详解套接字 Socket 与网络 IO 模型演进
详解套接字 Socket 与网络 IO 模型演进
前言:我要吐了,学 redis 要看网络模型,学 nginx 要看网络模型,学 tomcat 要看网络模型,学 netty 要看网络模型,每次看到文档中的 select、epoll、poll 头都大了,最近找了多篇参考资料,总结 socket 和各种网络模型到底指的什么,演进流程是怎么样的,希望这篇文章可以总结清楚。
从网络通信说开去
我们知道,网络中的请求的发送,以 http 为例,需要逐层封装和解封,比如我发送了一个订单要买东西,从上到下依次要经过这些流程:
- 我要买东西(正文)
- Http头部:我要买东西
- TCP头部:Http头部:我要买东西
- IP头部:TCP头部:Http头部:我要买东西
- MAC头部:IP头部:TCP头部:Http头部:我要买东西
最后经过网关、路由器等中间设备,一步步的到对方服务器进行处理
这是我们计算机网络学习的东西,那么引申出一个问题,socket 是什么?因为在上述的流程里,我们完全没有看到 socket 的影子。
当请求到达对方服务器,进行一层一层的拆包,拆下 TCP 头部后,服务器发现这是给我 8080(假设是 tomcat 默认端口) 端口这个应用的,操作系统是不关心这到底是给哪个应用的,它只负责拆包,填充包,发送,解析等内容。有包来了,是需要应用程序来监听的,我们平时说 tomcat 监听的是 8080 端口就是这个意思。我们知道 linux 是区分用户态和内核态的,tomcat 作为上层应用当然是运行在用户态,但是 MAC 地址、IP 头部、TCP 头部都是在内核态进行处理的,那么当请求来了的时候,tomcat 需要接收,用户态该怎么进入内核态呢,没错,就是 socket 系统调用,所以在使用 socket 编程时,需要绑定端口号,因为要从内核获取发给指定端口号的包。
socket 不是网络分层体系中的概念,自然也没有说处于哪一层次这个说法,它是用户态和内核态进行通信的一个机制。
Socket 编程及演进
我们平时会提到 Socket 网络编程,原因是 tcp、udp 是内核态下的东西,不方便直接调用,Socket 是在其上面的一个抽象,提供了封装好的 API。Socket 可以作插口或者插槽讲,虽然我们是写软件程序,但是你可以想象为弄一根网线,一头插在客户端,一头插在服务端,然后进行通信。所以在通信之前,双方都要建立一个 Socket。
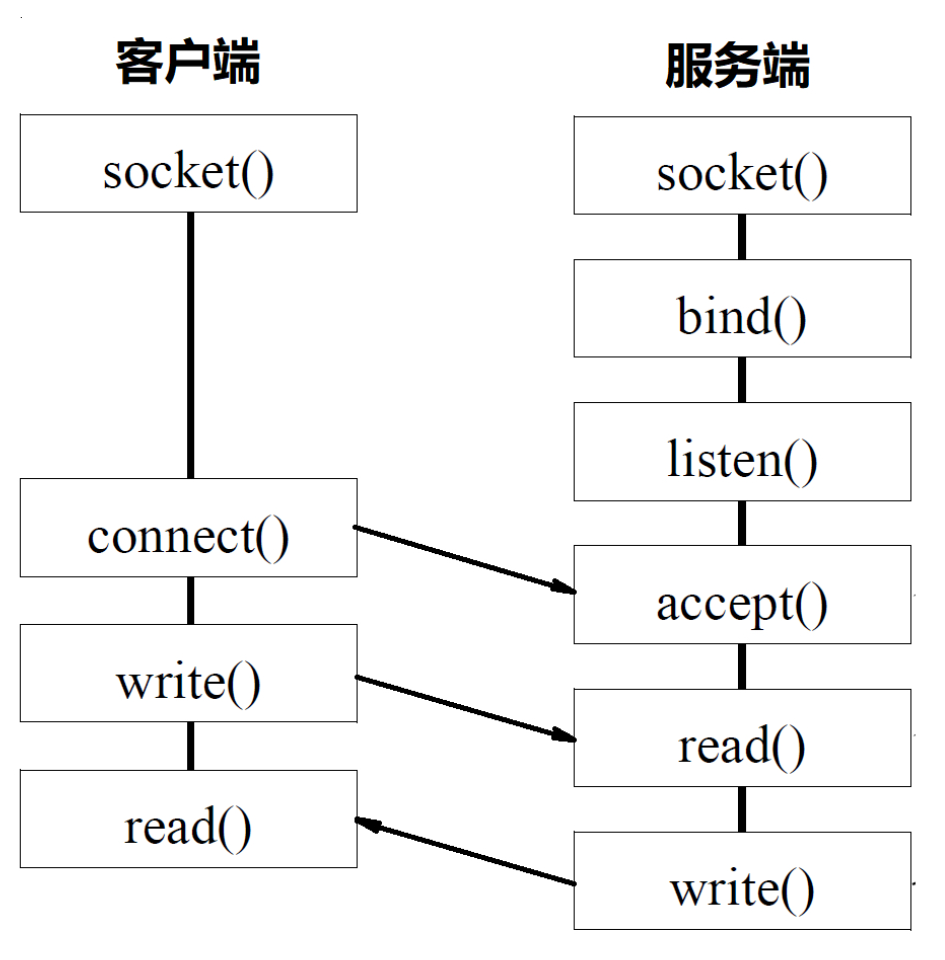
对于服务端:
- 创建一个 Socket,绑定一个端口(bind)
- 监听这个端口(listen)
- 获取这个端口传来的数据(accept)
- 读取数据(read)
- 给予响应(write)
注意一个问题,第一步创建的 Socket 我们称为监听Socket,而第三步获取的称为已连接Socket。可以这样理解:监听 Socket 会去问内核要发往绑定端口的数据,如果要到了,带回来一个,也就是对应 accept 操作,没有要到,程序就会阻塞在这里,直到有数据到来。
对于客户端:
- 连接远程主机的端口(connect)
- 发送数据(write)
- 读取响应(read)
可以用以下图示来进行说明:
以下是 java 语言实现客户端和服务端在 9090 端口通信的一个案例程序:
服务端:
import java.io.*;
import java.net.*;
public class Server {
public static void main(String[] args) {
int port = 9090;
try {
// 创建 ServerSocket 监听指定端口
ServerSocket serverSocket = new ServerSocket(port);
System.out.println("服务器启动,监听端口: " + port);
while (true) {
// 等待客户端连接
Socket clientSocket = serverSocket.accept();
System.out.println("客户端连接成功,来自: " + clientSocket.getInetAddress());
// 获取客户端的输入流
BufferedReader input = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
// 获取客户端的输出流
PrintWriter output = new PrintWriter(clientSocket.getOutputStream(), true);
String message;
// 循环读取客户端发送的消息
while ((message = input.readLine()) != null) {
System.out.println("客户端发送的消息: " + message);
// 回应客户端
output.println("服务器收到消息: " + message);
}
// 关闭连接
input.close();
output.close();
clientSocket.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 第 9 行,只标识了端口,这个构造器方法会自动绑定本地的对应端口并进行监听(bind、listen)
- 第 13 行,调用 accept 获取一个客户端发送来的 socket
客户端:
import java.io.*;
import java.net.*;
public class Client {
public static void main(String[] args) {
String serverAddress = "127.0.0.1"; // 本机地址
int port = 9090;
try {
// 连接到服务器
Socket socket = new Socket(serverAddress, port);
System.out.println("连接到服务器: " + serverAddress + ":" + port);
// 获取输出流并发送消息给服务器
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 创建输入流来读取用户输入
BufferedReader userInput = new BufferedReader(new InputStreamReader(System.in));
String message;
// 循环发送消息给服务器
while (true) {
System.out.print("请输入消息发送给服务器 (退出请输入 'exit'): ");
message = userInput.readLine();
// 退出条件
if ("exit".equalsIgnoreCase(message)) {
break;
}
// 发送消息给服务器
out.println(message);
// 读取并输出服务器的响应
String response = in.readLine();
System.out.println("服务器回应: " + response);
}
// 关闭连接
userInput.close();
out.close();
in.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 第 10 行,连接远程地址的对应端口,返回一个 socket,注意这里并没有指定本机端口,内核会给客户端分配一个临时的端口。一旦握手成功,服务端的 accept 就会返回这个 socket
其实这个很好理解,服务端如果只有一个监听 socket 用来接收数据,那么无法标识同时到来的多个请求,不知道哪个请求该回复给谁,所以针对每一个连接,都有一个已连接 socket。
但是你如果仔细看服务端的代码,会发现一个问题
while (true) {
// 等待客户端连接
Socket clientSocket = serverSocket.accept();
.......
// 关闭连接
input.close();
output.close();
clientSocket.close();
}
服务端接收一个客户端 socket 后,会一直为其服务,直到这个连接关闭后才继续 while 循环,处理其他的连接请求,那这样的程序并发一定不高,基本退化成了一对一沟通,这样肯定不行,我们要对其进行优化。
在优化前,我们先计算一下服务端最多能接收多少个请求,一个 socket 可以用 [本机ip、本机端口、客户端ip、客户端端口]这样的四元组表示,那么对于一个服务程序来说,【本机ip、本机端口】是固定的,【客户端ip、客户端端口】的最大数量约为 232 * 216 这样,当然这只是逻辑上,实际数量远远远远少于这个值,因为具有以下限制:
- linux 中一切皆文件,Socket 也是文件,所以首先要通过 ulimit 配置文件描述符的数目
- 每一个连接都消耗内存,操作系统的资源是有限的
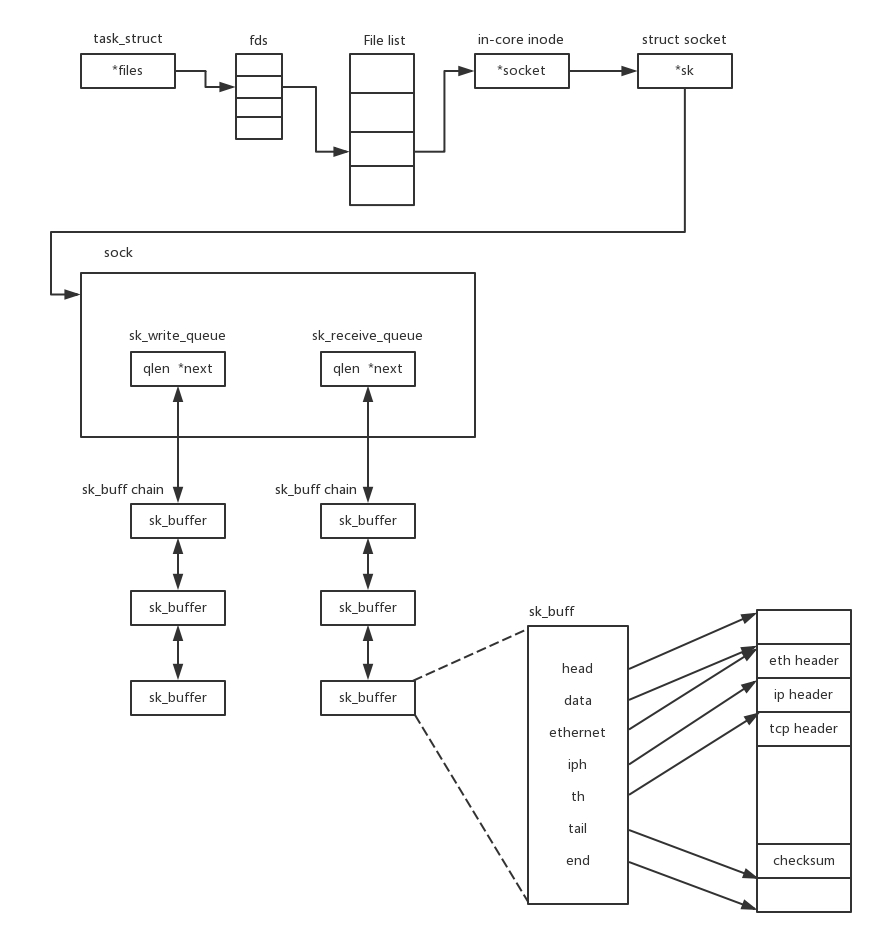
注意:在内核中,Socket 是一个文件,那对应就有文件描述符。每一个进程都有一个数据结构 task_struct,里面指向一个文件描述符数组,来列出这个进程打开的所有文件的文件描述符。文件描述符是一个整数,是这个数组的下标。这个数组中的内容是一个指针,指向内核中所有打开的文件的列表。既然是一个文件,就会有一个 inode,只不过 Socket 对应的 inode 不像真正的文件系统一样,保存在硬盘上的,而是在内存中的。在这个 inode 中,指向了 Socket 在内核中的 Socket 结构。
【优化1】每获得一个新的已连接 socket,都丢给一个新进程去做
一旦建立了一个连接,就会有一个已连接 Socket,这时候你可以创建一个子进程,然后将基于已连接 Socket 的交互交给这个新的子进程来做。如果你对 redis 有一定了解,可能会想到 redis 开启后台进程去做一些事情:比如持久化,调用的是 linux 的 fork 函数,fork 的消耗是很大的,会复制主进程的所有内容,页表项、内存空间等,当然也能获得主进程刚获得的已连接 Socket,就可以去进行自己的处理了
【优化2】每获得一个新的已连接 socket,都丢给一个新线程去做。每次 fork 新的进程消耗还是太大了,而创建一个线程不用复制那么多东西,直接引用父进程的页表项等就行。但是有个C10K 问题,它的意思是一台机器要维护 1 万个连接,就要创建 1 万个进程或者线程,那么操作系统是无法承受的
【优化3】一个线程维护多个 socket,有事来轮询处理(select)
由于 Socket 是文件描述符,因而某个线程盯的所有的 Socket,都放在一个文件描述符集合 fd_set 中,然后调用 select 函数来监听文件描述符集合是否有变化。一旦有变化,就会依次查看每个文件描述符。那些发生变化的文件描述符在 fd_set 对应的位都设为 1,表示 Socket 可读或者可写,从而可以进行读写操作,然后再调用 select,接着盯着下一轮的变化
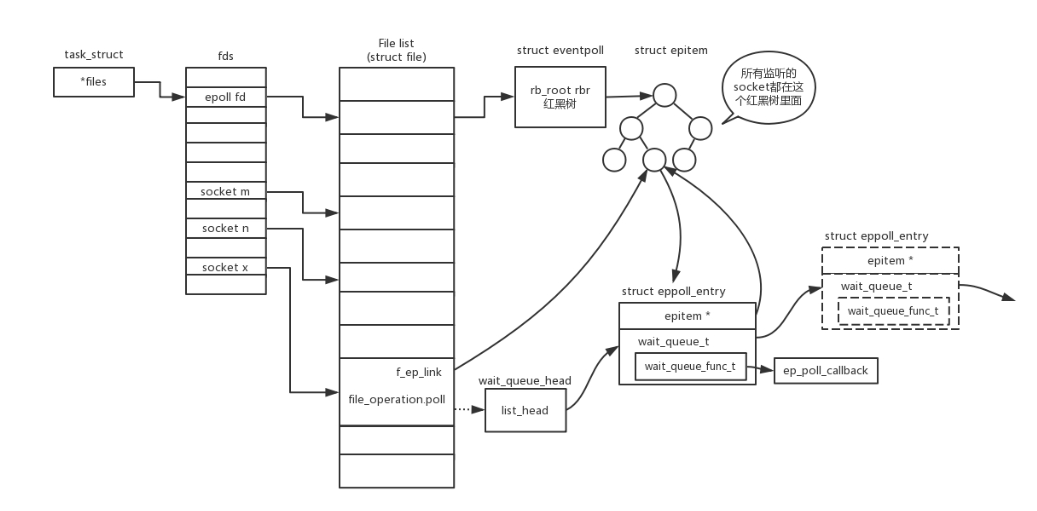
【优化4】一个线程维护多个 socket,但是由 socket 通知线程处理(epoll)
上面 select 函数还是有问题的,因为每次 Socket 所在的文件描述符集合中有 Socket 发生变化的时候,都需要通过轮询的方式,也就是需要将全部项目都过一遍的方式来查看进度,因而使用 select,能够同时盯的 socket 数量由 FD_SETSIZE(通常为1024) 限制。
如果改成事件通知的方式,情况就会好很多,项目组不需要通过轮询挨个盯着这些项目,而是当项目进度发生变化的时候,主动通知项目组,然后项目组再根据项目进展情况做相应的操作。能完成这件事情的函数叫 epoll,它在内核中的实现不是通过轮询的方式,而是通过注册 callback 函数的方式,当某个文件描述符发送变化的时候,就会主动通知。这种通知方式使得监听的 Socket 数据增加的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了。上限就为系统定义的、进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器
【1】上述流程大多基于 TCP 连接分析,UDP 由于不需要握手什么的,流程会简单一点
【2】图示需要对 网络协议、linux 数据结构有一定了解,参考极客时间刘超老师专栏:趣谈 Linux 操作系统