python3 的字符串
Python3 字符串知识点详解
一、字符串基础
1. 创建方式
- 单引号/双引号:等效使用,可互相嵌套特殊符号
s1 = '允许嵌入"双引号"' s2 = "包含'单引号'的文本" - 三引号:支持多行字符串,保留换行和缩进格式
s3 = '''第一行 第二行''' - 续行符
\: 将代码拆分为多行,输出为单行:long_str = "This is a very very very \ long string" # 输出为单行
2. 索引与切片
- 索引规则:正向从0开始,负向从-1开始(反向计数)
text = "Python" print(text[0]) # 'P' print(text[-3]) # 'h' - 切片语法:
[start:end:step]print(text[1:4]) # 'yth'(索引1-3) print(text[::2]) # 'Pto'(步长2)
3. 不可变性
- 修改需创建新对象,原字符串不变
s = "Hello" new_s = s[:4] + "p" # 'Help'
二、字符串操作
1. 拼接与重复
- 运算符:
+(拼接)、*(重复)print("Hi" * 3) # 'HiHiHi' print("A" + "B") # 'AB'
2. 常用方法
| 方法 | 功能说明 | 示例 |
|---|---|---|
split(sep) | 按分隔符拆分字符串 | "a,b,c".split(",") → ['a','b','c'] |
join(list) | 合并列表为字符串 | "-".join(['a','b']) → 'a-b' |
replace(old,new) | 替换子串 | "Hi".replace("i","ello") → 'Hello' |
strip() | 去除首尾空白符 | " text ".strip() → 'text' |
upper()/lower() | 全大写/全小写转换 | "AbC".lower() → 'abc' |
3. 格式化方法
- f-string(推荐):直接嵌入变量或表达式
name = "Alice" print(f"Hello, {name.upper()}!") # 'Hello, ALICE!' - 传统占位符:
%或str.format()print("PI: %.2f" % 3.1415) # 'PI: 3.14' - 字符串格式化汇总
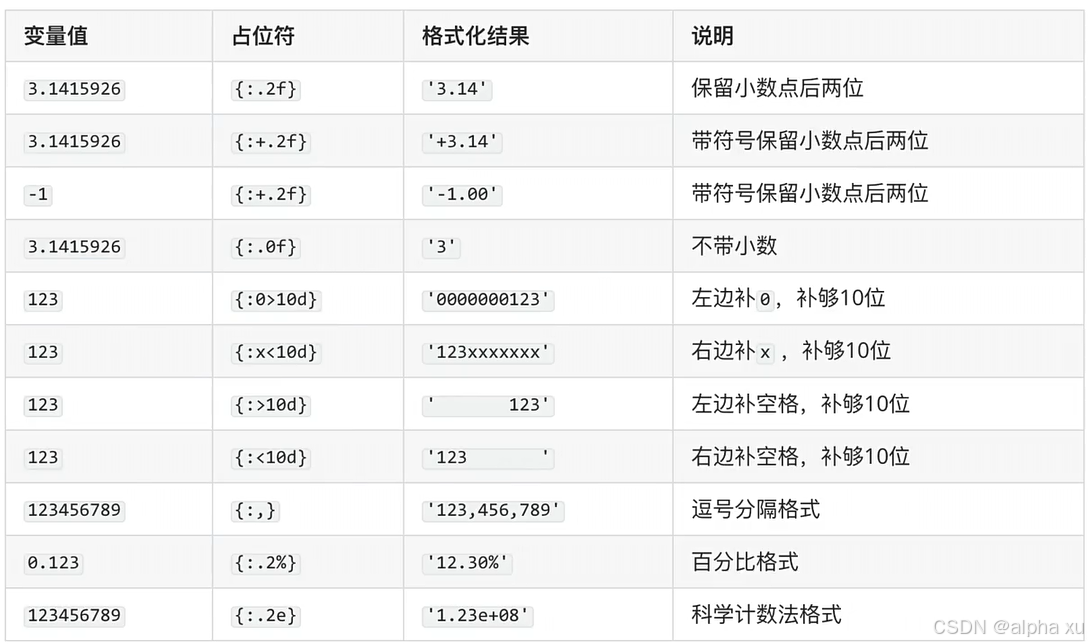
三、高级特性
1. 编码转换
- str ↔ bytes:使用
encode()和decode()bytes_data = "中文".encode("utf-8") # b'\xe4\xb8\xad\xe6\x96\x87' text = bytes_data.decode("utf-8", errors="ignore")
2. 特殊方法
partition(sep):分割为三元组print("key:value".partition(":")) # ('key', ':', 'value')translate():批量字符替换table = str.maketrans("aeiou", "12345") print("apple".translate(table)) # '1ppl2'
3. 正则表达式
- 结合
re模块实现复杂文本匹配import re print(re.findall(r'\d+', "ID:123")) # ['123']
四、字符串转义
1.核心转义字符表
Python使用反斜杠\作为转义标识符,常见转义字符及功能如下:
| 转义字符 | 功能描述 | 示例代码与输出 | 引用来源 |
|---|---|---|---|
\\ | 输出单个反斜杠 | print("C:\\Users") → C:\Users | |
\' / \" | 在单/双引号字符串中输出对应引号 | print('I\'m OK') → I'm OK | |
\n | 换行符(光标移动到下一行行首) | print("A\nB") → 分两行输出 | |
\t | 水平制表符(相当于4个空格) | print("Hi\tPy") → Hi Py | |
\r | 回车符(覆盖行首内容) | print("123\rAB") → AB3 | |
\b | 退格符(删除前一个字符) | print("hel\blo") → hllo | |
\xhh | 十六进制字符编码(如\x41为’A’) | print("\x41") → A | |
\ooo | 八进制字符编码(如\101为’A’) | print("\101") → A | |
\uXXXX | Unicode字符(如\u03A9为希腊字母Ω) | print("\u03A9") → Ω | |
\a | 响铃符(触发系统提示音) | print("\a") → 响铃 |
注意:Windows系统换行符为
\r\n,Linux/Mac为\n
2.原始字符串(Raw String)
在字符串前加r或R前缀可禁用转义解析,常用于正则表达式和文件路径处理:
# 正则表达式场景
import re
pattern = r"\d+\t\w+" # 保留原始反斜杠
match = re.search(pattern, "123\tAbc")
# 文件路径场景
path = r"C:\Users\data\new_folder" # 避免多次转义
注意:原始字符串末尾不能为单反斜杠(需拼接处理):
path = r"C:\folder" + "\\" # 正确写法
3.安全处理与实战技巧
- 用户输入清洗
使用.replace()防止特殊字符注入:
user_input = input("输入内容:").replace("\\", "\\\\") # 转义反斜杠
- 参数化查询
避免SQL注入攻击:
import sqlite3
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
user_input = "1; DROP TABLE users"
# 安全做法(使用占位符)
cursor.execute("SELECT * FROM users WHERE id=?", (user_input,))
- 格式化字符串转义
在f-string中需双重转义:
name = "Alice"
print(f"路径: {name}\\data") # 输出: Alice\data
五、实用技巧
1. 多行处理
textwrap.dedent():消除缩进from textwrap import dedent s = dedent('''保留自然缩进的多行文本''')
2. 性能优化
- 避免
+频繁拼接,优先使用join()# 低效:生成多个临时对象 result = "" for s in list_data: result += s # 高效:单次内存分配 result = "".join(list_data)