大数据运维实战之YARN任务内存泄露排查实战:从节点掉线到精准定位的完整指南
1.问题背景:集群内存风暴引发的危机
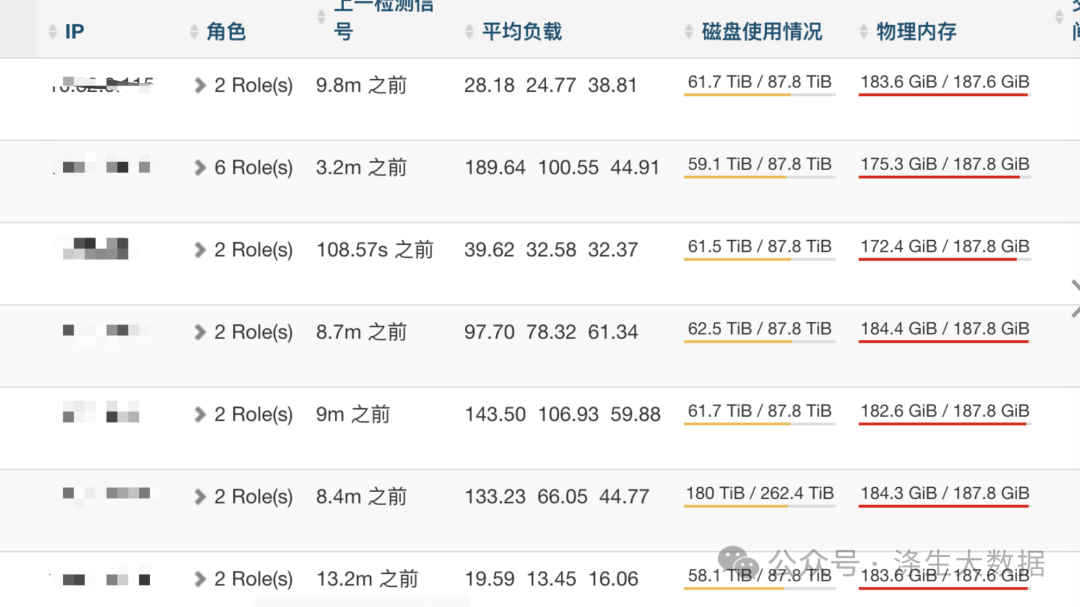
最近某大数据集群频繁出现节点掉线事故,物理内存监控持续爆红。运维人员发现当节点内存使用率达到95%以上时,机器会进入不可响应状态,最终导致服务中断。这种"内存雪崩"现象往往由单个异常任务引发,如何快速定位问题作业成为当务之急。
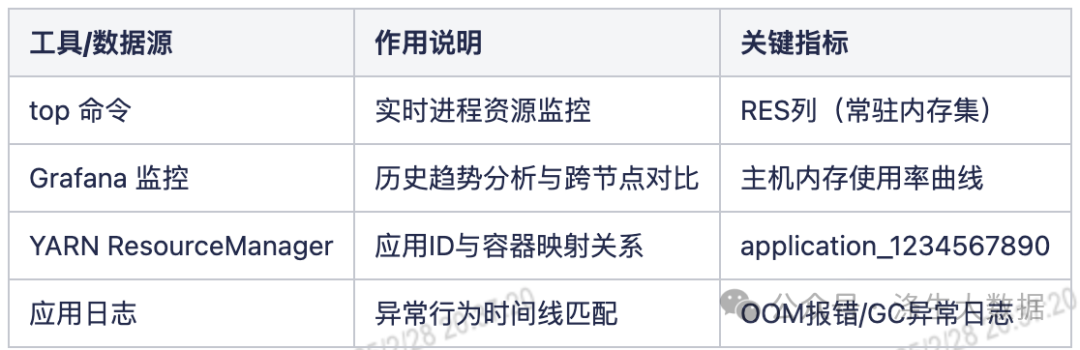
2.排查武器库:核心工具与数据源
3.四步定位法实战演示

步骤1:内存异常节点锁定
通过Grafana筛选出满足以下特征的节点:
-
内存使用率曲线呈阶梯状持续增长
-
当前内存使用率>85%但未完全宕机
-
出现时间集中在业务高峰时段
# 示例节点内存趋势
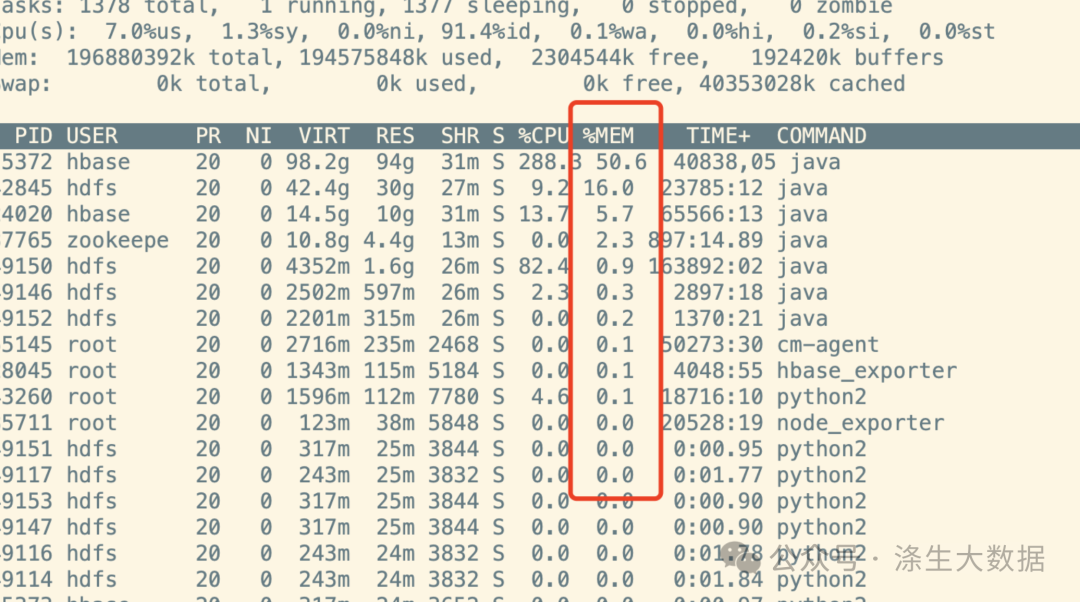
步骤2:内存占用双重验证
通过top命令与监控数据交叉验证:
通过 grafana 监控选定主机查看内存使用率,此时会发现 top计算出来的内存使用会比监控采集的内存小很多,且监控中能发现,主机的内存在某个时间点之后持续攀升。注意点:当top显示的RES总和远小于实际内存消耗时,可能存在:
-
Buffer/Cache未被及时释放
-
内存碎片化严重
-
内核级内存泄漏(需排查slabinfo)
步骤3:异常进程关联应用ID
通过进程PID反向查找YARN应用:
再用 top 指令拿到本机内存使用很高的几个 PID,通过 ps 获取到PID 对应的application ID。
提示:多找几台机器重复上面的操作,选出几台机器同时共存的 application ID。
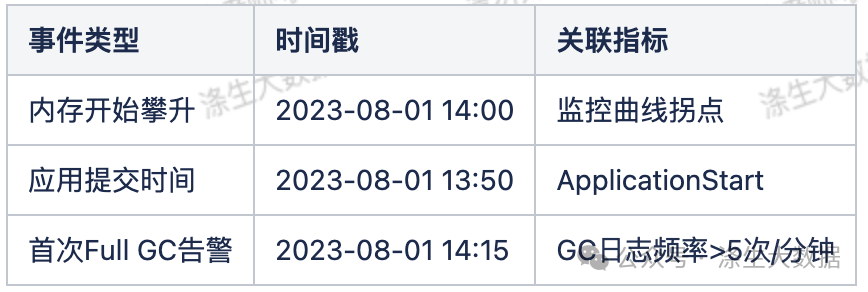
步骤4:时空关联分析
建立时间线对照表:
通过观察上面步骤找出来的 appid,主要看这几个 application 的运行日志是否异常、提交时间和机器内存异常攀升的时间点是否吻合。
4.典型内存泄漏模式识别
1. 堆外内存泄露特征
-
JVM堆内存稳定,但RES持续增长
-
Netty等NIO框架使用后未释放DirectBuffer
-
出现
java.lang.OutOfMemoryError: Direct buffer memory
2. 元空间泄露特征
-
Metaspace使用量超过-XX:MaxMetaspaceSize
-
频繁动态生成类(如Groovy脚本引擎)
-
日志出现
java.lang.OutOfMemoryError: Metaspace
3. 缓存失控增长
-
Guava Cache未设置过期策略
-
使用静态Map做缓存且无淘汰机制
-
缓存命中率持续下降,堆内存直线上升
5.防御性编程实践
1. 容器化部署约束

2. JVM参数加固

3. 监控体系增强
建议部署以下监控项:
-
每个容器的RES/VIRT内存使用量
-
JVM各内存池(Old/Young/Metaspace)占比
-
容器存活状态心跳检测
-
Full GC频率与持续时间
6.总结与反思
通过本次排查我们得出以下经验:
-
内存问题要早于OOM发生前介入,85%使用率即需预警
-
多维度数据交叉验证(主机/容器/JVM三级监控)
-
优先在测试环境复现问题,避免生产环境直接操作
建议后续优化方向:
-
建立应用内存画像基线,识别异常增长模式
-
在调度层添加内存使用率弹性约束
-
定期进行内存泄露专项测试(如JMeter压力测试)