清华大学大模型智能体自我认知与决策流程!自知、反思、规划:城市环境目标导航中的大模型智能体新范式


- 作者:Qingbin Zeng 1 ^{1} 1, Qinglong Yang 1 ^{1} 1, Shunan Dong 1 ^{1} 1, Heming Du 2 ^{2} 2, Liang Zheng 2 ^{2} 2, Fengli Xu 1 ^{1} 1, Yong Li 1 ^{1} 1
- 单位: 1 ^{1} 1清华大学电子工程系, 2 ^{2} 2澳洲国立大学计算学院
- 论文标题:Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions
- 论文链接:https://arxiv.org/pdf/2408.04168
- 代码链接:https://anonymous.4open.science/r/PReP-13B5
主要贡献
- 论文提出PReP(Perceive, Reflect, and Plan)智能体工作流,以提高大模型(LLMs)在城市导航中的空间认知能力。
- 通过微调LLaVA-7B模型,论文展示了该模型能够以足够的准确性感知地标的大致方向和距离,从而支持城市导航任务。
- 设计了存储和检索历史经验的记忆机制来帮助智能体形成认知地图,使得智能体能够在当前感知的基础上进行有效的决策论证。
- 提出了利用反思结果生成长期计划的规划模块,以避免在长距离导航中的短视决策,显著提高了智能体在城市导航中的成功率。
研究背景
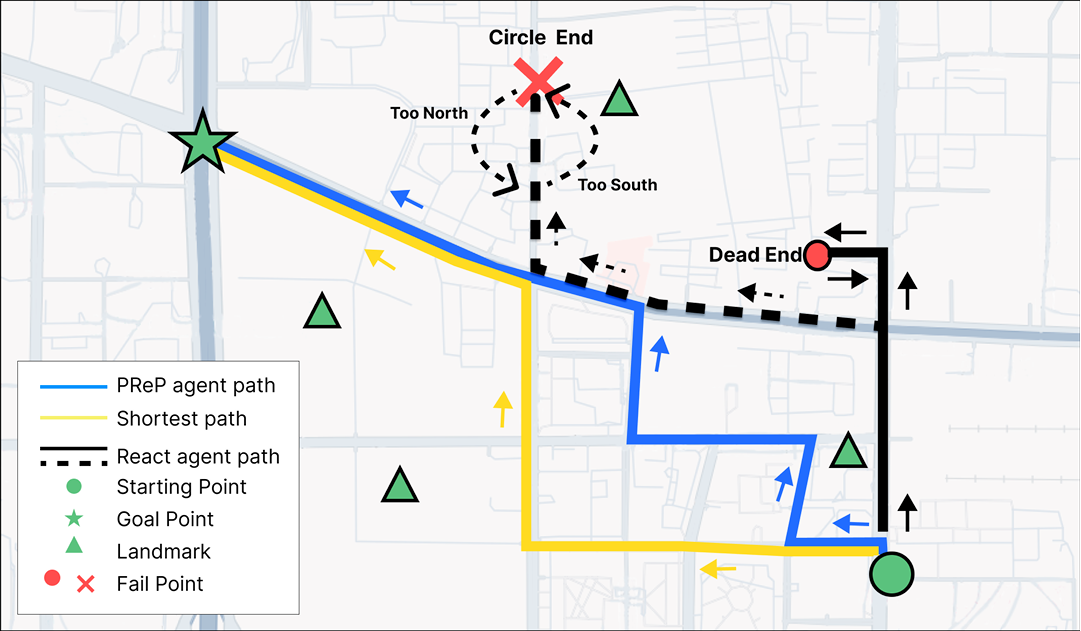
研究问题
论文研究了在没有导航指令和地图的情况下,AI智能体如何在城市环境中进行目标导向的导航。
具体来说,智能体通过观察周围场景(包括识别地标和道路网络连接)来决策如何导航到目标地点。
研究难点
该问题的研究难点包括:
- 智能体需要建立自我位置感知并获得复杂城市环境的空间表示;
- 在没有导航指令的情况下,智能体需要构建认知地图以进行高质量的导航决策。
相关工作
-
视觉语言导航(VLN):
- VLN旨在使智能体能够基于自然语言指令在视觉环境中自主导航。
- 该领域从室内环境扩展到城市环境,任务范围和数据集也有所增加。
- 早期的研究包括Anderson等人创建的VLN数据集,以及Mirowski等人引入的跨模态匹配模型,这些模型利用注意力和强化学习来实现视觉和文本的整合。
-
使用LLMs的VLN方法:
- 近年来,大模型(LLMs)被引入到VLN中,为解决室内环境中的导航问题提供了新的解决方案。
- 例如,Zhou等人、Dorbala等人、Zu等人的研究展示了LLMs在室内环境中的应用成功。
-
户外VLN研究:
- 其他研究如Shah等人、Schumann等人专注于户外VLN,利用LLMs强大的语言理解能力进行基于地面的导航。
- 相比之下,本文提出的方法是一种目标导向的城市导航,不需要逐步的语言指令或地图。
-
智能体工作流与LLMs:
- 探索使用LLMs的智能体工作流成为一种有效的策略,用于解决规划问题。
- 研究表明,反思(如Huang等人、Shinn等人)和交互式规划方法(如Wang等人、Hao等人)可以增强智能体的理解并减少错误。
- 其他工作流,如CaP(Liang等人)、ProgPrompt(Singh等人)、CoT(Wei等人)和ToT(Yao等人),为如何引导LLMs执行目标导向任务提供了集体理解。
- 然而,这些方法大多用于数学和常见推理问题,关于LLMs是否能够处理空间推理,特别是在导航问题中,尚未得到充分研究。
任务定义与数据集
任务定义
-
城市环境定义:
- 城市环境被描述为一个无向图 G = ⟨ V , E ⟩ G = \langle V, E\rangle G=⟨V,E⟩,其中每个节点 v i ∈ V v_i \in V vi∈V 表示道路上的一个位置,附加的视觉信息(街景图像)为 S i = { s i 1 , s i 2 , … , s i k } S_i = \{s_i^1, s_i^2, \ldots, s_i^k\} Si={si1,si2,…,sik}。
- 边 e i j ∈ E e_{ij} \in E eij∈E 表示节点 v i v_i vi 和 v j v_j vj 之间的移动路径。
- 地标 L M = { l m 1 , l m 2 , … , l m n } L M = \{l m_1, l m_2, \ldots, l m_n\} LM={lm1,lm2,…,lmn} 被定义为图中独立的顶点。
-
城市导航任务定义:
- 任务的目标是从起始节点 v s v_s vs 到目标节点 v g v_g vg 找到一条路径。具体来说,给定一个导航任务 T = ⟨ v s , v g , D ⟩ T = \langle v_s, v_g, D\rangle T=⟨vs,vg,D⟩,目标是找到一条最短路径到达目标。
- 描述 D = { R 1 , R 2 } D = \{R_1, R_2\} D={R1,R2} 用于确定目标,其中 R 1 = { R ( v g , l m ) ∣ l m ∈ L M s } R_1 = \{R(v_g, lm) | lm \in L M_s\} R1={R(vg,lm)∣lm∈LMs} 是目标与可见地标之间的相对位置关系, R 2 = { R ( l m i , l m j ) ∣ l m i , l m j ∈ L M } R_2 = \{R(lm_i, lm_j) | lm_i, lm_j \in LM\} R2={R(lmi,lmj)∣lmi,lmj∈LM} 是环境中所有地标之间的相对位置关系。
-
智能体行为定义:
- 在时间 t t t 和节点 v t v_t vt 处,智能体根据街景图像和道路连接做出决策,识别街景中的地标并推断目标的方向和距离 R ( v t , v g ) R(v_t, v_g) R(vt,vg),然后导航到目标。
数据集
- 数据集从四个城市的中央商务区(CBD)收集,覆盖几公里的范围。
- 道路网络数据被提取并以50米的间隔离散化,形成城市环境 G G G。
- 每个道路网络的节点与相应的街景图像关联。街景图像的数量等于节点的度数。
- 每个区域选择了几座著名的建筑作为地标。
- 数据集的可视化示例和任务示例在论文中展示。
PReP智能体工作流
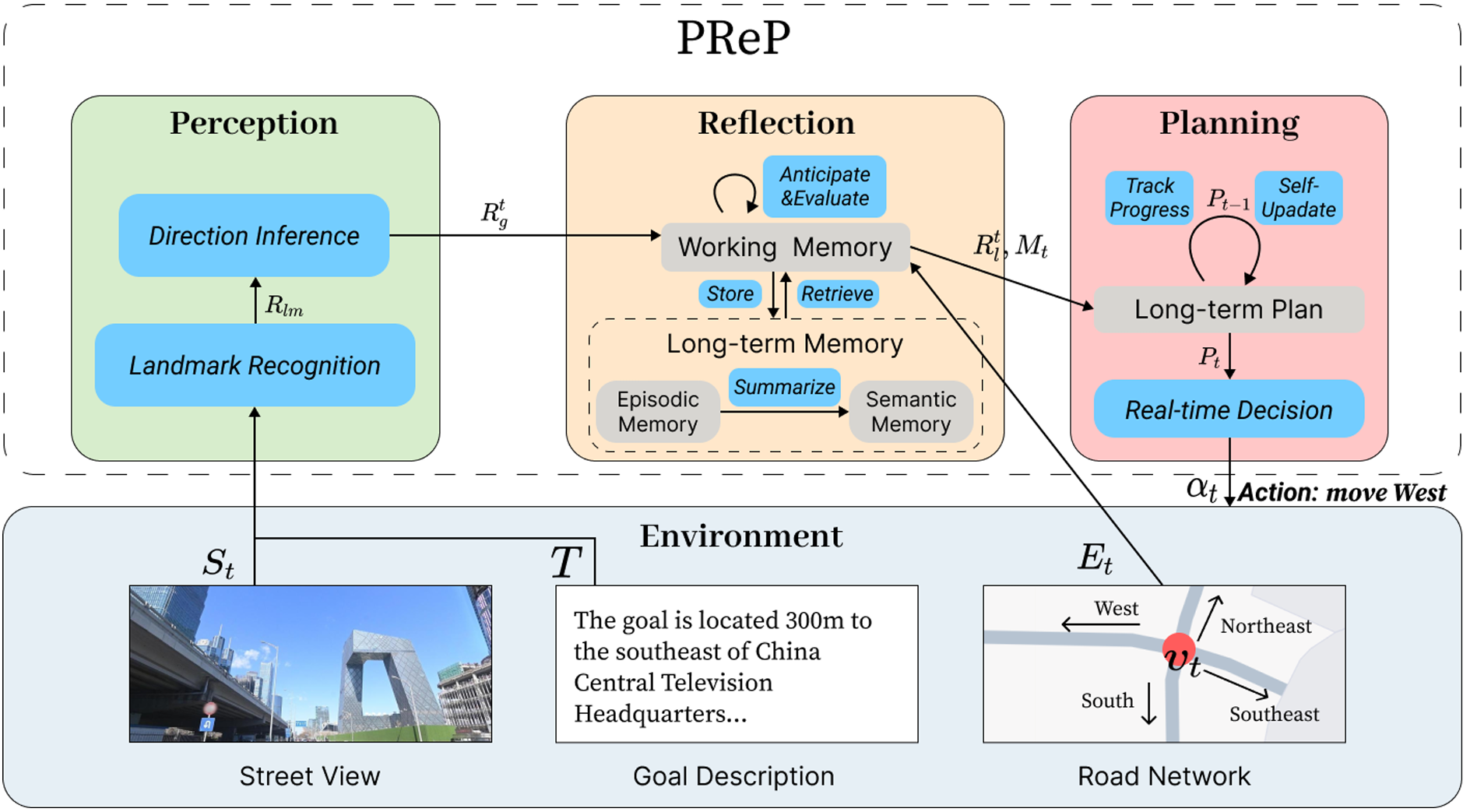
PReP工作流由三个主要部分组成:视觉感知、反思与记忆、以及规划。
感知
-
视觉感知能力:
- 智能体通过视觉感知识别街景图像中的地标,并预测目标的方向和距离。
- 使用微调的LLaVA-7B模型进行感知,因为LLaVA是一个多模态模型,能够同时处理文本和图像。
- 智能体通过检测地标并估计其相对于智能体的位置 R l m = { R ( l m i , v t ) ∣ l m i ∈ L M } R_{lm} = \{R(lm_i, v_t) | lm_i \in LM\} Rlm={R(lmi,vt)∣lmi∈LM} 来获取地标的位置信息。
-
目标方向的推断:
- 智能体结合地标位置和任务描述来推断目标的方向。
- 使用余弦定理等方法来计算目标相对于智能体的方向和距离 R g t = R ( v g , v t ) R_g^t = R(v_g, v_t) Rgt=R(vg,vt)。
反思与记忆
-
反思机制:
- 反思部分通过总结过去的经验和反思视觉感知结果来帮助智能体形成认知地图。
- 包括长期记忆和工作记忆两个主要组件。
-
长期记忆:
- 情景记忆:存储导航数据和历史轨迹,格式化为自然语言句子。
- 语义记忆:使用LLMs从情景记忆中总结和学习,形成高层次的认知功能,帮助智能体构建内在的导航地图表示。
-
工作记忆:
- 接收感知结果并从长期记忆中检索相关经验。
- 设计了预期-评估机制,以解决在街景中无法检测到地标的问题。
- 工作记忆使用历史感知结果 R g t ′ R_{g}^{t'} Rgt′ 和移动方向来预期潜在的目标方向 R R R。
规划
-
规划模块:
- 规划模块结合反思后的目标推断、检索的记忆和当前的路径连接来生成导航计划。
- 将完整的路径分解为多个子目标,确保在长距离导航中的一致性和合理性。
-
短期决策:
- 短期决策器将计划转化为具体的行动,基于当前的路径连接。
- 行动 α t = L L M a c t i o n ( P t , E t ) \alpha_t = LLM_{action}(P_t, E_t) αt=LLMaction(Pt,Et) 表示从节点 v t v_t vt 移动到节点 v t + 1 v_{t+1} vt+1。
实验
实验设置
-
实验环境:
- 实验在模拟的城市导航任务中进行,评估所提出的智能体工作流的有效性。
- 使用成功率和路径长度加权成功率(SPL)来衡量系统的效果和效率。
-
数据集:
- 实验在四个城市的四个测试集上进行,每个测试集包含100个不同的导航任务,每个任务有不同的起始点和目标点。
- 每个起始点和目标点的选择是随机的,有时会在没有可见地标的位置,增加了任务的挑战性。
- 从起始节点到目标节点的最小步数遵循正态分布,平均值为30步,标准差为10步,每一步对应地图上的50米。
-
迭代限制:
- 设置迭代次数为最小步数的2.5倍。如果智能体超过这个限制仍未到达目标,则视为任务失败。
主要结果

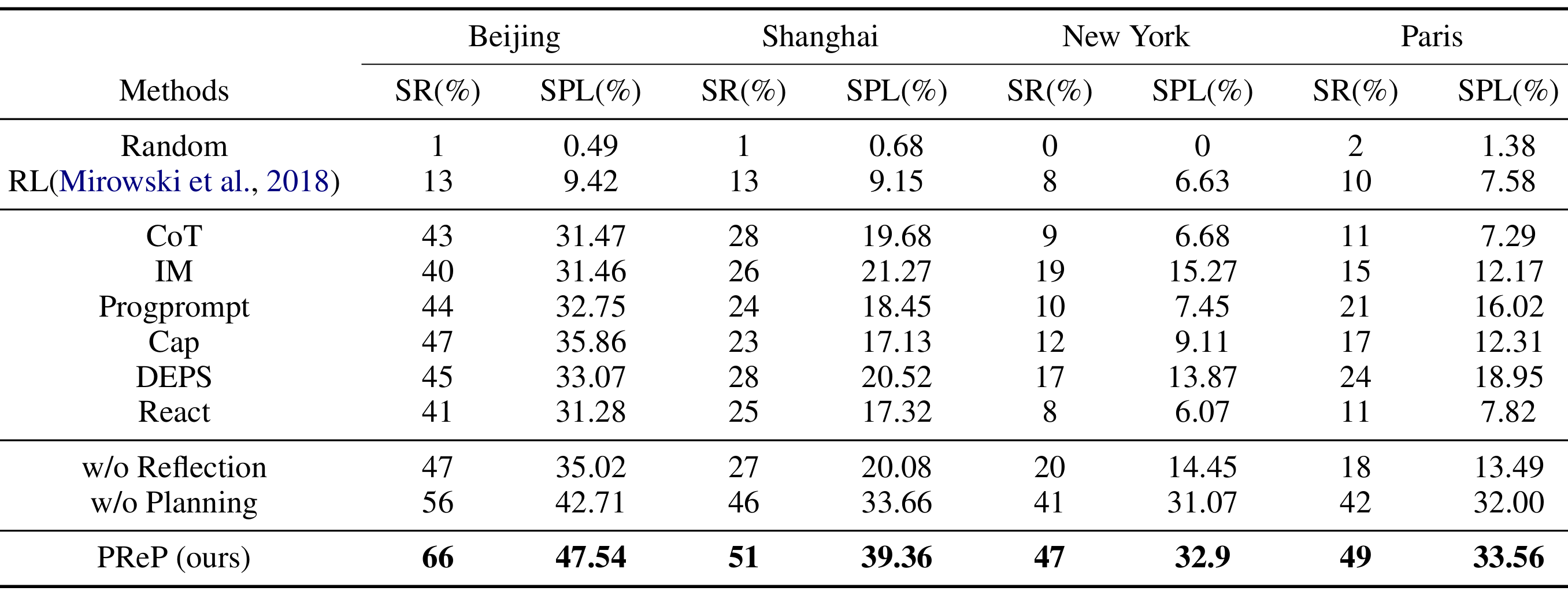
- 与现有方法的比较:
- 将PReP与现有的基于语言的方法进行比较,包括Code as Policies (CaP)、ProgPrompt、Inner Monologue (IM)、Chain of Thought (CoT)、DEPS和React。
- 还实现了两种非LLM基线方法:随机方法和强化学习(RL)方法。
- 所有语言方法使用GPT-4-turbo作为基础模型,所有LLM的超参数相同,以确保公平比较。
-
实验结果:
- PReP在所有城市中均表现出最佳导航性能。
- 例如,在北京的测试集上,PReP的成功率为66.68%,SPL为48.25%,显著优于其他方法,如DEPS(成功率45%,SPL 33.07%)和CaP(成功率47%,SPL 35.86%)。
-
消融研究:
- 进行消融研究以验证反思和规划方法的有效性。
- 结果显示,完整的PReP工作流表现最佳。例如,在北京的测试集上,PReP的成功率比仅使用感知的方法高25%,比无反思的方法高19%,比无规划的方法高10%。
进一步分析

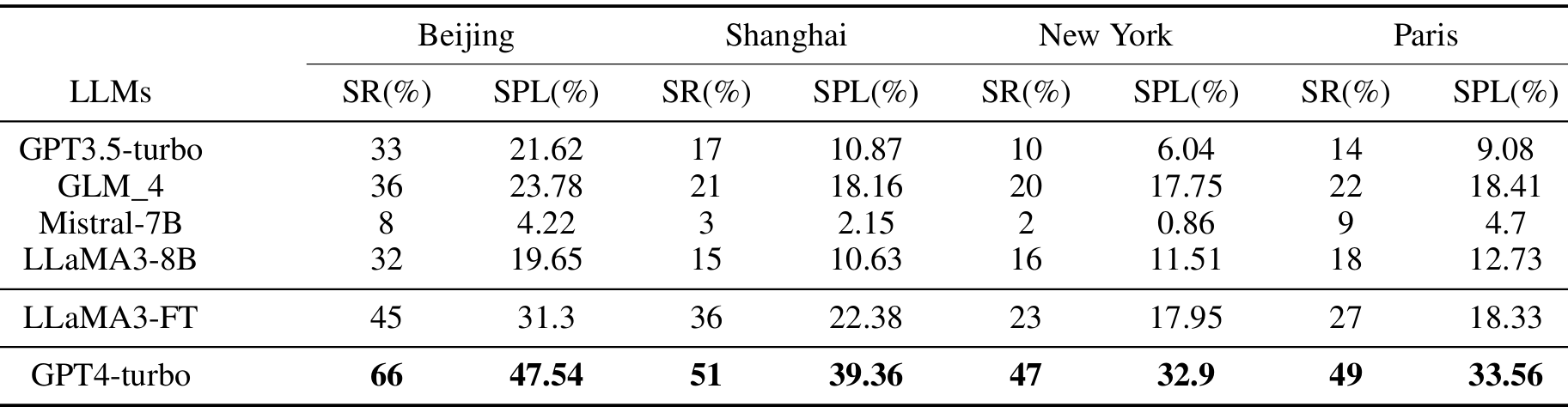
- LLaVA微调的效果:
- 比较微调后的LLaVA和零样本LLaVA的性能,发现微调后的LLaVA在成功率和SPL上均有显著提升。
-
不同LLM的比较:
- 使用不同的LLM进行推理,结果显示GPT-4-turbo表现最佳,微调后的LLaMA3表现次之。
-
目标距离的影响:
- 分析目标距离对成功率的影响,发现成功率在目标距离达到2公里时仍保持相对稳定。
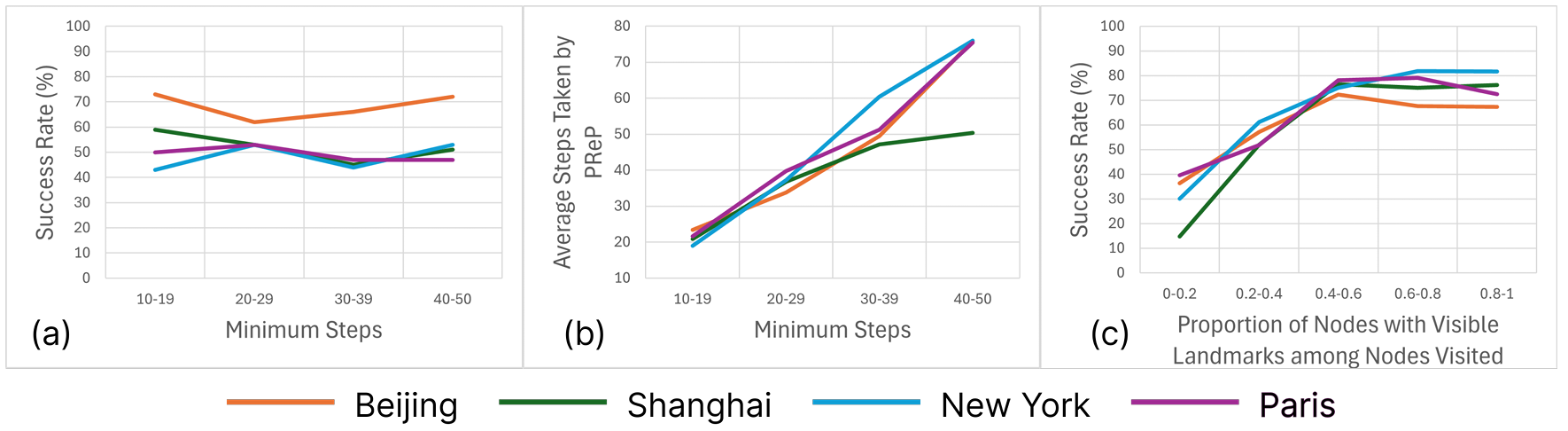
- 地标可见性的影响:
- 研究地标可见性对成功率的影响,发现路径上可见地标比例的增加显著提高了成功率。
总结
- 论文提出了用于目标导向城市导航的智能体工作流。
- 该工作流包括微调的LLaVA模型进行空间感知、记忆模块用于综合和反思感知结果及检索的记忆,以及规划模块用于导航路线规划。
- 论文展示了LLMs在城市导航任务中的应用潜力,并通过反思和规划模块显著提高了导航性能。
