # 无论单批推理几条,返回结果都是一个列表
print(f'response: {response[0].choices[0].message.content}')
2.合并LoRA微调结果推理
参考https://swift.readthedocs.io/zh-cn/latest/Instruction/%E9%A2%84%E8%AE%AD%E7%BB%83%E4%B8%8E%E5%BE%AE%E8%B0%83.html
import os
from swift.llm import (
PtEngine, RequestConfig, safe_snapshot_download, get_model_tokenizer, get_template, InferRequest
)
from swift.tuners import Swift
query = """
请根据以下地址情报和文本情报生成该POI的主点、分区、楼栋、单元号、楼层、户室号、和描述信息。分区、楼栋、单元号、户室号、和描述信息出现在楼层之后提取,出现在楼层之前不提取。
POI名称:浩瀚能源充电站(ZEEKRPower重庆彩云湖万科里超充地下站)|||地址情报:重庆市九龙坡区彩云湖万科里地下LG层B3停车场57号车位旁|||文本情报:
"""
# 设置推理显卡
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 本地模型地址
model = '/mnt/workspace/model/qwen/Qwen2.5-7B-Instruct'
# checkpoint路径,注意要详细到最后一个epoch对应的文件夹
ck_dir = '/mnt/workspace/output/charge_new_train850.qwen2.5_7b/v0-20250327-175653/checkpoint-156'
lora_checkpoint = safe_snapshot_download(ck_dir)
template_type = None # 使用对应模型默认的template_type
default_system = "You are a helpful assistant." # 使用对应模型默认的default_system
# 加载模型和对话模板
model, tokenizer = get_model_tokenizer(model)
model = Swift.from_pretrained(model, lora_checkpoint)
template_type = template_type or model.model_meta.template
template = get_template(template_type, tokenizer, default_system=default_system)
engine = PtEngine.from_model_template(model, template, max_batch_size=2)
request_config = RequestConfig(max_tokens=512, temperature=0)
# 推理
infer_requests = [
InferRequest(messages=[{'role': 'user', 'content': query}])
]
response = engine.infer(infer_requests, request_config)
print(f'response: {response[0].choices[0].message.content}')
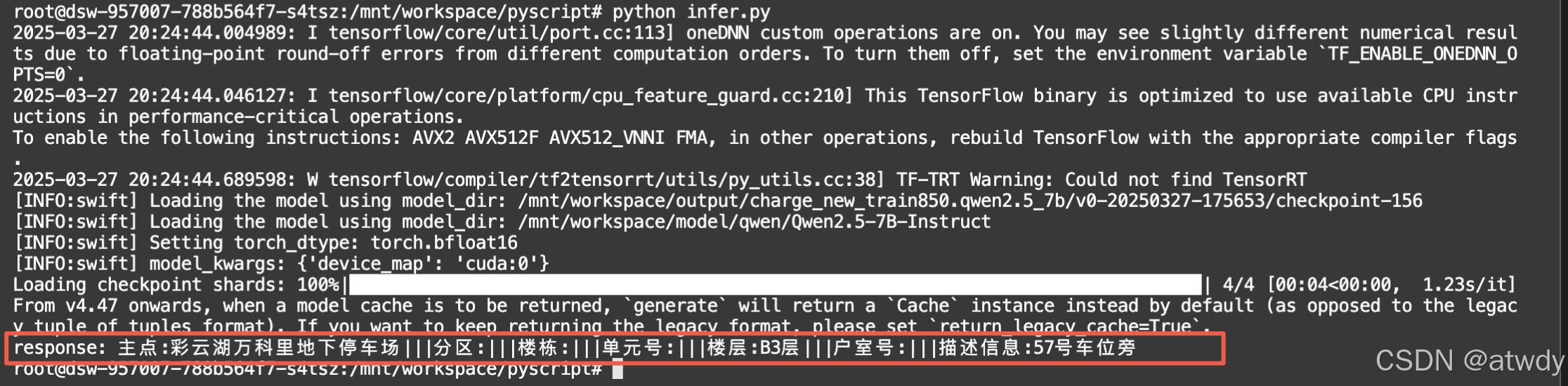
可以看到合并LoRA微调结果之后输出格式按照训练集的格式输出,推理效果也更好。
B3停车场当成B3楼,但符合标注数据的提取逻辑。
API(ms-swift)
github:https://github.com/modelscope/ms-swift
2.x:https://swift2x.readthedocs.io/zh-cn/latest/
3.x:https://swift.readthedocs.io/zh-cn/latest/