KMP算法
KMP算法
基本概念
KMP算法是一种高效的字符串匹配算法,算法名称取自于三位共同发明人名字的首字母组合。该算法的主要使用场景就是在字符串(也叫主串)中的模式串(也叫子串)定位问题,常见的有“求子串出现的起始位置”、“求子串的出现次数”等。
核心算法
暴力匹配
暴力匹配的算法思想很简单,即依次枚举主串中的字符,作为匹配子串的起始字符,然后将两个字符串从起始位置一一比对,若中间出现字符串不匹配的情况,则将主串的起始位置回溯到上一起始位置的下个位置,子串的起始位置回溯到第一个字符,重新开始匹配,时间复杂度为O(m*n),效率较低
算法优化
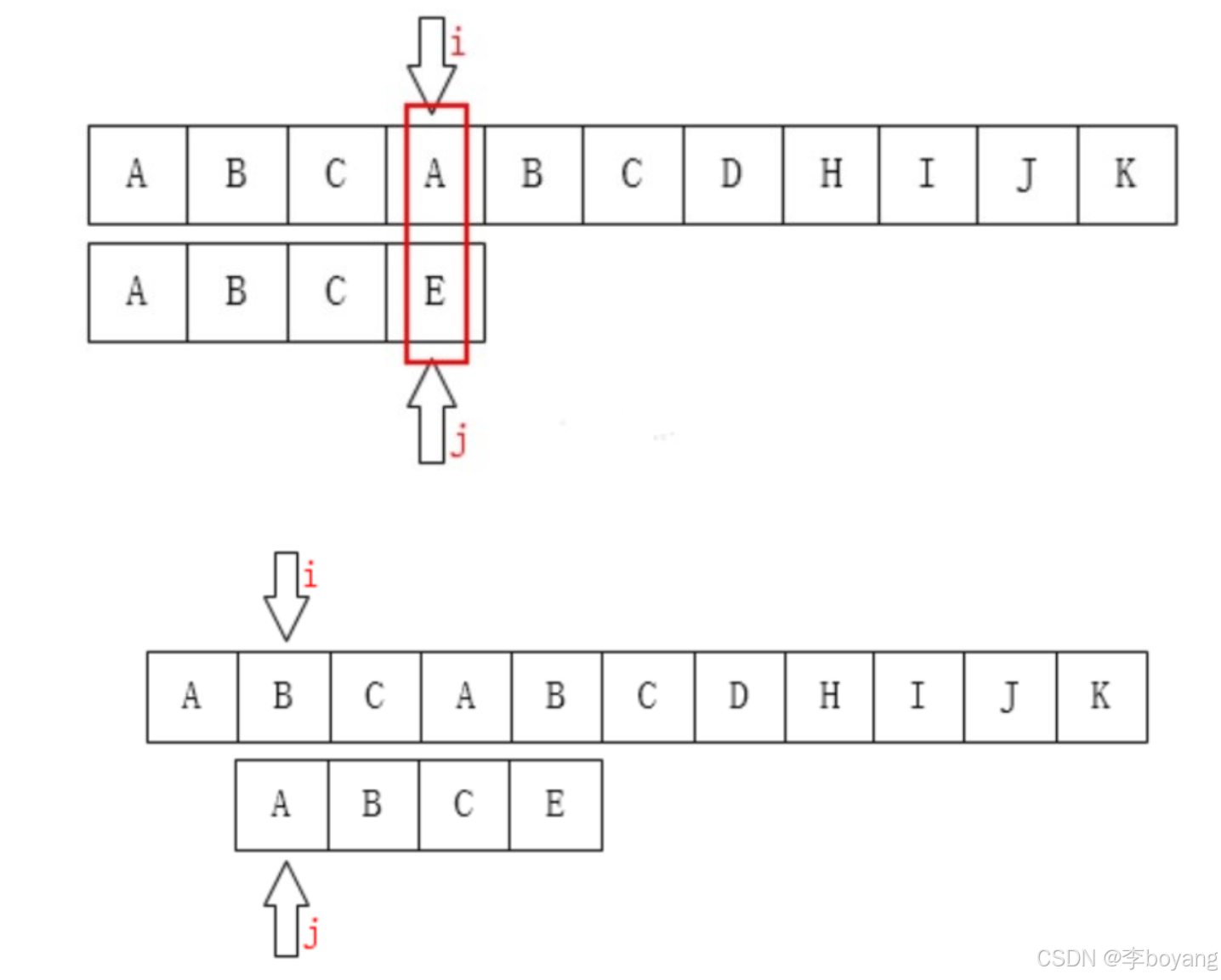
KMP算法相比于暴力匹配算法,最大的优化就是利用匹配失败时失败之前的已知部分时匹配的这个有效信息,保持主串的 i 指针不回溯,通过修改模式串(子串)的 j 指针,使模式串尽量地移动到有效的匹配位置。该算法的时间复杂度为 O(n+m),算法过程示例如下:
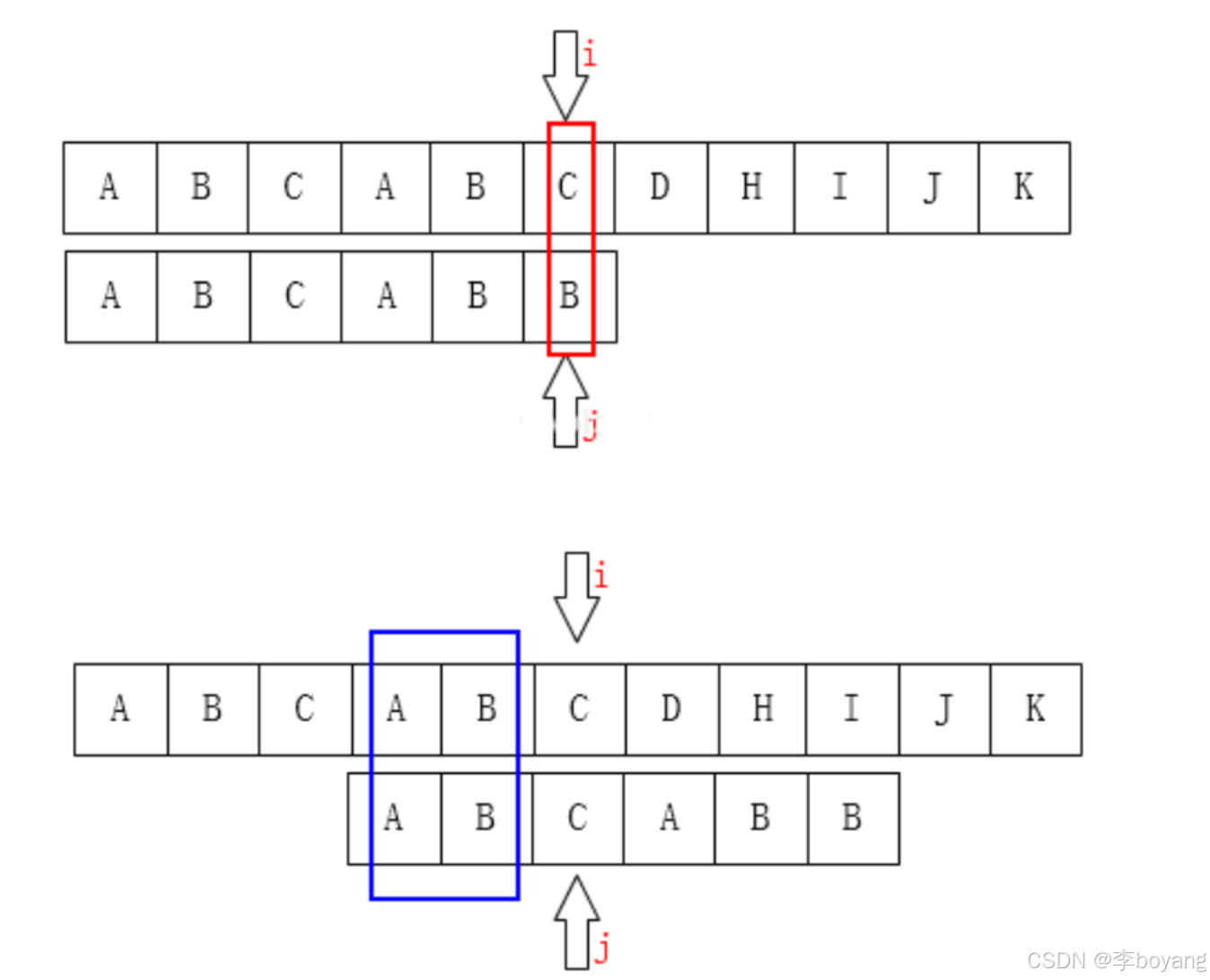
对上面的例子进行抽象分析:
其中,我们需要借助next数组,来求出子串的最大相等前缀和后缀的长度,即上图中的B,当主串与子串的字符不匹配时,我们只需要让子串的起始位置回溯到最长相等前缀的下一个位置即图中的z,而主串不需要再回溯,这样就大大提高了匹配效率,时间复杂度也减小到了O(m+n)
next数组
next数组的定义
- 最长前缀概念: 最长前缀是说以第一个字符开始,但是不包含最后一个字符
- 最长后缀概念: 最长后缀是说以最后一个字符开始,但是不包含第一个字符
- next 数组定义:在模式串中(下标从0开始),next[i] 表示模式串中以下标 i 处字符结尾的子串的最大相同前后缀的长度。在KMP算法中,该值一方面表示模式串中1~i位置子串中的最长相同前后缀长度,另一方面表示在该位置匹配失败时模式串回溯比较的下一个字符位置(最长前缀末座标的下一个字符
如何求next数组
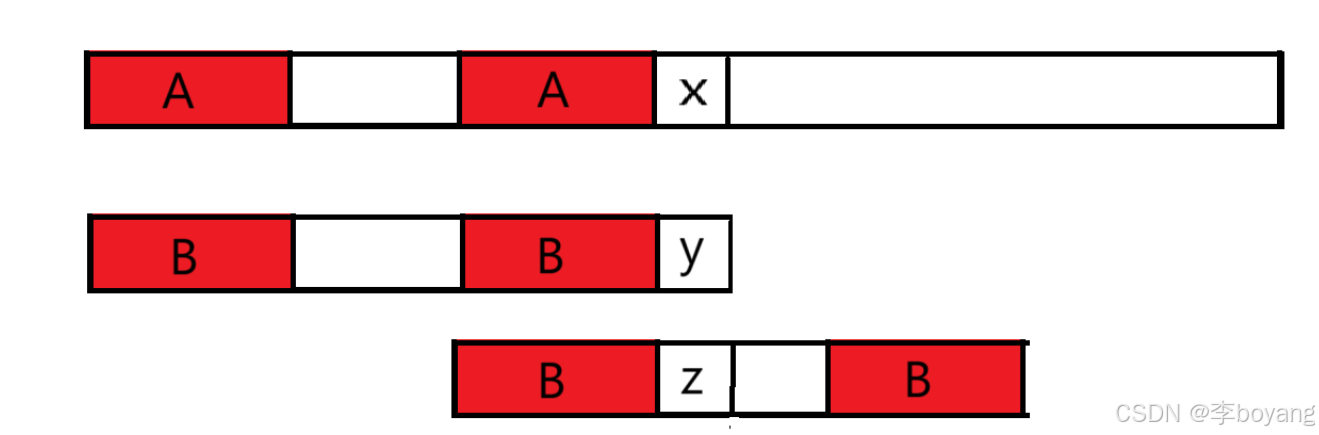
对于模式串 S 来说,首先初始化 next[0] = 0(一个字符不存在相同前后缀,所以长度为0)。假设在求取模式串 next 数组的过程中(与主串无关),已知 next[j] 现在要求 next[j+1] 则有以下两种情况:
-
若 S[ j+1 ] == S[ next[j] ] : 则 next[j+1] = next[j]+1;(next[j] 的值表示长度,但在下标为0开始的字符数组中就表示相等前缀末下标的下一位,因此不用+1即可)
-
若 S[ j+1 ] != S[ next[j] ] : 则说明该结尾处的相同前后缀应该比 j 处的更短一些,也就是我们要找一个更短的前缀和 j+1 处的后缀进行相等匹配。但是由 j 处的匹配可知 A~F 段的前后缀是相同的,因此这就等价于我们要在前缀 A~F 段中即 0~next[j]-1 中寻找一个尽可能大的相同前后缀。而之前的前后缀我们都已经求出了,于是比较就变成了 k = next[next[j] - 1] & S[j+1] == S[k]
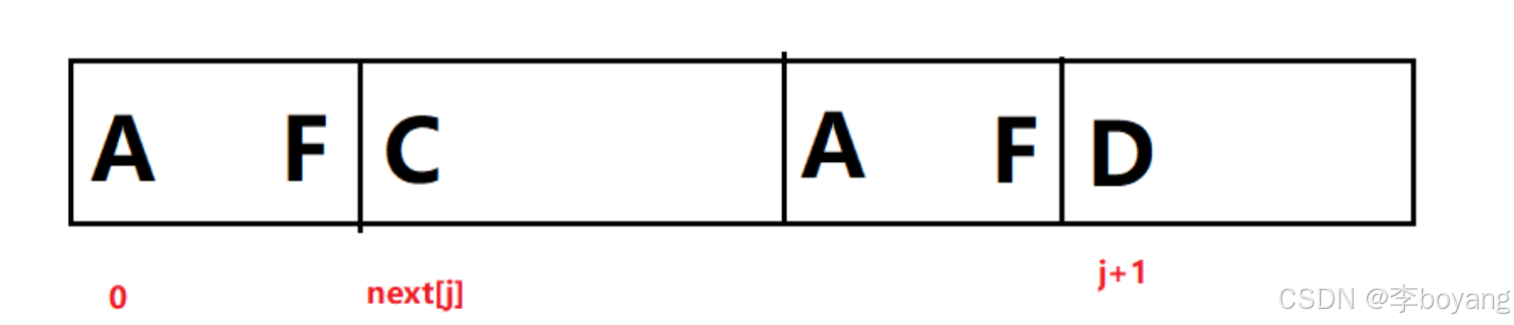
算法实现:
void getNext(char* s,int len)
{
next[0] = 0;
int k = 0; //k = next[0]
int i = 1;
while(i < len)
{
if(s[i] == s[k])
{
next[i++] = ++k; //next[j+1] = k+1;
}
else
{
if(k > 0)k = next[k-1]; //k = next[k-1]
else
{
next[i++] = k; //next[j+1] = 0 回溯到头了,找不到相同前缀,则最大相同前后缀长度=0
}
}
}
}
经典例题
//返回主串T中子串S第一次出现的位置下标,找不到则返回-1
int kmp(char *T, char* S)
{
int len_T = strlen(T);
int len_S = strlen(S);
for(int i = 0,j = 0;i<len_T;i++)
{
while(j > 0 && T[i] != S[j])j = next[j-1];
if(T[i] == S[j])j++;
if(j == len_S)return i-len_S+1;
}
return -1;
}