KNN算法原理及python代码实现
一、KNN算法简介
1.1 算法介绍
KNN算法是一种简单而强大的监督学习算法,广泛应用于分类和回归任务。它基于“近朱者赤,近墨者黑”的原理,通过查找训练数据中与目标点最接近的K个点(邻居)来预测目标点的类别或值
- 分类任务:通过多数投票法确定新数据点的类别
- 回归任务:通过计算最近邻的平均值来预测新数据点的值
1.2 算法实现步骤
1.计算已知类别数据集中的点与当前点之间的距离
注:距离度量方法
- 欧几里得距离:
适用于连续数值型数据
- 曼哈顿距离:
适用于网格状数据
- 闵可夫斯基距离:
通过调整参数 p,可以得到欧几里得距离(p=2)和曼哈顿距离(p=1)。
2.按照距离递增次序排序
3.选取与当前点距离最小的k个点
4.确定前k个点所在类别的出现频率
5.返回前k个点出现频率醉倒的类别作为当前点的预测分类
1.3 算法优缺点
1.优点
- 可以处理分类问题,KNN算法实现简单,容易理解
- 可以免去训练过程
- 可以处理回归问题,也就是预测
2.缺点
- 效率过低
- 队训练数据依赖度特别大
- 存在维数灾难问题
1.4 算法适用场景
KNN算法广泛应用于以下领域:
- 图像识别:用于手写数字识别、人脸识别等
- 文本分类:用于文档分类、情感分析等
- 推荐系统:用于基于用户行为的推荐
- 医学诊断:用于疾病诊断、基因表达分析等
二、实例问题引入:约会网站配对
2.1 问题引入
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人:
- 不喜欢的人
- 一般喜欢的人
- 非常喜欢的人
这些人包含以下三种特征
- 每年获得的飞行常客里程数
- 玩视频游戏所耗时间百分比
- 每周消费的冰淇淋公升数
该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。
2.2 需求概要分析
根据问题,我们可知,样本特征个数为3,样本标签为三类。现需要实现将一个待分类样本的三个特征值输入程序后,能够识别该样本的类别,并且将该类别输出
2.3 本例使用KNN算法流程
1.数据准备
这包括收集、清洗和预处理数据。预处理可能包括归一化或标准化特征,以确保所有特征在计算距离时具有相等的权重。
2. 选择距离度量方法
确定用于比较样本之间相似性的度量方法,常见的如欧几里得距离、曼哈顿距离等
3. 确定K值
选择一个K值,即在分类或回归时应考虑的邻居数量。这是一个超参数,可以通过交叉验证等方法来选择最优的K值
4. 找到K个最近邻居
对于每一个需要预测的未标记的样本:
- 计算该样本与训练集中所有样本的距离,
- 根据距离对它们进行排序
- 选择距离最近的K个样本
5. 预测
- 对于分类任务:查看K个最近邻居中最常见的类别,作为预测结果。例如,如果K=3,并且三个最近邻居的类别是[1, 2, 1],那么预测结果就是类别1
- 对于回归任务:测结果可以是K个最近邻居的平均值或加权平均值
6. 评估
使用适当的评价指标(如准确率、均方误差等)评估模型的性能
7. 优化
基于性能评估结果,可能需要返回并调整某些参数,如K值、距离度量方法等,以获得更好的性能。
2.4 算法实现
1.数据准备
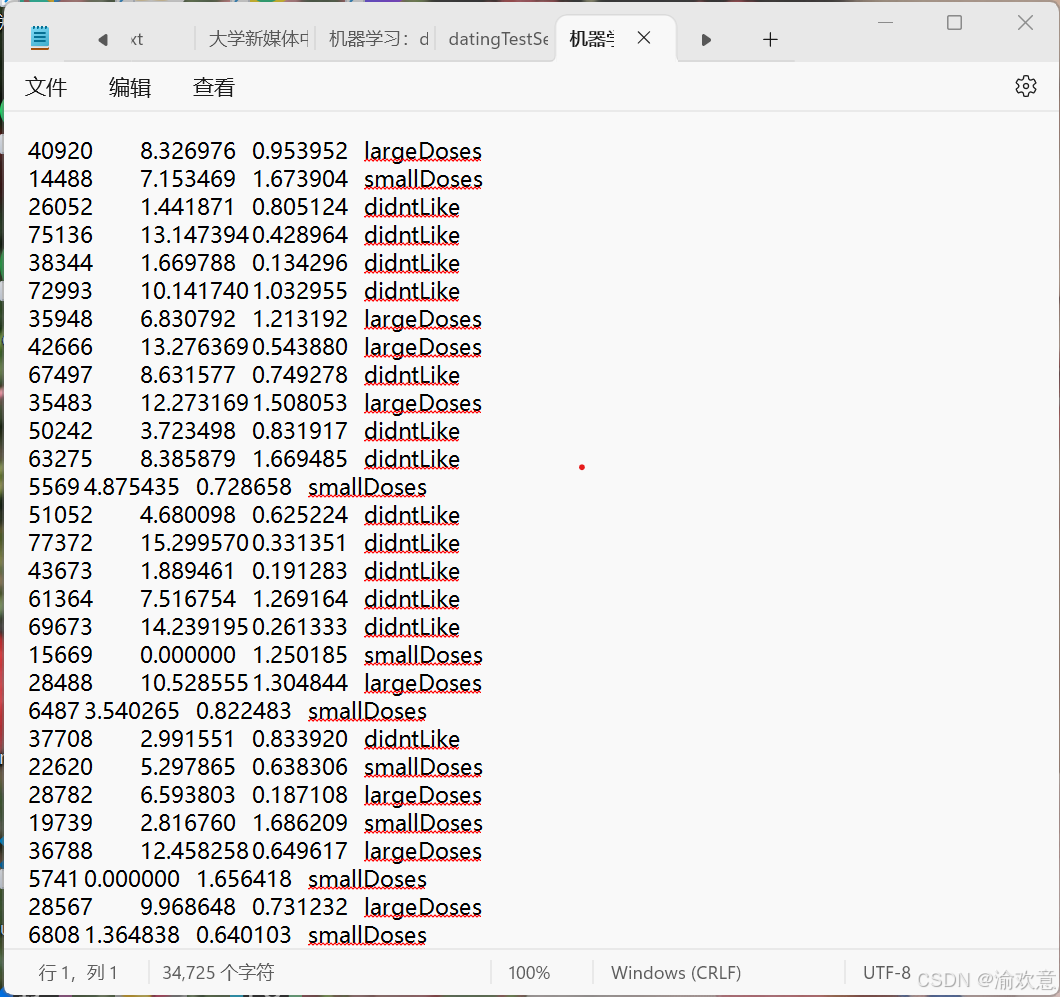
数据的大致格式如上所示,有三个特征值以及一种标签类
第一列:每年获得的飞行常客里程数
第二列:玩视频游戏所耗时间百分比
第三列:每周消费的冰淇淋公升数
第四列:didntLike-不喜欢、smallDoses-有点喜欢、largeDoses-非常喜欢
通过输入前三个特征来预测约会的对象是否符合自己的口味
2.数据读取
使用 load_dataset 函数从文件中读取数据。标签部分将字符串标签(didntLike, smallDoses, largeDoses)转换为整数(1、2、3)
3.数据归一化
使用公式 将特征值归一化到 [0,1] 区间
注意:
:原始特征值。
:该特征列的最小值。
:该特征列的最大值。
:归一化后的特征值,范围在 [0, 1] 之间
4.定义KNN分类器
- 计算测试样本与所有训练样本之间的距离
- 在本实验中,我选取的是欧几里得距离,即
- 找出距离最近的 K 个样本,并统计这些样本的标签
- 选择出现次数最多的标签作为预测结果
5.数据划分
使用简单的切分方式划分训练集和测试集,测试集比例默认为 20%
eg.数据集中共有1000个数据,即训练集个数为800个,测试集个数为200个
6.代码实现
# 定义函数读取数据集
def load_dataset(file_path):
dataset = [] # 存储特征数据
labels = [] # 存储标签数据
with open(file_path, 'r') as file:
for line in file:
# 去掉首尾空格并按制表符分割
features = line.strip().split('\t')
if len(features) != 4:
print(f"Warning: Line skipped due to incorrect format: {line.strip()}")
continue
# 将前三列特征转换为浮点数
dataset.append([float(features[i]) for i in range(3)])
# 将最后一列标签转换为整数
label = features[-1]
if label == "didntLike":
labels.append(1)
elif label == "smallDoses":
labels.append(2)
elif label == "largeDoses":
labels.append(3)
else:
print(f"Warning: Unknown label '{label}' in line: {line.strip()}")
return dataset, labels
# 定义函数对数据进行归一化处理
def normalize(dataset):
# 计算每列的最小值和最大值
min_vals = [min(column) for column in zip(*dataset)]
max_vals = [max(column) for column in zip(*dataset)]
ranges = [max_val - min_val for max_val, min_val in zip(max_vals, min_vals)]
# 归一化数据
normalized_dataset = []
for row in dataset:
normalized_row = [(row[i] - min_vals[i]) / ranges[i] for i in range(len(row))]
normalized_dataset.append(normalized_row)
return normalized_dataset, min_vals, ranges
# 定义函数计算欧几里得距离
def euclidean_distance(instance1, instance2):
distance = 0.0
for i in range(len(instance1)):
distance += (instance1[i] - instance2[i]) ** 2
return distance ** 0.5
# 定义KNN分类器
def knn_classifier(train_data, train_labels, test_instance, k):
distances = []
for i in range(len(train_data)):
# 计算测试实例与每个训练实例的距离
dist = euclidean_distance(train_data[i], test_instance)
distances.append((train_data[i], train_labels[i], dist))
# 按距离排序
distances.sort(key=lambda x: x[2])
neighbors = []
for i in range(k):
neighbors.append(distances[i][1])
# 统计最近邻的标签
votes = {}
for neighbor in neighbors:
if neighbor in votes:
votes[neighbor] += 1
else:
votes[neighbor] = 1
# 返回得票最多的标签
return max(votes, key=votes.get)
# 定义函数划分训练集和测试集
def split_dataset(dataset, labels, test_ratio=0.2):
total = len(dataset)
test_size = int(total * test_ratio)
train_size = total - test_size
train_data = dataset[:train_size]
train_labels = labels[:train_size]
test_data = dataset[train_size:]
test_labels = labels[train_size:]
return train_data, train_labels, test_data, test_labels
# 定义函数计算测试精度
def calculate_accuracy(test_labels, predictions):
correct = sum(1 for true, pred in zip(test_labels, predictions) if true == pred)
return correct / len(test_labels)
# 主程序
if __name__ == "__main__":
# 加载数据集
file_path = r"C:\Users\林欣奕\Desktop\datingTestSet.txt"
dataset, labels = load_dataset(file_path)
if not dataset or not labels:
print("Failed to load the dataset. Please check the file path and format.")
else:
# 数据归一化
normalized_dataset, min_vals, ranges = normalize(dataset)
# 划分训练集和测试集
train_data, train_labels, test_data, test_labels = split_dataset(normalized_dataset, labels, test_ratio=0.2)
# 设置K值
k = 3
# 使用KNN分类器进行预测
predictions = [knn_classifier(train_data, train_labels, test_instance, k) for test_instance in test_data]
# 计算测试精度
accuracy = calculate_accuracy(test_labels, predictions)
# 输出结果
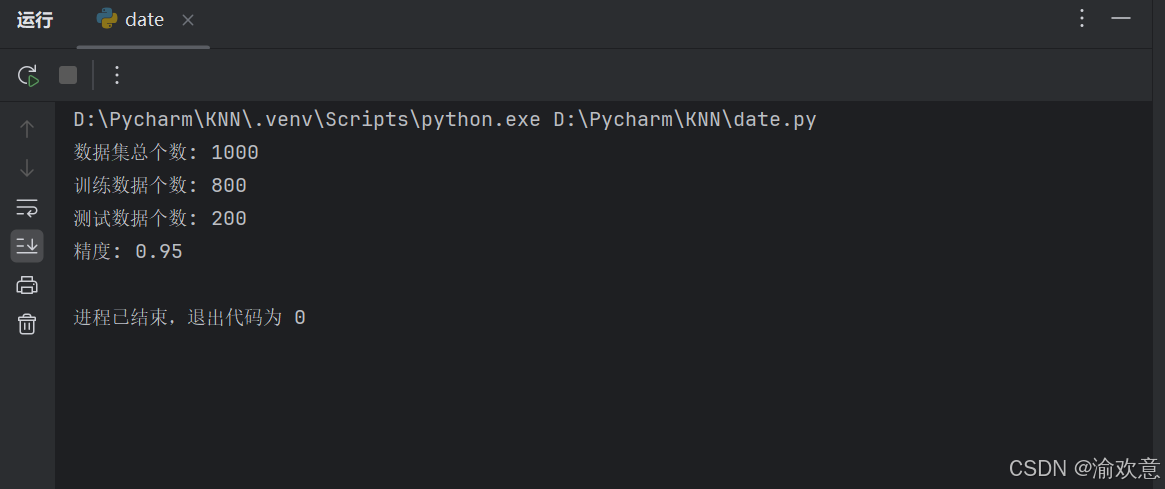
print("数据集总个数:", len(dataset))
print("训练数据个数:", len(train_data))
print("测试数据个数:", len(test_data))
print("精度:", accuracy)7.实验结果截图