【回归算法解析系列07】决策树回归(Decision Tree Regressor)
【回归算法解析系列】决策树回归(Decision Tree Regressor)
1. 决策树回归:非参数化的非线性建模
决策树回归(Decision Tree Regressor)是一种基于树结构的非参数模型,它在机器学习领域中占据着重要的地位。其核心优势体现在多个方面:
1.1 处理非线性关系
在现实世界的数据中,很多特征与目标变量之间的关系并非简单的线性关系。决策树回归无需对数据的分布做出任何假设,能够自动捕捉特征之间的复杂交互。例如,在预测房价时,房屋的面积、房龄、周边配套设施等因素可能相互影响,决策树可以通过递归地划分数据空间,灵活地适应这种非线性关系。
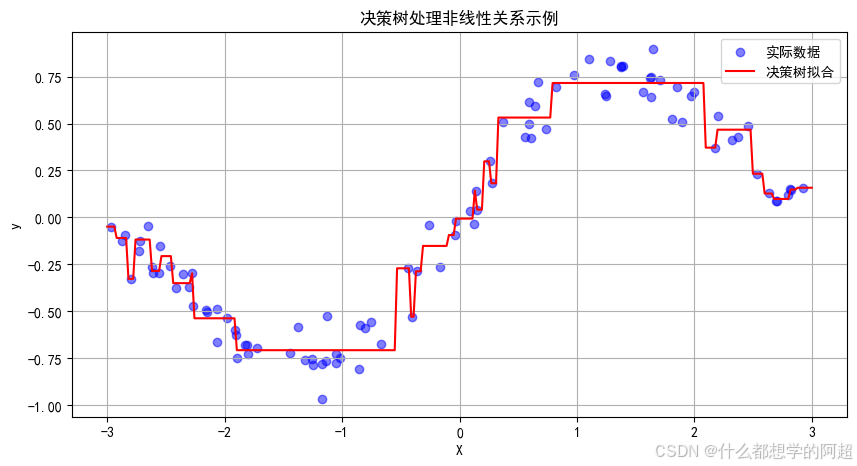
1.2 可解释性强
决策树的树结构可以直观地可视化,这使得模型的决策过程变得透明。通过观察树的结构,我们可以清晰地看到每个特征在决策过程中的作用,从而支持特征重要性分析。比如在金融风控领域,决策树可以帮助我们提取出明确的规则,如“客户的信用评分低于600且贷款金额超过50万则风险较高”,这对于业务人员理解和解释模型的决策非常有帮助。
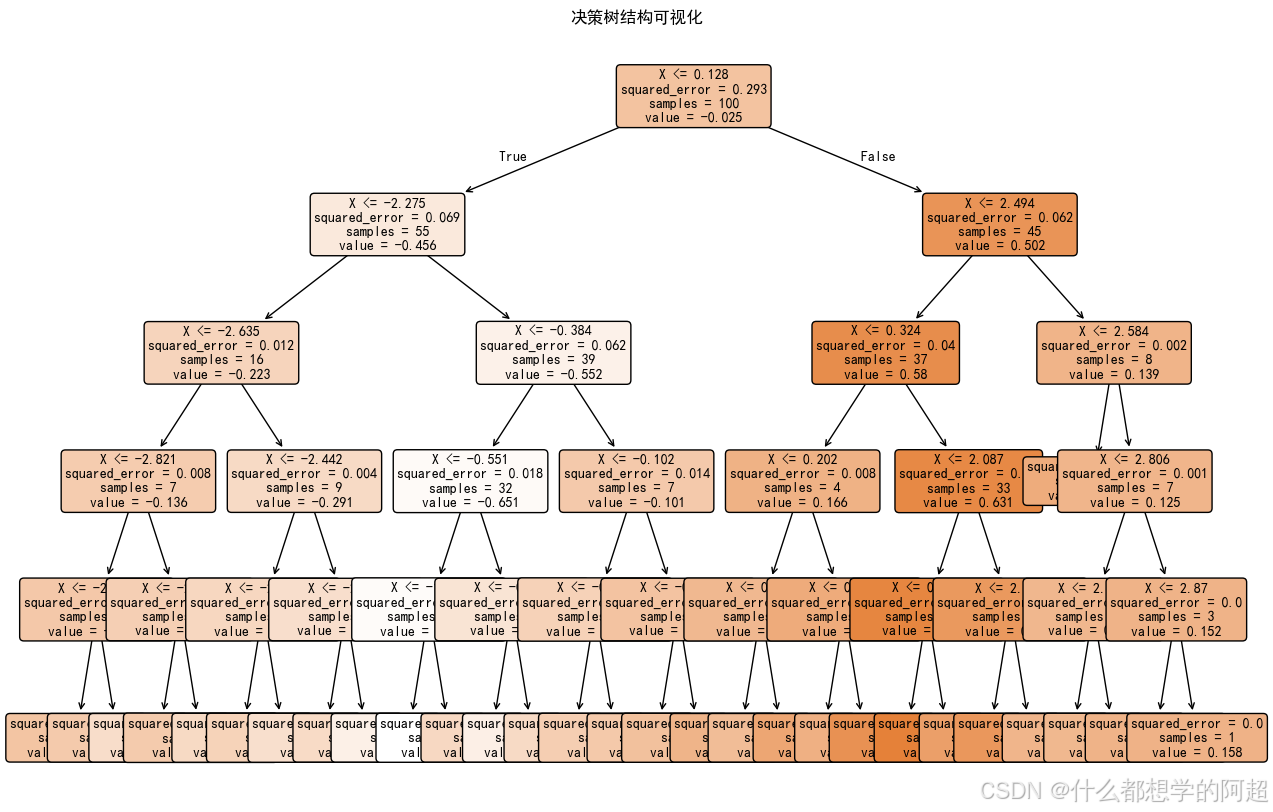
1.3 适应混合数据类型
在实际应用中,数据往往包含数值型和类别型特征。决策树回归能够同时处理这两种类型的特征,无需进行复杂的数据转换。例如,在医疗诊断中,患者的年龄、体温等数值型特征可以与疾病类型、症状等类别型特征一起作为输入,决策树可以有效地利用这些信息进行预测。
适用场景
- 需要模型解释性的业务场景(如金融风控规则提取):在金融领域,决策的可解释性至关重要。监管机构要求金融机构能够清晰地解释模型的决策依据,决策树的可解释性使其成为金融风控的理想选择。通过分析决策树的结构,我们可以提取出具体的风险规则,帮助业务人员进行风险评估和决策。
- 特征与目标存在复杂非线性关联(如医疗诊断指标与疾病程度):医疗数据往往具有高度的复杂性和非线性。例如,某些疾病的发生可能与多个因素相互作用有关,决策树回归可以自动捕捉这些复杂的关系,为疾病的诊断和治疗提供有价值的信息。
2. CART算法与分裂准则
2.1 算法流程
CART(Classification and Regression Trees)算法是构建决策树的常用算法,它通过递归二分法来构建树。具体步骤如下:
2.1.1 选择最优特征与切分点
在每一个节点上,CART算法会遍历所有的特征和可能的切分值,寻找能够使分裂后子节点纯度提升最大的特征和切分点。这个过程类似于在一个多维空间中不断地划分区域,使得每个区域内的数据尽可能纯净。
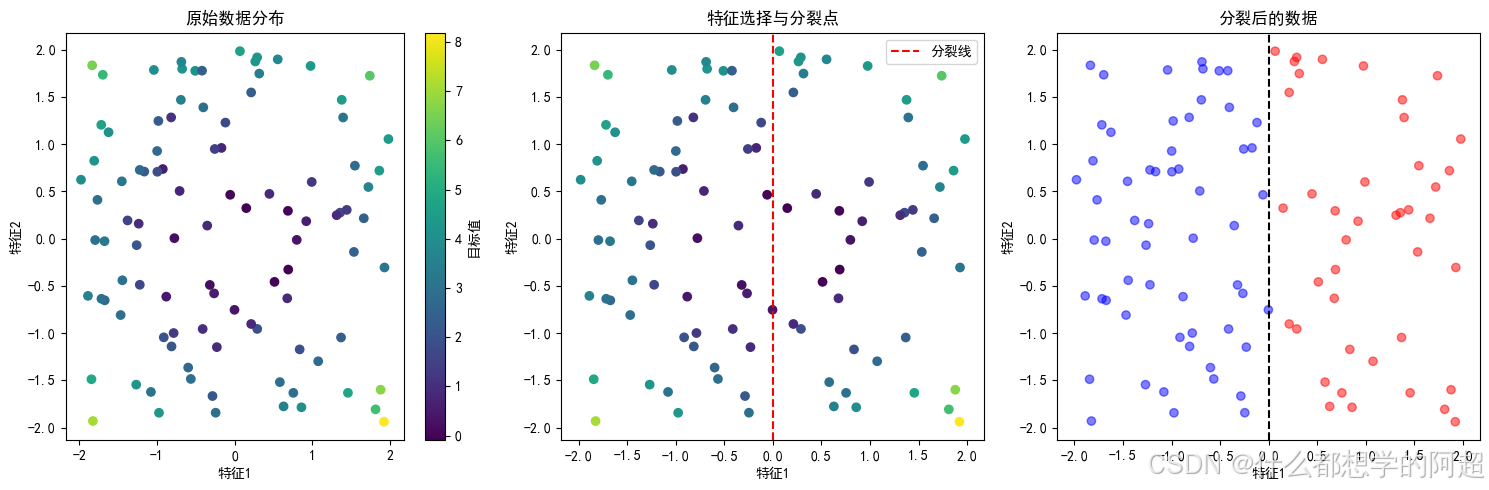
2.1.2 计算分裂增益
为了衡量分裂的好坏,CART算法使用分裂增益来进行评估。常用的分裂准则有均方误差(MSE)和平均绝对误差(MAE),下面我们将详细介绍这两种准则。
2.1.3 递归分裂
在选择了最优特征和切分点后,CART算法会将节点分裂成两个子节点,并对子节点重复上述过程,直到满足停止条件。停止条件可以是树的深度达到最大值、节点中的样本数小于某个阈值等。
2.2 分裂准则:均方误差(MSE)与平均绝对误差(MAE)
2.2.1 MSE(方差减少)
均方误差是一种常用的衡量回归模型误差的指标,在决策树回归中,我们使用MSE的减少量来选择最优的分裂点。其计算公式如下:
[
\Delta \text{MSE} = \text{MSE}\text{父节点} - \left( \frac{N\text{左}}{N} \text{MSE}\text{左} + \frac{N\text{右}}{N} \text{MSE}_\text{右} \right)
]
其中,
N
N
N 是父节点的样本数,
N
左
N_\text{左}
N左 和
N
右
N_\text{右}
N右 分别是左子节点和右子节点的样本数,
MSE
父节点
\text{MSE}_\text{父节点}
MSE父节点、
MSE
左
\text{MSE}_\text{左}
MSE左 和
MSE
右
\text{MSE}_\text{右}
MSE右 分别是父节点、左子节点和右子节点的均方误差。
2.2.2 MAE(中位数绝对偏差)
平均绝对误差是另一种衡量回归模型误差的指标,它对异常值的敏感度较低。在决策树回归中,MAE的减少量也可以作为分裂准则,其计算公式如下:
[
\Delta \text{MAE} = \text{MAE}\text{父节点} - \left( \frac{N\text{左}}{N} \text{MAE}\text{左} + \frac{N\text{右}}{N} \text{MAE}_\text{右} \right)
]
代码示例:计算MSE增益
import numpy as np
def mse(y):
"""
计算均方误差
:param y: 输入的目标值数组
:return: 均方误差
"""
return np.mean((y - np.mean(y)) ** 2)
def mse_gain(y_left, y_right):
"""
计算MSE增益
:param y_left: 左子节点的目标值数组
:param y_right: 右子节点的目标值数组
:return: MSE增益
"""
y_parent = np.concatenate([y_left, y_right])
mse_parent = mse(y_parent)
mse_left = mse(y_left)
mse_right = mse(y_right)
return mse_parent - (len(y_left)*mse_left + len(y_right)*mse_right)/len(y_parent)
3. 树的剪枝:控制模型复杂度
3.1 预剪枝(Pre-pruning)
预剪枝是在树的构建过程中,通过设置一些参数来限制树的生长,从而避免过拟合。常用的预剪枝参数包括:
max_depth:最大树深度,限制树的深度可以防止树过于复杂。例如,当max_depth=3时,树的深度最多为3层。min_samples_split:节点最小样本数,当节点中的样本数小于这个阈值时,停止分裂。这可以避免在样本数较少的节点上进行不必要的分裂。min_samples_leaf:叶节点最小样本数,确保每个叶节点至少包含一定数量的样本。
3.2 后剪枝(Post-pruning)
后剪枝是在构建完整的树之后,自底向上合并叶节点,通过比较不同子树在验证集上的误差,选择误差最小的子树作为最终的模型。后剪枝可以在一定程度上提高模型的泛化能力,但计算成本较高。
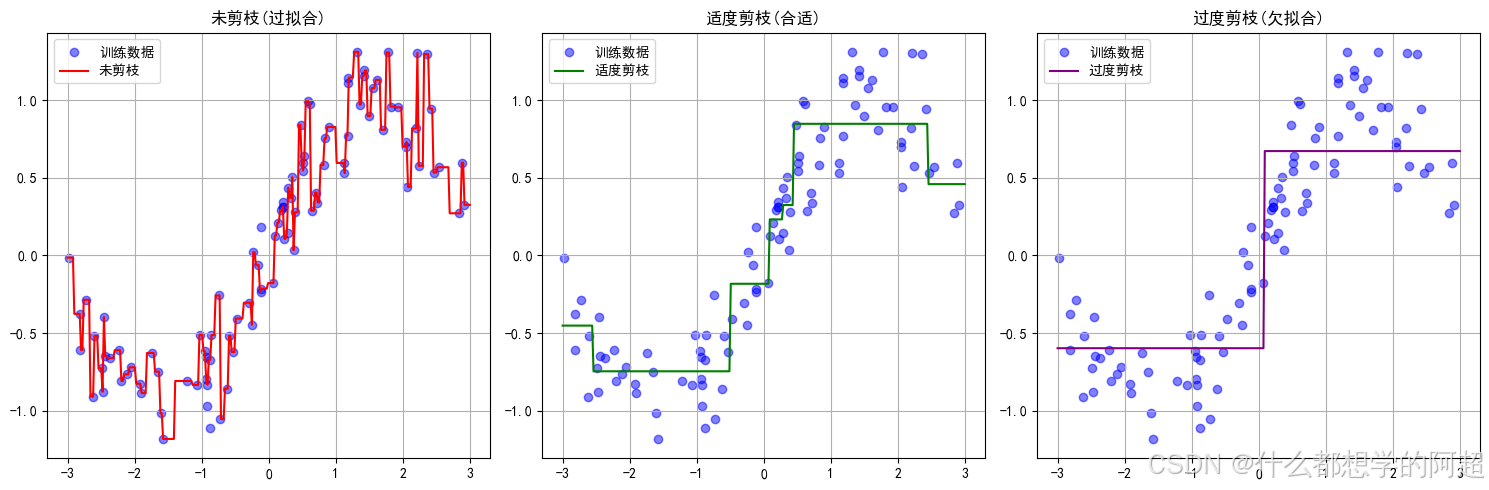
4. 代码实战:天气温度预测
4.1 数据集与特征工程
import pandas as pd
from sklearn.model_selection import train_test_split
# 示例数据集:天气温度预测(特征:湿度、风速、季节、气压)
data = pd.read_csv("weather_data.csv")
X = data[['Humidity', 'WindSpeed', 'Season', 'Pressure']]
y = data['Temperature']
# 类别特征编码(Season为类别)
X = pd.get_dummies(X, columns=['Season'], drop_first=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4.2 模型训练与调参
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 初始模型(未剪枝)
tree_full = DecisionTreeRegressor(random_state=42)
tree_full.fit(X_train, y_train)
# 剪枝模型
tree_pruned = DecisionTreeRegressor(
max_depth=3,
min_samples_split=20,
min_samples_leaf=10,
random_state=42
)
tree_pruned.fit(X_train, y_train)
# 评估
def evaluate(model):
y_pred = model.predict(X_test)
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred)):.2f}")
print(f"MAE: {mean_absolute_error(y_test, y_pred):.2f}")
print("完整树:")
evaluate(tree_full) # 输出示例:RMSE: 3.15, MAE: 2.10
print("\n剪枝树:")
evaluate(tree_pruned) # 输出示例:RMSE: 2.73, MAE: 1.88
4.3 树结构可视化
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 8))
plot_tree(tree_pruned, filled=True, feature_names=X.columns,
rounded=True, fontsize=10)
plt.show()
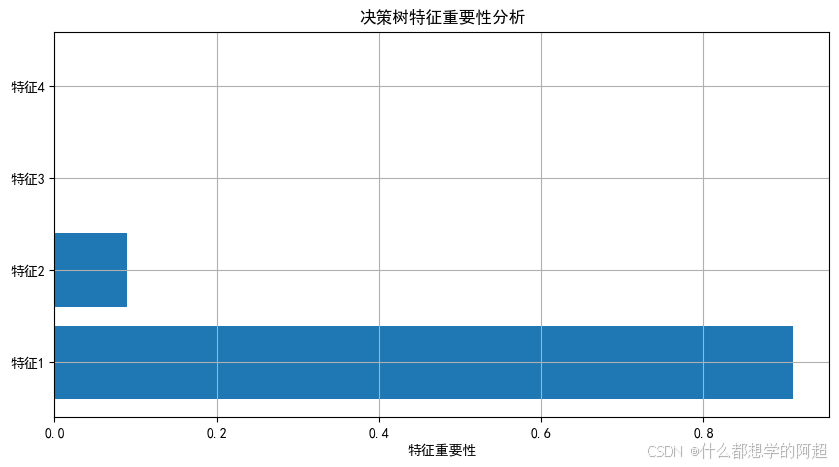
5. 特征重要性分析
5.1 基于分裂增益的重要性
importance = tree_pruned.feature_importances_
features = X.columns
plt.barh(features, importance)
plt.xlabel("特征重要性")
plt.title("决策树特征重要性")
plt.show()

5.2 业务解读
- 湿度和气压是主要预测因子,符合气象学常识。湿度和气压的变化通常与温度密切相关,较高的湿度可能会抑制热量的散发,从而导致温度升高;而气压的变化也会影响大气的稳定性和热量的传递。
- 季节通过
get_dummies编码后重要性较低,可能与数据地域性有关。不同地区的气候条件和季节变化存在差异,数据集中的季节特征可能无法充分反映这种差异,导致其重要性相对较低。
6. 决策树的优缺点
6.1 优点
- 无需数据预处理:决策树可以自动处理缺失值和类别特征,无需进行复杂的数据预处理步骤。例如,在处理含有缺失值的数据时,决策树可以根据其他特征的值来选择合适的分支,而对于类别特征,决策树可以直接处理而无需进行编码转换。
- 可解释性强:决策树的树结构可以转化为业务规则,这使得模型的决策过程易于理解和解释。例如,在金融风控中,我们可以将决策树的规则转化为具体的风险评估标准,帮助业务人员进行决策。
- 高效训练:决策树的训练时间复杂度约为 ( O(n \log n) ),在处理大规模数据时具有较高的效率。
6.2 缺点
- 高方差:决策树对训练数据敏感,训练数据的微小变动可能导致树结构的剧变。这意味着决策树的稳定性较差,容易受到噪声和异常值的影响。
- 预测精度有限:单个决策树容易欠拟合或过拟合,尤其是在处理复杂数据时。为了提高预测精度,通常需要使用集成学习方法,如随机森林。
7. 总结与下一篇预告
7.1 核心结论
- 决策树回归通过递归分裂实现非线性建模,适合解释性优先的场景。在实际应用中,当我们需要对模型的决策过程进行解释和理解时,决策树是一个很好的选择。
- 剪枝策略是平衡模型复杂度的关键。通过预剪枝和后剪枝,我们可以避免决策树过拟合,提高模型的泛化能力。
- 特征重要性分析可指导业务决策优化。通过分析特征的重要性,我们可以了解哪些特征对目标变量的影响最大,从而有针对性地进行特征选择和业务决策。
7.2 下一篇预告
下一篇:《随机森林回归:集成学习的威力》
将深入讲解:
- Bootstrap聚合(Bagging)降低方差
- 特征随机性提升泛化能力
- 使用OOB误差进行无偏估计
延伸阅读
- 《The Elements of Statistical Learning》第9章
- Scikit-Learn决策树文档
- CART算法原始论文
讨论问题
你在实际项目中如何利用决策树的可解释性?是否遇到过树模型不稳定的问题?欢迎分享解决方案!